







摘要
在过去的十年中,目标检测取得了显著的进展。然而,由于以下内在原因,定向和高密度物体的检测仍然具有挑战性:
(1)神经元的感受都是轴向对齐的,形状相同,而物体通常是不同的形状,沿着不同的方向排列
(2)检测模型通常使用通用知识进行训练,在测试时不能很好地泛化处理特定的对象;
(3)数据集有限,阻碍了本任务的发展。
为了解决前两个问题,本文提出了一种由两部分组成的动态细化网络:特征选择模块(FSM)和动态细化头(DRH)。我们的FSM使神经元能够根据目标物体的形状和方向调整感受野,而DRH使我们的模型能够以对象感知的方式动态地改进预测。为了解决相关基准测试可用性有限的问题,我们收集了一个广泛的、完全注释的数据集,即SKU110K-R,它基于面向边界框进行重新标记。我们对几个公开的基准进行定量评估,包括DOTA,HRSC2016,SKU110K和我们自己的SKU110K- R数据集。实验结果表明,与基线方法相比,该方法取得了一致且显著的增益。
1.介绍
在深度学习的帮助下,目标检测在一些基准(如VOC[6]和COCO[24])上取得了显著的进展。许多精心设计的方法[35,44,46,34,3]已经证明了很好的结果。然而,当物体(如航空图像中的物体)方向任意且分布密集时,大多数探测器会遇到问题。此外,几乎所有的检测器都对训练集上的模型参数进行优化,并在之后保持不变。这种使用一般知识的静态范例可能不够灵活,无法在测试期间检测特定的样本。
最近在定向目标检测方面的大部分进展都是基于R-CNN系列框架[8,7,35]。这些方法首先生成大量的水平边界框作为候选区域,然后根据区域特征预测分类和定位。不幸的是,水平roi通常会在边界框和定向对象之间严重失调[40,29]。例如,航拍图像中的物体通常具有任意的方向和密集的排列,导致几个实例通常拥挤在一个水平RoI[5]中。 因此,提取准确的视觉特征变得困难。其他方法[40,26,29,28]利用定向边界框作为锚来处理旋转的对象。然而,这些方法的计算复杂度很高,因为它们获得了许多设计良好的锚,具有不同的角度、尺度和宽高比。近年来,RoI Trans[5]通过旋转RoI学习器,利用旋转位置敏感的RoI对齐模块提取旋转不变区域特征,将水平方向RoI转化为定向方向RoI。但是,这种方法仍然需要精心设计的锚,而且不够灵活。
模型训练是一个由特殊到一般的过程,推理是一个由一般到特殊的过程。然而,几乎所有的方法都遵循平稳范式,不能基于样本进行灵活的推理。动态过滤器是一种简单而有效的方法,可以使模型在不同的样本上进行更改。现有的方法[4,38]采用动态滤波器进行特征重组,取得了较好的效果。然而,检测器有两个不同的任务,即分类和回归。图1显示了一些说明性的例子。对于分类任务,关键是细化特征嵌入以提高可判别性。然而,对于一个回归问题,直接细化预测值是可取的。针对上述两个方面,我们提出了两个版本的动态优化头(DRHs)。

