







下面主要介绍一下如何利用python对数值型变量相关性进行判断
1.什么是相关性?
相关性,是指两个变量的关联程度。一般地,从散点图上可以观察到两个变量有以下三种关系之一:两变量正相关、负相关、不相关。如果一个变量高的值对应于另一个变量高的值,相似地,低的值对应低的值,那么这两个变量正相关。在土壤中,孔隙率和渗透度就具有典型的正相关。反之,如果一个变量高的值对应于另一个变量低的值,那么这两个变量负相关。如果两个变量间没有关系,即一个变量的变化对另一变量没有明显影响,那么这两个变量不相关。
https://baike.baidu.com/item/相关性/10097225?fr=ge_ala

总的来说,了解任何关系的目的都是为了帮助我们更好的认识、理解、描述和预测事物。
2.如何判定相关关系?
2.1快速画图,初始判断数据特征
这里我们以python内置数据为例,当我们拿到一组数据时,如果想要判断他们是否具有相关性,看如何通过快速画图先了解大概数据特征。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns; sns.set(color_codes=True)
from sklearn import datasets
# 加载内置的iris数据集
iris = datasets.load_iris()
X= iris.data
Xdata = pd.DataFrame(X)
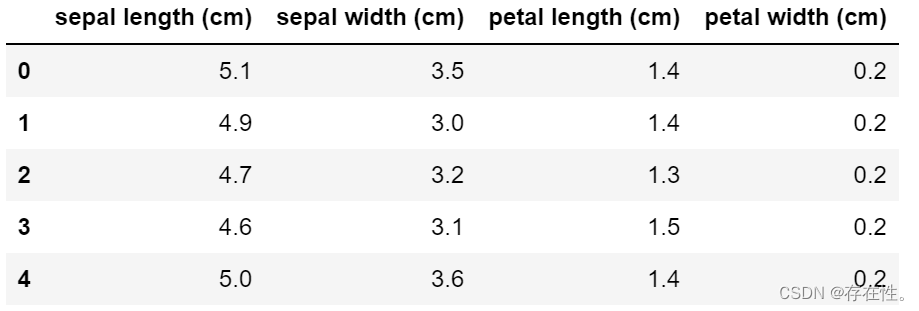
Xdata.columns = iris.feature_names #每个样本都有4个特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度
Xdata.head()
2.1.1seaborn.pairplot 画两两特征图
- 函数pairplot作用:用来进行数据分析,画两两特征图。
- 函数原型:
seaborn.pairplot(data, hue=None, hue_order=None, palette=None, vars=None, x_vars=None, y_vars=None,
kind=’scatter’, diag_kind=’hist’, markers=None, size=2.5, aspect=1,
