







DRN

论文地址:https://arxiv.org/pdf/2005.09973.pdf
开源代码:https://github.com/Anymake/DRN_CVPR2020
本文亮点:
- 对SKU110K-R这个数据集通过旋转进行旋转目标物体的数据增强。
- 提出动态选择head,分别对回归(角度、尺寸和偏移量)和分类进行预测。
Abstract
- 定向和密集的目标检测仍然存在问题:
- 神经元的感受野都是相同形状呈现轴向排列,而目标通常形状不同,并且沿着不同方向排列。
- 检测模型是用一般知识训练的,在测试阶段时可能不能很好地泛化处理特定的目标。
- 有限的数据集阻碍了这类任务的发展。
- 提出的解决办法:
- 为解决第1个和第2个问题,作者提出了动态精细化网络,包括FSM(特征选择模块)、DRH(动态优化 head)。——FSM能够根据目标物体的形状和方向位置调整神经元的感受野。DRH能使模块以目标感知的方式动态地优化预测。
- 为解决第3个问题,扩展了含完整标注的数据集: SKU110K-R,这是基于SKU110K定向边界框重新标定的数据集。
- 在DOTA、HRSC2016、SKU110K、SKU110K-R 数据集多个公开 baseline 进行定量评估。
1 Introduction
-
目前的检测器在训练时优化参数,训练后保持固定的参数不变,这种静态数据在测试阶段不够灵活,可能检测不到特定的样本。
-
基于RCNN的网络,首先生成大量的水平边界框作为RoI,然后根据RoIs进行位置回归和分类的预测。
-
在特定的目标,这种使用水平RoIs的方法会导致边界框和定向目标间的失调。比如,航拍下目标会产生多个实例被单一实例所涵盖。
-
使用定向边界框作为anchor来处理旋转目标,因为anchors大量角度不同、尺寸不同、纵横比不同导致计算量比较大。
-
动态滤波器时一种简单而有效的方法,可以使模型在不同的样本中变化。
-
基于CenterNet,增加角度预测head作为baseline,提出了本文网络——DRN(Dynamic Refinement Network)。
-
本文的贡献:
- 提出一种基于目标形状和方向的自适应调整神经元感受野的模块。该FSM模块能有效地缓解感受野和目标之间的失调。
- 提出两个DRH,即DRH-C和DRH-R(分别用于分类和回归任务)。这些DRHs可以根据每一个样本的唯一性和特殊性建模,并以一种面向对象的方法进行预测。
- 收集了SKU110K-R,包含对定向边界框精细标注。
- 在DOTA、HRSC2016、SKU110K和SKU110KR中,我们的方法在定向和密集填充对象检测方面取得了一致和实质性的进展。

图解:
- (a)分类任务(b)回归任务
- 箭头表示可以通过动态精细化进行调整。该图表示分类和回归上的动态改进效果。
- (a)灰色圆形代表特征空间,点代表三个类别的样本。一些样本远离边界说明这些样本具有良好的识别语义性能。
- (b)橙色实心点表示例子的目标值,橙色曲线代表学习的回归模型。
2 Related Work
- RoI Trans : 将轴对齐的RoI转换成可旋转的RoI,解决RoI与定向目标之间的错位问题。
- SCRDet: 在Smooth L1 loss中增加IOU常数因子,解决定向边界框的边界问题。
- FSAF: 学习一个anchor-free模块动态选择最适合的特征level。
- Dynamic anchor feature selection for single-shot object detection: 提出一种基于新定位点位置和大小的动态特征选择模块。
- SKN: 提出使用不同的卷积核在每个位置选择具有不同感受野的特征。
- SENet: 自适应调整并校准信道特征响应。
- CBAM: 采取多个空间注意力模型对空间之间的关系进行建模。
- Active convolution: 用偏移量增加卷积层中的采样位置,该模型在不同的空间位置共享偏移量,训练后的模型参数是静态的。
- Deformable convolutional network (DCN) : 对图像中的密集空间变化进行建模,偏移量是动态模型输出。
- RoI Trans: 学习了五个offsets,类似于位置敏感的RoI Align对齐方式,将轴对齐RoI转换为旋转RoI。
- ORN: 提出了在卷积过程中主动旋转的有源旋转滤波器。旋转角度是一个超参数,是一个固定的数,所有的位置共享相同的旋转角度。
- 神经网络引入动态滤波器,根据输入特征和切换样本进行调节。动态滤波器在训练阶段学习滤波器权重,从而可以在推理阶段提取样本特征。
- CARAFE: 提出一个内核预测模块,该模块负责以内容感知的方式重组卷积核。
- DCN和RoI Trans: 它们对偏移预测进行动态建模,不改变核权重。
3 Method
3.1 Network Architecture
- 基于CenterNet网络修改,添加一个分支来回归bbox的方向。

