







 本文深入探讨了使用PyTorch和TorchText构建的Seq2Seq模型,详细讲解了编码器-解码器架构,包括LSTM层的应用,以及如何进行训练和评估。通过实例演示了德语到英语的翻译过程。
本文深入探讨了使用PyTorch和TorchText构建的Seq2Seq模型,详细讲解了编码器-解码器架构,包括LSTM层的应用,以及如何进行训练和评估。通过实例演示了德语到英语的翻译过程。
1 介绍
在本系列中,我们将使用PyTorch和TorchText构建一个机器学习模型,从一个序列到另一个序列。 这将在德语到英语的翻译中完成,但是模型可以应用于涉及从一个序列到另一个序列的任何问题。(本篇论文“Sequence to Sequence Learning with Neural Networks ”)
最常见的序列到序列(seq2seq)模型是编码器-解码器模型,通常使用递归神经网络(RNN)将源(输入)语句编码为单个向量。 在本笔记中,我们将将此单个向量称为上下文向量。 我们可以将上下文向量视为整个输入句子的抽象表示。 然后,该向量由第二个RNN解码,该第二个RNN通过一次生成一个单词来学习输出目标(输出)语句。
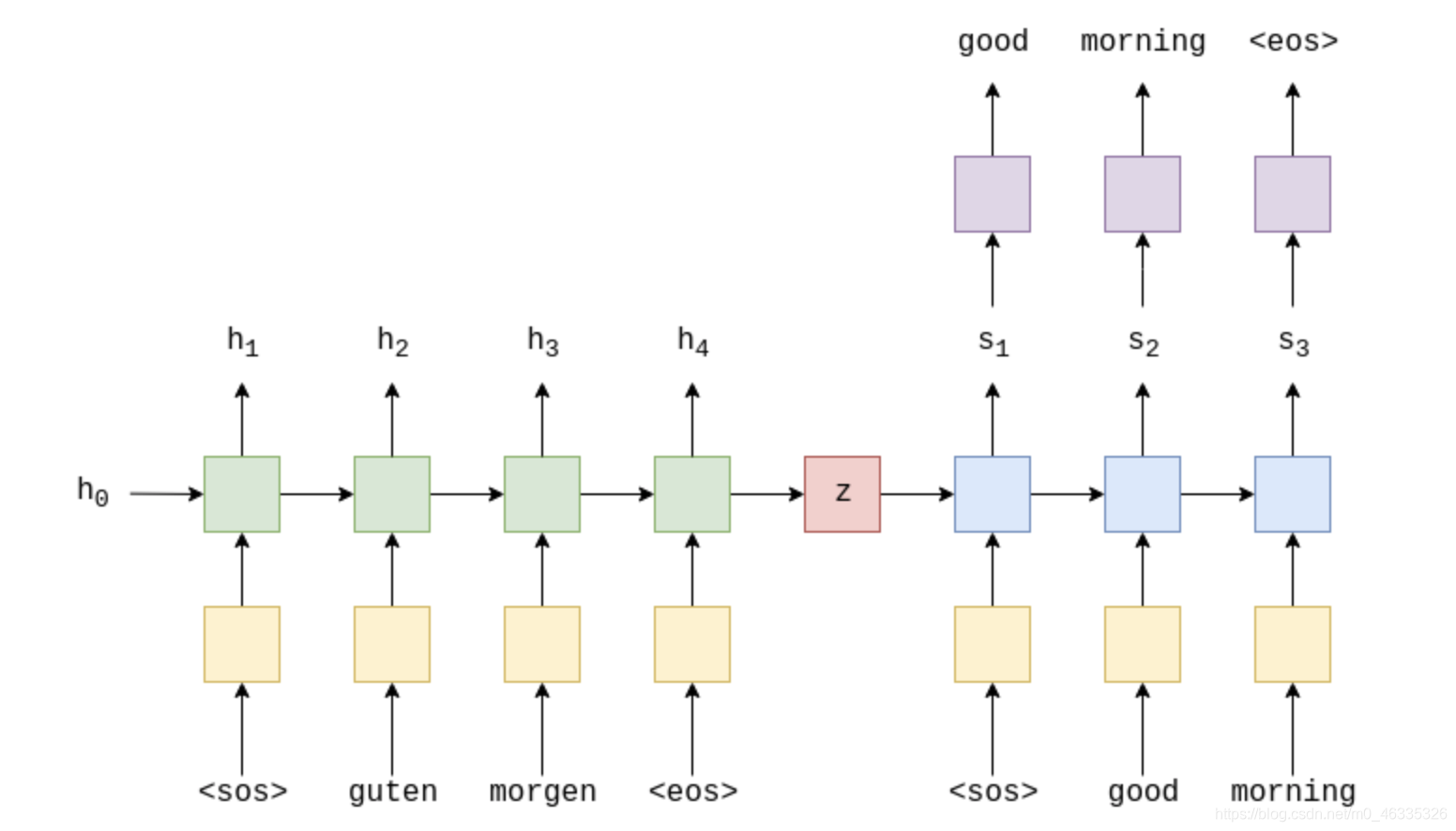
上图显示了示例翻译。 输入/源句子“ guten morgen”穿过嵌入层(黄色),然后输入到编码器中(绿色)。 我们还将序列的开头()和序列的结尾()标记分别附加到句子的开头和结尾。 在每个时间步,编码器RNN的输入既是当前单词e(x_t)的嵌入,也是前一个时间步的隐藏状态 h (t -1) ,编码器RNN输出新的隐藏状态h_t 。 到目前为止,我们可以将隐藏状态视为句子的向量表示。 RNN可以表示为 e(x_t)和 h_ {t-1} 的函数:
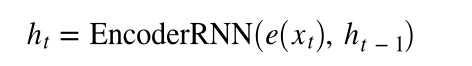
将隐藏层最后一个输出h_t当作源句子的向量z
添加句子的起始和结束单词,隐藏层输入为S(t-1),起始的S_0为句子向量即s_0 = z = h_t(the initial decoder hidden state is the final encoder hidden state):

在句子中至少出现两次的单词才允许在词汇表中出现,只出现一次的单词使用<unk>代替
2 模型构建
模型分为三个部分:编码器,译码器以及seq2seq整合模型
- Encoder:
1)两层LSTM
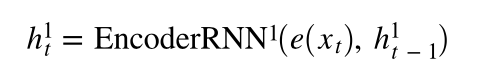

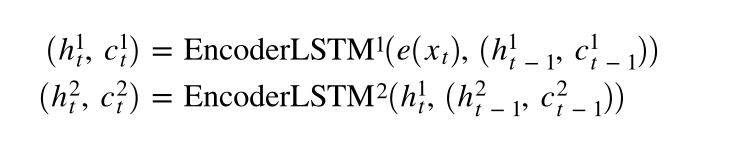
在这些教程中,我们不会详细讨论嵌入层。 我们所需要知道的是,在将单词(从技术上讲,单词的索引)传递到RNN之前,需要一步,然后将RNN转换为向量。
【注】 - 输入的词向量(input_dim)维度与one-hot相同(也与词汇表大小相同,实质是利用索引)
- hid_dim为隐藏层单元数
我们传入源语句X,该语句使用嵌入层转换为密集向量,然后应用dropout。 然后将这些嵌入传递到RNN。 当我们将整个序列传递给RNN时,它将为我们自动对整个序列进行隐藏状态的递归计算! 注意,我们没有将初始的隐藏状态或单元状态传递给RNN。 这是因为,如文档中所述,如果没有将任何隐藏/单元状态传递给RNN,它将自动创建初始隐藏/单元状态作为全零的张量。
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.hid_dim = hid_dim
self.n_layers = n_layers
#RNN的层数
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
#src = [src len, batch size]
#实质上使用的词向量的索引