dropna=True, plot_kws=None, diag_kws=None, grid_kws=None)
- 常用参数介绍:
data:必不可少的数据
hue: 用一个特征来显示图像上的颜色,类似于打标签
marker: 每个label的显示图像变动,有的是三角,有的是原点
vars:只留几个特征两两比较
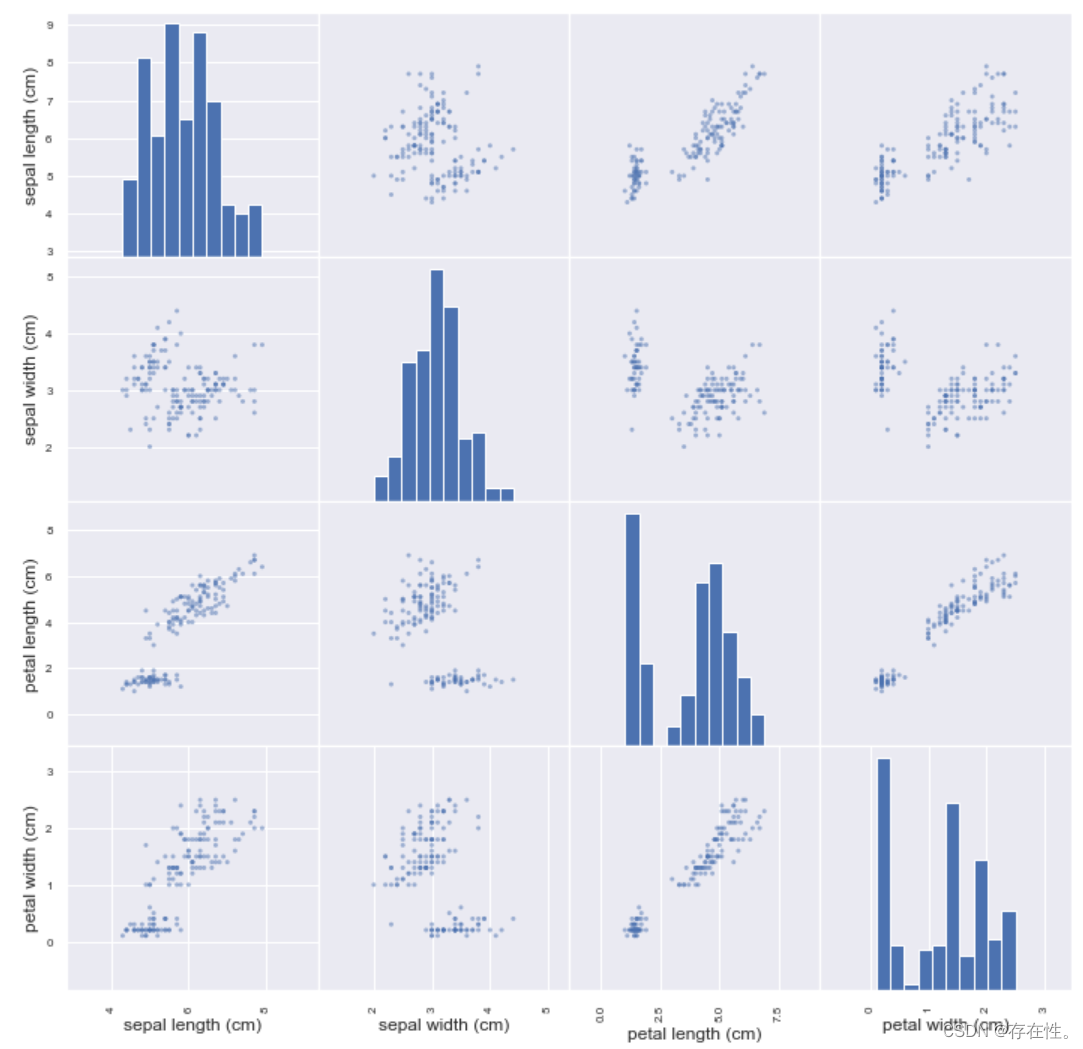
sns.pairplot(Xdata)
效果图如下

用sns.pairplot函数可以快速画出两个变量之间的散点图和自身的分布图。
pairplot官方函数链接:
http://seaborn.pydata.org/generated/seaborn.pairplot.html#seaborn.pairplot
2.1.2 pd.plotting.scatter_matrix 画两两特征图
- 函数plotting.scatter_matrix作用:使用散点图矩阵图,可以两两发现特征之间的联系
- 函数原型
pd.plotting.scatter_matrix(frame, alpha=0.5, c,figsize=None, ax=None, diagonal='hist',
marker='.', density_kwds=None,hist_kwds=None, range_padding=0.05, **kwds)
- 常用参数介绍
frame:pandas dataframe对象
alpha:图像透明度,一般取(0,1]
figsize:以英寸为单位的图像大小,一般以元组 (width, height) 形式设置
diagonal:必须且只能在{‘hist’, ‘kde’}中选择1个,‘hist’表示直方图(Histogram plot),‘kde’表示核密度估计(Kernel Density Estimation);该参数是scatter_matrix函数的关键参数
marker,Matplotlib可用的标记类型,如’.’,‘,’,'o’等
density_kwds:(other plotting keyword arguments,可选),与kde相关的字典参数
hist_kwds:与hist相关的字典参数
range_paddin:(float, 可选),图像在x轴、y轴原点附近的留白(padding),该值越大,留白距离越大,图像远离坐标原点
