







用于图像分割的单样本学习(BMVC2017)
本文算是小样本学习的经典之作,虽然以现在的角度来看比较粗糙,但仍然值得学习!
本文的方法说白了就是利用高维参数来进行比较(而不是像现今的大多数方法是利用特征匹配的思想),因此依赖于权重哈希来防止过拟合。本文的方法现在基本淘汰,但它无疑开创了小样本分割的先河。
概述
本文从few shot学习中得到启发,提出了一种新的双分支的一次性语义图像分割方法。第一个分支将标记的图像作为输入,并生成参数向量作为输出。第二个分支接受这些参数和一个新图像作为输入,并为新类生成图像的分割掩码作为输出。
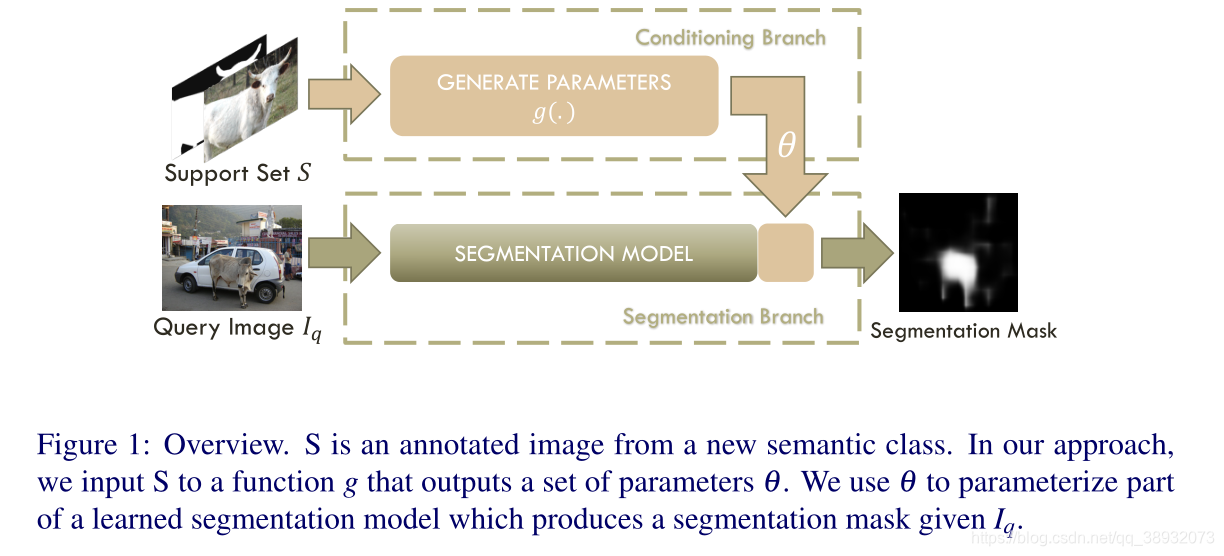
本文贡献:
1)提出了一种新的单样本分割技术,该技术在快速分割的同时优于基线;2)该技术可以在不为新类添加弱标签的情况下做到这一点;3)即使只有少数类具有较强的标注,元学习也能有效地进行;4)在PASCAL上为具有挑战性的k-shot语义分割任务建立了基准。
问题设置
值得注意的是,本论文提出的OSLSM的问题设置在后面的很多小样本分割任务中都被沿用,所以这里给出完整设置。
支持集(support set)设为 S = { ( I s i , Y s i ( l ) ) } i = 1 k S=\left\{ \left( I_{s}^{i},Y_{s}^{i}\left( l \right) \right) \right\} _{i=1}^{k} S={(Isi,Ysi(l))}i=1k,指的是 k k k个图像----掩码对( image-binary mask pairs)的一个小集合(少量样本)。其中 Y s i ∈ L t e s t H × W Y_{s}^{i}\in L_{test}^{H\times W} Ysi∈LtestH×W指的是图像 I s i I_{s}^{i} Isi的分割注释, Y s i ( l ) Y_{s}^{i}\left( l \right) Ysi(l)指的是第 i i i个图像对语义类 l ∈ L t e s t l\in{L_{test}} l∈Ltest的掩码。目的是学习一个模型 f ( I q , S ) f(I_q,S) f(Iq,S),当给定一个支持集 S S S和查询图像 I q I_q Iq时,预测一个对语义类 l l l的掩码 M ^ q \hat{M}_q M^q.