embedded = self.dropout(self.embedding(src))
#embedded = [src len, batch size, emb dim]
outputs, (hidden, cell) = self.rnn(embedded)
#outputs = [src len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#outputs are always from the top hidden layer
return hidden, cell
- Decoder
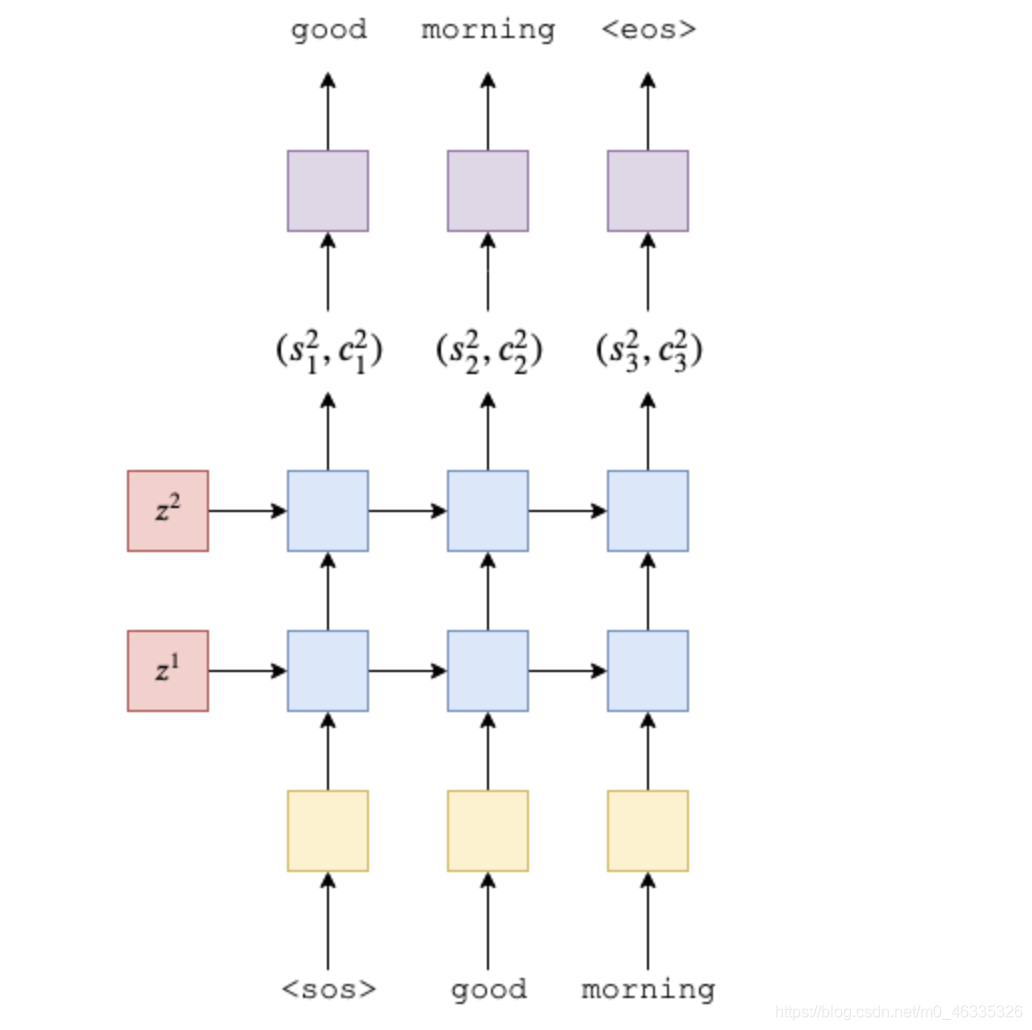
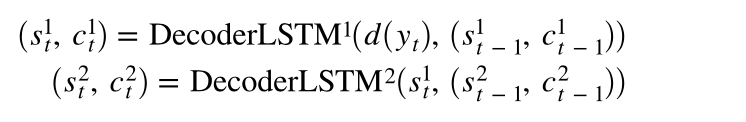
解码器的初始隐藏状态和单元状态是上下文向量,它们是同一层编码器的最终隐藏状态和单元状态
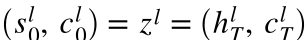
参数和初始化与Encoder类类似,output_dim是输出/目标的词汇大小,还添加了线性层,用于根据顶层隐藏状态进行预测。
在forward方法中输入一个batch词向量,先前的隐藏状态和先前的单元状态。由于我们一次只解码一个单词,因此输入单词的序列长度始终为1。我们对输入单词进行解压以添加句子长度维度1。然后,类似于编码器,我们穿过一个嵌入层并申请辍学。然后将这批嵌入式令牌与先前的隐藏状态和单元状态一起传递到RNN中。这将产生一个输出(RNN顶层的隐藏状态),一个新的隐藏状态(每一层一个,彼此堆叠)和一个新的单元状态(每层一个状态,一个彼此堆叠)。然后,我们将输出(除去句子长度维度后)通过线性层以接收我们的预测。然后,我们返回预测,新的隐藏状态和新的单元状态。
注意:由于我们的序列长度始终为1,因此可以使用nn.LSTMCell而不是nn.LSTM,因为它被设计为处理一批不一定在序列中的输入。 nn.LSTMCell只是一个单元格,而nn.LSTM是可能多个单元格的包装。在这种情况下使用nn.LSTMCell意味着我们不必放松即可添加假序列长度尺寸,但是在解码器中,每层我们需要一个nn.LSTMCell并确保每个nn.LSTMCell都接收正确的初始隐藏编码器的状态。所有这些使代码不太简洁-因此决定坚持常规nn.LSTM。
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
#input = [batch size]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#n directions in the decoder will both always be 1, therefore:
#hidden = [n layers, batch size, hid dim]
#context = [n layers, batch size, hid dim]
input = input.unsqueeze(0)
#input = [1, batch size]
embedded = self.dropout(self.embedding(input))
#embedded = [1, batch size, emb dim]
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
#output = [seq len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#seq len and n directions will always be 1 in the decoder, therefore:
#output = [1, batch size, hid dim]