kwds:与scatter_matrix函数本身相关的字典参数
c:颜色
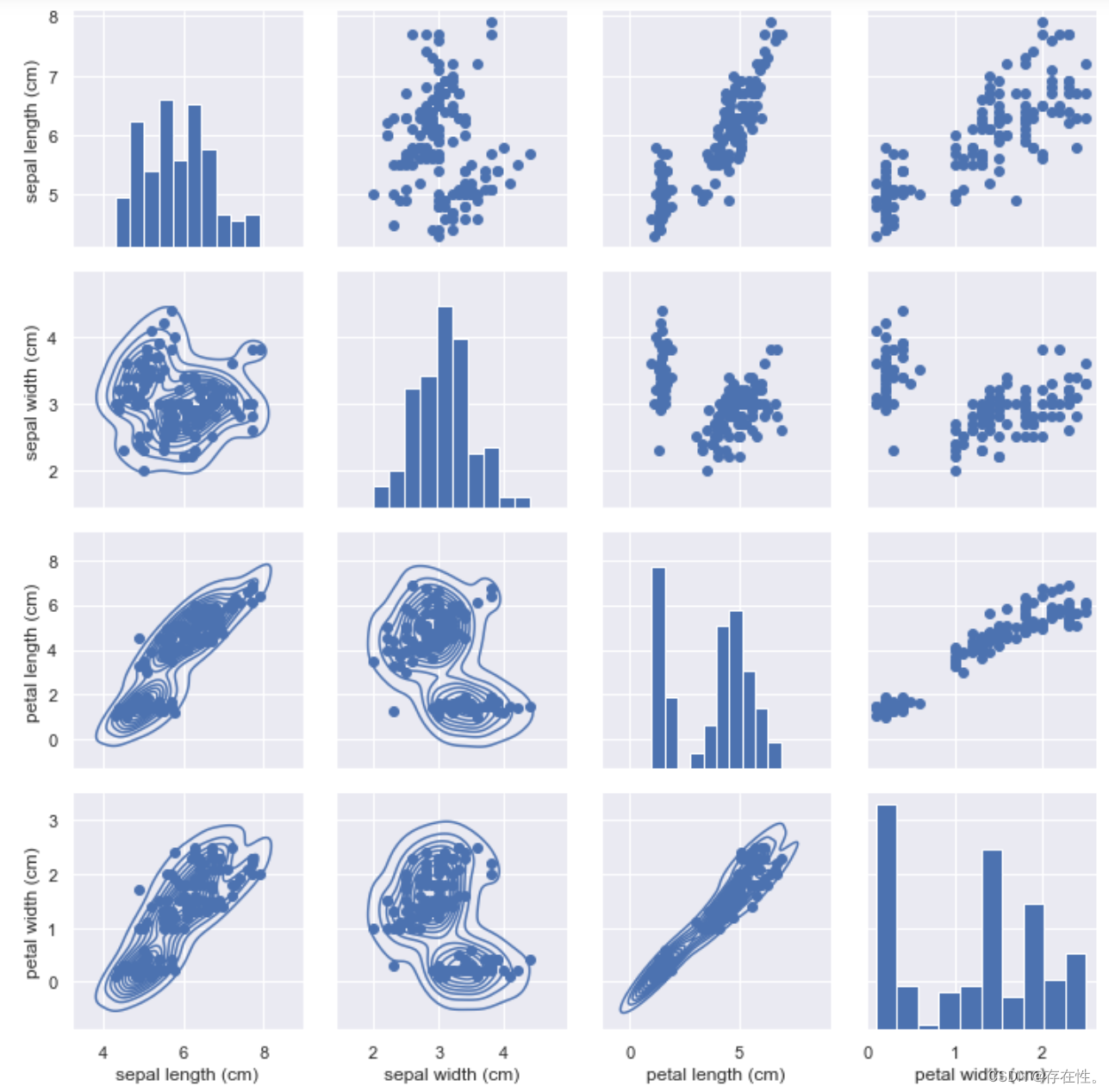
pd.plotting.scatter_matrix(Xdata,figsize=(12,12),range_padding=0.8)
效果图如下
2.1.3 seaborn.PairGrid多图网格
- 函数plotting.scatter_matrix作用:使用散点图矩阵图,可以两两发现特征之间的联系
- 函数原型
sns.PairGrid(data,hue=None,hue_order=None,palette=None,hue_kws=None,
vars=None,x_vars=None,y_vars=None,diag_sharey=True,height=2.5,
aspect=1,despine=True,dropna=True,size=None,)
- 常用参数介绍
data:DataFrame格式
hue:将绘图的不同面映射为不同的颜色
palette:调色板
vars:使用data中的变量,否则使用一个数值型数据类型的每一列。
height标量:可选,每个刻面的高度(以英寸为单位)
aspect:标量,可选,aspect 和 height 的乘积得出每个刻面的宽度(以英寸为单位)
despine:布尔值,可选,从图中移除顶部和右侧脊柱。
dropna:布尔值,可选,在绘图之前删除数据中的缺失值。
g= sns.PairGrid(Xdata)
g = g.map_diag(plt.hist)
g = g.map_offdiag(plt.scatter)
g = g.map_lower(sns.kdeplot)
g = g.add_legend()
效果图如下
2.2使用相关系数精确计算
通过快速画图对数据的认识是粗略大概的,想要精确的知道两者之间的关系,需要引入相关系数。
-
相关系数,是以数值的方式来精确地反映两个变量之间线性相关的强弱程度的,经常用字母r来表示相关系数。
-
相关系数的特征如下:
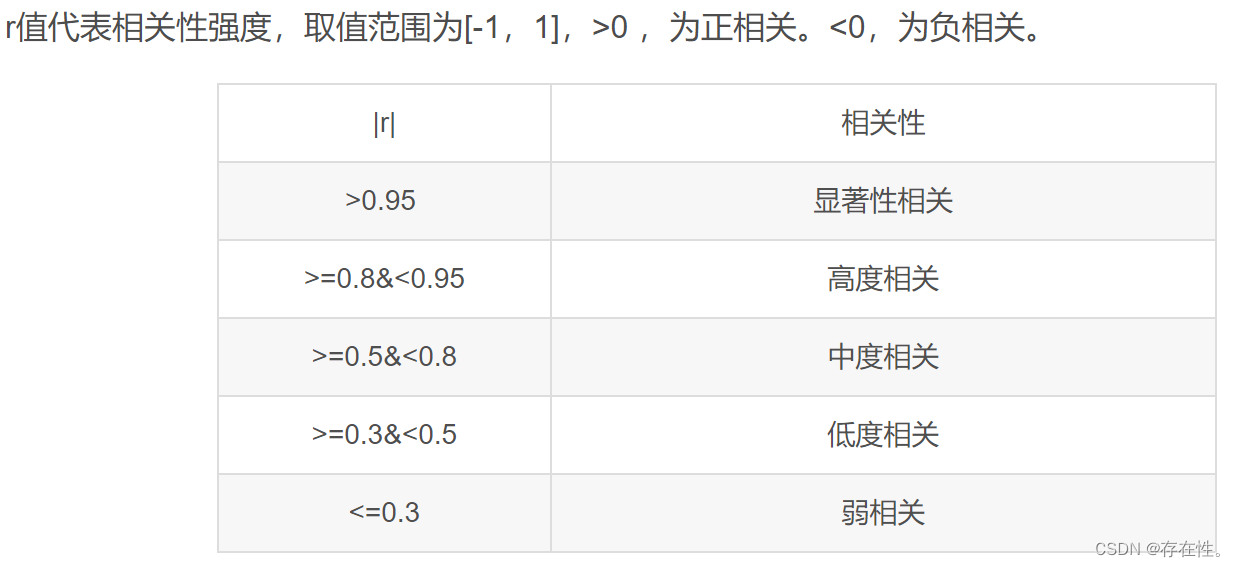 来自 https://www.zhihu.com/question/31992750/answer/2238103559