图解:
- 动态改进网络整体架构图。
- 输入经过hourglass网络,输出两个分支(angle,FSM)。经过FSM调整感受野大小,输出三个分支(size,offset,heatmap)。
公式介绍:
-
模型的输出bbox :
使用的参数有 ( c x , c y , h , w , θ , δ x , δ y ) (c_{x},c_{y},h,w,\theta ,\delta _{x},\delta _{y}) (cx,cy,h,w,θ,δx,δy)
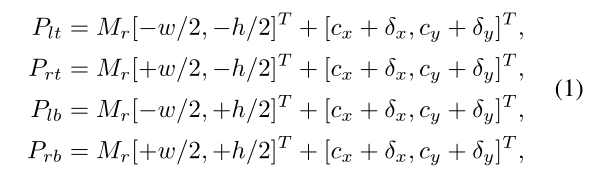
参数说明:
( c x , c y ) 和 ( δ x , δ y ) (c_{x},c_{y}) 和(\delta _{x},\delta _{y}) (cx,cy)和(δx,δy)分别是中心点和预测偏移量, ( w , h ) (w,h) (w,h)是预测的宽和高, M r M_{r} Mr是旋转矩阵, P l t , P r t , P l b , P r b P_{lt},P_{rt},P_{lb},P_{rb} Plt,Prt,Plb,Prb是bbox的四个角点。 -
旋转角度的回归:
使用L1 loss损失来计算旋转角度的回归。
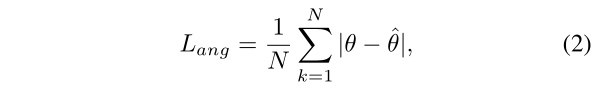
参数说明:
θ \theta θ和 θ ^ \hat{\theta} θ^分别是目标和预测的旋转角度。 N N N是正样本的个数。 -
总的损失函数:
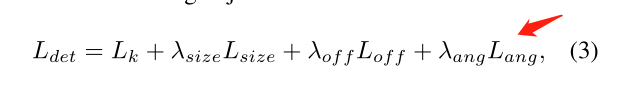
参数说明:
与CenterNet一样, L k , L s i z e , L o f f L_{k},L_{size},L_{off} Lk,Lsize,Loff分别表示中心点的识别,尺寸预测回归和偏移回归的损失。 λ s i z e , λ o f f , λ a n g \lambda_{size}, \lambda _{off}, \lambda _{ang} λsize,λoff,λang均为常数因子,设置为0.1。
3.2 Feature Selection Module
- FSM 用于自适应地聚合提取不同的核大小、形状和方向的信息。

