







论文地址:SG-One: Similarity Guidance Network for One-Shot Semantic Segmentation
Code地址:SG-One
Abstract
小样本图像语义分割是一项具有挑战性的任务,即仅使用一个注释示例作为监督,从未见过的类别中识别目标区域。在本文中,我们提出了一种简单而有效的相似性引导网络来解决小样本分割问题。我们的目标是参考同一类别的一个密集标记的支持图像,来预测一个查询图像的分割掩码。为了获得支持图像的鲁棒代表性特征,我们首先采用掩码平均池化(masked average pooling)策略,通过只考虑支持图像的像素来生成引导特征。然后利用余弦相似度建立引导特征与查询图像像素特征之间的关系。使用这种方式,可以利用生成的相似图中的可能性嵌入来指导分割对象的过程。此外,我们的SG One是一个统一的框架,可以在一个网络中高效地处理支持和查询图像,并以端到端的方式进行学习。我们在Pascal VOC 2012上进行了大量实验。特别是,我们的SG One达到了46分的mIoU分数。3%,超过基线方法。
INTRODUCTION
目前的网络都是基于孪生框架,简单地说,训练一对并行网络,分别提取标记支持图像和查询图像的特征。然后融合这些特征,生成目标对象的概率图。网络的目的实际上是在高层特征空间中学习带密集标注的支持图像和查询图像之间的关系。
- 这些方法的优点是,可以直接利用观察到的类的训练参数来测试看不见的类,而无需进行微调。
- 然而,这些方法也存在一些缺点:1)参数使用两个平行的网络冗余,容易过度拟合,导致浪费计算资源;2)仅仅通过乘法来结合支持图像和查询图像不足以指导网络进行高质量的分割。
为了克服上述方法的缺点, 本文提出了一种用于一次性语义切分的相似性引导网络(SG-one)。SG One的基本思想是通过有效地结合支持对象和查询图像特征之间的像素相似性来指导分割过程。特别地,我们首先提取输入的支撑集图像和查询图像的高级特征映射。高级特征(High-level features)通常是抽象的,且属于同一类别对象的像素的嵌入在高级特征中非常接近。