来自 https://www.zhihu.com/question/31992750/answer/2238103559 -
对于两两变量之间的相关性,这里主要介绍以下3种相关系数:Pearson相关系数、Spearman相关系数、kendall相关分析
https://zhuanlan.zhihu.com/p/353541738?utm_id=0
https://baijiahao.baidu.com/s?id=1789055704401470445&wfr=spider&for=pc
2.2.1 Pearson相关系数
写的过程中发现的好文章分享给大家https://zhuanlan.zhihu.com/p/172155247?utm_id=0

方法1:numpy.corrcoef()
https://blog.csdn.net/qq_39514033/article/details/88931639 关于该函数可详细参考以上链接
- 函数numpy.corrcoef:返回皮尔逊积矩相关系数。
numpy.corrcoef(x, y=None, rowvar=True, bias=<no value>, ddof==<no value>)
- 参数
x :array_like,一维或二维数组,其中包含多个变量和观察值。 x的每一行代表一个变量,每列代表所有这些变量的单个观察值。另请参见下面的rowvar。
y :array_like, 可选一组额外的变量和观察值。 y与x具有相同的形状。
rowvar :bool, 可选,如果rowvar为True(默认值),则每一行代表一个变量,各列中带有观察值。 否则,该关系将转置:每一列代表一个变量,而行包含观察值。 - 返回值
R :ndarray,计算矩阵的相关系数,返回Pearson乘积矩相关系数的矩阵。
效果如下:
#x的每一行代表一个变量,每一列都是对所有这些变量的单一观察
correlation_matrix = np.corrcoef(Xdata.T,Xdata.T)
correlation_matrix

方法2:pandas.corr 函数(无显著性检验)
- 参数解析
DataFrame.corr(
method = ‘pearson’,
# 可选值为{‘pearson’:‘皮尔森’, ‘kendall’:‘肯德尔秩相关’, ‘spearman’:‘斯皮尔曼’}
min_periods=1 # 样本最少的数据量