在训练过程中,使用了大量的图像----掩码对 D = { ( I j , Y j ) } j = 1 N D=\left\{ \left( I^j,Y^j \right) \right\} _{j=1}^{N} D={(Ij,Yj)}j=1N,其中 Y j ∈ L t r a i n H × W Y^j\in L_{train}^{H\times W} Yj∈LtrainH×W是训练图像 I j I^{j} Ij的语义分割掩码。在测试过程中查询图像只针对新的语义类进行了注释,也就是 L t r a i n ∩ L t e s t = ⊘ L_{train}\cap L_{test}=\oslash Ltrain∩Ltest=⊘。这是与典型图像分割的关键区别,在典型图像分割中,训练和测试类是相同的。
方法
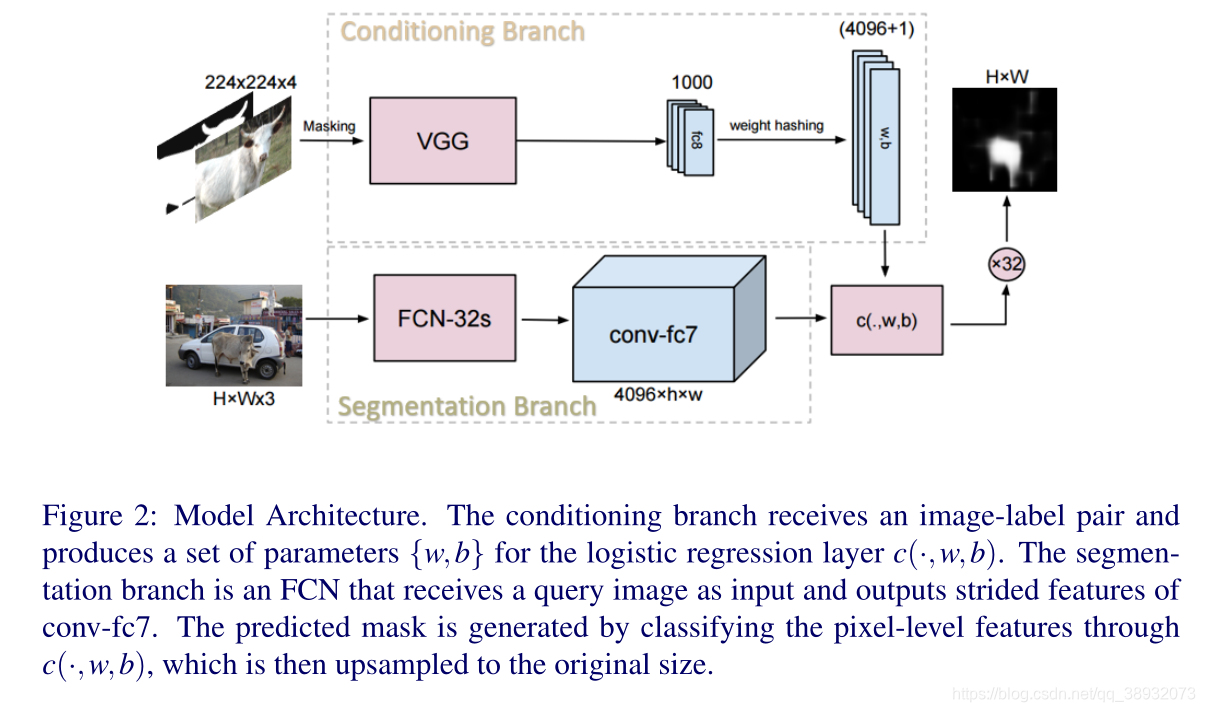
第一个分支输入支持集中带标签的图像,准确地说是输入图像标签对
S
=
(
I
s
,
Y
s
(
l
)
)
S=(I_s,Y_s(l))
S=(Is,Ys(l))来产生一组参数:
w
,
b
=
g
η
(
S
)
w,b=g_{\eta}\left( S \right)
w,b=gη(S)
在另一个分支上,使用参数嵌入函数
ϕ
\phi
ϕ(这里指的似乎就是FCN之类的backbone)来从查询图像
I
q
I_q
Iq中提取特征。设
F
q
=
ϕ
ζ
(
I
q
)
F_q=\phi _{\zeta}\left( I_q \right)
Fq=ϕζ(Iq)是从
I
q
I_q
Iq中提取的feature volume,则
F
q
m
n
F_{q}^{mn}
Fqmn指的是空间位置
(
m
,
n
)
(m,n)
(m,n)上的特征向量。然后使用第一层的参数对特征进行像素级逻辑回归,得到最终的mask.