图解:
- 上面: 特征选择模块。下面: 旋转卷积层。
- 特征选择方式:为了增强神经元的自适应性,采用一种类似注意力机制,以位置的方式来融合特征。
- FSM流程:
-
设初始特征图 X ∈ R H × W × C X\in \mathbb{R}^{H\times W\times C} X∈RH×W×C,经过 1 × 1 C o n v + B N + R e l u 1\times1 Conv+ BN+ Relu 1×1Conv+BN+Relu 输出 X c ∈ R H × W × C ‘ X_{c}\in \mathbb{R}^{H\times W\times C‘} Xc∈RH×W×C‘。
-
X c X_{c} Xc分成三部分,分别在 3 × 3 3\times3 3×3, 1 × 3 1\times3 1×3, 3 × 1 3\times1 3×1旋转卷积核(RCL)下做卷积,每一个小部分负责不同的感受野。将三个部分 X i , ( i = 1 , 2 , 3 ) X_{i},(i=1,2,3) Xi,(i=1,2,3)分别进行输入注意力块中,分别输出注意力特征图 A i ∈ R H × W × 1 , ( i = 1 , 2 , 3 ) A_{i}\in \mathbb{R}^{H\times W\times1},(i=1,2,3) Ai∈RH×W×1,(i=1,2,3),然后在通道上concat A i A_{i} Ai并使用Softmax获得归一化的选择权重 A i ’ A_{i}’ Ai’,最后使用软注意力融合 X i X_{i} Xi和 A i ’ A_{i}’ Ai’的特征,输出最后结果 Y Y Y。这部分可以扩展到更多不同内核大小和形状的分支。
-
RCL灵感来源于DCN,使用 R R R表示规则的网格感受野与扩张参数。比如, 3 × 3 3\times3 3×3卷积核为
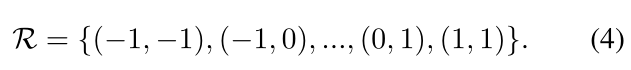
-
RCL启发引入:

上图是在二维平面上可变形卷积核普通卷积的描述。
(a)是普通卷积,卷积核大小为3×3,采样点排列非常规则,是一个正方形。
(b)是可变形的卷积,给每个采样点加一个offset(这个offset通过额外的卷积层学习得到),排列变得不规则。
(c)和(d)是可变形卷积的两种特例。对于(c)加上offset,达到尺度变换的效果。而(d)是上offset,达到旋转变换的效果。(图(d)就是我们这篇文章使用的RCL)。 -
RCL流程:
下图是可变形卷积的流程图。

下图是本文RCL框架图。 原始的卷积核,在通过额外conv层学到的参数θ,把之前标准的卷积核变成带有参数θ的旋转卷积核,得到offset,共享输入的特征图,然后输入特征图与offset共同作为旋转卷积层的输入。

公式介绍:
-
已学习的偏移量:
给定第 i i i个位置和已学习的角度 θ \theta θ的预定义偏移量 p i ∈ R p_{i}\in R pi∈R,已学习的偏移量定义为:
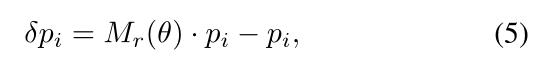
其中, M r ( θ ) M_{r}(\theta) Mr(θ)是公式(1)定义的旋转矩阵。 -
经过RCL输出的特征图 X i X_{i} Xi:
对于每一个位置 p 0 p_{0} p0,都有输出的特征图为 X i ( p 0 ) X_{i}(p_{0}) Xi(p0)为:
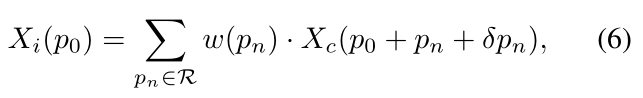
其中, p n ) p_{n}) pn)表示在 R R R中的位置参数, w w w表示核权重。 -
归一化选择权重:
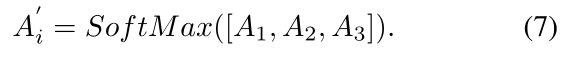
-
最后输出特征图:
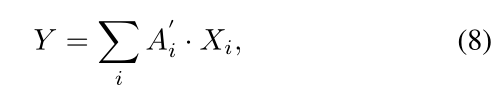
其中, X ∈ R H × W × C X\in \mathbb{R}^{H\times W\times C} X∈RH×W×C 与输入的通道数、宽高一致。
3.3 Dynamic Refinement Head
- DRH用于解决推理阶段,测试集输入到固定参数的模型中会产生预测灵活性差的问题。为解决这个问题,提出DRHs对每个输入对象的特征性进行建模。
- 有两个任务,回归与分类。
- 回归任务的输入: 由三个部分组成,主干网输出的特征图一部分输入到特征选择模块中,另一部分输入到angle(角度预测)中。从特征选择模块出来的特征图(Y),输入到size(尺寸预测)和offset中做回归检测。
- 回归任务的输出: 得到回归位置,包括角度、尺寸大小、偏移量。
- 分类任务的输入: 从特征选择模块出来的特征图(Y),输入到heatmap中。
- 分类任务的输出: 得到类别的特征热图。
(为了方便阅读,把网络框架放在这里)
可以看到最右边的标注,绿色代表回归任务的输入输出,棕色代表分类任务的输入输出。
- 分类:

图解及公式说明:
-
给定输入 F i n ∈ R H × W × C F_{in}\in R^{H\times W\times C} Fin∈RH×W×C,首先得到目标感知过滤器 K c K_{c} Kc:
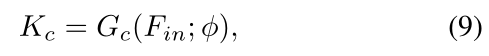
参数说明: G c G_{c} Gc表示动态滤波生成器, ϕ \phi ϕ表示 G c G_{c} Gc的参数集。 K c ) K_{c}) Kc)表示从例子中学习到的核权重。 -
然后, F m i d F_{mid} Fmid和滤波器 K c K_{c} Kc卷积操作得到特征细化 F △ F_{\bigtriangleup } F△ :
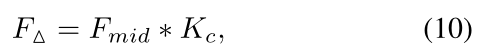
参数说明: F m i d F_{mid} Fmid是通过 F i n F_{in} Fin的基本特征处理(Conv-BN-ReLU)。 -
最后,使用 F m i d F_{mid} Fmid和 F △ F_{\bigtriangleup } F△得到分类预测 H c H_{c} Hc:
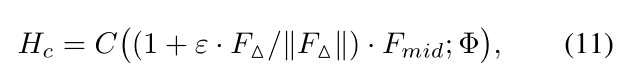
参数说明: C ( ⋅ , Φ ) C(·,Φ) C(⋅,Φ) 表示带有参数量Φ的分类器。 ∣ ∣ ⋅ ∣ ∣ ||\cdot || ∣∣⋅∣∣表示模运算,用于对每个位置的通道方向进行标准化,标准化后的 ∣ ∣ F △ ∣ ∣ ||F_{\bigtriangleup }|| ∣∣F△∣∣引导基础特征 F m i d F_{mid} Fmid的修改方向。根据特征长度自适应地对基本特征进行细化。ε是控制细化范围的常数因子。
- 回归:

- 对于回归任务,通常使用最小化L1或L2的平均距离。为了预测准确而不增加过度拟合,设计了图5的检测头。
图解及公式说明:
- 给定输入
F
i
n
∈
R
H
×
W
×
C
F_{in}\in R^{H\times W\times C}
Fin∈RH×W×C,首先通过
G
r
(
⋅
,
φ
)
G_{r}(·,φ)
Gr(⋅,φ)计算动态滤波器权重
K
r
K_{r}
Kr,然后通过类似公式(10)计算得到
H
△
H_{\bigtriangleup}
H△,最后计算得到目标感知回归结果
H
r
H_{r}
Hr。
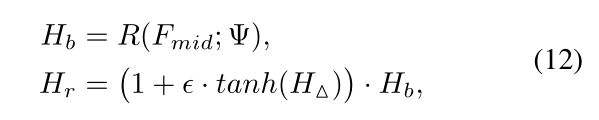
参数说明:
R ( ⋅ , Ψ ) R(·,Ψ) R(⋅,Ψ) 表示带有参数量Ψ的回归器。 H b H_{b} Hb表示基于一般知识的基本预测值。细化因子通过 t a n h tanh tanh激活函数在[-1, 1]范围内变化。 ϵ \epsilon ϵ表示防止模型被过大细化而混淆的控制因子,设置为0.1。
3.4 SKU110K-R Dataset
- SKU110K-R 是SKU110K的扩展版本。
- 原始SKU110K数据集包含11,762张图片(8,233张用于训练,588张用于验证,2,941张用于测试)和1,733,678个实例。
- 数千家超市商品图片,不同视角、比例、照明条件和噪声条件。
- SKU110K范围是[-15°,15°]。
- SKU110K-R将SKU110K图像旋转六个不同的角度(-45°, -30°, -15°, 15°, 30°, 和45°)进行数据扩展和增强。