)
#默认为pearson
效果见下:
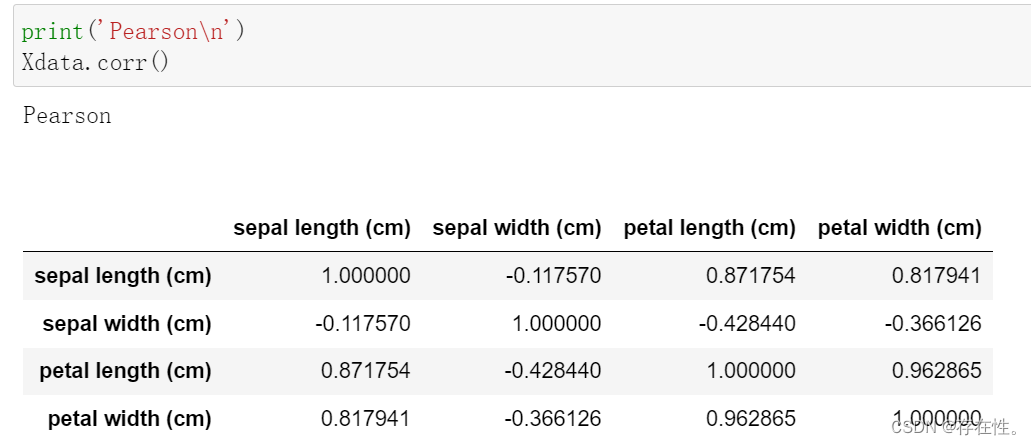
print('Pearson\n')
Xdata.corr()
方法3:scipy.stats.pearsonr 函数 (有显著性检验)
官方文档https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.pearsonr.html#scipy.stats.pearsonr
- 函数scipy.stats.pearsonr()
scipy.stats.pearsonr(x, y, *, alternative='two-sided', method=None)[source]
- 参数
x: (N,) 数组
输入数组。
y: (N,) 数组
输入数组。
alternative: {‘双面’,‘greater’, ‘less’},可选
定义备择假设。默认为“双面”。可以使用以下选项:“双边”:相关性不为零,‘less’:相关性为负(小于零),‘greater’:相关性为正(大于零)
method: 重采样方法,可选定义用于计算 p 值的方法。如果方法是一个实例PermutationMethod/MonteCarloMethod,p 值的计算方法scipy.stats.permutation_test/scipy.stats.monte_carlo_test使用提供的配置选项和其他适当的设置。否则,p 值将按照注释中的记录进行计算。 - 返回
result: PearsonRResult
具有以下属性的对象:统计 浮点数;皮尔逊 product-moment 相关系数。
p值 浮点数:与所选替代方案相关的 p 值。
效果如下:
#scipy.stats.pearsonr 函数 (有显著性检验)
from scipy.stats import pearsonr
r = pearsonr(Xdata['sepal length (cm)'],Xdata['petal length (cm)'])
print("pearson系数:",r[0])
print(" P-Value:",r[1])

注意:该方法不能一次性计算所有变量两两组合的相关性,想要一次性计算两两变量之间的pearsonr相关系数且进行显著性检验,可采用
