






Python数据爬虫
最近需要获取大量能源方面的数据,找到数据之后,需要写代码爬取下来,记录一下,供大家参考学习。
1.先直接分享一下代码
#基本的库
import requests
from bs4 import BeautifulSoup
from urllib.parse import quote
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings("ignore")
import time,re
for page in range(1,18): #有17页
url = "https://www.100ppi.com/news/list-14--546-{}.html".format(page)
headers = {
"Cookie":"JSESSIONID=66BCAC23D5212CED07C266778883E06F; Path=/; HttpOnly",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
html = requests.get(url)
soup = BeautifulSoup(html.content,"lxml")
# print(soup)
YEAR_data = pd.DataFrame()
for a_tag in soup.find_all('div', class_='block mb15 magt5 clearfix'):
for Y_url in a_tag.find_all('a', {'target': '_blank'}):
if Y_url == "\n": # 如果文本是空行就跳过
continue
else:
try:
# print(Y_url)
day_url1 = Y_url.get('href') # url的后半截
day_url = 'https://www.100ppi.com/news/'+str(day_url1)
# print("---------------",day_url) #https://www.100ppi.com/news/detail-20240515-3331176.html
day_text = Y_url.get_text(strip=True) if Y_url else '' #出来的是:醋酸乙烯商品报价动态(2024-05-30)