背景像素的嵌入通常被抑制,并且这些嵌入表达与前景对象的嵌入表达距离较远。因此,我们提出了一种掩码平均池化方法来从支持图像中获取表达向量。掩码平均池化可以通过排除背景噪声的影响,提取出与对象相关的特征。然后,我们通过计算每个支持图像表达向量和查询图像在每个像素上的余弦相似度来得到引导映射。如果查询图像中对象像素对应的特征向量与支持图像中提出的表达向量接近,那么引导映射的对应得分较高。否则,如果像素属于背景,引导映射的分数就会很低。所生成的引导图被用于向分割过程提供所需区域的引导信息。具体的说,就是查询图像的位置特征向量乘以相应的相似度值。该策略在支持图像及其掩码的引导下,能够有效激活查询图像的目标对象区域。
与之前的技术相比,我们的方法提供了多种吸引人的优势,例如OSLSM【15】和co FCN【16】。
- 首先,OSLSM和co-FCN通过改变网络的输入结构或输入图像的统计分布来合并支持图像的分割模板。不同的是,我们使用屏蔽平均池操作从中间特征映射中提取代表向量,而不是改变输入。我们的方法既不会损害网络的输入结构,也不会损害输入数据的统计。仅平均对象区域可以避免背景的影响。否则,当背景像素占主导地位时,学习的特征将偏向背景内容。
- 其次,OSLSM和co-FCN直接将代表向量乘以查询图像的特征映射,预测分割模板。SG-One计算代表向量与查询图像每个像素处的特征之间的相似度,并利用相似度图指导分割分支找到目标对象区域。我们的方法在分割查询图像的过程中具有优越性。
- 第三,OSLSM和co FCN都分别采用一对VGGnet-16网络来处理支持和查询图像。我们使用统一的网络来同时处理它们。统一网络使用更少的参数,以减少计算负担,并提高在测试中推广到新类的能力。
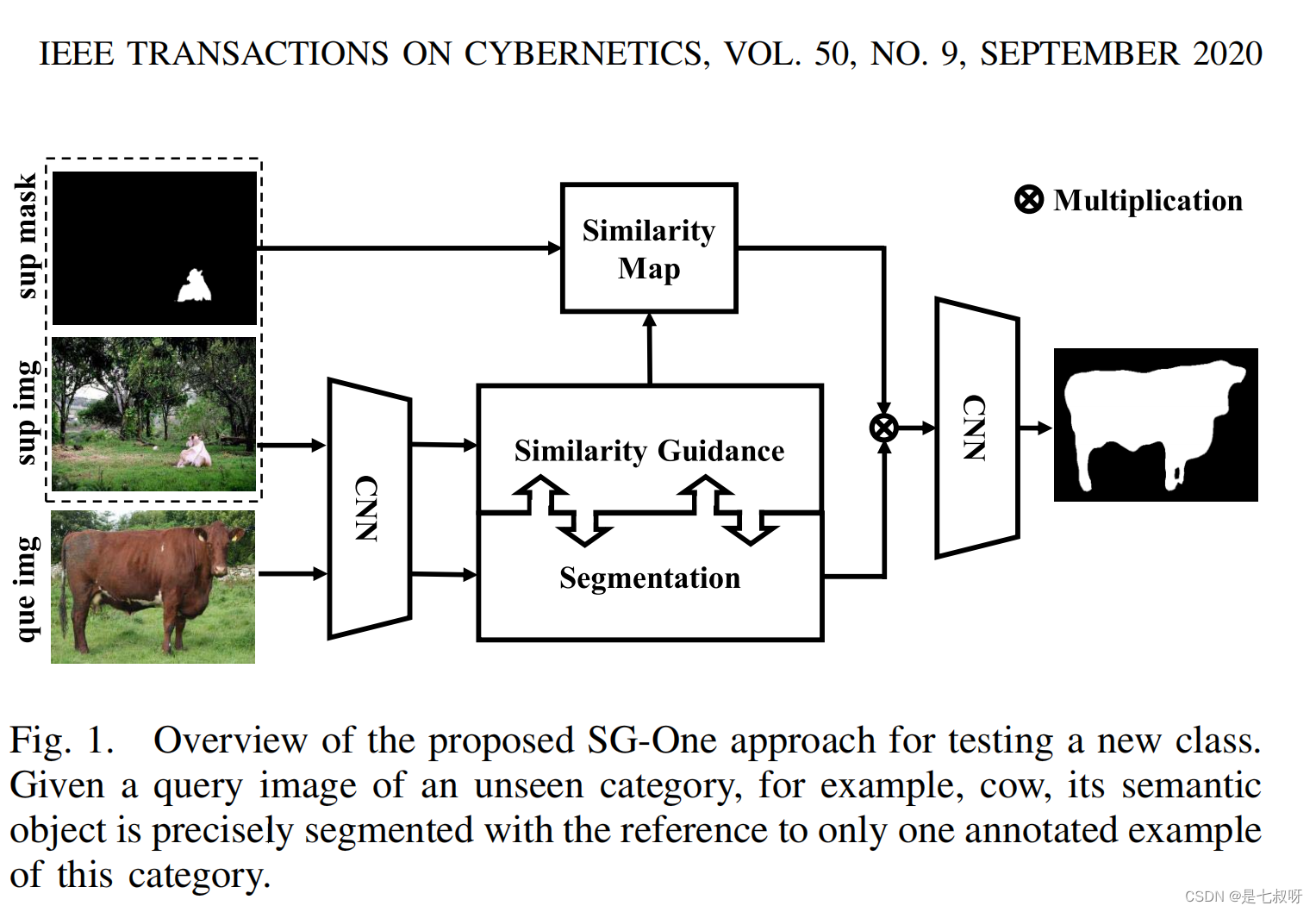
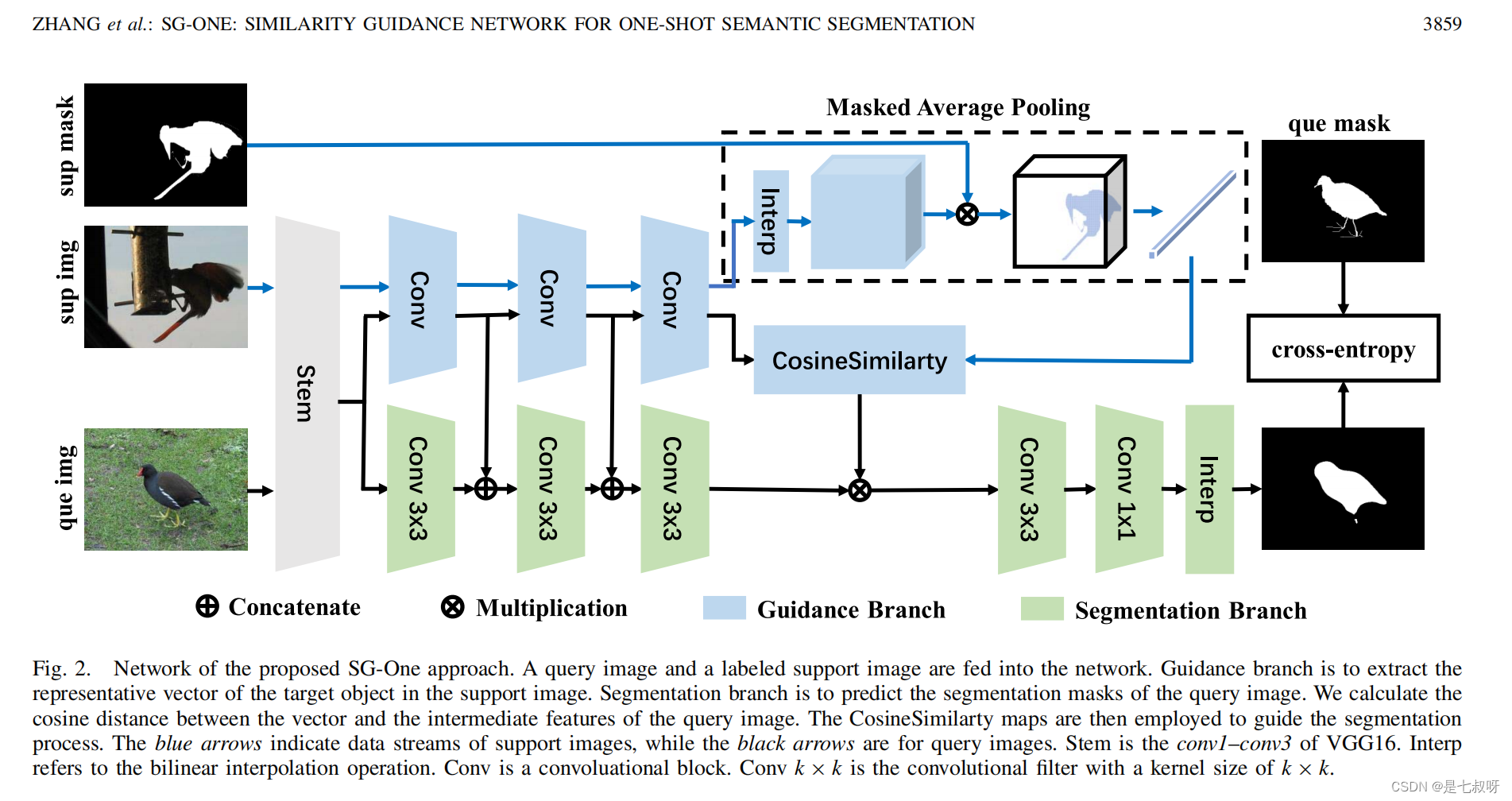
