







Anatomy of High-Performance Many-Threaded Matrix Multiplication
* Authors: Tyler M. Smith, Robert Van De Geijn, Mikhail Smelyanskiy, Jeff R. Hammond, Field G. Van Zee
阅读内容总结
1 论文摘要(Abstract)
描述BLIS如何扩展GotoBLAS来实现矩阵乘法(GEMM)。GEMM以前是围绕一个内部内核实现的三个循环,而BLIS在这个内部内核中公开了两个额外的循环,将计算转换为BLIS微内核,这样移植GEMM就变成了为给定的体系结构定制这个微内核的问题。我们将讨论这如何促进更精细的并行性,从而极大地简化了GEMM的多线程,以及并行多个循环的额外机会。
具体来说,展示了随着IBM PowerPC A2处理器(Blue Gene/Q使用)和Intel Xeon Phi处理器等多核架构的出现,像BLIS方法所支持的那样,在内核内部和内核周围并行不仅方便,而且对于可延展性也是必要的。最终的实现为这些体系结构提供了我们认为最好的开源性能,实现了令人印象深刻的性能和出色的可伸缩性。
2 研究动机(Motivation/Introduction)
作者团队过去的两篇文章:
- BLIS: A Framework for Rapidly Instantiating BLAS Functionality
表明了BLIS可以视为GotoBLAS的一个系统重新实现,但有许多关键的见解,大大减少了库开发人员的工作量。其中主要的创新之处在于,内部内核——GotoBLAS GEMM 实现中最小的计算单元——可以进一步简化为微内核周围的两个循环。这意味着库开发人员只需要实现和优化实现 C := AB+C 计算的一个例程,其中 的C 是一个适合目标架构的寄存器的小子矩阵。 - Implementing level-3 BLAS with BLIS: Early experience FLAME Working Note #69
展示了在大量现有处理器上的移植性和性能表现的实验,文章主要实现在单核上,虽然对BLIS怎样支持并行化有一个简单的描述,但是没有展示更多细节。
本文主要描述了GEMM的BLIS实现中所暴露的并行机会,特别关注当针对需要比内核更多的线程的多核架构时,如果达到接近峰值的性能,这如何支持高性能和可扩展性。
两种架构用于实验和检测:
- PowerPC A2 处理器,具有 16 个核心,这是 IBM 的 Blue Gene/Q 超级计算机的基础, 支持总共 64 个线程的四向超线程;
- Intel Xeon Phi 处理器,具有 60 个内核,还支持总共 240 个线程的四向超线程。
结果表明,由于 GotoBLAS 方法采用的内部内核内 BLISS 方法暴露的额外并行性,可以具体实现出色的性能和可扩展性。