图1所示。分类(a)和回归(b)的动态细化说明。每个实心点代表一个样本。分类器和回归器利用训练过程中学习到的一般知识进行预测,但缺乏灵活性。模型应随样品的变化而变化。箭头表示可以通过动态精细化进行调整。
- (a)灰色圆形代表特征空间,点代表三个类别的样本。一些样本远离边界说明这些样本具有良好的识别语义性能。
- (b)橙色实心点表示例子的目标值,橙色曲线代表学习的回归模型。
在本研究中,我们采用CenterNet[44],以一个附加的角度预测头作为我们的基线,并提出了动态细化网络(DRN)。我们的DRN由两部分组成:特征选择模块(FSM)和动态优化头(DRH)。FSM赋予神经元根据物体形状和方向调整感受野的能力,从而将精确的去噪特征传递给检测器。DRH使我们的模型能够以对象感知的方式进行灵活的推断。具体来说,我们提出了两个DRH用于分类(DRH-C)和回归(DRH-R)任务。此外,我们仔细重新标记了定向SKU110K[9]的边框,并将其命名为SKU110K- r;通过这种方式,面向对象的检测更加方便。为了评估所提出的方法,我们在DOTA、HRSC2016和SKU110K数据集上进行了广泛的实验。
总之,我们的贡献包括:
•我们提出了一种基于物体形状和方向自适应调整神经元感受野的新型FSM。所提出的FSM有效地缓解了感受野与物体之间的错位。
•我们提出了两个DRH,即DRH-C和DRHR,分别用于分类和回归任务。这些DRH可以对每个样本的独特性和特殊性建模,并以客观的方式细化预测。
我们收集一个仔细重新标记的数据集,SKU110K-R,包含定向边界框的精确标注,便于面向密集目标检测的研究。
•我们的方法在DOTA、HRSC2016、SKU110K和SKU110KR上显示出了一致且显著的定向和密集目标检测增益
2. 相关工作
大多数的目标检测方法[35,27,32,36,34,18,44,37]集中在轴对齐或直立的目标上,当目标方向任意或呈现密集分布[9]时可能会遇到问题。对于面向对象的目标检测,一些方法[8,10,25,29,28]采用了R-CNN[35]框架,使用了大量不同角度、比例和纵横比的锚点,但计算复杂度大幅增加。SRBBS[29]采用旋转感兴趣区域(RoI)翘曲提取旋转感兴趣区域的特征;然而,由于重复生成候选框会消耗额外的时间,因此很难嵌入神经网络。Ding等人[5]提出了一种RoI变压器,将轴向对齐的RoI转换为旋转的RoI,以解决RoI与面向对象之间的错位。SCRDet[42]在L1损失项中添加了一个IOU常数因子来解决定向边界盒的边界问题。相对于上述方法,我们提出了FSM方法,该方法自适应地调整神经元的感受野,并针对不同角度、形状和尺度的物体重新组合合适的特征。
FPN[22]提出了一种特征金字塔网络来进行多尺度的目标检测。他们根据面积大小选择候选框特征。FSAF[46]学习一个无锚模块,动态选择最合适的特征级别。Li等[19]提出了一个动态特征选择模块,根据新锚点的位置和大小来选择像素。这些方法的目的是在对象层次上选择额外的合适的特征。为了变得更细粒度,SKN[20]学会了使用不同的内核在每个位置选择具有不同感受野的特性。SENet[11]显式地自适应地重新校准通道的特征响应,而CBAM[39]采用了一个更多的空间注意模块来建模空间间关系。我们的FSM学习以像素的方式提取形状不变和旋转不变的特征。
空间变压器网络[13]是第一个在深度学习框架中学习空间变换和仿射变换来扭曲特征图的网络。主动卷积[14]用偏移量增加了卷积层中的采样位置。它共享不同空间位置的偏移量,训练后模型参数是静态的。变形卷积网络(DCN)[4]对图像中的密集空间变换进行建模,其偏移量为动态模型输出。FSM中的旋转卷积层以一种密集的方式学习旋转变换。RoI Trans[5]学习五种偏移量来将轴向对齐的RoI转换为与位置敏感的RoI Align[35]相似的方式。ORN[45]提出了在卷积过程中主动旋转的主动旋转滤波器。旋转角度是一个严格的超参数,所有位置都具有相同的旋转角度。相反,我们的旋转变换是可学习的,可以预测每个位置的角度。
通过引入动态滤波器,神经网络以输入特征和样本变化为条件。动态滤波器[15]在训练阶段学习滤波器权值,从而在推理时提取样本特征。类似地,CARAFE[38]提出了一个内核预测模块,该模块负责以内容感知的方式生成重组内核。DCN[4]和RoI Trans[5]虽然对偏移量预测进行了动态建模,但并不改变内核的权值。与[4,38]相比,我们的drh旨在通过引入动态滤波器而不是特征重组,以内容感知的方式细化检测结果。
3. 我们的方法和数据集
我们的方法总体框架如图2所示。我们首先在第3.1节介绍我们的网络架构。每个网络层中不同物体和感受野之间的错位是普遍存在的;因此,我们提出一个FSM来自动重组最合适的特性,如第3.2节所述。为了使模型具有根据不同示例动态细化预测的能力,我们在第3.3节中建议使用DRH来实现对象感知的预测。