图【将查询图像和标记的支持图像馈送到网络中。引导分支是提取目标对象在支持向量图像中的代表向量。分割分支是预测查询图像的分割掩码。我们计算向量和查询图像中间特征之间的余弦距离。然后利用余弦相似映射来指导分割过程。蓝色箭头表示支持图像的数据流,而黑色箭头表示查询图像。Stem是VGG16的conv1–conv3。Interp是指双线性插值操作。Conv是一个循环块。Conv k×k是核大小为k×k的卷积滤波器。】
SG One的概述如上图所示。我们应用两个分支,即相似性引导分支和分割分支,来生成引导图和分割掩膜。我们通过推进支撑集图像和查询集图像通过引导分支来计算相似性图,查询集图像还通过分割分支来计算分割掩膜。相似性图来充当引导注意力图,其中目标区域得分较高,而背景区域得分较低。分割过程由相似图引导,以获得精确的目标区域。训练阶段结束后,SG One网络可以在不改变参数的情况下预测新类的分割掩码。例如,处理不可见类(例如cow)的查询图像,以发现仅提供一个带注释的支持图像的属于cow的像素。
总而言之,我们的主要贡献有三个方面:
- 1) 我们建议在不改变网络输入结构的情况下,使用掩码平均池化生成鲁棒的对象相关代表向量,以合并上下文信息。
- 2) 我们使用展示向量和查询特征之间的余弦相似度生成像素级引导,用于预测分割掩码。
- 3) 我们提出了一个用于处理支持和查询图像的统一网络。我们的网络实现了46的交叉验证mIoU。在PASCAL-5idataset上,单次分割设置为3%,超过了基线方法。
RELA TED WORK
OSS旨在对给定图像中的每个像素进行分类,以区分不同的对象或内容。以密集注释作为监管的OSS在精确识别各种对象方面取得了巨大成功【18】–【25】。近年来,大多数性能优异的工作都是基于深度卷积网络的。FCN[2]和U-Net[1]放弃了完全连接的层,建议仅使用卷积层来保持像素的相对位置。基于FCN的优点,Chen等人[26],[27]提出的DeepLab是分割的最佳算法之一。与大卷积核方法相比,它采用扩展卷积运算(dilated convolution operations)来增加感受野,同时节省参数。He等人[3]提出的分割掩码和检测边界框可以使用统一网络同时预测。
