







 本文介绍了一项针对医疗化验单的OCR识别项目,旨在提高数值和名称的识别准确率达到85%以上。项目采用PaddleOCR模型,并通过图片扶正与裁剪等预处理手段显著提升了识别精度。
本文介绍了一项针对医疗化验单的OCR识别项目,旨在提高数值和名称的识别准确率达到85%以上。项目采用PaddleOCR模型,并通过图片扶正与裁剪等预处理手段显著提升了识别精度。
项目总结
前言
课题组项目的总结。
一、项目要求
课题组和广州的一家药企有合作,甲方要求把一张医疗化验单内的表格内容整体识别出来,特别是化验的数值和名称的准确率,要求达到85%以上。
比如下面一张样本,三线表之外的内容都不需要我们负责(比如姓名、年龄这些),我们只需要把三线表里面的内容识别出来,特别是项目栏、结果栏的识别精度要高。但是很明显有很多干扰(竖线、手写体),这些都会严重影响识别精度。这还是PDF版的,属于干扰最少的,还有手动拍照的、拍摄电脑屏幕的样本更难识别。

甲方的要求就是我们把数值和名称的识别准确率优先提上去。甲方之前有一个识别模型,但是准确率提不上去,也想过找百度合作,但是成本太高,所以找到了我们课题组。
二、解决思路
1.模型
OCR模型我们选用的是百度开源的PaddleOCR。
Git:PaddleOCR
1.扶正
由于要识别的样本不是很规整,有PDF、手动拍照、拍电脑屏幕的。这就导致样本有各种各样的倾斜角度,有的照片甚至有曲折,这给OCR识别造成了很大的困扰。所以针对这些干扰,首先解决倾斜问题,要把样本图片的角度扶正也就是成水平状态,这样能提高OCR的准确率。并且我们实验发现,如果把整张表传进去识别,准确率会很低。而如果只把我们需要的表格裁剪下来,那识别精度就会很高了,所以把图片扶正也是为了裁剪做准备。
甲方想要做成小程序,所以深度学习这方面就不考虑,要尽量减小模型,只能用opencv的技术。要把图片扶正,首先要找一个参考点,我们的思路是以表格的这些直线作为参考,计算他们的斜率是否为0来判断图片是否水平。
以三线表为例,通过opencv把三线表的三条直线识别出来,因为识别的直线有误差,所以决定计算三条直线的斜率取平均,平均斜率就是我们的判断依据。
opencv识别直线的算法其实有很多,我们也尝试了很多种例举两种。
一是通过找轮廓的方法,也就是opencv的cv2.findContours函数。根据找出轮廓的周长大小来把直线筛选出来。因为三线表的三条直线明显比其他的要长很多,自然周长也会大些。实验效果虽然也还不错,但是如果样本干扰太多,这个方法会有很大的误差,会找出很多非直线的轮廓。这个方法也就pass。