还表明,当使用许多线程时,有必要在多个维度上并行化。这建立在Marker等人的基础上,我们认为是第一批研究GEMM在多线程体系结构上的2D工作分解的论文。论文还建立在描述供应商实现PowerPC A2和Xeon Phi的工作之上。根据我们的经验,BLISS 将其中许多见解包装在一个更清晰的框架中,以便对算法设计空间的探索简化。我们展示了相对于英特尔数学内核库 (MKL) 和 IBM 的工程和科学子程序库 (ESSL)的性能具有竞争力。
3 符号系统(Notation)
4 结论(Conclusion)
- 在 BLISS 框架内暴露了微内核周围的五个循环,这些循环在矩阵矩阵乘法下。讨论了在计算的原型点上,数据驻留在何处,并用它来激发有关并行化各种循环的机会的见解。
- 讨论了并行化不同的循环如何影响数据的共享和数据运动的摊销。
- 将这些见解应用于对需要许多线程才能达到峰值性能的两种架构的并行化:Blue Gene/Q 超级计算机和 Intel Xeon Phi 基础的 IBM PowerPC A2。
- 展示了如何并行化多个循环是高性能和可扩展性的关键。
- 在 Xeon Phi 上,生成的性能与英特尔高度调整的 MKL 相匹配。对于 PowerPC A2,并行化比 IBM 的 ESSL 产生了可观的性能提升,这主要是由于更好的可扩展性。因此在这两个架构上,为矩阵乘法的BLIS架构添加并行化似乎是可以支撑高性能的,这可以很快为社区提供另一种多线程BLAS的开源方法。
- 这两种架构上共有的一个有意思之处是它们的L1 cache对于支持要求获得接近峰值性能的多线程硬件而言太小了,这是通过使用L2 cache中一小块区域来存储传统结构中驻留在L1 cache中的数据来克服的,这一问题将在未来的多核架构中反复出现。
5 主体工作
5.1 从外至内描述BLIS内核外层的5重循环以及相应的数据组织方式
-
第一层循环,将C和B分割成,宽度为 n c n_c nc的列panel,规模很大(分别为mX n c n_c nc和kX n c n_c nc),由 j c j_c jc进行索引;使用最外层循环的主要原因是为了矩阵限制所需的工作空间,第二个原因是为了允许B的工作缓冲保留在L3cache中。
-
第二层循环,将A和第一层循环分割的Bpanel,分别分割为mX k c k_c kc的列panel和 k c k_c kcX n c n_c nc的行panel,由 p c p_c pc进行索引;此时,需要将二次分割后的Bpanel,打包成连续寻址的特殊存储方式,同时存储在L3 cache中。
-
第三重循环,将第二层循环分割的Apanel和第一层分割的Cpanel,分别分割成 m c m_c mcX k c k_c kc,和 m c m_c mcX n c n_c nc的block,由 i c i_c ic进行索引;此时,需要将二次分割后的Ablock,打包成连续寻址的特殊存储方式,同时存储在L2 cache中。
注意,到此为止,就是GotoBLAS方法中实现的GEBP内核,接下来的两重循环是BLIS中额外展开的,使用C编写,而GotoBLAS中常采用汇编实现。 -
第四重循环,将已打包好的Bpanel进一步分割成 k c k_c kcX n r n_r nr的Bmirco-panel,将C进一步分割成 m c m_c mcX n r n_r nr的Cmirco-panel,由 j r j_r jr索引;同时,通过打包操作,Bpanel以每次一行(宽度为 n r n_r nr)的方式连续存储,便于寻址同时减少缺失,这也是打包的目的之一。