4 Experiments
- 数据集: DOTA,HRSC2016,SKU110K-R
- backbone: hourglass-104
- 输入的图片大小: DOTA是1024×1024,HRSC2016,SKU110K-R 都是768×768。
4.1 Experimental Results

图解:
- 动态改进网络(DRN)与其他方法在 DOTA 数据集上的 OBB 任务评估结果对比。
- 实验表明,多尺度方法在SCRDet和DRN模型上mAP效果差不多,在某些类别中SCRDet检测效果还高一些。(本文是anchor-free的方法,能够比两阶段的mAP差不多,说明提出的模块是有效的。)
- 使用翻转和多尺度,使得本文提出的方法提升了0.28%。

图解:
- 实验表明,DRN方法在HRSC2016数据集上,mAP方面获得了6.4%的提升。
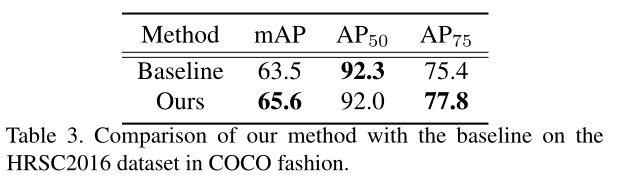
图解:
- COCO格式中的HRSC2016数据集的mAP效果。

图解:
- 显示SKU110K-R和SKU110K数据集上的结果。
- CenterNet-4point†表示对每个边界框的四个角进行回归,CenterNet†表示添加了中心池化。
4.2 Ablation Study
- backbone:hourglass-52
- kernel: (3,3)表示方形,(1,3)表示扁平矩形,(3,1)表示细长矩形。

图解:
- DOTA验证集上进行FSM的消融实验。MK表示使用多核,DCN表示可变形卷积,ROT表示旋转卷积核。
- 实验表明,(3,3),(1,3),(3,1)的卷积核使得FSM模块提升效果不太明显,而使用ROT提升效果比较明显,因为RCL使神经元能够通过旋转来调节感受野。
- 三分裂的FSM使神经元能够在两个自由度中(旋转,形状)调节感受野。
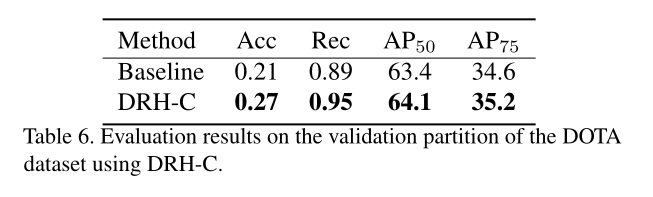
图解:
- DOTA验证集上使用DRH-C,精度提高了0.06%,召回率提高了0.06%。

图解:
- 在DOTA上,使用标准的L1来计算GT和预测的误差。
- DRH-R使用尺度、角度和偏移量这三个单独的head研究,看出只有scale改善比较明显。
- L1的误差降低了1.24,AP50和AP75分别提高了0.7%,0.6%。

图解:
- DOTA和HRSC2016一些检测结果图。

图解:
- 增加了一些测试时间和参数量,AP提升了2.3%。
5 Conclusion
- 提出一种基于目标形状和方向的自适应调整神经元感受野的模块。
- 提出两个DRH来动态细化预测。
- 使用SKU110K数据集重新标记,命名为SKU110K-R。
- 使用大量的实验证明本文方法的有效性。
















 856
856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