二是通过霍夫变换。霍夫变换是一个非常经典的算法,简单实用。霍夫变换实验的效果一开始其实不是很好,因为样本真的没有想象那么好,非常非常多的干扰,识别出来的效果如下(蓝色线即霍夫变换识别出来的直线):

肉眼看很明显的三条直线直接识别出来几百条,霍夫变换不可能像人一样精准的标注出一条直线,它是根据像素之间的关系来计算的,所以看起来一个地方只有一条直线,其实它预测了很多条只是斜率相差很小很小,所以这就是为什么要取平均的另一个原因。后续就开始了调参之路(调参不是漫无目的地调要弄懂原理),有的样本适合这个参数有的适合另一个参数。调参后:

部分代码demo
class RectifyBias():
def __init__(self,pic_path):
self.pic_path=pic_path #图片路径
def rotate_bound(self,image, angle):
(h, w) = image.shape[:2]
(cX, cY) = (w / 2, h / 2)
M = cv2.getRotationMatrix2D((cX, cY), -angle, 1.0)
cos = np.abs(M[0, 0])
sin = np.abs(M[0, 1])
nW = int((h * sin) + (w * cos))
nH = int((h * cos) + (w * sin))
M[0, 2] += (nW / 2) - cX
M[1, 2] += (nH / 2) - cY
return cv2.warpAffine(image, M, (nW, nH))
# 轮廓方法
def find_contour(self):
pic=cv2.imdecode(np.fromfile(self.pic_path,dtype=np.uint8),cv2.IMREAD_COLOR)
gray=cv2.cvtColor(pic,cv2.COLOR_BGR2GRAY)
thresh, binary=cv2.threshold(gray,150,255,cv2.THRESH_BINARY)
img=pic.copy()
a,b=cv2.findContours(binary,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
row,col=binary.shape
# j=0
for i in range(len(a)):
if cv2.arcLength(a[i],closed=True)>col/2 and cv2.arcLength(a[i],closed=True)<1.9*(col+row):