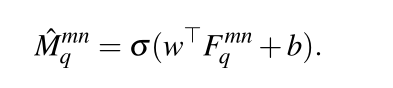
其中
σ
(
⋅
)
\sigma \left( \cdot \right)
σ(⋅)指的是sigmoid函数,
M
^
q
m
n
\hat{M}_q^{mn}
M^qmn表示在坐标
(
m
,
n
)
(m,n)
(m,n)处的预测掩码值。最后将预测掩码通过双边线性插值的方式进行上采样,恢复到原图尺寸,然后以0.5为阈值对查询图片进行掩码操作得到分割图像。
损失函数
这一损失函数的目的是最大化预测对ground-truth mask的对数似然

其中
η
\eta
η和
ζ
\zeta
ζ指的是两个分支结构的网络参数。
实验结果
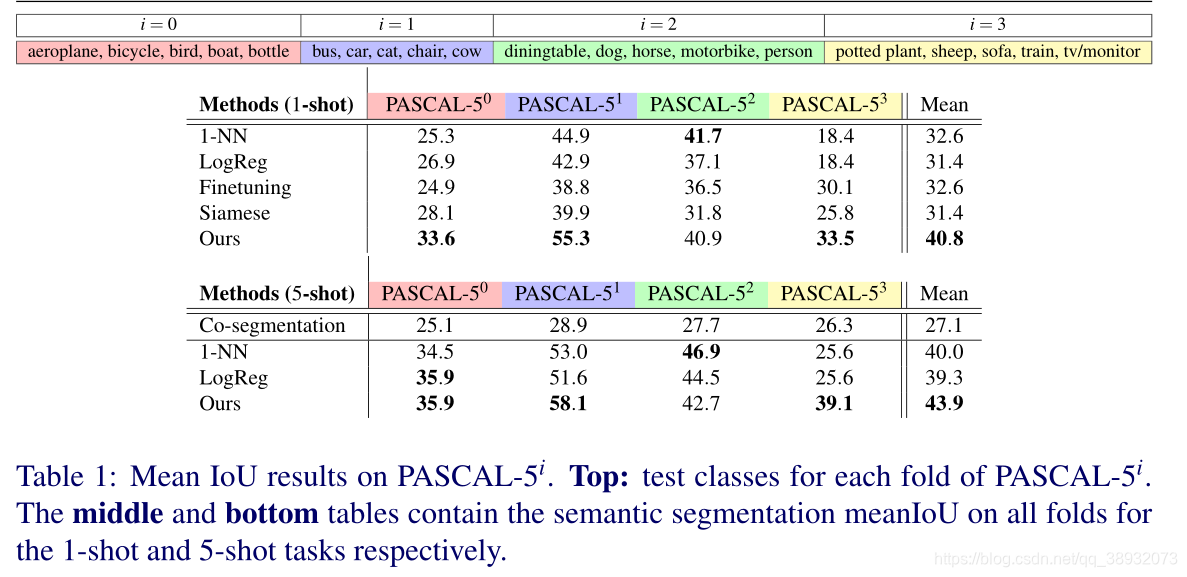
结论
本文提出了一种新的图像分割体系结构来解决这一问题。我们的架构学习学习一个集成分类器,并使用它对查询图像中的像素进行分类。综合实验表明,该算法具有明显的优越性。所提出的方法比其他基准要快得多,并且占用的内存也更少。

















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