date_text = day_text[11:21].split() #2024-05-29
# print(day_text)
if '生石灰' in day_text:
# #到每一天的页面
day_html = requests.get(day_url,headers = headers)
day_soup = BeautifulSoup(day_html.content,"lxml")
# print(day_soup)
# #得到发布日期
day_tags = day_soup.find_all('div', class_='news-detail')
day_time1 = day_tags[0].find_all('div', class_='nd-info')
day_title = day_time1[0].get_text(strip=True) # https://www.100ppi.com 2023年12月18日 15:11
day_title = day_title[22:35] #2023年09月28日
print("---------开始爬取{}----------".format(day_title))
# #爬取表格
table = day_tags[0].find_all('div', class_='nd-c width588')
# 提取表格的所有行(<tr>元素)
rows = table[0].find_all('li')
# # 初始化列名和数据列表
date_title = [th.get_text(strip=True) for th in rows[0].find_all('span')]
# print(date_title) ## ['交易商', '品牌/产地', '交货地', '最新报价']
data = []
date_data = []
ranks_name = table[0].find_all('ul', class_='pn_text')
inner_soup = ranks_name[0]
# 遍历所有的pn_data类li元素
for data_item in inner_soup.find_all('li', class_='pn_data'):
trader = data_item.find('span', class_='title_w180l20').get_text(strip=True)
brand_origin = data_item.find('span', class_='title_w110l30').get_text(strip=True)
delivery_place = data_item.find('span', class_='title_w140').get_text(strip=True)
price = data_item.find('span', class_='title_w100').get_text(strip=True)
# 提取产品名称(如果有多个<ul class="pn_name">)
product_name = None
for product_name_item in inner_soup.find_all('ul', class_='pn_name'):
if product_name_item.find_next_sibling('li', class_='pn_data') == data_item:
product_name = product_name_item.get_text(strip=True)
break
# 将数据添加到列表中
data.append({'交易商': trader, '品牌/产地': brand_origin, '交货地': delivery_place, '最新报价': price, '产品名称': product_name})
date_data.append(day_title)
df = pd.DataFrame(data)
# 使用ffill填充NaN值
df['产品名称'] = df['产品名称'].fillna(method='ffill')
title_data = pd.DataFrame(date_data)
concat_data = pd.concat([df,title_data],axis = 1)
# print(concat_data)
# concat_data.to_csv("保存路径\生石灰{}的数据.csv".format(day_title))
print("-------------------------------------------------------------{}爬取完毕".format(day_title))
