







 文章详细介绍了传统图特征工程,包括节点特征(如节点连接数、重要度、graphlet信息)和连接层面特征。还讨论了全图特征工程的方法,并重点讲解了Weisfeiler-LehmanKernel算法在解决图同构问题和图相似度度量中的应用。
文章详细介绍了传统图特征工程,包括节点特征(如节点连接数、重要度、graphlet信息)和连接层面特征。还讨论了全图特征工程的方法,并重点讲解了Weisfeiler-LehmanKernel算法在解决图同构问题和图相似度度量中的应用。
一、传统图特征工程
1、图特征
图点本身就具备的特征称为属性特征(如:连接权重、节点类型等),属性特征大部分时候都是多模态的。
图中一个节点和其他节点之间的连接关系称为连接特征(结构信息)
人工提取并构造的特征称为特征工程。(将图变为向量)特征工程一般针对图的连接特征进行构造
2、节点特征工程
节点层面连接特征分为:
①节点的连接数
②节点的重要度
③节点的聚集系数(某节点与其相邻节点之间是否有联系)
④节点的子图信息(某节点周围有多少人工定义的子图)
2.1 节点连接数
求节点连接数,直接按某行/某列求和即可;或将邻接矩阵与一个值为1的向量相乘即可。但节点连接数不考虑连接的质量。若考虑节点重要度,则可通过以下几种指标衡量
2.2 节点重要度
1)度中心性(Degree Centrality)
无向图:邻居节点数量
有向图:分为入度与出度

其中deg(v)表示节点v的度数,n表示图中节点的总数
2)接近中心性(Clossness Centrality)
衡量节点的影响范围和在信息传播中的作用,指节点到其他节点的平均距离的倒数

3)介数中心性(Betweenness centrality)
指节点在所有最短路径中出现的次数。该指标可以衡量节点在信息传播和资源流动中的作用。

4)特征向量重要度(Eigenvector Centrality)
指节点的重要性与其相邻节点的重要性有关。如果一个节点与其他重要节点相连,那么它的重要性也会提高。

5)集群系数(Clustering Coefficient)
计算方法为:该节点的周围节点之间相连数 / 该节点与周围节点相连数,值域为[0,1]。详见下图示例:

分母为相邻节点两两个数
分子为v节点邻居节点两两连接数,可通过数三角形得到,这种三角形连接被称为:自我中心网络(ego-network)

2.3 graphlet-节点的子图信息
相同样的节点数构成非同形子图(类似同分异构体),例如4个节点可以构成6种graphlet

提取某节点周围的graphlet个数即可构成一个称为Graphlet Degree Vector(GDV)
3、连接层面特征工程
3.1 目的
通过已知连接补齐未知连接。可以通过两种方法来获取D维向量:
①直接提取连接的特征
②将连接两端节点的D维向量拼在一起(但这种方法会丢失link本身的连接信息)
3.2 连接预测的一般方法为
①获取连接的D维向量
②将D维向量送入机器学习中进行计算,获得分数
③将分数 c(x,y) 进行排序,选出最高的n个新连接
④计算这n个预测结果与真实值
3.3 连接特征
连接特征一般分为:①节点间的距离;②节点局部连接信息;③节点在全图的连接信息
3.3.1 最短路径长度
两个点之间经过节点最少的路径上的节点数,但是其与节点连接数一样只看数量不看权重。

3.3.2 基于两节点的局部连接信息
1)common neighbors
2)杰卡德相似性
共同相邻节点个数;交并比等。但若两个节点不存在局部连接,则其交并比和共同相邻节点个数均会为0。例如下图中A和E就不存局部连接。

3)Adamic-Adar(adac)
Adamic Adac算法常用于社交链路中关系的预测,如好友推荐,美食推荐等等

其中N(u)是与相邻的节点集u。
值A(x,y)=0表示两个节点不接近,而较高的值表示节点较近
该库包含一个计算两个节点之间接近都的函数
3.3.3 节点在全图的连接信息
1)卡兹系数(Katz index)
1.1 )基础
表示节点u和节点v之间的长度为k的路径个数。计算方法如下:
- 用邻接矩阵的幂运算
- 离散数学中提到,邻接矩阵的n次幂表示的就是路径长度为n的路径(假设每条路径长度均为1)
1.2)推导
当距离为1时,Katz index 值为 邻接矩阵
当距离为2时,Katz index 值为 邻接矩阵的平方
根据数学归纳法证明,当距离为 L 时,Katz index值为 邻接矩阵的 L 次幂

