







Abstract
特征金字塔是识别系统中用于检测不同尺度目标的基本组成部分。但最近的深度学习对象检测器避免了金字塔表示,部分原因是它们是计算和内存密集型的。在本文中,我们利用深层卷积网络固有的多尺度金字塔层次结构来构造具有边界额外成本的特征金字塔。开发了一种具有横向连接的自顶向下体系结构,用于在所有尺度上构建高级语义特征图。这种称为特征金字塔网络(FPN)的体系结构作为通用特征提取器,在一些应用中展现了显著的提升。在一个基础的更快的R-CNN系统中使用FPN,我们的方法在COCO检测基准上实现了sota的单模型结果,无需任何提示,超过了所有现有的单模型条目,包括COCO 2016挑战赛优胜者的条目。此外,我们的方法可以在GPU上以6 FPS的速度运行,因此是一种实用且精确的多尺度目标检测解决方案。代码将公开提供。
Feature Pyramid Networks
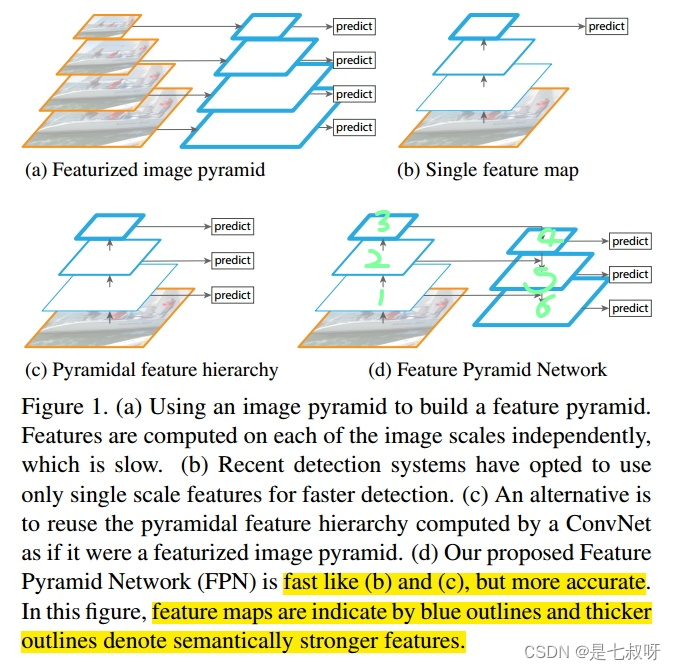
- 识别不同大小的物体是计算机视觉中的一个基本挑战,我们常用的解决方案是构造多尺度金字塔。
- (b)学者们发现我们可以利用卷积网络本身的特性,即对原始图像进行卷积和池化操作,通过这种操作我们可以获得不同尺寸的feature map,这样其实就类似于在图像的特征空间中构造金字塔。实验表明,浅层的网络更关注于细节信息,高层的网络更关注于语义信息,而高层的语义信息能够帮助我们准确的检测出目标,因此我们可以利用最后一个卷积层上的feature map来进行预测。
这种方法存在于大多数深度网络中,比如VGG、ResNet、Inception,它们都是利用深度网络的最后一层特征来进行分类。这种方法的优点是速度快、需要内存少。它的缺点是我们仅仅关注深层网络中最后一层的特征,却忽略了其它层的特征,但是细节信息可以在一定程度上提升检测的精度。 - (c)图c所示的架构,它的设计思想就是同时利用低层特征和高层特征,分别在不同的层同时进行预测,这是因为我的一幅图像中可能具有多个不同大小的目标,区分不同的目标可能需要不同的特征,对于简单的目标我们仅仅需要浅层的特征就可以检测到它,对于复杂的目标我们就需要利用复杂的特征来检测它。整个过程就是首先在原始图像上面进行深度卷积,然后分别在不同的特征层上面进行预测。它的优点是在不同的层上面输出对应的目标,不需要经过所有的层才输出对应的目标(即对于有些目标来说,不需要进行多余的前向操作),这样可以在一定程度上对网络进行加速操作,同时可以提高算法的检测性能。
它的缺点是获得的特征不鲁棒,都是一些弱特征(因为很多的特征都是从较浅的层获得的)。 - (d)FPN它的架构如图d所示,整个过程如下所示,首先我们在输入的图像上进行深度卷积,然后对Layer2上面的特征进行降维操作(即添加一层1x1的卷积层),对Layer4上面的特征就行上采样操作,使得它们具有相应的尺寸,然后对处理后的Layer2和处理后的Layer4执行加法操作(对应元素相加),将获得的结果输入到Layer5中去。其背后的思路是为了获得一个强语义信息,这样可以提高检测性能。认真的你可能观察到了,
这次我们使用了更深的层来构造特征金字塔,这样做是为了使用更加鲁棒的信息;除此之外,我们将处理过的低层特征和处理过的高层特征进行累加,这样做的目的是因为低层特征可以提供更加准确的位置信息,而多次的降采样和上采样操作使得深层网络的定位信息存在误差,因此我们将其结合其起来使用,这样我们就构建了一个更深的特征金字塔,融合了多层特征信息,并在不同的特征进行输出。这就是上图的详细解释。(个人观点而已)
参考:FPN详解
我们的目标是利用ConvNet的金字塔形特征层次结构,它具有从低级到高级的语义,并构建一个始终具有高级语义的特征金字塔。由此产生的特征金字塔网络是通用的,在本文中,我们主要关注滑动窗口提议器(Region Proposal Network,简称RPN)[29]和基于区域的检测器(Fast R-CNN)[11]。我们还将FPN推广到Sec6中的实例分割中。
我们的方法将任意大小的单尺度图像作为输入,以全卷积的形式在多个levels上按比例输出特征图。这个过程独立于主干卷积体系结构(例如,[19,36,16]),在本文中,我们使用ResNets[16]给出了结果。我们金字塔的构建包括自下而上的路径(bottom-up pathway)、自上而下的路径(top-down pathway)和横向连接(lateral connections),如下所述。
自下而上Bottom-up pathway
