







挖掘潜在类以实现Few-Shot分割
论文地址
这篇文章读起来有点抽象,还是以原文为主。
摘要
Few-Shot分割(FSS)的目的是在只给出少量标注样本的情况下分割未见类。现有的方法存在特征破坏的问题,即在训练阶段将潜在的新类作为背景。我们的方法旨在缓解这一问题,并增强潜在新类的特征嵌入。我们提出了一种新的联合训练框架,在传统的支持查询对的训练过程基础上,我们引入了一个额外的挖掘分支,通过可转移的子簇(transferable sub-clusters)来挖掘潜在的新类,并在背景和前景类别上引入了一种新的修正技术,以加强更稳定的模型。除此之外,我们的可转移子簇还能够利用额外的未标记数据进行进一步的特征增强。
存在的问题及解决方案
过去的FSS方法取得了不错的效果,但这些方法很少关注FSS的固有问题,即特征破坏和原型偏差问题:1)特征破坏问题是在典型的FSS中作为背景学习时,潜在新类的嵌入被过度平滑。如图1所示,在每个episode中我们只会关注当前的支持类,潜在的新类(person)被错误地视为背景。2)原型偏差问题是由few shot不能模拟真实的类统计数据而产生的,这使得仅仅利用当前的原型来估计支持是次优的,在我们的工作中,我们的目标是利用潜在的新类并使得原型具有更小的偏差,以缩小few shot很真实统计数据间的差异。

在我们的工作中,我们提出了一种基于度量学习框架的新的潜在类挖掘策略和一种新的原型修正技术。我们认为每个像素在训练集中都很重要,这意味着即使是有临时注释的背景也可以包含新的类,显式挖掘可以增强特征识别。特别的是,我们的辅助分支通过从标注的基类转移语义子簇从训练集的背景中挖掘潜在类。不仅如此,我们的方法还可以利用额外的未标记数据进行进一步的特征增强。请注意,我们的方法也很适合更现实的设置,在这些设置中,由于注释的劳动力有限,或者在标记时不需要或不发现新类,可能存在大量额外的新类。另一方面,我们提出了一种新的技术来校正前景类和背景类的原型。如前所述,我们假设背景携带了比支持先验更多的信息,我们提出通过移动平均的方法利用整个训练集来对背景建模。
方法