# j+=1
cv2.drawContours(img,a,i,(0,0,255),2)
coor=a[i]
# if j==2:
break
# print(cv2.minAreaRect(coor)[2])
if cv2.minAreaRect(coor)[2]<45:
imgs=self.rotate_bound(img,-(cv2.minAreaRect(coor)[2]))
else:
imgs=self.rotate_bound(img,90-(cv2.minAreaRect(coor)[2]))
cv2.namedWindow("before",cv2.WINDOW_NORMAL)
cv2.resizeWindow("before",1200,1200)
cv2.imshow("before",img)
cv2.imshow("after",imgs)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 霍夫变换
def find_lines(self):
pic=cv2.imdecode(np.fromfile(self.pic_path,dtype=np.uint8),cv2.IMREAD_COLOR)
gray=cv2.cvtColor(pic,cv2.COLOR_BGR2GRAY)
thresh, binary=cv2.threshold(gray,160,255,cv2.THRESH_BINARY)
dst=cv2.GaussianBlur(binary, (9,9), 0)
img=pic.copy()
edges = cv2.Canny(dst, 70, 150,)
lines = cv2.HoughLinesP(edges ,1,np.pi/180, 100,minLineLength= 200, maxLineGap=200)
# lines = cv2.HoughLinesP(edges ,1,np.pi/360, 300,minLineLength= 500, maxLineGap=300)
slope_list=[]
for i in range(len(lines)):
x_1, y_1, x_2, y_2 = lines[i][0]
if (x_1-x_2)!=0:
# if ((y_1-y_2)/(x_1-x_2))<1 and ((y_1-y_2)/(x_1-x_2))>-1:
slope_list.append(round((y_1-y_2)/(x_1-x_2),2))
cv2.line(img, (x_1, y_1), (x_2, y_2), (255, 0, 0), 3)
