







用于小样本图像分割的先验引导特征增强网络(PFENet)
目前存在的问题
现有的Few-Shot Segmentation方法普遍存在的问题包括高级特征的误用导致的泛化损失以及查询样本和支持样本之间的空间不一致。
本文贡献
(1)一种无需训练的先验掩模生成方法,不仅保留了模型的泛化能力,而且提高了模型的性能。
(2)特征增强模块,一种使用支持特征(support feature)和先验掩码(prior mask)来自适应增强查询特征(query feature)以克服空间不连续问题的模块。
重要的观察(为何要使用先验引导):
在CANet的实验中发现了高层特征(例如ResNet50中的conv5_x)会导致最终表现下降。有的文献对此现象的解释是中层特征表现更好的原因是这部分是由unseen classes所共享的部分组成的(例如大多数动物不管是狗还是猫都有眼睛鼻子),而本文给出的解释是包含在高级特征中的语义信息比包含在中级特征中的语义信息更特定于某个类,这表明高级特征更有可能对模型对不可见类的泛化能力产生负面影响
值得注意的是,与发现高层特征会对few shot分割的性能产生不利影响相反,之前的分割框架利用这些特征为最终预测提供语义线索。这一矛盾促使我们寻找一种以training-class-insensitive的方式利用高级信息的方法,以提高在few shot分割中的性能。
方法
首先将ImageNet[32]预先训练的包含语义信息的高级特征转换为一个先验掩码,该掩码告诉像素属于目标类的概率,如图:

Backbone参数使用的是PANet或CANet的网络参数。
I
Q
I_Q
IQ表示输入的查询图像,
I
S
I_S
IS表示输入的支持图像,
M
S
M_S
MS表示二值支持掩码,
F
\mathcal{F}
F表示backbone网络,
X
Q
X_Q
XQ和
X
S
X_S
XS分别表示高层查询图像特征和高层支持图像特征,有公式如下:
X
Q