我们构建了一个统一的框架,通过对支持查询对的情景训练进行元学习,同时通过辅助监督从背景中挖掘潜在的新类。在这个联合训练框架下,我们的方法既可以学习可迁移的元知识,又可以学习有用的嵌入知识。为了获得对潜在类的辅助监督,我们使用基类转移的代表子簇对训练图像进行标注。离线标注过程只需要进行一次且整个训练阶段伪掩码保持一致。
训练过程中,首先对支持图像和查询图像做特征提取,然后将每个查询特征与当前支持类和背景类原型进行比较,这里的分割主要是为了判断二分类是支持类或不是。在我们的工作中,额外的监督来自训练集中额外图像的伪标签,这一过程主要用于多类分割。总体的优化目标为:
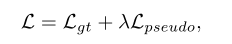
此外,为了使支持原型的估计更稳定、信息量更大,我们充分利用训练集中的统计信息,分别对背景原型和前景原型进行校正。具体来说,背景原型用全局背景原型进行修正,训练过程中对全局原型进行维护和更新,以捕捉各个场景的共同特征;前景原型只在推理过程中使用训练集中最相关的区域进行修正。
挖掘和学习潜在类
它可以概括为一个两阶段的过程:1)伪标记潜在类,2)学习潜在类。假设来自同一领域的前景对象之间存在或多或少的共性,通过基类转移的具有代表性的子簇来标注潜在类是可行的。例如,马和牛的形状可能有共同之处,因为它们都是四条腿的动物。我们通过对前景对象进行分组并生成语义子簇来获得这些可转移的共性。然后,训练图像被用于转移元知识的原始ground-truth掩码和生成的用于在潜在新类上判别嵌入信息的伪掩码进行联合监督。
用有代表性的子集群进行注释
提取代表性的子簇:
给出一个预先训练好的嵌入网络,我们采用掩码平均池化(MAP)策略来获得图像中特定类别的整体描述。第
i
i
i个图像的第
c
c
c个类的原型可表示为:
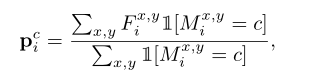
P
f
g
\mathcal{P}_{fg}
Pfg和
P
b
g
\mathcal{P}_{bg}
Pbg表示在所有标注训练图像中的前景和背景类集合。使用K-means聚类算法在
P
f
g
\mathcal{P}_{fg}
Pfg在产生
K
K
K个最具代表性的子簇(或者说聚类中心)
P
c
l
u
s
t
e
r
\mathcal{P}_{cluster}
Pcluster,它被用于捕捉各种前景对象之间的共性。另一方面,考虑到不同图像的背景差异很大,我们通过平均所有
P
b
g
\mathcal{P}_{bg}
Pbg中的原型来得到单个背景原型
p
b
g
p_{bg}
pbg,用作背景的全局描述。一个由
K
+
1
K+1
K+1个代表性子簇组成的集合
P
r
e
p
\mathcal{P}_{rep}
Prep由
P
c
l
u
s
t
e
r
\mathcal{P}_{cluster}
Pcluster和
p
b
g
p_{bg}
pbg组合而成,可以被视为训练集中前景和背景类的高级表述。
注释训练图像
训练图像 I I I的提取特征为 F F F,伪掩码为 M p M^p Mp,接下来,我们将演示为什么以及如何根据最近邻对每个像素进行分类。
我们假设
I
I
I的物体和前景原型
P
c
l
u
s
t
e
r
\mathcal{P}_{cluster}
Pcluster共享某些特性,同时不存在物体的区域要更加接近背景原型
p
b
g
p_{bg}
pbg,将
F
(
x
,
y
)
F(x,y)
F(x,y)分为
K
+
1
K+1
K+1类中的一类,公式表示为:
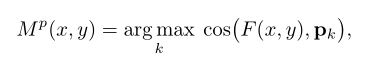
其中
p
k
∈
P
r
e
p
p_k\in \mathcal{P}_{rep}
pk∈Prep
获得的伪掩码中的标签最多包含
K
+
1
K+1
K+1类。需要注意的是,除了背景类之外,其他的K个聚类并不代表任何具体的对象或类,但它们可能代表实际存在的类别的几个典型特征。所生成的伪掩码将整个场景分割成多个具有内在语义一致性的区域,可以用来学习更多的判别特征。
联合训练
给定带伪掩码和ground-truth掩码的训练图像,我们使用这两种监督源一起训练编码网络。构造一个由包含ground-truth的图像和包含伪掩码的额外采样图像的小批量。
对于带有ground-truth mask的图像,采用情景训练的元学习范式学习元知识,快速适应新类。在我们的模型中,我们采用了非参数匹配机制。使用余弦相似函数来度量查询图像中的每个特征与支持集的前景和背景原型之间的相似度。查询图像上的损失函数可以表示为:
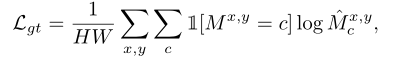
得分图可定义为:
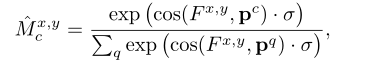
对于带有伪掩码标注的图像,在编码网络后增加一个辅助解码分支,直接学习伪掩码。
指数移动平均:在我们的实验中,我们发现,在伪掩码的额外监督下,模型收敛得更快。而有噪声的伪掩码往往会在后期影响性能。因此,我们对模型参数保持指数移动平均,以获得更稳定的模型进行评价。
修正支持原型
全局背景原型
Few-Shot分割的典型做法是从当前支持类的背景区域中提取背景原型。然而,这假设了背景的特征并没有与特定的前景类强共轭。鉴于此,我们建议将目前的支持背景原型
p
b
g
c
u
r
p_{bg}^{cur}
pbgcur和一个更威威稳定的全局背景原型
p
b
g
g
l
o
b
a
l
p_{bg}^{global}
pbgglobal进行整合,它是训练过程中学习到的所有背景原型的指数移动平均。具体来说,在训练过程中通过以下方式迭代更新全局背景原型:
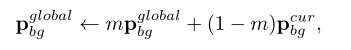
其中
m
m
m为动量系数,默认为0.999
在推理过程中使用类似的方式:
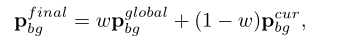
其中
w
w
w设为0.9以获得更为稳定而信息丰富的全局背景,全局背景原型对数据集中的各种场景进行编码,并对当前背景进行良好的校正。我们还尝试了一个离线的全局背景原型,它是通过对最终模型的所有背景特征进行平均而生成的,但是它的性能比在线更新的模型差。这可能是由于训练和测试之间的不一致。
修正前景原型
在推理过程中,我们利用伪标记区域来校正图像集(如训练集)上的前景原型。
给定一个支持图像
I
s
I^s
Is,我们首先通过测量图像嵌入的余弦相似度来选取前N个相关图像。在这个图像池中,通过比较支持前景原型和区域嵌入
p
i
r
p^r_i
pir之间的余弦相似度来选择K个最相关区域,前景原型的修正可表示为:
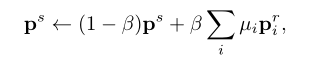
其中
p
i
r
p^r_i
pir是第
i
i
i幅图像中最相关的区域级原型,
μ
i
\mu _i
μi衡量所有区域级原型和支持原型之间的相对相似性
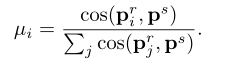
实验结果



结论
在这项工作中,我们通过从背景中挖掘潜在类,从一个新的视角来解决少镜头分割问题,并提出了一个新的框架来学习元知识,以及从ground-truth掩码和伪掩码中挖掘好的嵌入信息。为此,我们提出了一种新的支持原型校正技术。在两个FSS基准上进行了大量的实验,在没有附加条件的情况下,我们的方法可以比以前的方法有很大的优势。此外,通过消融研究以及与先进的自我监督和半监督学习技术的比较,我们的方法可以通过挖掘隐藏在训练数据背后的新类来更好地挖掘训练数据中的知识。















 4248
4248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









