






 本文介绍了Transformer模型的结构,特别是Embedding层如何将图像分解为小patch并转换为向量,以及自注意力机制的工作原理。作者通过实例和代码解释了这两个关键部分,展示了Transformer从泛化学习到细致化学习的进化过程。
本文介绍了Transformer模型的结构,特别是Embedding层如何将图像分解为小patch并转换为向量,以及自注意力机制的工作原理。作者通过实例和代码解释了这两个关键部分,展示了Transformer从泛化学习到细致化学习的进化过程。
前言
论文中对Transformer的定义:
Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution。
自从具有强大编码能力的Transformer提出来以后,在机器学习的各大领域中几乎无处不在,而他的效果也确实非常的好。从个人认知的角度来看,从全连接到CNN,再到Transformer的历程,其实是机器学习的模式从一种“泛化式”学习(只看重结果而忽略学习过程的细节)过渡到“条理化”学习形式(开始注重学习过程),再转到“细致化”学习(十分强调学习过程的细节)升级过程。最近也正在学Vision Transformer,看了网上很多博客都做了非常好的总结,奈何自己不懂的地方实在太多,于是自己简单的做一个整理,争取理解透彻。🧐
一、模型结构
整个结构可以将其大致分为3个部分:
- Embedding层:将图像转换成一个序列。
- Transformer Encoder
- MLP Head
这里附上Wz大佬绘制的结构图:
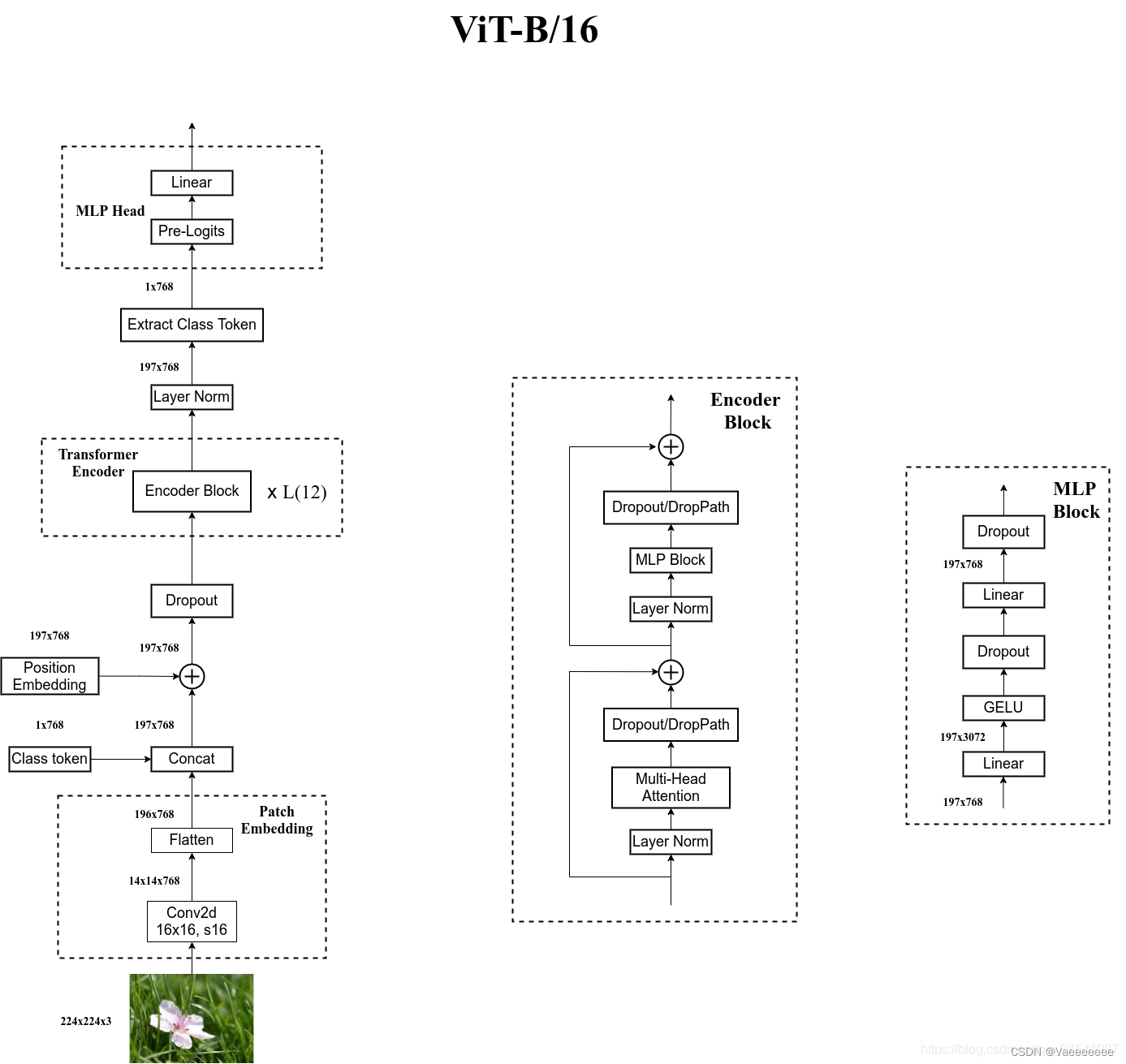
二、原理解析
1.Linear Projection of Flattened Patches(Embedding层)