-
第五重循环,将已打包好的Ablock进一步分割成 m r m_r mrX k c k_c kc的Amirco-panel,将C进一步分割成 m r m_r mrX n r n_r nr的Cmirco-block,由ir索引;注意,这里需要将Cmirco-block驻留在寄存器中;同时,通过打包操作,Ablock以每次一列(高度为 m r m_r mr)的方式连续存储,便于寻址同时减少缺失,这也是打包的目的之一。此时,微内核就可以通过, m r m_r mrX k c k_c kc的Amirco-panel与 k c k_c kcX n r n_r nr的Bmirco-panel的乘积更新 m r m_r mrX n r n_r nr的Cmirco-block。
-
展示了在一次微内核计算中,内存和三级cache中的数据驻留情况。
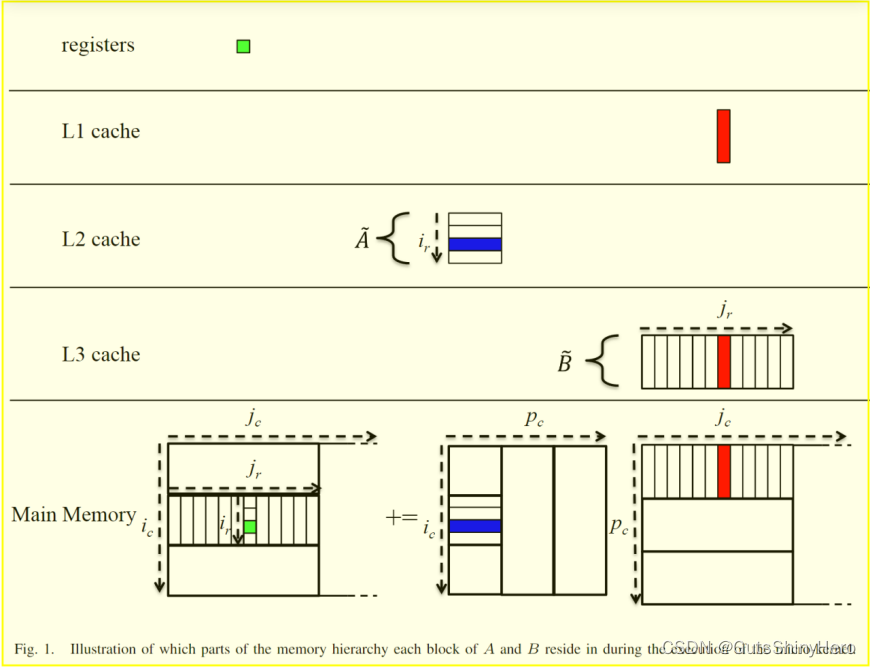
-
展示了最接近微内核的三重循环的数据访问过程,需要注意的是最内层的两层循环在GotoBLAS中是隐藏的
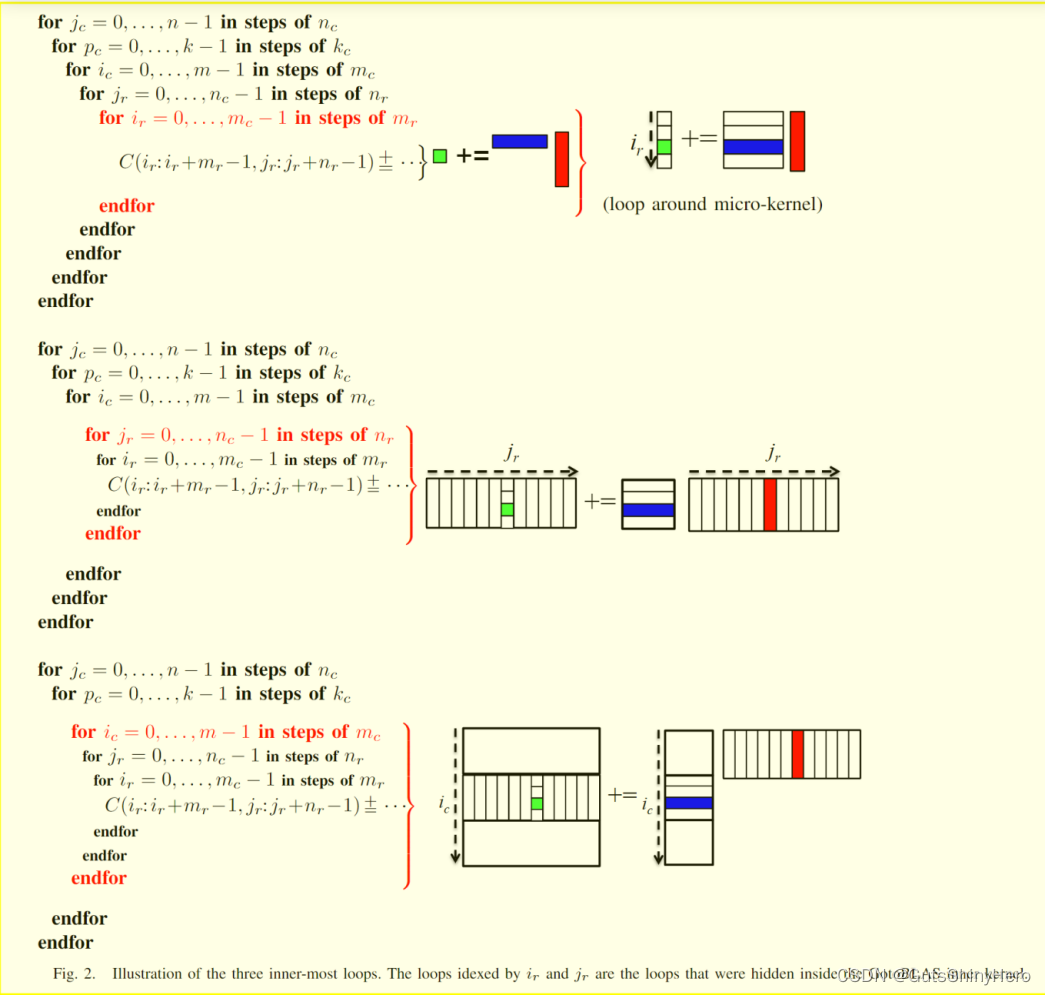
5.2 分析各层循环并行的可行性
关键的见解是:GotoBLAS中内核就是最小的不可分的计算单元,在内核中不再有并行的机会,但BLIS将内核进一步展开,因此增加了两个并行的机会;使用给定的内存层次进行分析可以对哪层并行提供指导
-
在微内核中进行并行
微内核中的循环是对Cmirco-block的一系列rank-1更新操作,对这些操作进行并行是不明智的,原因有三:
1. 计算的粒度很小,使得开销相当大,
2. 不同的线程会分别计算C块因此需要跨线程reduce
3. 每个线程对 m r m_r mr × n r n_r nr C块的每次更新所做的计算更少,因此更新成本的摊销减少了。
这仅仅意味着围绕rank-1更新并行化循环是不可取的。对于需要超线程以获得最佳性能的核心,可以设想以其他方式仔细并行微内核。但是这种并行性可以被描述为围绕微内核并行化第一个和第二个循环的某种组合。
我们稍后将重新讨论这个话题。
本文的重点在于微内核是BLIS的基本计算单元。我们关注的是如何在不触及基本计算单元的情况下获得并行性。 -
第五层循环进行并行(由ir索引)
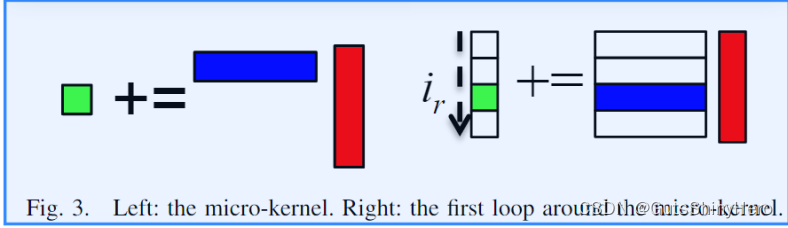
在该层循环进行并行,意味着将不同的微内核计算分配给不同的线程,我们的目标是优化使用快速内存资源。在这种情况下,不同的线程共享相同的Bmirco-panel,它驻留在L1cache中。
由于:
a. 该层循环固定执行 m c m_c mc/ m r m_r mr次,因此该循环中能被提取的并行数量很有限;
b. Bmirco-panel会先从L3 cache中读取到L1 cache,供该层循环每次迭代利用,并行之后,用于计算的总时间将会减少,因而访存时间对应可摊销的计算时间会减少,但是注意在非并行化时的计算时间可能就是能覆盖访存时间的最小时间,所以只有该循环迭代次数足够多时,并行才可行,但是 m c m_c mc/ m r m_r mr的大小通常是很小的, m c m_c mc通常只有百数量级。
