






 本文介绍了如何在数据库(MySQL8.0前后)和Java中实现根据特定字段分组并获取组内最大记录的方法。在数据库层面,通过SQL查询,利用窗口函数或直接分组获取;在Java层面,利用Stream API的分组和比较器功能。
本文介绍了如何在数据库(MySQL8.0前后)和Java中实现根据特定字段分组并获取组内最大记录的方法。在数据库层面,通过SQL查询,利用窗口函数或直接分组获取;在Java层面,利用Stream API的分组和比较器功能。
1. 说明
最近遇到一个问题,一个记录表,需要批量根据某一个特定字段,获取这个字段最大记录,也就是需要先分组再组内排序,取组内最大一条数据
2. 解决方案
组内排序获取最大一条记录,本文探讨的是数据库层面和 java代码层面
2.1 数据准备
create table userlog
(
id int auto_increment comment 'id'
primary key,
phone varchar(11) null comment '手机号',
name varchar(20) null comment '名称',
create_time datetime null comment '创建时间'
);
INSERT INTO `userlog`(`phone`, `name`, `create_time`) VALUES ('18800000000', 'name0', '2022-02-01 10:32:10');
INSERT INTO `userlog`(`phone`, `name`, `create_time`) VALUES ('18800000000', 'name0', '2022-02-01 10:32:10');
INSERT INTO `userlog`(`phone`, `name`, `create_time`) VALUES ('18800000000', 'name0', '2022-02-01 10:32:20');
INSERT INTO `userlog`(`phone`, `name`, `create_time`) VALUES ('18800000000', 'name0', '2022-02-01 10:32:21');
INSERT INTO `userlog`(`phone`, `name`, `create_time`) VALUES ('18800000002', 'name2', '2022-02-01 10:32:30');
INSERT INTO `userlog`(`phone`, `name`, `create_time`) VALUES ('18800000002', 'name2', '2022-02-01 10:32:40');
INSERT INTO `userlog`(`phone`, `name`, `create_time`) VALUES ('18800000004', 'name4', '2022-02-01 10:32:50');
INSERT INTO `userlog`(`phone`, `name`, `create_time`) VALUES ('18800000004', 'name4', '2022-02-01 10:33:00');
INSERT INTO `userlog`(`phone`, `name`, `create_time`) VALUES ('18800000006', 'name6', '2022-02-01 10:33:10');
INSERT INTO `userlog`(`phone`, `name`, `create_time`) VALUES ('18800000006', 'name6', '2022-02-01 10:33:20');
INSERT INTO `userlog`(`phone`, `name`, `create_time`) VALUES ('18800000008', 'name8', '2022-02-01 10:33:30');
INSERT INTO `userlog`(`phone`, `name`, `create_time`) VALUES ('18800000008', 'name8', '2022-02-01 10:33:40');
2.2 数据库组内排序
2.2.1 mysql 8.0 以前
如果只需要分组字段且正序,可以直接分组,mysql默认分组展示的就是正序第一条
sql语句-此处只是写了一种方式还有许多实现方式,思路大致都是两步 1. 分组 2.组内排序
-- 先查满足条件的最大id,然后自身通过id关联查出所需数据
select * from userlog as teble1 join
(select max(id) as id from userlog where phone in ('18800000000','18800000002','18800000004','18800000006','18800000008') group by phone) as table2
on teble1.id = table2.id;
执行结果

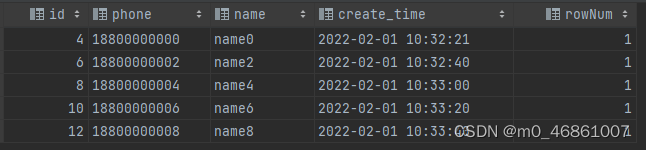
2.2.2 mysql 8.0 及其以后(窗口函数)
如果只需要分组字段且正序,可以直接分组,mysql默认分组展示的就是正序第一条
sql语句
-- rank() over() 如果组内排序字段重复,跳跃计数
-- dense_rank() over() 如果组内排序字段重复,不跳跃计数
-- row_number() over() 表示组内行数和组内排序字段没关系
-- partition by phone 相当于根据字段 phone 分组
select t.*
from (select *, rank() over (partition by phone order by id desc) as rowNum
from userlog
where phone in ('18800000000', '18800000002', '18800000004', '18800000006', '18800000008')) t
where t.rowNum = 1;
执行结果
2.3 java代码组内排序
2.3.1 环境要求
jdk需要8及其以上
java8及其之后
可以使用 lambda表达式,比较方便,这里主要想说下思路问题,之前一个时受到数据库的影响,一个是对api理解程度不够的原因,实现方式见方式一;后来有种恍然大悟的感觉,改成了方式二的实现;
方式一:先分组,组内过滤每一条数据
Map<String, List<UserLog>> collect = list.stream().collect(Collectors.groupingBy(UserLog::getPhone));
Map<String, UserLog> result = new HashMap<>();
collect.keySet().forEach(item -> {
UserLog userLog = collect.get(item).stream().max(Comparator.comparing(UserLog::getCreateTime)).get();
result.putIfAbsent(item, userLog);