图2。动态优化网络的总体框架。骨干网后面有两个模块,即特征选择模块(FSM)和动态细化头(DRHs)。FSM通过自适应调整感受野来选择最合适的特性。DRH以对象感知的方式动态地改进预测。
3.1 网络体系结构
我们使用CenterNet[44]作为基线,它将对象建模为一个单独的点(即包围框的中心点),并回归对象的大小和偏移量。为了预测有方向的边界框,我们添加一个分支来回归边界框的方向,如图2所示。设(cx, cy, h, w, θ, δx, δy)是模型输出的七个字节。然后构造有向边界框

式中(cx, cy)、(δx, δy)为中心点,偏移预测;(w, h)为尺寸预测;Mr为旋转矩阵;Plt、Prt、Plb、Prb为定向包围盒的四个角点。根据CenterNet的回归任务,我们使用L1损失对旋转角度进行回归

其中θ、ˆθ分别为目标转角和预测转角;N为正样本数。因此,我们模式的总体培养目标是
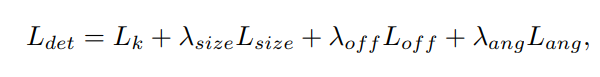
其中Lk、Lsize、Loff分别为中心点识别损失、规模回归损失、偏移回归损失,与CenterNet相同;λsize、λoff、λang是常量因子,在我们的实验中都设置为0.1
3.2 特征选择模块
为了减少不同物体和神经元轴向感受野之间的不匹配,我们提出了一种特征选择模块(FSM)来自适应地聚合使用不同核大小、形状(长宽比)和方向提取的信息(见图3)。

图3。上图:特征选择模块。底部:旋转卷积层。图中显示了一个分为三部分的示例。每次分割都使用3*3、1*3和3*1核的旋转卷积层来提取不同的信息。我们采用注意机制来聚合信息。
多特征。给出了一个特征映射![]() 首先用一个1*1卷积层对特征进行压缩,然后依次使用Batch Normalization[12]和ReLU[31]函数进行改进信息聚合。接下来,我们使用旋转卷积层(rcl)从
首先用一个1*1卷积层对特征进行压缩,然后依次使用Batch Normalization[12]和ReLU[31]函数进行改进信息聚合。接下来,我们使用旋转卷积层(rcl)从![]()
![]() 中提取多个特征。图3显示了一个包含3*3、1*3和3*1核的三个部分示例。每个部分负责不同的感受野,我们称之为
中提取多个特征。图3显示了一个包含3*3、1*3和3*1核的三个部分示例。每个部分负责不同的感受野,我们称之为![]() ,其中i∈{1, 2, 3}。RCL的灵感来自于DCN[4],实现细节如图3所示。类似于DCN,我们用R表示规则的网格感受野和扩张。对于大小为3*3的核,我们有
,其中i∈{1, 2, 3}。RCL的灵感来自于DCN[4],实现细节如图3所示。类似于DCN,我们用R表示规则的网格感受野和扩张。对于大小为3*3的核,我们有
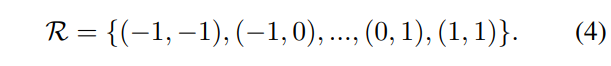
给定第i个位置的预定义偏移pi∈R,学习角θ,则学习到的偏移为
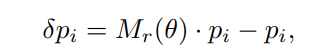
其中Mr(θ)是定义在Eqn (1)中的旋转矩阵。对于输出特征映射Xi中的每个位置p0,我们有

其中pn表示R中的位置,w为核权值
特征选择。为了使神经元具有自适应的感受野,我们采用注意机制以位置方式融合特征。Xi首先进入注意力块(由卷积核1*1、批量标准化和ReLU顺序组成)获取注意力映射![]() 。然后,我们连接通道方向的Ai,跟着SoftMax操作获取归一化选择权值
。然后,我们连接通道方向的Ai,跟着SoftMax操作获取归一化选择权值![]()