pandas.corr 加 scipy.stats.pearsonr 获取相关系数检验P值矩阵。
效果见下:
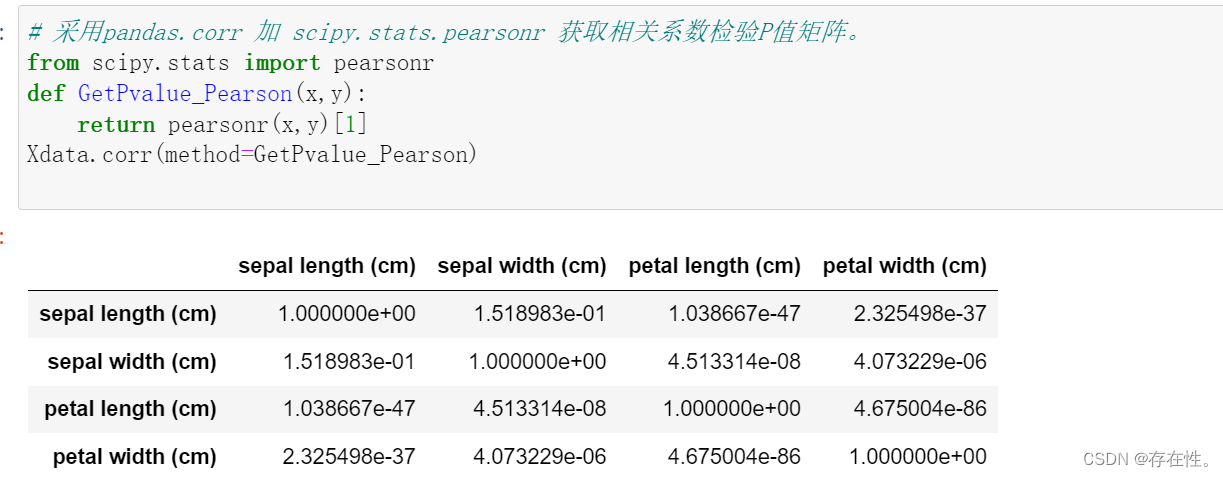
# 采用pandas.corr 加 scipy.stats.pearsonr 获取相关系数检验P值矩阵。
from scipy.stats import pearsonr
def GetPvalue_Pearson(x,y):
return pearsonr(x,y)[1]
Xdata.corr(method=GetPvalue_Pearson)
Spearman 相关系数是一种非参数的相关系数,用于度量两个变量的单调关系,不要求变量满足正态分布和线性关系。
2.2.2 Spearman相关系数
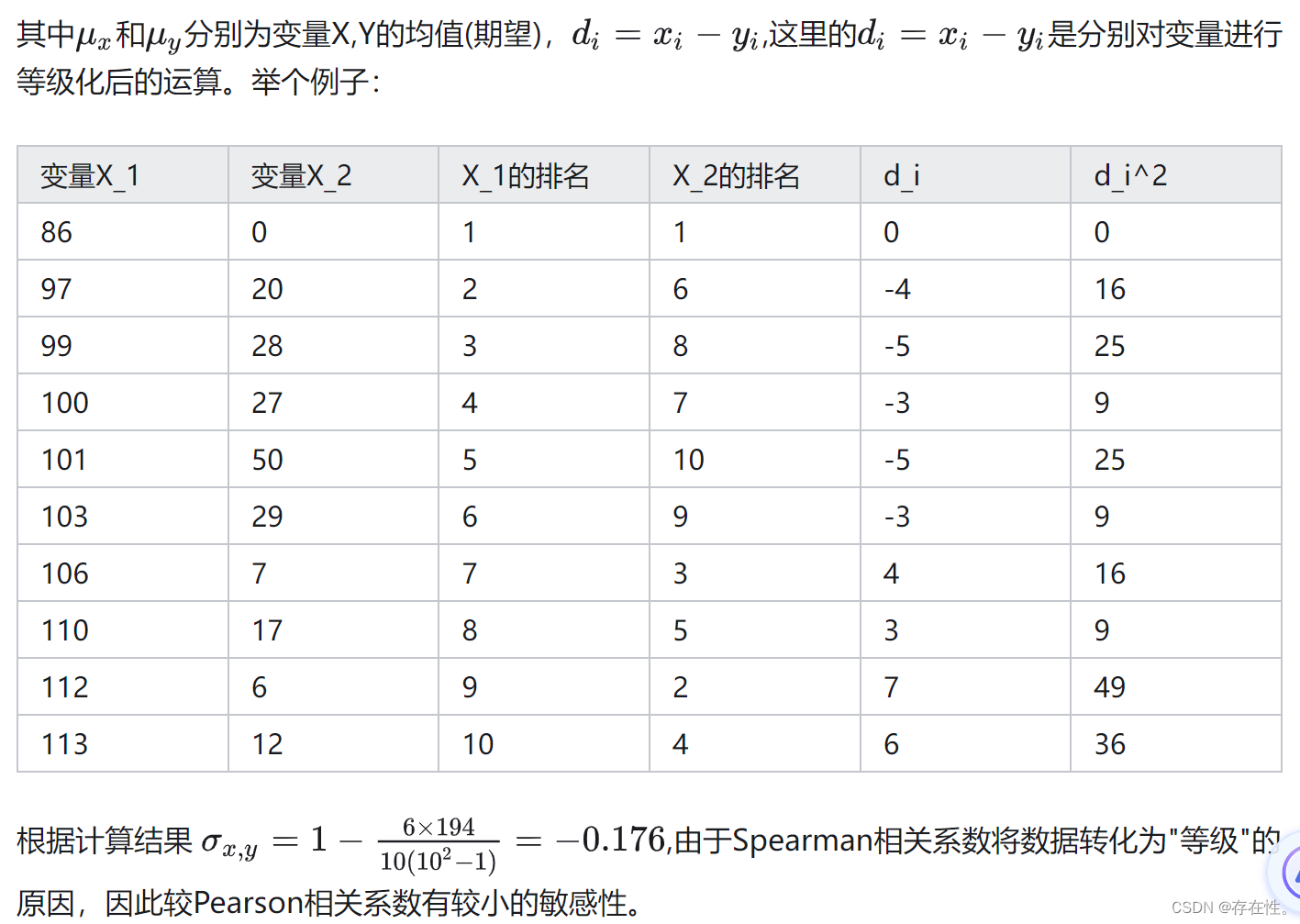
在 统计学中, 以查尔斯·爱德华·斯皮尔曼命名的斯皮尔曼等级相关系数,即spearman相关系数。经常用希腊字母ρ表示。 它是衡量两个变量的依赖性的 非参数 指标。 它利用单调方程评价两个统计变量的相关性。Spearman相关性的基本思想是:分别对两个变量X、Y做等级变换(rank transformation),用等级RX和RY表示;然后按Pearson相关性分析的方法计算RX和RY的相关性 [1]。 如果数据中没有重复值, 并且当两个变量完全单调相关时,斯皮尔曼相关系数则为+1或−1。
搬运百度工https://baike.baidu.com/item/spearman相关系数/7977847

方法1:scipy.stats.spearmanr 函数 (有显著性检验)
scipy.stats.spearmanr()官网链接https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.spearmanr.html
- 函数scipy.stats.spearmanr()
scipy.stats.spearmanr(a, b=None, axis=0, nan_policy='propagate', alternative='two-sided')
- 参数
a, b: 1D 或 2D 数组,b 是可选的
一个或两个包含多个变量和观测值的一维或二维数组。当这些是一维时,每个代表单个变量的观察向量。对于 2-D 情况下的行为,请参见下面的 axis 。两个数组需要在axis 维度中具有相同的长度。