=
F
(
I
Q
)
,
X
S
=
F
(
I
S
)
⊙
M
S
X_Q=\mathcal{F}\left( I_Q \right) ,X_S=\mathcal{F}\left( I_S \right) \odot M_S
XQ=F(IQ),XS=F(IS)⊙MS
⊙
\odot
⊙表示的是Hadamard积,这样做可以通过置0的方式将支持图像的背景部分移除。
假定作为 X Q X_Q XQ先验掩码的 Y Q Y_Q YQ能够揭示 X Q X_Q XQ和 X S X_S XS之间的像素对应关系, X Q X_Q XQ中具有高值的像素意味着这个像素在支持特征 X S X_S XS中至少有一个像素与之具有高对应性。因此它很可能在查询图像的目标区域。且通过将支持特征的背景设置为零,查询特征的像素与支持特征的背景没有对应关系,它们只与前景目标区域相关。
如何获取先验掩码
Y
Q
Y_Q
YQ,计算
X
Q
X_Q
XQ和
X
S
X_S
XS每个像素间的余弦相似度
c
o
s
(
x
q
,
x
S
)
cos(x_q,x_S)
cos(xq,xS):

将所有支持像素间的最大相似度作为响应值
c
q
c_q
cq:
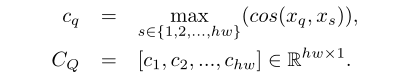
将
C
Q
C_Q
CQ转换为
h
×
w
h×w
h×w的形式,并对其做归一化处理即得到先验掩码
Y
Q
Y_Q
YQ
这一方法的关键在于利用固定的高级特征生成先验掩码,从大小为
h
w
×
h
w
hw × hw
hw×hw的相似矩阵中取最大值。
特征增强模块:
现有方法大多使用全局平均池化来从支持图像中提取类特征。然而,由于查询目标的区域可能比支持样本大得多或小得多,支持图像上的全局平均池化会导致空间信息不一致。因此,使用全局池化支持特性直接匹配查询特性的每个像素并不理想。
PPM或ASPP可以为特征提供多尺度的空间信息,但是它们并不算最好的,原因有二:1)它们是为最后合并的特性提供空间信息而没有在每个特定的尺度上进行细化处理;2)忽略了不同尺度的层次关系