# print(slope_list)
imgs=self.rotate_bound(img,-(math.degrees(math.atan(np.mean(slope_list)))))
cv2.namedWindow("before",cv2.WINDOW_NORMAL)
cv2.resizeWindow("before",1200,1200)
cv2.imshow("before",img)
# cv2.imshow("after",imgs)
cv2.waitKey(0)
cv2.destroyAllWindows()
# DS221789-全套体检报告
pic_path= "pic6.png"
pic_path = ""
for image in os.listdir(pic_path):
pic_path = ""
pic_path +=image
a=rectify_bias(pic_path)
a.find_lines()
# a=rectify_bias(pic_path)
# a.find_lines()
# a=rectify_bias(pic_path)
# a.find_contour()
2.裁剪
解决完倾斜问题后,发现精度有提升但还是不够。随后做了很对实验,实验发现,如果把整张表传进去识别,准确率会很低。而如果只把我们需要的表格裁剪下来传进去,那识别精度就会很高了,所以把图片扶正也是为了裁剪做准备。
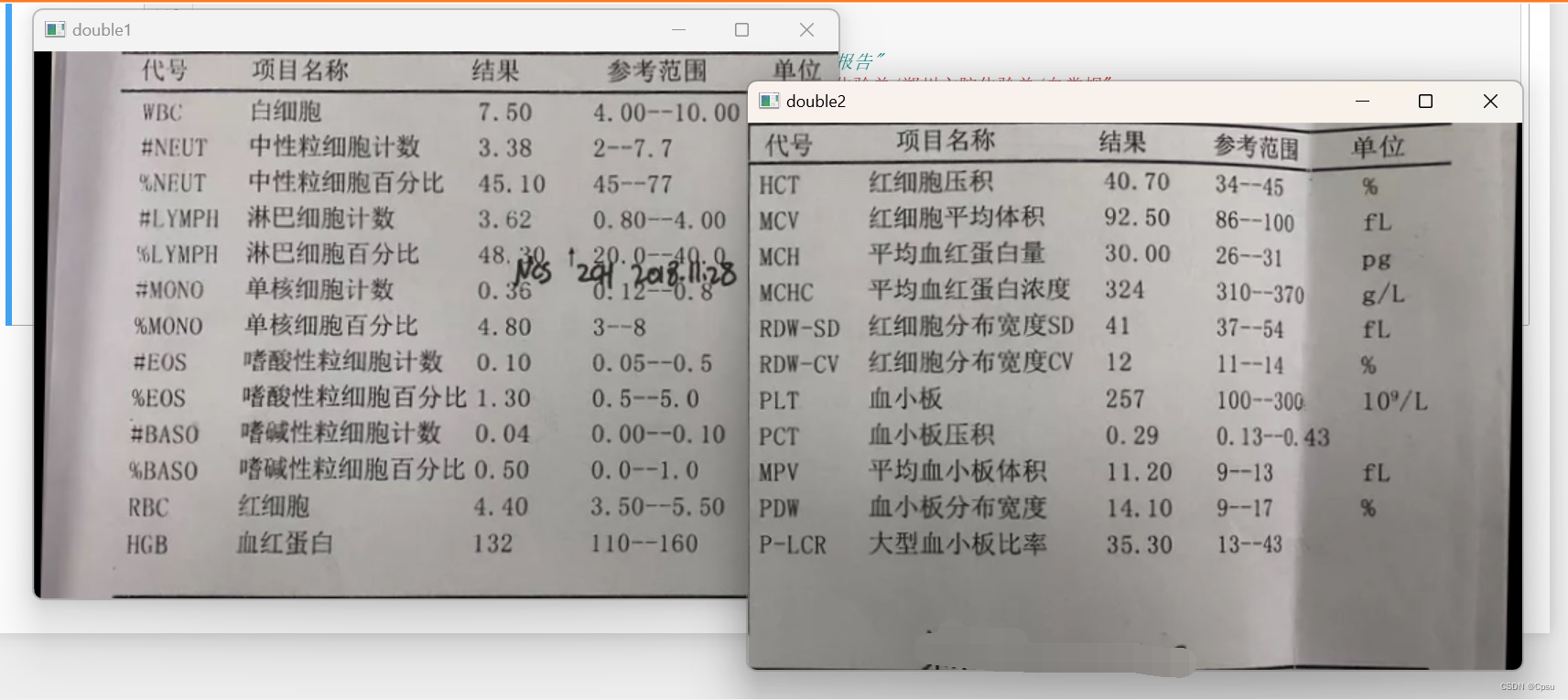
裁剪需要在扶正后的图片的基础上,找出第一根直线和最后一根直线,把表格裁剪出来。这是三线表的做法。但是,还有一种双栏表(中间还有一条竖线也就是两栏):

就是要把这种裁剪成两部分。这样识别精度大大提高。
demo结果参考:
三线表裁剪:
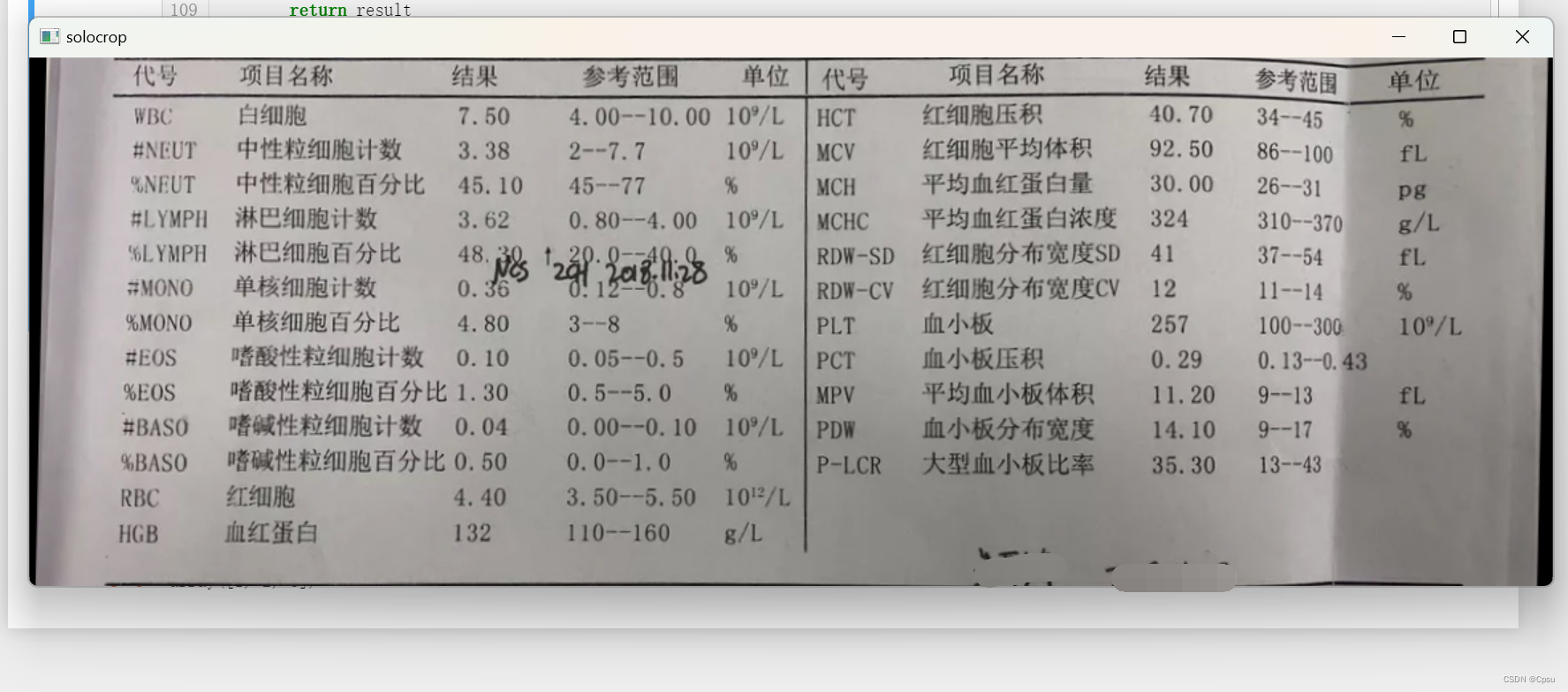
双栏裁剪:
3.pipeline
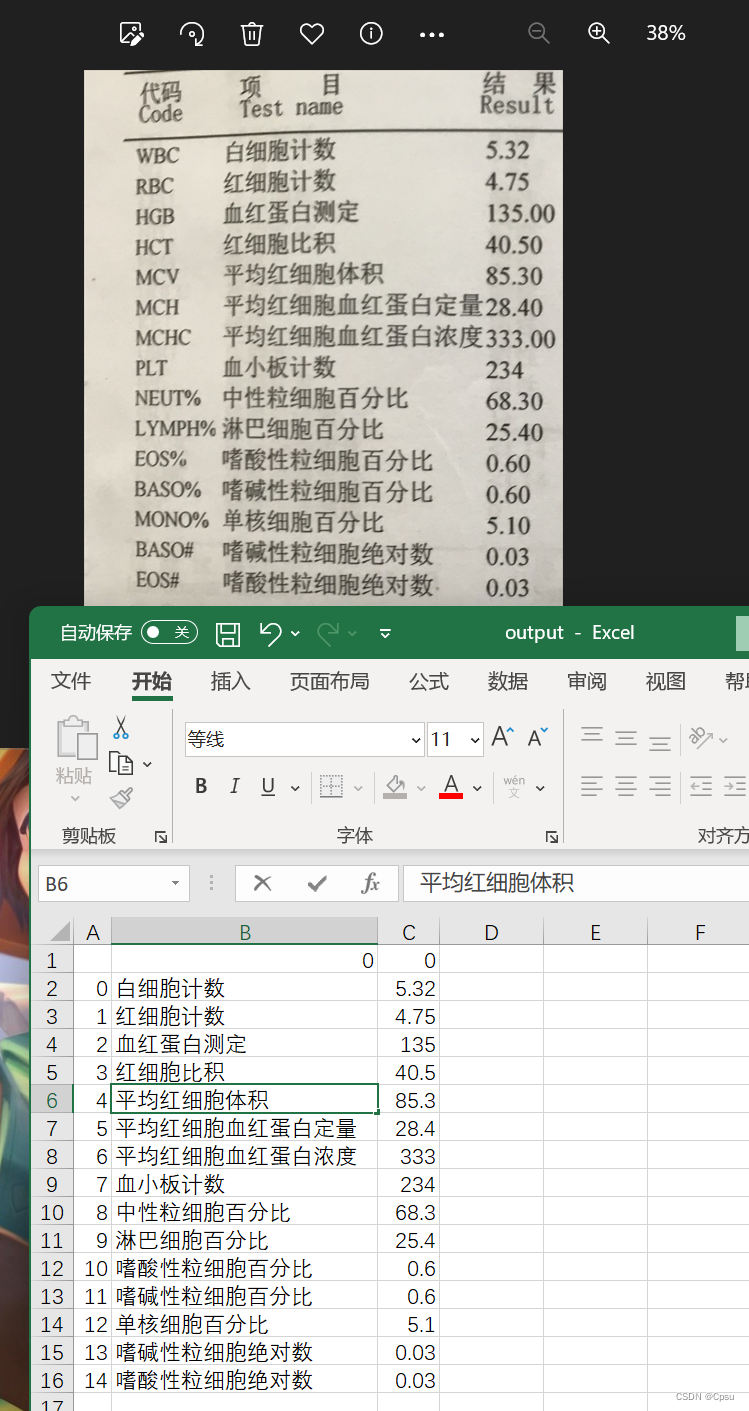
送入一张图片,经过预处理后(扶正、裁剪等)送入Paddle OCR,得出结果后通过文字纠正(模型后处理)以后,输出结果。
结果精度:
三、总结
项目经过几个月也算是完成了,组里算是5个人一起搞这个项目,经过很多尝试也算是做成了,一开始甲方以为我们做不成,不过最后精度不仅没问题还超过了甲方所提的要求,也顺利签合同。

















 5861
5861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