#hidden = [n layers, batch size, hid dim]
#cell = [n layers, batch size, hid dim]
prediction = self.fc_out(output.squeeze(0))
#prediction = [batch size, output dim]
return prediction, hidden, cell
- Seq2Seq
1)接收输入/源句
2)使用编码器产生上下文向量
3)使用解码器产生预测的输出/目标句子
对于此实现,我们必须确保编码器和解码器中的层数和隐藏(和单元)尺寸相等。并非总是如此,在序列到序列模型中,我们不一定需要相同数量的层或相同的隐藏尺寸大小。但是,如果我们做了一些类似的事情,例如拥有不同数量的层,那么我们将需要决定如何处理。例如,如果我们的编码器有2层,而我们的解码器只有1层,该如何处理?我们是否平均解码器输出的两个上下文向量?我们是否都穿过线性层?我们是否仅使用最高层的上下文向量?我们将使用模型预测的令牌作为模型的下一个输入,即使它与序列中实际的下一个令牌不匹配也是如此。
在decoder每一次loop中做以下工作:
1)输入前一个时间点(y_t, s_{t-1}, c_{t-1})
2)得到当前时间点的 (y_{t+1}, s_t, c_t)
3)将y_{t+1}放入张量y’中
4)是否采用 “teacher force”
经过loop最后返回y’
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
assert encoder.hid_dim == decoder.hid_dim, \
"Hidden dimensions of encoder and decoder must be equal!"
assert encoder.n_layers == decoder.n_layers, \
"Encoder and decoder must have equal number of layers!"
def forward(self, src, trg, teacher_forcing_ratio = 0.5):
# teacher_forcing_ratio使用正确的下一个单词去训练(不知道理解的对错)
#src = [src len, batch size]
#trg = [trg len, batch size]
#teacher_forcing_ratio is probability to use teacher forcing
#e.g. if teacher_forcing_ratio is 0.75 we use ground-truth inputs 75% of the time
batch_size = trg.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
#需要定义一个张量,存储所有预测出的结果y‘
#tensor to store decoder outputs
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
#last hidden state of the encoder is used as the initial hidden state of the decoder
hidden, cell = self.encoder(src)
#first input to the decoder is the <sos> tokens
input = trg[0,:]
for t in range(1, trg_len):
#insert input token embedding, previous hidden and previous cell states