为了解决上述问题,本文对多尺度解构进行分解,提出了一种特征增强模块(FEM)。主要思路:1)在每个尺度上,查询特征与支持特征和先验掩码进行水平交互;2)垂直利用层次关系,通过自顶向下的信息路径从细粒度特征中提取基本信息来丰富粗粒度特征。在横向和纵向优化后,收集投影成不同尺度的特征,形成新的查询特征。
FEM的具体实现过程:
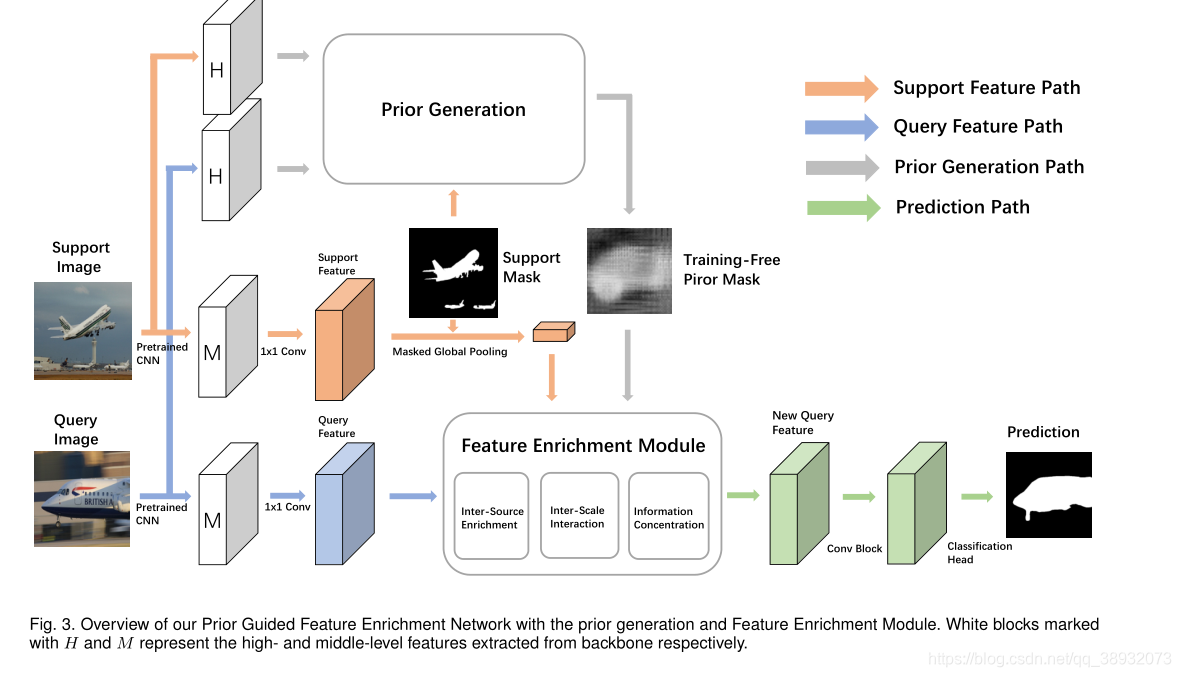
FEM主要分为了三个子模块:1)Inter-Source Enrichment-----首先对不同规模的投影进行输入,然后在每个规模中独立地将查询特性与支持特性和优先掩码进行交互;2)Inter-scale interaction-----有选择地在不同规模的合并的查询–支持特性之间传递基本信息;3)Information concentration------合并不同尺度的特征,最终产生细化的查询特征。
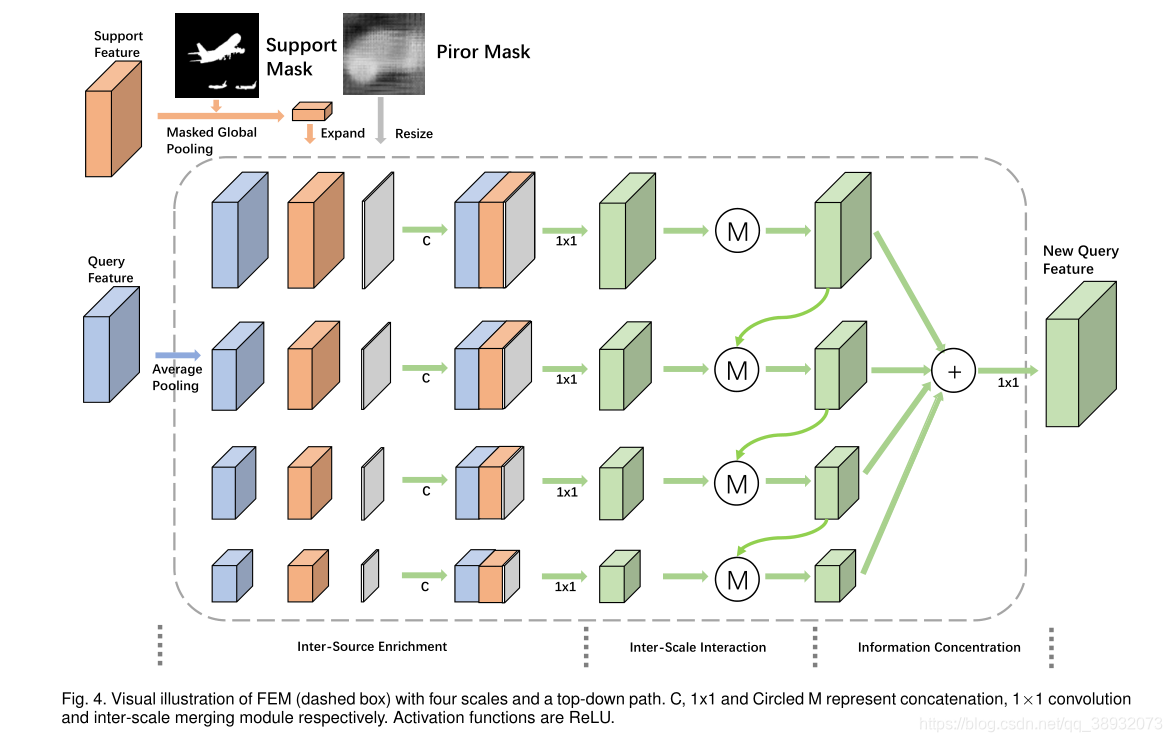
Inter-Source Enrichment中利用平均池化产生不同尺度的特征图,再进行合并:
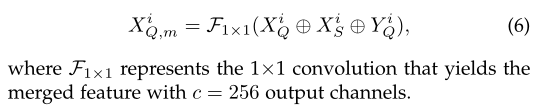
Inter-Scale Interaction中需要注意的一点是下采样特征映射可能导致微小对象消失。自适应地从较细的特征向较粗的特征传递信息的自顶向下路径有助于在我们的特征丰富模块中建立层次关系。交互不仅是在每个尺度的查询和支持特征之间(水平),而且是在不同尺度的合并特性之间(垂直),这有利于整体性能。
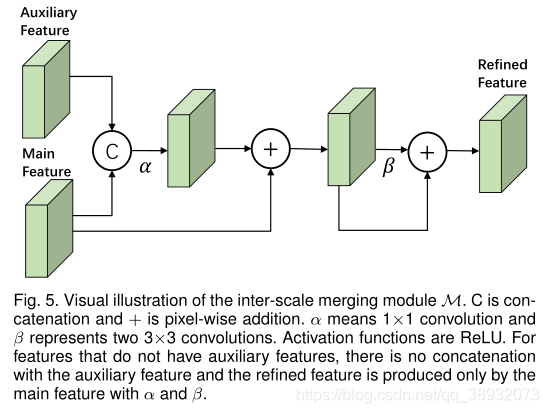
损失函数设计:
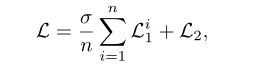
其中
L
1
i
(
i
∈
{
1
,
2
,
.
