






1.前言
- Vision Transformer论文
- 2021年发表
2.Vision Transformer算法流程
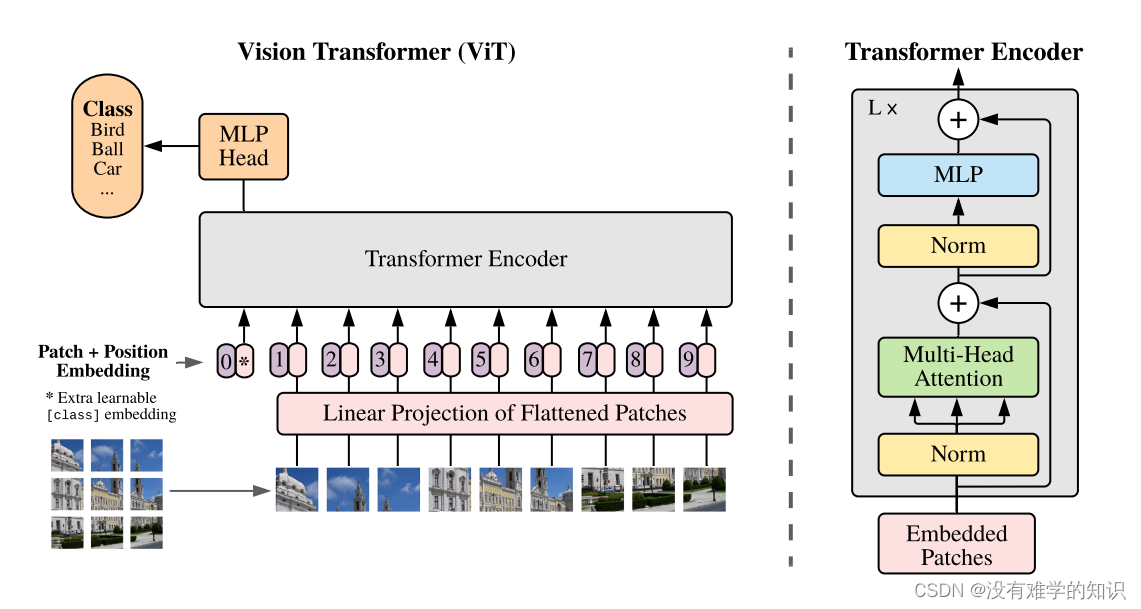
- 将图像分为一个个的patch,然后将九个patch输入至Linear Projection of Flattened Patches(Embedding层)
- 之后每个patch会得到对应的一个个向量(token),同时会在9个token前面加上class token(参考的BERT网络)上图的粉色椭圆形对应的区域
- 再给每一个token加上位置信息(Position Embedding),对应到上图紫色的椭圆形0-9这些数字所标注的
- 然后将token和Position Embedding输入到Transformer Encoder(具体内容是上图右侧所示)
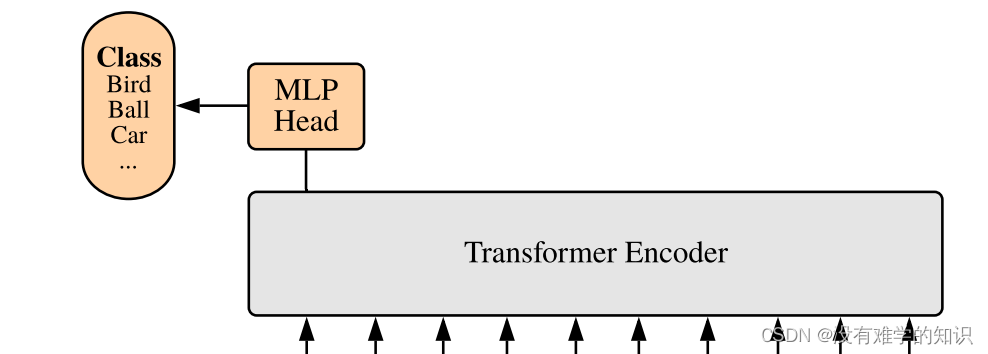
- 我们这里需要对图像进行分类,所以只需要提取class token所对应的输出,再通过MLP head得到最终的分类结果
2.1Linear层
-
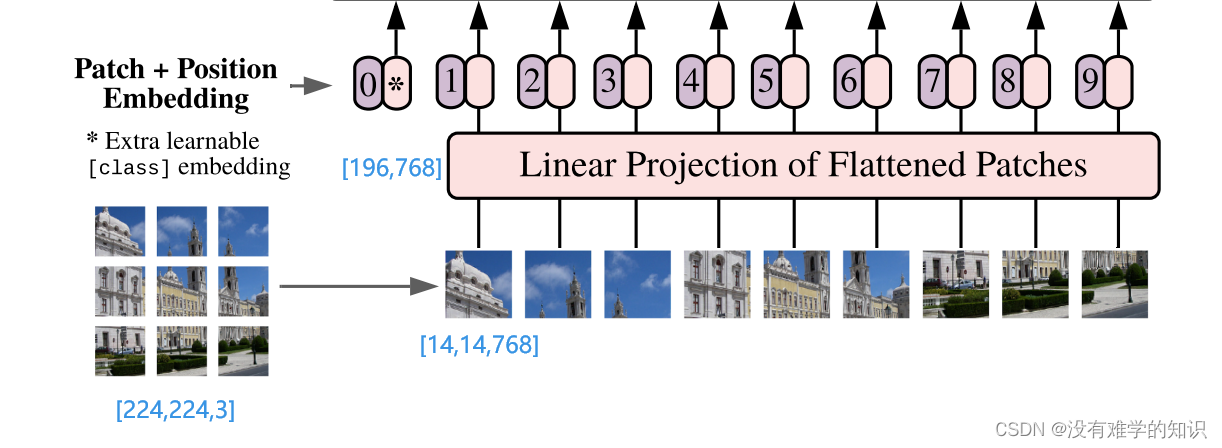
对于标准的Transformer模块,要求输入的是token(向量)序列,即二维码矩阵[num_token,token_dim]
-
在图像分层patches再输入至Linear Projection of Flattened Patches(Embedding层)时,在代码实现中,是直接通过一个卷积层来实现以ViT-B/16为例(其中16就是patch的大小),使用卷积核大小为16×16,步距stride为16,卷积核个数为768,这里768对应每个token向量的长度/维度(16×16×3)
-
所以通过卷积层之后就将[224,224,3]变成了[14,14,768](226÷14=16),再将高度和宽度两个信息展平变成[196×768](14×14=196),196个token
-