axis: int 或无,可选
如果axis=0(默认),则每列代表一个变量,行中包含观察值。如果axis = 1,则关系被转置:每一行代表一个变量,而列包含观察值。如果axis=None,那么两个数组都将被解开。
nan_policy: {‘propagate’, ‘raise’, ‘omit’},可选
定义当输入包含 nan 时如何处理。以下选项可用(默认为‘propagate’):
‘propagate’:返回 nan
‘raise’:引发错误
‘omit’:执行忽略 nan 值的计算
alternative: {‘双面’,‘less’, ‘greater’},可选
定义备择假设。默认为“双面”。可以使用以下选项:
“双边”:相关性不为零
‘less’:相关性为负(小于零)
‘greater’:相关性为正(大于零)
- 返回
res: SignificanceResult包含属性的对象:统计 float 或 ndarray(二维正方形),Spearman 相关矩阵或相关系数(如果仅给出 2 个变量作为参数)。相关矩阵是正方形,长度等于a 和b 中变量(列或行)总数的总和。
p值 浮点数:假设检验的 p 值,其原假设是两个样本没有序数相关性。有关替代假设,请参阅上面的替代方案。 pvalue 与统计量具有相同的形状。
关于spearmanr的优秀文档https://vimsky.com/examples/usage/python-scipy.stats.spearmanr.html
效果见下:
#scipy.stats.spearmanr 函数 (有显著性检验)
from scipy.stats import spearmanr
r = spearmanr(Xdata['sepal length (cm)'],Xdata['petal length (cm)'])
print("spearmanr:",r[0])
print(" P-Value:",r[1])

方法2:pandas.corr(‘spearman’)
print('Spearman\n')
Xdata.corr('spearman')

2.2.3 kendall等级相关分析

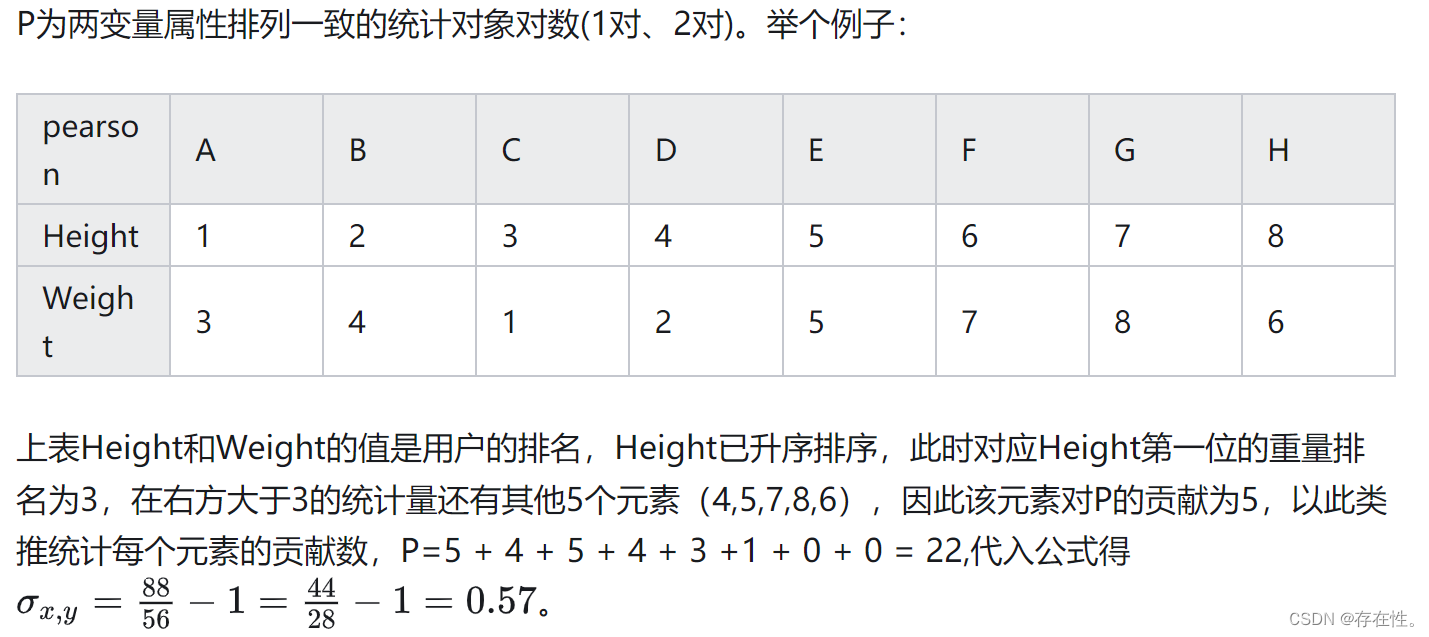
在这里插入图片描述