.
.
,
n
}
)
\mathcal{L}_{1}^{i}\left( i\in \left\{ 1,2,...,n \right\} \right)
L1i(i∈{1,2,...,n})表示中间的监督损失,也就是Inter-Scale Interaction输出部分的损失,
L
2
\mathcal{L}_{2}
L2表示的则是最终预测结果的损失。
σ
\sigma
σ用来平衡中间监督的权重。
实验结果
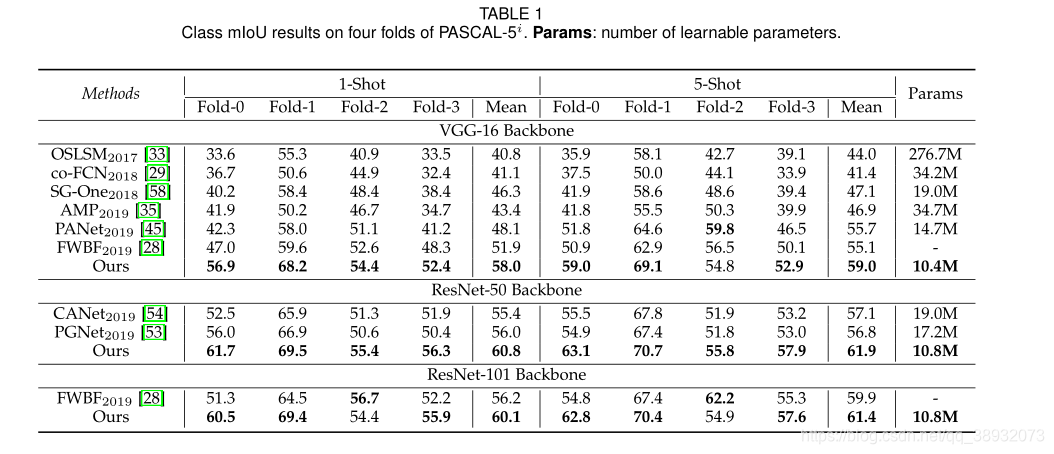
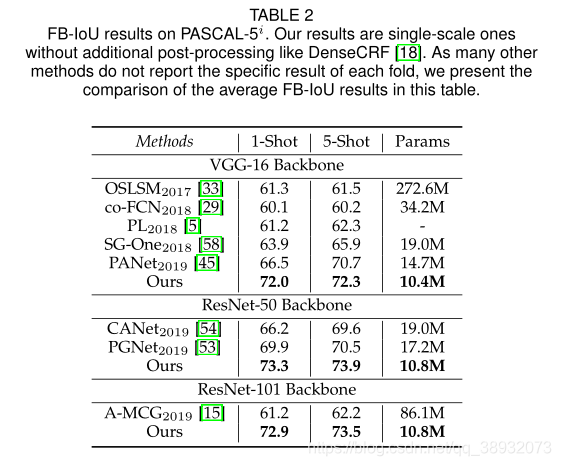
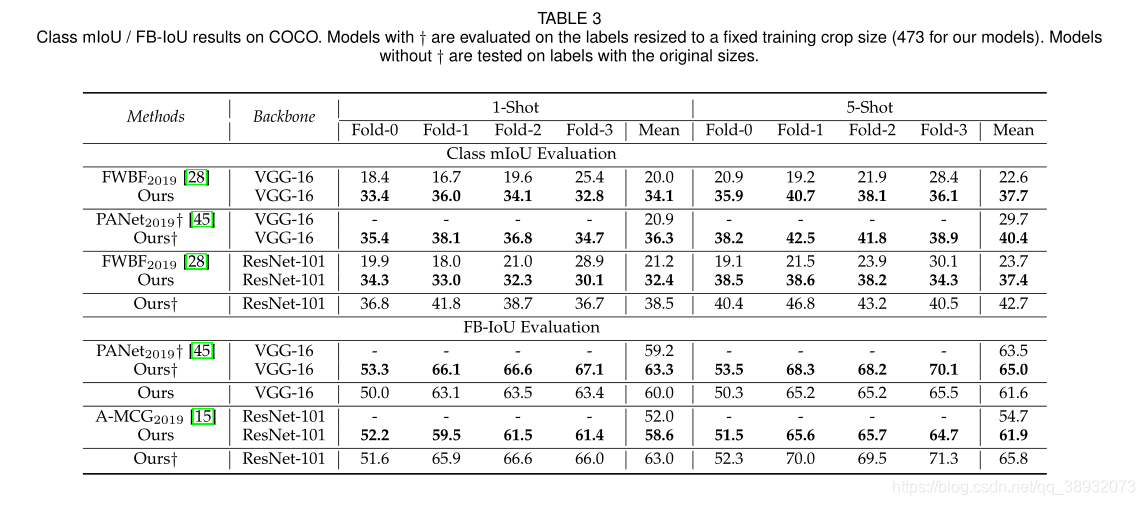
PFENet再PASCAL-5i数据集上达到了新的SOTA水平,在COCO数据集上mIoU比以往的先进方法都要高出10个点。与PANet相比,在FB-IoU上的性能优势相对于COCO上的mIoU要小一些,因为FB-IoU偏向于背景和类,而类覆盖了很大一部分前景区域。值得注意的是,PFENet以最少的可学习参数(基于VGG的模型为10.4M,基于ResNet的模型为10.8M)获得了最佳性能。

消融实验
针对Inter-Scale Interaction实验结果表明,使用较细的特征(辅助特征)为粗特征(主要特征)提供附加信息比使用粗特征(辅助特征)细化较细的特征(主要特征)更有效。这是因为在信息集中的后期,如果目标对象在小范围内消失,粗特征就不足以针对查询类,也就是在这一部分自顶向下连接的方法要优于自下向顶的方法。