#receive output tensor (predictions) and new hidden and cell states
output, hidden, cell = self.decoder(input, hidden, cell)
#place predictions in a tensor holding predictions for each token
outputs[t] = output
#decide if we are going to use teacher forcing or not
teacher_force = random.random() < teacher_forcing_ratio
#get the highest predicted token from our predictions
top1 = output.argmax(1)
#if teacher forcing, use actual next token as next input
#if not, use predicted token
input = trg[t] if teacher_force else top1
return outputs
3 训练模型
- 输入和输出向量的维度由词汇表大小决定,词向量维度和正则化使用可以改变,hidden cell和layers需要保持统一。
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
HID_DIM = 512
N_LAYERS = 2
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, N_LAYERS, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, N_LAYERS, DEC_DROPOUT)
model = Seq2Seq(enc, dec, device).to(device)
def init_weights(m):
for name, param in m.named_parameters():
nn.init.uniform_(param.data, -0.08, 0.08)
model.apply(init_weights)
训练
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg)
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
在评估模型时,我们使用with torch.no_grad()块来确保在该块内不计算梯度,这样可以减少内存消耗并加快处理速度。
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output = model(src, trg, 0) #turn off teacher forcing
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
我们终于可以开始训练我们的模型了!
在每个时期,我们都会检查模型是否达到了迄今为止的最佳验证损失。 如果有,将更新最好的验证损失并保存模型的参数(在PyTorch中称为state_dict)。 当我们测试模型时,将使用保存的参数来获得最佳的验证损失。
N_EPOCHS = 10
CLIP = 1
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut1-model.pt')
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')

















 2427
2427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