软注意融合了多个分支的特征
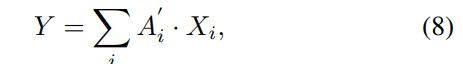
其中![]() 为输出特征。为了相似,我们省略了Y之前的通道扩展层。这里,我们展示了一个三个分支的例子,可以很容易地扩展到更多具有不同内核大小和形状的分支。
为输出特征。为了相似,我们省略了Y之前的通道扩展层。这里,我们展示了一个三个分支的例子,可以很容易地扩展到更多具有不同内核大小和形状的分支。
3.3。动态优化头
在标准的机器学习框架中,人们通常通过一个大的带注释的训练集来学习模型。在推理时,将试验实例输入参数固定的模型,得到预测结果。当经过良好训练的模型只能根据从训练集中学到的一般知识作出反应,而忽略每个例子的唯一性时,就会出现问题。
为了使模型能够根据每个样本进行响应,我们建议使用DRH来建模每个输入对象的特殊性。具体来说,可以使用两个不同的模块,即DRH-C和DRH-R分别进行分类和回归。
我们用一个三类分类问题的例子来说明我们的动机,如图1(a)左图所示。灰色圆形区域代表特征空间,实点代表三类实例。一些样本位于远离识别边界的地方,表明这些样本具有良好的语义可辨别性。
动态细化分类
DRH-C的架构如图4所示。给定一个输入特征映射![]() ,我们首先得到一个对象感知滤波器
,我们首先得到一个对象感知滤波器
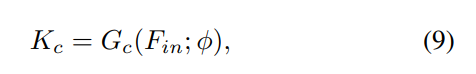
式中,Gc为动态滤波器发生器,φ为Gc参数集。Kc是已知的示例核权值。然后,我们通过卷积运算得到特征细化F
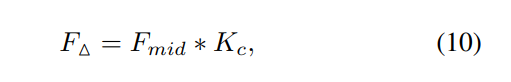
其中Fmid是通过核3 *3的一个卷积Conv-BN-ReLU块处理Fin的基本特征,表示卷积算子。最后得到分类预测Hc
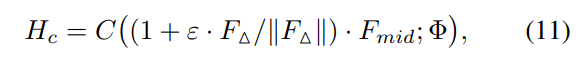
其中,C(·,Φ)表示参数为Φ的分类器,||.||为模运算。我们在每个位置的信道方向上规范化 F。归一化F表示基本特征Fmid的修改方向。我们根据其长度自适应地细化基本特征。ε是控制细化范围的恒定因素
对回归的动态改进。我们还在图1(b)中展示了一个简单的回归任务示例。橙色实心点代表样本的目标值,橙色曲线代表学习到的回归模型。对于回归任务,研究者通常会最小化L1或L2的平均距离;因此,学习到的模型不能准确拟合目标值。为了在不增加过拟合风险的情况下预测精确值,我们设计了一个类似于图中分类器的对象感知回归头。

给定特征映射Fin∈RH×W×C,首先通过Gr(·; ϕ)计算动态滤波器权重Kr;然后预测类似于Eqn10的改进因子HM。得到最终的对象感知回归结果H
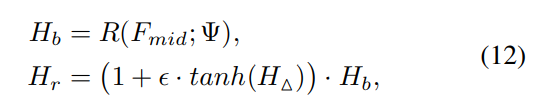
R(·;Ψ)为带参数的回归器.Hb是根据一般知识的基础预测值。细化因子的范围为[−1,1]通过tanh活化函数,$是防止模型被大细化所迷惑的控制因素.这个因子被设置为0,1在我们的实验中.
3.4。SKU110K-R数据
我们的SKU110K- r数据集是SKU110K[9]的扩展版本。原始的SKU110K数据集总共包含11,762张图像(8,233张用于训练,588张用于验证,2,941张用于测试)和1,733,678个实例。这些图像是从数千家超市中收集来的,具有不同的规模、观察角度、照明条件和噪音水平。所有的图像都被调整为1百万像素的分辨率。数据集中的大多数实例都是紧密打包的,通常具有[15,15]的特定方向。为了丰富数据集,我们通过将图像旋转6个不同的角度,即-45、-30、-15、15、30和45来进行数据增强。然后,我们通过众包的方式对每个实例的面向边框进行标注,得到我们的SKU110K-R数据集。关于SKU110-的更多细节,请参考我们的补充资料















 4340
4340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