同时消融实验针对先验掩码生成的有效性进行了分析,以往的方法(例如PANet,SG-One)在掩码生成过程中包含可学习的组件,这导致生成的掩码在训练过程中偏向于基类(比如一副图有很多个瓶子,它可能只会倾向于最明显的那个瓶子,但这可能并不是我们想要的结果)。其次,由于支持特征中最相关的信息在池化操作中可能会被不相关的信息淹没,因此支持特征的掩码平均池化会导致判别损失。例如,“猫和狗”的区分区域主要在头部附近。主体具有相似的特征(例如,有尾四足动物),这使得掩码全局平均池化(masked GAP)所产生的表示失去了支持样本中包含的判别性信息。
结论
本文利用所提出的先验生成方法和特征增强模块,提出了先验引导特征增强网络(PFENet)。先验生成方法通过利用对预先训练好的高级特征的余弦相似度计算来提高性能。先验掩码鼓励模型更好地对查询目标进行定位,而不会失去泛化能力。FEM通过中间监督和条件特征选择,自适应地融合多尺度的查询和支持特征,解决了空间不一致性问题。通过这些模块,PFENet在PASCAL-5i和COCO数据集上获得了最新的结果,而没有增加太多的模型尺寸和显著的效率损失。zero shot 场景的实验进一步证明了我们工作的鲁棒性。未来可能的工作包括将这两种设计扩展到少镜头目标检测和少镜头实例分割。

















 1490
1490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