});
/**
* 执行结果
* UserLog{id='1'phone='18800000000', name='name0', createTime='2022-00-01 10:00:10'}
* UserLog{id='2'phone='18800000000', name='name0', createTime='2022-00-01 10:00:20'}
* UserLog{id='3'phone='18800000002', name='name2', createTime='2022-00-01 10:00:30'}
* UserLog{id='4'phone='18800000002', name='name2', createTime='2022-00-01 10:00:40'}
* UserLog{id='5'phone='18800000004', name='name4', createTime='2022-00-01 10:00:50'}
* UserLog{id='6'phone='18800000004', name='name4', createTime='2022-01-01 10:01:00'}
* UserLog{id='7'phone='18800000006', name='name6', createTime='2022-01-01 10:01:10'}
* UserLog{id='8'phone='18800000006', name='name6', createTime='2022-01-01 10:01:20'}
* UserLog{id='9'phone='18800000008', name='name8', createTime='2022-01-01 10:01:30'}
* UserLog{id='10'phone='18800000008', name='name8', createTime='2022-01-01 10:01:40'}
* 组内排序后:
* UserLog{id='2'phone='18800000000', name='name0', createTime='2022-00-01 10:00:20'}
* UserLog{id='4'phone='18800000002', name='name2', createTime='2022-00-01 10:00:40'}
* UserLog{id='6'phone='18800000004', name='name4', createTime='2022-01-01 10:01:00'}
* UserLog{id='8'phone='18800000006', name='name6', createTime='2022-01-01 10:01:20'}
* UserLog{id='10'phone='18800000008', name='name8', createTime='2022-01-01 10:01:40'}
*/
方式二:利用map的key不重复特点
Map<String, UserLog> collect1 = list.stream().collect(Collectors.toMap(UserLog::getPhone, item -> item, (v1, v2) -> v1.getCreateTime().getTime() > v2.getCreateTime().getTime() ? v1 : v2));
/**
* 执行结果
* UserLog{id='1'phone='18800000000', name='name0', createTime='2022-00-01 10:00:10'}
* UserLog{id='2'phone='18800000000', name='name0', createTime='2022-00-01 10:00:20'}
* UserLog{id='3'phone='18800000002', name='name2', createTime='2022-00-01 10:00:30'}
* UserLog{id='4'phone='18800000002', name='name2', createTime='2022-00-01 10:00:40'}
* UserLog{id='5'phone='18800000004', name='name4', createTime='2022-00-01 10:00:50'}
* UserLog{id='6'phone='18800000004', name='name4', createTime='2022-01-01 10:01:00'}
* UserLog{id='7'phone='18800000006', name='name6', createTime='2022-01-01 10:01:10'}
* UserLog{id='8'phone='18800000006', name='name6', createTime='2022-01-01 10:01:20'}
* UserLog{id='9'phone='18800000008', name='name8', createTime='2022-01-01 10:01:30'}
* UserLog{id='10'phone='18800000008', name='name8', createTime='2022-01-01 10:01:40'}
* 组内排序后1:
* UserLog{id='2'phone='18800000000', name='name0', createTime='2022-00-01 10:00:20'}
* UserLog{id='4'phone='18800000002', name='name2', createTime='2022-00-01 10:00:40'}
* UserLog{id='6'phone='18800000004', name='name4', createTime='2022-01-01 10:01:00'}
* UserLog{id='8'phone='18800000006', name='name6', createTime='2022-01-01 10:01:20'}
* UserLog{id='10'phone='18800000008', name='name8', createTime='2022-01-01 10:01:40'}
*/
完整测试代码(虚拟的数据)
//此处需要加入 本类的 package 信息
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Calendar;
import java.util.Comparator;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class GroupOrder {
public static void main(String[] args) {
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyy-MM-dd HH:mm:ss");
GroupOrder groupOrder = new GroupOrder();