因此,该层循环并不适合并行化 -
第四层循环并行(由 j r j_r jr索引)
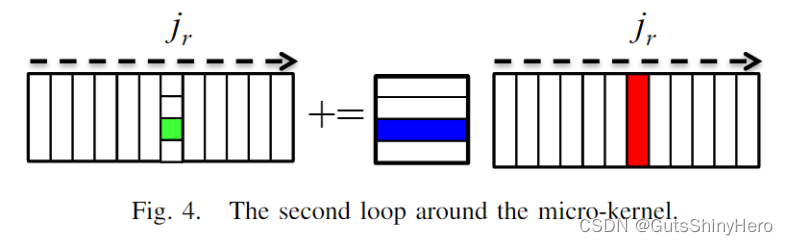
该层循环固定执行 n c n_c nc/ n r n_r nr次;在该层,每次迭代会共享驻留在L2 cache中的相同的Ablock,然后每次迭代会将不同的Bmirco-panel从L3 cache读取到L1 cache中,每次迭代使用相同的Ablock和不同的Bmirco-panel相乘计算。
与第五层循环类似,开始前会将Ablock从主存读取到L2 cache,供该层循环并行利用,因此只在 n c n_c nc/ n r n_r nr较大时,并行才能让访存时间摊销到足够的计算时间上,而 n c n_c nc往往由千数量级,足够大,所以该层并行是可行的。
如果每个线程共享相同的L2 cache:
需要注意,并行的线程会共享Ablock的L2 cache,但是每个线程同时也需要一定的L2 cache空间来缓冲各自不同的Bmirco-panel。因此,有可能需要调整Ablock或Bmirco-panel的片段大小,以便所有片段同时放入cache中。然而,与二级cache的大小相比,Bmirco-panel很小,所以这可能不是问题。
如果每个线程不共享相同的L2 cache:
每个线程将打包部分的Ablock,然后使Ablock的整个块进行本地计算。在GEMM的串行情况下Ablock的打包过程会将其移动到单个L2cache中。相比之下,并行化这个循环会导致Ablock的各个部分被放置在不同的 L2 cache中。这是因为Ablock的打包是并行化的。在并行打包中,每个线程将打包 ̃Ablock的不同部分,以便 ̃Ablock的部分最终将位于该线程的私有 L2 cache中。然后必须依赖cache一致性协议,以保证根据需要Ablock的片段在L2cache中重复。这发生在微内核执行期间,并且可能与计算重叠。因为这会导致额外的内存移动并依赖于cache一致性,因此根据cache之间的重复成本,这可能也可能不希望使用。请注意,如果架构不提供cache一致性,则必须手动完成 ̃Ablock片段的重复。 -
第三层循环(由 i c i_c ic索引)
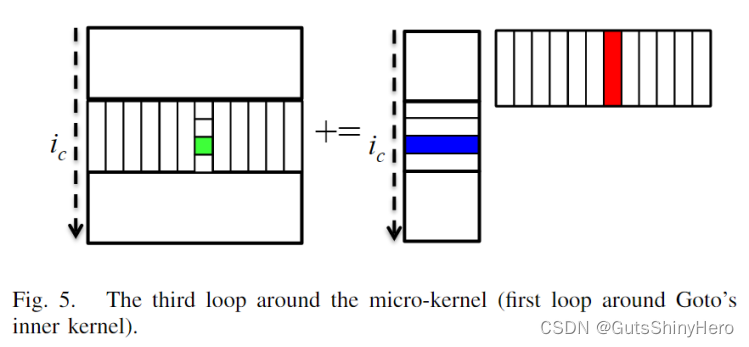
该层循环固定执行m/ m c m_c mc次;在该层,每次迭代会共享驻留在L3 cache中的相同的Bpanel,,每次迭代使用各自不同的Ablock和相同的Bmirco-panel相乘计算。
与微内核最内部的两个循环不同,这个循环的迭代次数不受阻塞大小的限制;相反,这个循环的迭代次数取决于m的大小。请注意,当m小于 m c m_c mc和循环并行化程度的乘积时,Ablock将小于最优值,性能将受到影响。
如果每个线程共享相同的L2 cache:
L2 cache中必须有多个块。因此,每个Ablock的大小必须减少一个相对于这个循环的并行化程度的因子。Ablock的大小是 m c m_c mc × k c k_c kc,所以这两个都可以减小。注意,如果我们选择减小 m c m_c mc,那么并行化这个循环相当于并行化微内核周围的第一个循环。
如果每个线程都有自己的L2 cache:
那么每个Ablock都驻留在自己的cache中,因此不需要调整大小。
注意如果有多个L3 cache那么每个线程将把Bpanel的不同部分打包到自己的L3 cache中。然后,必须依赖cache 一致性协议来将Bpanel的每个部分放在每个L3cache中。和前面一样,如果体系结构不提供cache一致性,则必须手动完成对Bpanel的复制。 -
第二层循环(由 p c p_c pc索引)
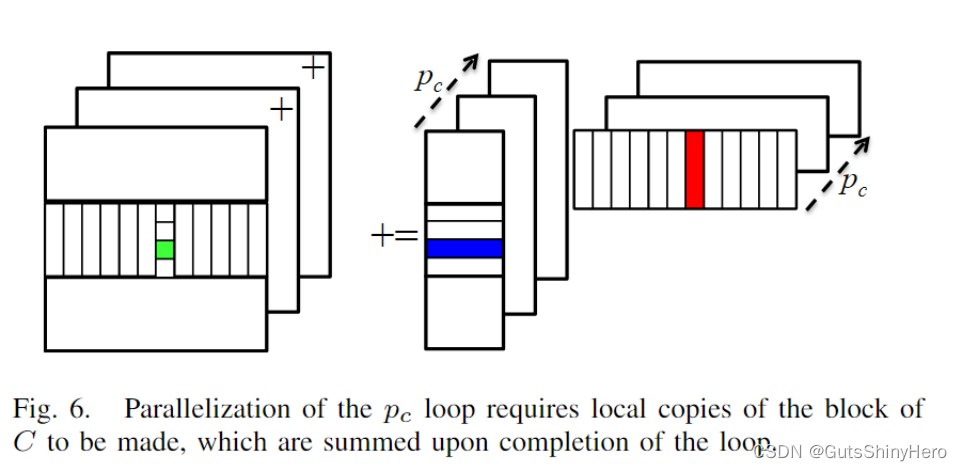
与前面讨论的并行不同,每个线程都将更新相同的C块,这可能会产生数据冲突。因此,并行化这个循环要么需要某种锁定机制,要么需要创建C块的副本(初始化为零),这样所有线程都可以更新自己的副本,然后reduce各自的结果。这个循环只能在非常特殊的情况下并行化。
一个例子是当C很小时,使得:- 只有通过并行化该循环才能实现令人满意的并行度水平,
- 相对于
- 其他计算成本,reduce结果开销小的。
正是由于这些原因,所谓的3D(有时称为2.5D)分布式存储器矩阵乘法算法选择该循环进行并行化(除了并行化一个或多个其他循环之外)。
-
第一层循环(由 j c j_c jc索引)
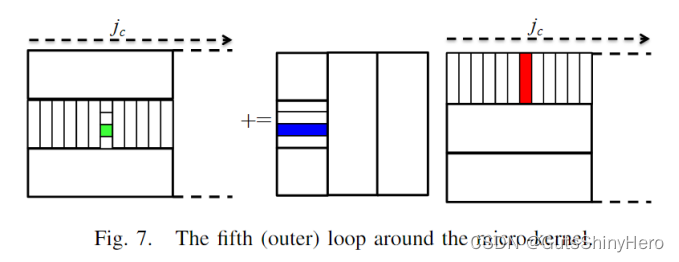
在该层循环中,每次不同的迭代会共享主存中的完整矩阵A,而使用各自不同的Bpanel计算。
考虑只有一个 L3 cache的情况。然后必须减小 Bpanel的大小,让多个Bpanel可以同时放置在 L3 cache中。如果 n c n_c nc 减少,则这相当于在微内核周围并行化第二个循环,就如何在线程之间划分数据。如果每个线程都有自己的 L3 cache,那么 ̃B 的大小不必更改, ̃Bpanel都将驻留在自己的cache中。
因此,并行化这个循环可能是多套接字系统的一个很好的想法,其中每个 CPU 都有一个单独的 L3 cache。此外,此类系统通常具有非均匀内存访问 (NUMA) 设计,因此为每个 NUMA 节点使用单独的Bpanel很重要,每个面板都驻留在该节点的本地内存中。
请注意,由于并行化此循环的线程不共享任何A或B的打包缓冲区,因此从数据共享的角度来看,并行化此循环相当于在BLIS之外获得并行性。
5.3 在INTEL XEON PHI体系上实现BLIS的并行化
-
体系结构的细节
- Xeon Phi 有 60 个内核,每个内核都有自己的 512 KB L2 cache和 32 KB L1 数据cache。 每个核心有四个硬件线程,所有这些线程共享相同的 L1 cache。
- 每个核心能够利用核心的两个管道为在每个时钟周期发出两个指令。
- 其中一个管道可用于执行向量浮点指令或向量内存指令。另一个可能仅用于执行标量指令或预取指令。如果要达到峰值性能,能够执行浮点运算的指令管道应尽可能执行融合的乘累积指令 (FMA)。