自下而上的路径是主干(backbone)ConvNet的前馈计算,它计算由多个尺度的特征映射组成的特征层次,缩放步长为2。通常有许多层生成相同大小的输出地图,我们说这些层处于相同的网络阶段。对于特征金字塔,我们为每个阶段定义一个金字塔级别。我们选择每个阶段最后一层的输出作为特征图的参考集,我们将丰富这些特征图以创建金字塔。这种选择是很自然的,因为每个阶段的最深层应该具有最强大的功能。
具体而言,对于resnet【16】,我们使用每个阶段的最后一个剩余块输出的功能激活。对于conv2、conv3、conv4和conv5输出,我们将这些最后剩余块的输出表示为{C2、C3、C4、C5},并注意到它们相对于输入图像具有{4、8、16、32}像素的跨距。由于conv1占用了大量内存,因此我们没有将其包括在金字塔中。
- 自底向上的过程就是神经网络普通的前向传播过程,特征图经过卷积核计算,通常会越变越小。具体而言,对于ResNets,我们使用每个阶段的最后一个residual block输出的特征激活输出。对于conv2,conv3,conv4和conv5输出,我们将这些最后residual block的输出表示为{C2,C3,C4,C5},并且它们相对于输入图像具有{4, 8, 16, 32} 的步长。由于其庞大的内存占用,我们不会将conv1纳入金字塔中。
自上而下的通道和横向连接Top-down pathway and lateral connections.
- 自上而下的路径通过从更高的金字塔级别对空间上更粗糙但语义上更强的特征映射进行上采样,从而产生更高分辨率的特征。
- 然后,通过横向连接,通过自底向上的路径增强这些特征。每个横向连接合并了自底向上路径和自顶向下路径中相同空间大小的特征图。自底向上的特征映射具有较低的语义级别,但其激活更精确地本地化,因为它的二次采样次数更少。
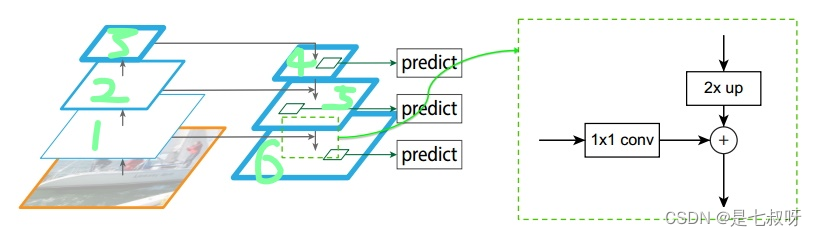
图3显示了构建自上而下特征图的构建块。对于较粗分辨率的特征图,我们将空间分辨率增加2倍(为简单起见,使用最近邻上采样)。
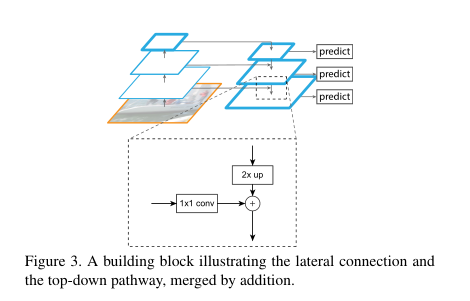
然后,通过元素相加和上采样合并。此过程将迭代,直到生成最精细的分辨率贴图。为了开始迭代,我们只需在C5上附加一个1×1卷积层减少通道数进行横向连接,以生成最粗糙的分辨率贴图。最后,我们在每个合并的地图上附加一个3×3卷积来生成最终的特征地图,以减少上采样的混叠效应。这最后一组特征图被称为{P2、P3、P4、P5},分别对应于空间大小相同的{C2、C3、C4、C5}。
由于金字塔的所有级别都像传统的特征化图像金字塔一样使用共享分类器/回归器,因此我们在所有特征映射中固定了特征维度(通道数,表示为d)。在本文中,我们设置d=256,因此所有额外的卷积层都有256个通道输出。在这些额外的层中没有非线性,我们经验发现这些层的影响很小。简单性是我们设计的核心,我们发现我们的模型对许多设计选择都很稳健。我们对更复杂的块进行了实验(例如,使用多层剩余块作为连接),并观察到稍微好一些的结果。设计更好的连接模块不是本文的重点,因此我们选择上面描述的简单设计。
- 自上而下的过程是把更抽象、语义更强的高层特征图进行上采样(upsampling),而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合(merge)。横向连接的两层特征在空间尺寸相同,这样做可以利用底层定位细节信息。将低分辨率的特征图做2倍上采样(为了简单起见,使用最近邻上采样)。然后通过按元素相加,将上采样映射与相应的自底而上映射合并。这个过程是迭代的,直到生成最终的分辨率图。
- 为了开始迭代,我们只需在C5上附加一个1×1卷积层来生成低分辨率图P5。最后,我们在每个合并的图上附加一个3×3卷积来生成最终的特征映射,这是为了减少上采样的混叠效应。这个最终的特征映射集称为{P2,P3,P4,P5},分别对应于{C2,C3,C4,C5},它们具有相同的尺寸。
- 由于金字塔的所有层次都像传统的特征化图像金字塔一样使用共享分类器/回归器,因此我们在所有特征图中固定特征维度(通道数,记为d)。我们在本文中设置d = 256,因此所有额外的卷积层都有256个通道的输出。















 3855
3855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