在输入Transformer Encoder之前需要加上[class]token以及Position Embedding,都是可训练参数
-
初始化了拼接参数[class]token:Cat([1,768],[196,768])->[197,768](Cat是1×1大小的,维度是768,再乘上上面计算patch的[196,768]最终得到的为[197,768])
-
叠加位置编码Position Embedding:[197,768]->[197,768]
2.2Position Embedding
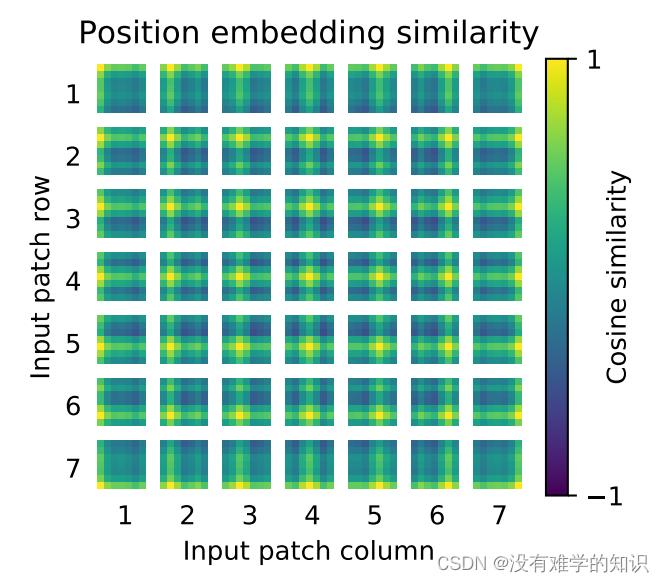
- 比如第一行第一列所对应的位置编码,首先与它自己进行余弦相似度的求解=1,所以就是黄色
- 通过对照右侧的数值表,可以知道值是在-1到1之间,颜色是从暗到亮的
- 通过上图可以观察到,该方块所对应的行和列都是比较亮的,比如最后一行最后一列的就是比较亮,偏黄的
2.3Transformer Encoder层
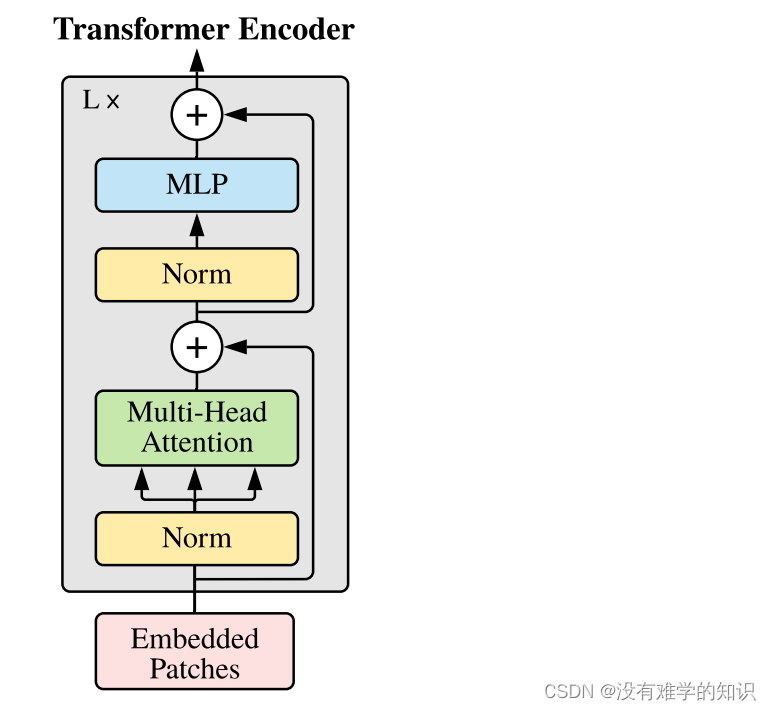
- 这部分与Transformer类似,这里就不再赘述了
- 注意,在Transformer Encoder前面有个Dropout层,后有一个Layer Norm层(原论文中没有绘制出来,但是看代码是有的)
2.4MLP Head层
- 注意,在Transformer Encoder前面有个Dropout层,后有一个Layer Norm层(原论文中没有绘制出来,但是看代码是有的)
- 训练ImageNet21K时,是由全连接层(Linear)+激活函数(tanh)+全连接层(Linear)
- 但是迁移到ImageNet1K上或者自己数据上时,就只有一个简单的全连接层(Linear),就可以将MLP Head简单理解为一个全连接层,后面如果需要得到每个类别概率,还需要再接上一个
s
o
f
t
m
a
x
softmax
softmax
















 6290
6290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