- 一个线程可能只会每隔一个时钟周期向每个管道发出一条指令。因此,利用两个硬件线程是完全利用浮点单元所需的最小要求。使用四个硬件线程进一步缓解了指令延迟和带宽问题
-
在该架构上实现BLIS的并行
由于Intel Xeon Phi处理器的高度并行特性,在设计微内核时必须考虑到从内核共享硬件线程中获得的并行性。在传统的体系结构中,会对A和B的分段进行大小调整,使得B驻留在L1 cache中,B从内存中流化。然而,这种情况并不适用于Xeon Phi。这是由于四个线程共享一个L1 cache,在m和n维度上并行化意味着L1cache中必须有至少两个的A的分块和两个片段的B的分块。在Xeon Phi处理器上,将如此多的数据放入L1cache将意味着将 k c k_c kc减少到一个点,在这个点上,更新C的 m r m_r mr × n r n_r nr块的成本不会被足够的计算平摊。解决方案是只面向L2 cache进行分块。为了将GotoBLAS方法应用于这种情况,我们可以将L2cache中包含A和B的区域视为虚拟L1cache,其中访问其元素的成本与访问L2 cache中的元素的成本相同。
- 多管道和多线程意味着,每次并行必须更新8X30或30X8的C分块(8是因为每个核心中有4线程和双管道,它们乘积应该固定为240,因为总线程数为240),本实验中选择30X8;
- m c m_c mcX k c k_c kc的Ablock应该被合适的驻留在512KB的L2 cache中。在本实验中令 m c m_c mc=120, k c k_c kc=240,这大约是512KB的一半,符合GotoBLAS中的假定设置。
- 没有L3 cache,所以 n c n_c nc只受主存的限制,以及我们想要用于保存panel的临时缓冲区的内存量。出于这个原因,我们选择 n c n_c nc为14400,这是我们在实验中使用的任何矩阵的最大n维的值。
-
选择哪一维进行并行化
线程的绝对数量和硬件线程以分层方式组织的事实表明,我们需要考虑并行化多个循环。我们使用fork-join模型来并行化多个循环。当一个线程遇到一个具有P路并行性的循环时,它将产生P个子线程,并且这P个线程并行化该循环实例。线程总数是并行处理每个循环的线程数的乘积。现在,我们将从上一节中了解到,确定哪些循环适合并行化,以及并行化到什么程度。在本节中,我们将使用索引变量的名称来标识每个循环。
- ir循环。注意 m c m_c mc=120, m r m_r mr=30,所以该层只有4次迭代,所以并不是一个好的时机
- j r j_r jr循环。注意 n c n_c nc=14400, n r n_r nr=8,所以该层循环的迭代次数非常巨大,所以适合并行化.而且每四个线程共享相同的L2 cache,如果利用这些线程进行并行,它们会很自然的共享相同的Ablock。
- i c i_c ic循环。这一循环中迭代120次(在m=n=k=14400的情况下),所以这个循环也是一个比较好的时机。而且,因为每个内核有各自的L2 cache,因此只要不在内核中进行线程的并行化那么Ablock的大小不需要进行额外调整(如果共享L2 cache,情况在上一节中讨论过