来自 https://blog.csdn.net/team39/article/details/121237071
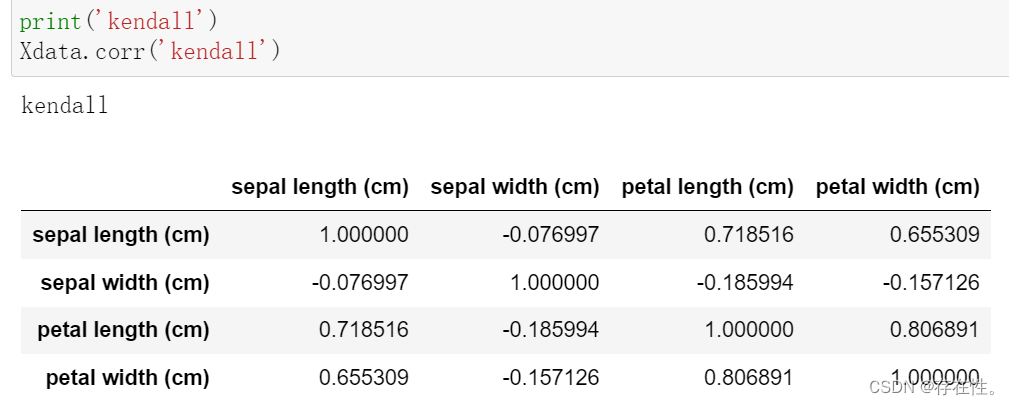
方法1:pandas.corr(‘kendall’)
print('kendall')
Xdata.corr('kendall')
方法2:scipy.stats.kendalltau函数 (有显著性检验)
from scipy.stats import kendalltau
kendalltau(Xdata['sepal length (cm)'],Xdata['petal length (cm)'])

2.3 相关系数的假设检验
关于kendalltau相关系数和spearman相关系数都是有显著性检验的,关于如何进行相关系数检验下面进行简介。

通常以5%为阈值(这里的阈值也称为显著水平),如果 p<0.05,则说明可以拒绝原假设。接受备择假设,即两变量之间存在显著的线性关联
3.其他备注
3.1相关和因果的关系
- 相关性是指当一个变量发生变化时,另一个变量也会朝着特定的方向变化。换句话说,两个变量一起变化。
- 因果关系表示一个变量的变化会引发另一个变量的变化。例如,增加药物剂量会导致症状严重度降低。
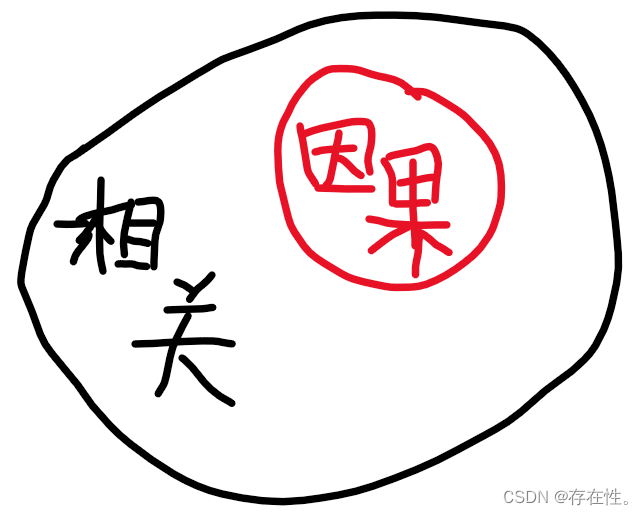
因此,因果一定相关,相关不一定因果。相关关系是对称性的,而因果关系是非对称性的,相关关系表示变量间存在某种程度的关联性,在现实中,相关性往往更容易证明,而因果关系往往通过设计AB实验对指标影响原因进行分析。
https://zhuanlan.zhihu.com/p/353541738?utm_id=0
3.2相关性系数真的能反应变量之间的相关性吗?
- 如果变量之间为线性关系,则相关性系数的绝对值越大,变量之间相关性越强。
- 如果变量之间存在非线性关系,其相关系数绝对值也可能很大也可能很小,此时不能用相关系数衡量。
- 相关性系数很容易受到离群点(异常点)的影响,也可能造成相关系数错误的反应变量的相关性。 针对以上情况,最好先将数据画散点图大致看下数据的趋势。















 7395
7395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