- 对模型而言,输入的要求是Token(向量)序列,其大小为
[num_token,token_dim]。
其实这一结构的主要作用就是将一张图片分解成若干张小图片,再将其小图片转换成向量。 - 结合上面论文中的原理图和下面的图以及代码部分来理解这个过程:

class PatchEmbed(nn.Module):
def __init__(self,img_size=224,patch_size=16,in_c=3,embed_dim=768,norm_layer=None):
super(PatchEmbed,self).__init__()
img_size = (img_size,img_size)
patch_size = (patch_size,patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0],img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.proj = nn.Conv2d(in_c,embed_dim,kernel_size=patch_size,stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self,x):
B,C,H,W = x.shape
assert H==self.img_size[0] and W ==self.img_size[1],f"Input image size ({H}*{W}) doesn't match model ({sefl.img_size[0]}*{self.img_size[1]})."
# flatten:[B,C,H,W] --> [B,C,HW]
# transpose:[B,C,HW] --> [B,HW,C]
x = self.proj(x).flatten(2).transpose(1,2)
x = self.norm(x)
return x
2.自注意力机制

- 具体原理可以参考Wz大佬写的内容,文末附有链接,写的非常详细。
- 下面结合自己的理解图看代码部分:
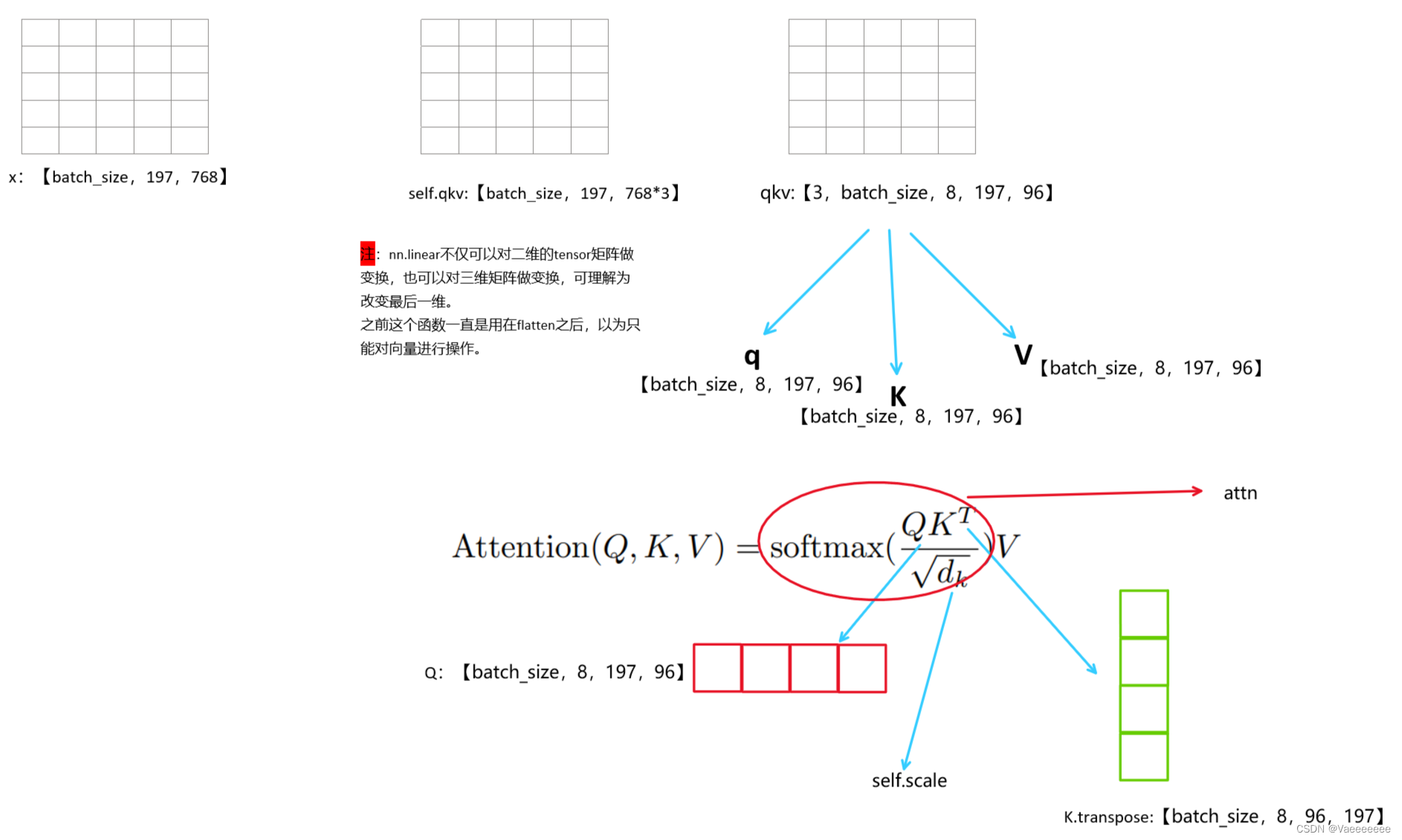
class Attention(nn.Module):
def __init__(self,
dim, #输入token的dim
num_heads = 8,
qkv_bias = False,
qk_scale = None,
attn_drop_ratio = 0.,
proj_drop_ratio = 0.):
super(Attention,self).__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim,dim*3,bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop_ratio)
self.proj = nn.Linear(dim,dim)
self.proj_drop = nn.Dropout(proj_drop_ratio)
def forward(self, x):
B,N,C = x.shape
# [barch_size,num_patches + 1,total_embed_dim]
qkv = self.qkv(x).reshape(B,N,3,self.num_heads,C // self.num_heads).permute(2,0,3,1,4)
# self.qkv(): ->[batch_size,num_patches + 1,3*total_embed_dim]
# reshape: ->[batch_size,num_patches + 1,3,num_heads,embed_dim_per_head]
# permute: ->[3,batch_size,num_heads,num_patches + 1,embed_dim_per_head]
q,k,v = qkv[0],qkv[1],qkv[2]
# transpose: ->[batch_size,num_heads,embed_dim_per_head,num_patches + 1]
# @: ->[batch_size,num_heads,num_patches + 1,num_patches + 1]
attn = (q @ k.transpose(-2,-1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]
# reshape: -> [batch_size, num_patches + 1, total_embed_dim]
x = (attn @ v).transpose(1,2).reshape(B,N,C)
x = self.proj(x)
x = self.proj_drop(x)
return x


















 2679
2679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