- p c p_c pc循环。因为C分块不足够小,所以不讨论这一循环,因为开销过大
-
j
c
j_c
jc循环。由于Xeon Phi处理器缺乏L3cache,因此与
j
r
j_r
jr循环相比,这个循环在n维并行化方面没有任何优势。它也提供了比
j
r
j_r
jr循环更差的空间局部性,因为会有不同的Bpanel需要缓冲。
所以,有 j r j_r jr循环和 i c i_c ic循环两个选择来进行并行。
-
内核中并行
对于 j r j_r jr循环并行来说,采用内核内并行是很有效的,每个线程会指定各自的Bmirco-panel,同时四个线程会共享相同的Ablock。如果四个线程进行同步,那么它们会同时访问Ablock的相同的子Amirco-panel,那么当一个线程将Amirco-panel读取进入L1 cache后,所有的线程都可以在它被驱逐之前使用它。
因此,并行化 j r j_r jr 循环并同步四个硬件线程会降低微内核的带宽要求。四个硬件线程的同步是通过定期执行障碍来完成的。即使线程位于不同的内核上,同步线程也可能很重要。例如,不同的核心之间可能都会访问相同的Bmirco-panel,读入它们各自的L2 cache中,如果正确同步,那只需要从主存(或L3 cache)中访问一次,如果核心之间同步失败,就可能造成多次的访问,影响性能和功耗。
对于我们的 Xeon Phi 实验,核心上的四个线程并行化 j r j_r jr 循环,并且在微内核的每 8 个实例中执行一个障碍。但是,我们不会在内核之间强制执行任何同步。
-
内核间并行
如前所述,由于每个核心都有自己的 L2 cache,因此在内核之间并行化 i c i_c ic 循环特别有利。但是,如果内核之间的并行性仅由这个循环获得,当 m 较小时,性能会很差。此外,当 m 是 7200 的倍数时,所有内核只会处理A 的整数个完整block(其中Ablock 的大小为 m c m_c mc × k c k_c kc)。出于这个原因,我们寻求在 m 和 n 维中获得并行性。因此,除了 i c i_c ic 循环之外,我们还并行化 j r j_r jr 循环以获得内核之间的并行性,即使这会导致cache一致性协议的额外成本,将所有Ablock 复制到每个 L2 cache。
6 实验结果(Evaluation)
![![[08-Assets/Pasted image 20231223214751.png]]](https://img-blog.csdnimg.cn/direct/a63cc0096484467287e1771116ce6456.png)
上图表示的是k不变,以m=n为变量做出的单核平均性能曲线;下图表示的是m=n=14400不变,以k为变量做出的性能曲线。 j r j_r jr表示在 j r j_r jr循环中并行的线程有几路, i c i_c ic表示在 i c i_c ic循环中并行的线程有几路。
















 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