time.sleep(1)
YEAR_data = pd.concat([YEAR_data,concat_data])
else:
pass
except IndexError:
pass
# YEAR_data.to_csv("保存路径第{}页的生石灰数据.csv".format(page))
time.sleep(30)
print("\n \n******************************************************************第{}页结束*************************************************".format(page))
代码页面解释
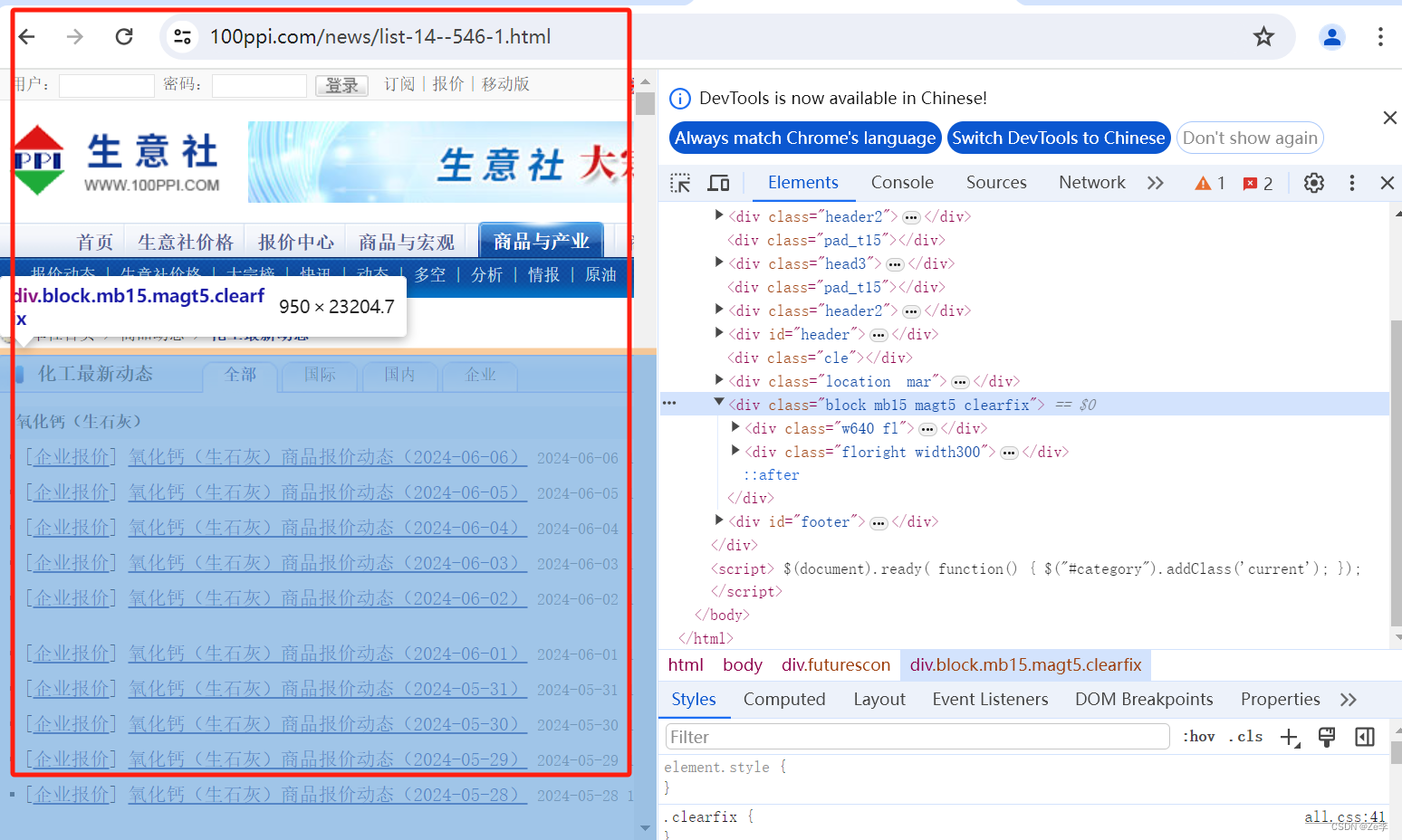
- 第1步:url(https://www.100ppi.com/news/list-14–546-1.html)
以第1页为例,通过上面url进去,看到的页面如下图:
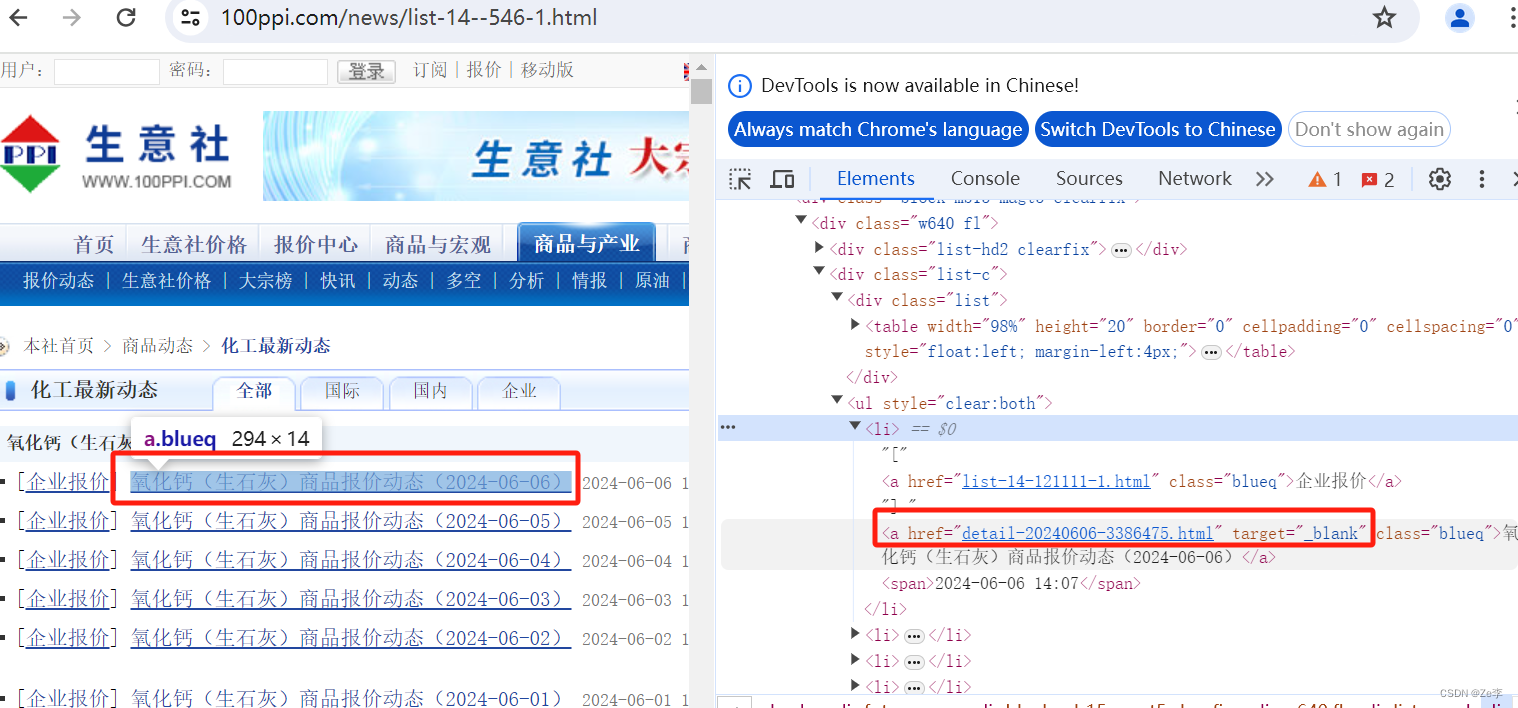
- 第2步:想要点进去每一天具体的页面,需要获取右边红色的链接,即代码里的day_url
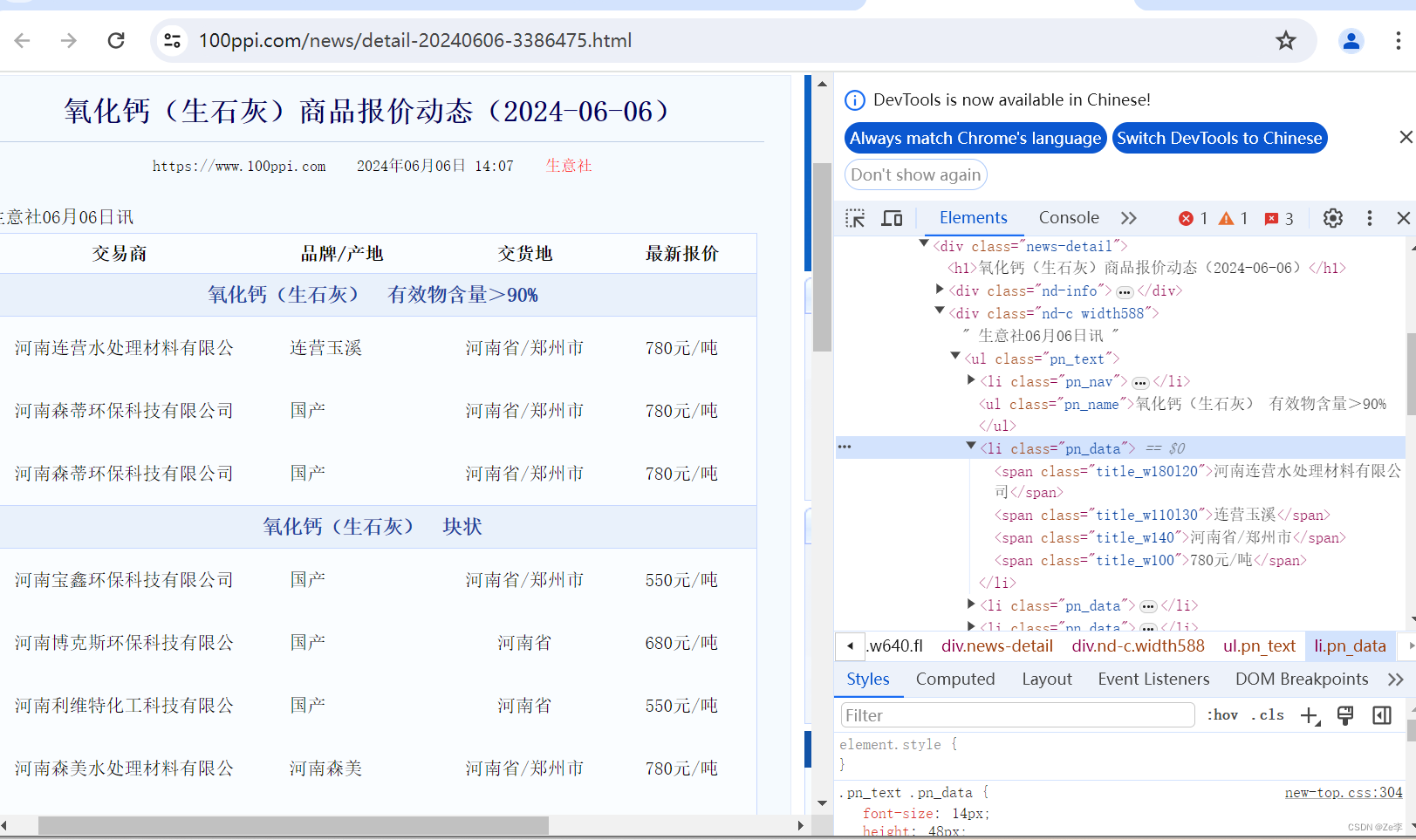
- 第3步:通过day_url链接可以看到对应解析的html为day_soup,然后利用BeautifulSoup的正则匹配就可以提取文字了。
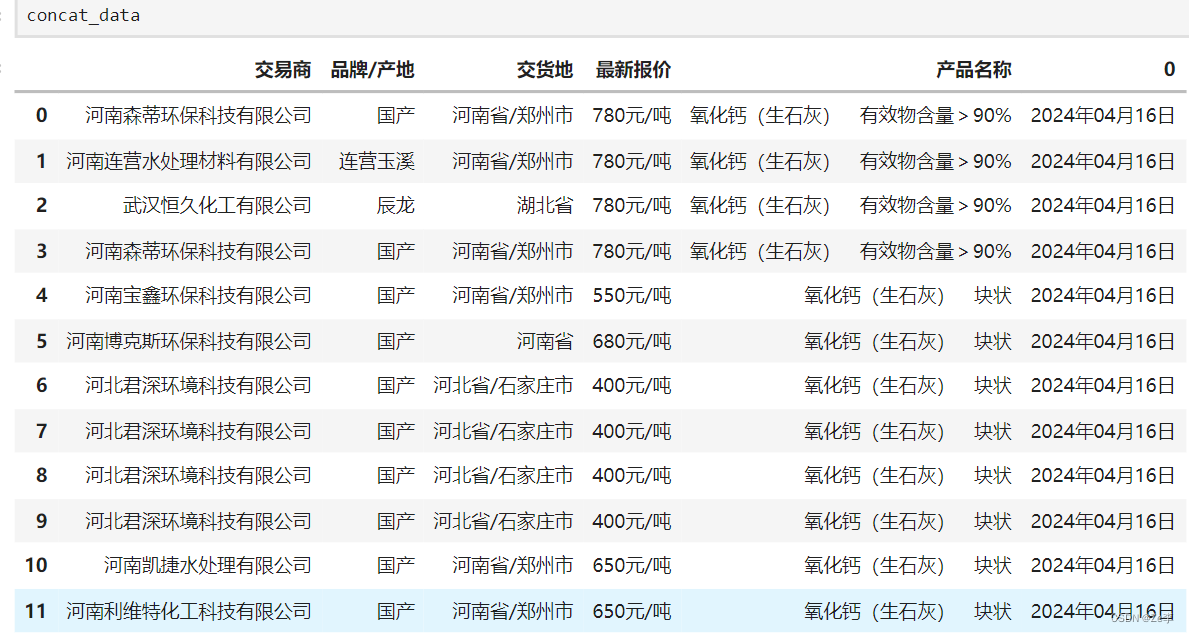
结果展示
每一个day_url保存的文件如下图,按页码保存的形式一致,只不过数据量变大了而已。
总结
目前爬的都是一些不需要代理或解密就可以爬到的,个人感觉难点就是提取解析文本信息,本次新使用到的是find_next_sibling,其他具体问题还得查找对应的解决方案。
关于bs4如何提取文本信息可以参考这个解析库bs4及爬取实例 ,个人感觉比较好。
总之,遇到问题不可怕,可怕的是不会主动去解决问题。















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