List<UserLog> list = groupOrder.getList();
StringBuilder sb = new StringBuilder("insert into userlog(phone, name, create_time) VALUES ");
for (UserLog userLog : list) {
sb.append("(");
sb.append("'").append(userLog.getPhone()).append("',");
sb.append("'").append(userLog.getName()).append("',");
sb.append("'").append(simpleDateFormat.format(userLog.getCreateTime())).append("'");
sb.append("),");
}
sb.append(");");
System.out.println(sb);
list.forEach(System.out::println);
/*
1. 先分组
2.循环每一个组内排序取符合的数据,放入map
3.获取map的值,得到最终的数据
*/
Map<String, List<UserLog>> collect = list.stream().collect(Collectors.groupingBy(UserLog::getPhone));
Map<String, UserLog> result = new HashMap<>();
collect.keySet().forEach(item -> {
UserLog userLog = collect.get(item).stream().max(Comparator.comparing(UserLog::getCreateTime)).get();
result.putIfAbsent(item, userLog);
});
System.out.println("组内排序后:");
result.values().stream().sorted(Comparator.comparing(UserLog::getCreateTime)).forEach(System.out::println);
/*
1. map映射,利用key重复时的处理获取数据
2. 获取map的值,得到最终的数据
*/
Map<String, UserLog> collect1 = list.stream().collect(Collectors.toMap(UserLog::getPhone, item -> item, (v1, v2) -> v1.getCreateTime().getTime() > v2.getCreateTime().getTime() ? v1 : v2));
System.out.println("组内排序后1:");
collect1.values().stream().sorted(Comparator.comparing(UserLog::getCreateTime)).forEach(System.out::println);
}
private List<UserLog> getList() {
Calendar calendar = Calendar.getInstance();
calendar.set(Calendar.YEAR, 2022);
calendar.set(Calendar.MONTH, 1);
calendar.set(Calendar.DAY_OF_MONTH, 1);
calendar.set(Calendar.HOUR_OF_DAY, 10);
calendar.set(Calendar.MILLISECOND, 0);
calendar.set(Calendar.SECOND, 0);
List<UserLog> data = new ArrayList<>();
String tempName = null;
String tempPhone = null;
for (int i = 0; i < 10; i++) {
UserLog temp = new UserLog();
if (i % 2 == 0) {
tempName = "name" + i;
tempPhone = "1880000000" + i;
}
temp.setId(i + 1);
temp.setName(tempName);
temp.setPhone(tempPhone);
calendar.add(Calendar.SECOND, 10);
temp.setCreateTime(calendar.getTime());
data.add(temp);
}
return data;
}
class UserLog {
private Integer id;
private String phone;
private String name;
private Date createTime;
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-mm-dd HH:mm:ss");
@Override
public String toString() {
final StringBuffer sb = new StringBuffer("UserLog{");
sb.append("id='").append(id).append('\'');
sb.append("phone='").append(phone).append('\'');
sb.append(", name='").append(name).append('\'');
sb.append(", createTime='").append(simpleDateFormat.format(createTime)).append('\'');
sb.append('}');
return sb.toString();
}
UserLog() {
}
UserLog(Integer id, String name, String phone, Date createTime) {
this.id = id;
this.name = name;
this.phone = phone;
this.createTime = createTime;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Date getCreateTime() {
return createTime;
}
public void setCreateTime(Date createTime) {
this.createTime = createTime;
}
}
}
3. 总结
- mysql8.0之前实现,先分组然后拿到分组后的数据排序,获取到自己需要的数据
- mysql8.0及其实现,可以使用窗口函数
- java8.0之前实现,和mysql8.0之前一样思路实现
- java8.0及其之后实现,利用map的key重复机制实现

















 4458
4458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