METHODOLOGY
Proposed Model
支持图像和掩码对(pairs)通常被编码为代表向量。OSLSM建议通过增加二进制掩码来支持图像,从而从支持图像中删除背景像素。co-FCN提出将支持图像与正负掩码连接,构建五个通道的输入块。然而,这两种方法都有两个缺点。首先,将背景像素擦除为零将改变支持图像集的统计分布。如果使用统一的网络对查询图像和擦除后的支持图像进行处理,输入数据的方差将大大增加。其次,将支持图像与其掩码拼接在一起,破坏了网络的输入结构,也会阻碍统一网络的实现。

平均掩码池化代码解读
将输出的支撑集图片特征outA_pos上采样到和mask一个大小,之后相乘求和得到原型向量
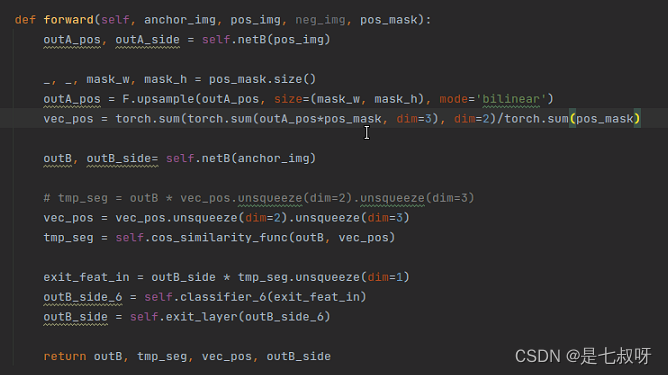
- 首先使用
torch.sum(outA_pos*pos_mask, dim=3)将按行的对应的列求和(每一行w对应h个列),消去索引为3的最后一个维度h。 - 之后将剩余的三个维度(b, c, w)
torch.sum(torch.sum(outA_pos*pos_mask, dim=3), dim=2)消去索引为2的目前的最后一个维度。 - 最后将得到的两个维度的(b,c)除以
torch.sum(pos_mask)(直接全部求和得到一个值),得到一个二维(b,c)的向量vec_pos

相似性引导代码解读
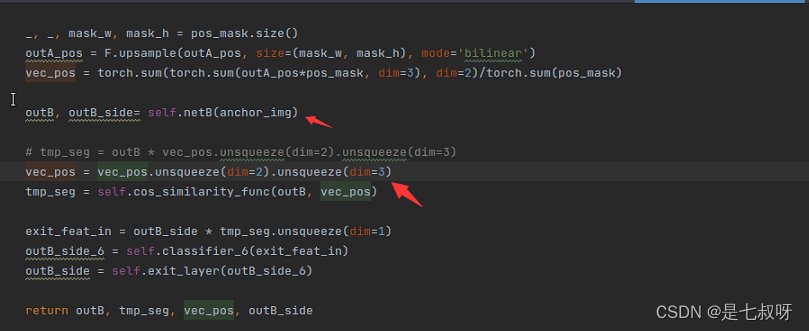
得到查询集特征outB,之后不做上采样、直接将平均掩码池化得到的向量unsqueeze出两个维度到(b,c,1,1),直接使用函数tmp_seg = self.cos_similarity_func(outB, vec_pos)求相似性tmp_seg,其中:
self.cos_similarity_func = nn.CosineSimilarity()
接着exit_feat_in = outB_side * tmp_seg.unsqueeze(dim=1)将得到的tmp_seg unsqueeze后与outB_side相乘 * ,送入33卷积relu分类器outB_side_6 = self.classifier_6(exit_feat_in),和11卷积outB_side = self.exit_layer(outB_side_6)得到最新的outB_side,定义如下:
self.classifier_6 = nn.Sequential(
nn.Conv2d(128, 128, kernel_size=3, dilation=1, padding=1), #fc6
nn.ReLU(inplace=True)
)
self.exit_layer = nn.Conv2d(128, 2, kernel_size=1, padding=1)
至此,前向传播完毕。
损失计算反向传播
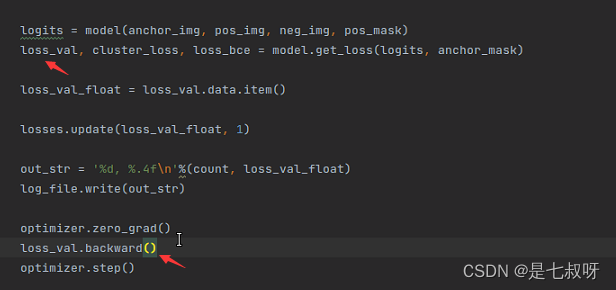
主函数中:
logits = model(anchor_img, pos_img, neg_img, pos_mask)
loss_val, cluster_loss, loss_bce = model.get_loss(logits, anchor_mask)
上采样计算损失函数:
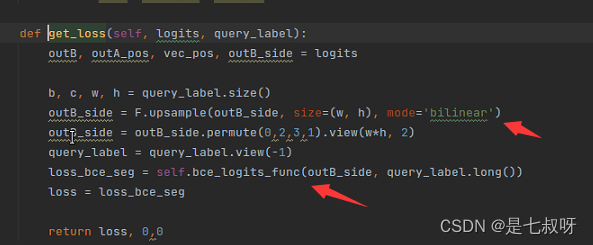
使用loss_val反向传播更新参数:
vgg16_sg
参考:PyTorch之VGG16网络结构详解以及源码解读
vgg的网络结构:
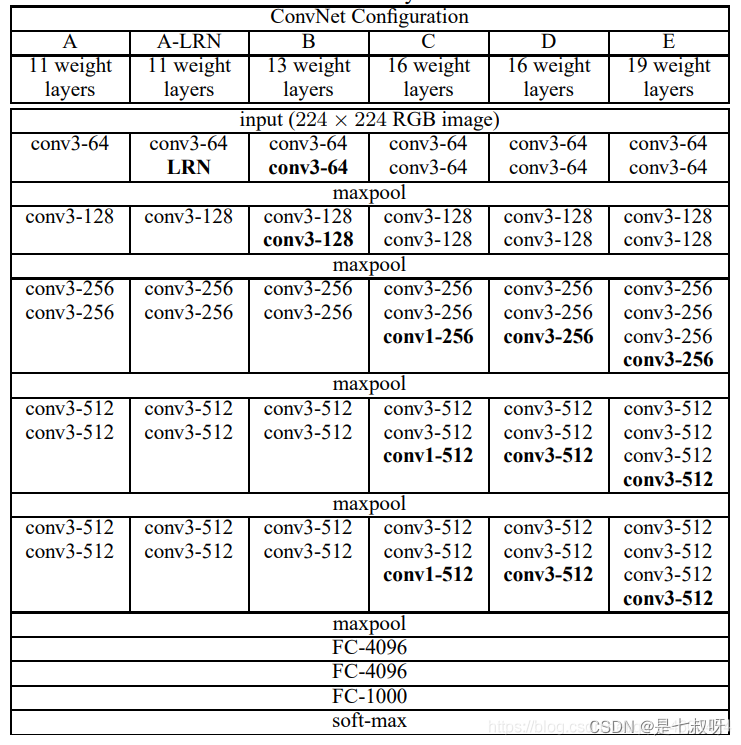
vgg_sg的双分支代码:
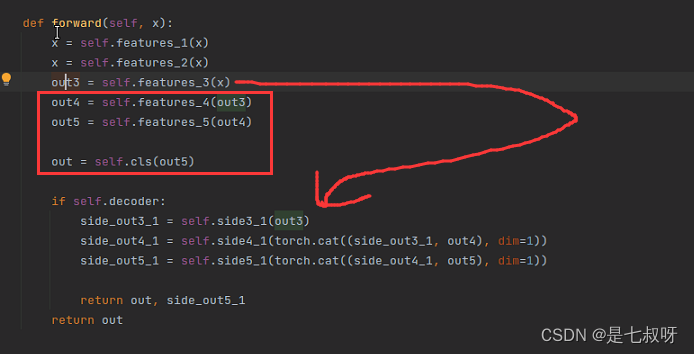

对应网络结构中的双分支:
SG-One主要包含三个部分,即1)stem;2)相似性指导;3)分割分支。stem其实就是个用来提取特征的全卷积网络(ResNet,VGG啥的)。将提取的查询图像和支持图像的特征输入相似指导分支。我们将参考对象的特征与查询图像的特征相结合,利用该分支生成相似引导图。对于支持图像的特征,我们实现了三个卷积块来提取高度抽象和语义的特征,然后是一个掩码平均池化来获取代表向量。提取的支持图像的代表向量应包含特定对象的高级语义特征。对于查询图像的特征,我们重用这三个块,并利用余弦相似层计算查询图像的每个像素处的代表向量和特征之间的相似度。分割分支用于在生成的相似图的指导下发现查询图像的目标对象区域。
CONCLUSION
我们提出SG-One可以在仅使用一个标注的样本情况下有效地分割新类别的语义像素。我们提出了掩码平均池化的方法来提取更健壮的对象相关的代表性特征。大量的实验表明,掩蔽平均池化方法更方便,能够结合上下文信息来学习更好的代表性向量。我们通过使用一个统一的网络来减少模型参数以降低过拟合的风险。我们所提出的网络同样可以直接应用于多分类图像的分割。我们提出了一个纯端到端网络,它不需要任何预处理或后处理步骤。更重要的是,SG-One提高了One-Shot语义分割的性能,超越了基准方法。最后,我们分析了一次性视频分割和我们的一次性图像语义分割问题之间的关系。实验表明,在公平的比较条件下,所提出的SG-One算法在视频对象分割方面具有优越性。与此形成鲜明对比的是,一个One-Shot图像分割任务提供的图像的目标对象或背景并不连续。查询图像中的对象和背景与支持图像存在较大差异。例如,在我们的One-Shot图像分割任务中,我们可能需要分割一个站在草地上的老人和一个躺在床上的小女孩,因为他们都属于同一类别,即是一个人。其次,得益于视频中的序列线索,视频分割方法可以从连续的帧中计算出帧间的相似度,并通过在线更新提高性能。














 1859
1859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