1.3)加 discount factor
当路径长度 正无穷 时,没有太大意义,对卡茨系数进行衰减
公式如下:

4、全图特征工程
目的是提取整张图的特征,将其变为D维向量,反映全图结构特点。
实际就是在计算不同特征在图中存在的个数
4.1 (将图视为文章,节点视为单词 Bag-of-Words (BoW) )
但这种方法有一个缺陷,就是只看是否存在第 i 个节点而不关心连接结构,如下图中两个图编码的D维向量一致,均为[1 1 1 1]

4.2 使用Bag-of-Node-degrees,但是同样的只看node dgree,不看节点也不看连接结构
4.3 Bag-of-xxx可以推广到之前提到的任意特征中,比如将全图的graphlets作为应用场景,其相较于节点层面的graphlets有如下区别:①可以存在孤立节点;②计数对象为全图,而不是特定节点邻域。
将两张图的graphlet进行数量积则可得到Graphlet Kernel(一个标量),该指标可以反映两张图是否相近/匹配,公式记作:

若两张图尺寸不一致则需要对其进行归一化
但是这种做法对算力的消耗极大。故一般采用Weisfeiler-Lehman Kernel算法,采用的是颜色微调的思想(Color refinement),其具体做法如下:
5、Weisfeiler-Lehman Kernel算法
原论文:The Weisfeiler-Lehman Test of Isomorphism
参考文章:The Weisfeiler-Lehman Isomorphism Test | David Bieber
5.1 目标
WL-test是目前解决图同构问题最有效的算法
5.2 两个图是同构图 Graph Isomorphism的性质
- 两图的边和顶点数量相同,且边的连接性相同
- 也可以认为一图的点是由另一图的点映射得到
- 计算图同构可以度量图的相似度(比如实际应用中具有相似结构的分子可能具备相似的功能特性)
5.3 思想
通过对相邻节点的节点标签排序后的集合来扩展节点标签,并将这些扩展后的标签压缩为新的短标签
5.4 更新流程
- 将图初始化
- 根据邻居节点的连接数量,对其进行编码调整
- 将不同的编码以不同的颜色代替(Hash)
- 重复以上步骤,最后两个相同结构的节点颜色始终相同
- 这样就将每张图变成了一个维度较低的向量。将这两张图的向量求内积即可得到Weisfeiler-Lehman kernel
示例:

5.5 WL子树
- 在WL Test的第k次迭代中,一个节点的标签代表了:以该节点为根的高度为k的子树结构
- 当两个节点的h层的标签一样时,表示:分别以这两个节点为根节点的WL子树是一致的
- 举例:右图是节点1迭代两次的子树

5.6 公式表示
- WL-test分为四步:聚合邻接节点标签、多重集排序、标签压缩、更新标签

二、图嵌入
1、图嵌入目标
用低维、稠密、实值的向量表示网络中的节点。图嵌入是将属性图转换为向量或向量集。嵌入应该捕获图的拓扑结构、顶点到顶点的关系以及关于图、子图和顶点的其他相关信息
2、图嵌入方法分类
1)基于因子分解的方法
2)基于随机游走的方法
3)基于深度学习的方法
三、graph embedding汇总
待补充
1、Deepwalk
1.1 核心思想
DeepWalk的思想类似word2vec,使用图中节点与节点的共现关系来学习节点的向量表示。那么关键的问题就是如何来描述节点与节点的共现关系,DeepWalk给出的方法是使用随机游走(RandomWalk)的方式在图中进行节点采样。
RandomWalk是一种可重复访问已访问节点的深度优先遍历算法。给定当前访问起始节点,从其邻居中随机采样节点作为下一个访问节点,重复此过程,直到访问序列长度满足预设条件。
获取足够数量的节点访问序列后,使用skip-gram model 进行向量学习。
1.2 算法实现步骤
①输入network/graph
②进行随机游走(random walk)
③得到节点序列(representation mapping)
④放到skip-gram模型中(中间节点预测上下文节点)
⑤output: representation(中间的隐层)
2、LINE
3、node2vec
4、Struc2vec
5、SDNE
四、图嵌入基础-词嵌入
词嵌入的目标:将词语映射为一个实数向量,同时保留词语之间语义的相似性和相关性
思想:通过某种降维算法,将向量映射到低纬度空间中,相似的词语位置较近,不相似的词语位置较远
1、N-gram
N-gram(N元)模型,就是在计算概率时,忽略长度大于N的上下文词的影响,只考虑前面的N个词
基于统计的语言模型,从概率论专业角度来描述就是:为长度为m的字符串确定其概率分布P(w_1, w_2, ..., w_n),其中w_1到w_n依次表示文本中的各个词语。一般采用链式法则计算其概率值:
P(w_1, w_2, ..., w_n) = P(w_1)P(w_2|w_1)P(w_3|w_1,w_2)...P(w_m|w_1,w_2,...,w_{m-1})
缺陷:N值越大,保留的词序信息(上下文)越丰富,但计算量也呈指数级增长。
2、NNLM
2.1 网络结构
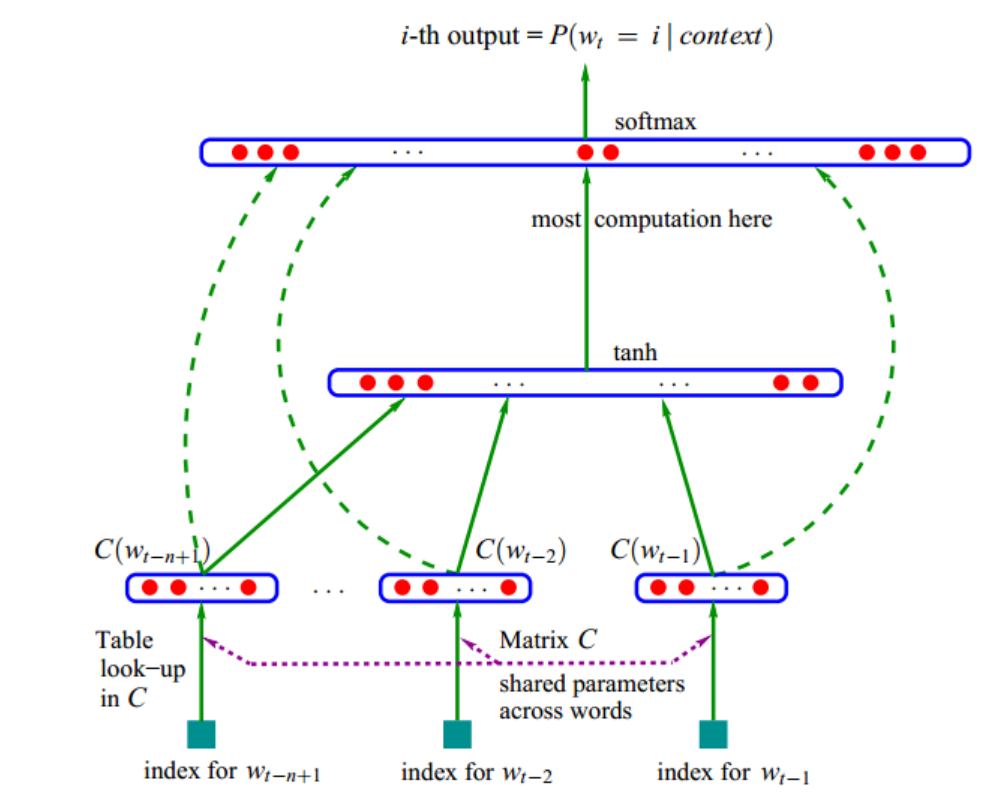
图中参数解释
look-up:查表
C(w)表示w对应的词向量
V表示语料中的总词数,m表示词向量的维度
矩阵C为 m行,|V| 列
2.2 前向传播
- 输入:前N-1个词语的向量(one-hot表示的向量)拼接,形成以一个(n-1)Xm大小的向量,记为x
- 网络的第二层(隐藏层):直接使用全连接,d+Hx
- 输出:第N个词语的一组概率,y=b+wx+Utanh(d+Hx),其中U为|V|Xh矩阵,从隐藏层到输出层的参数
2.3 目标函数
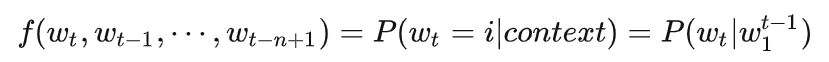
2.4 网络结构的示意图表示
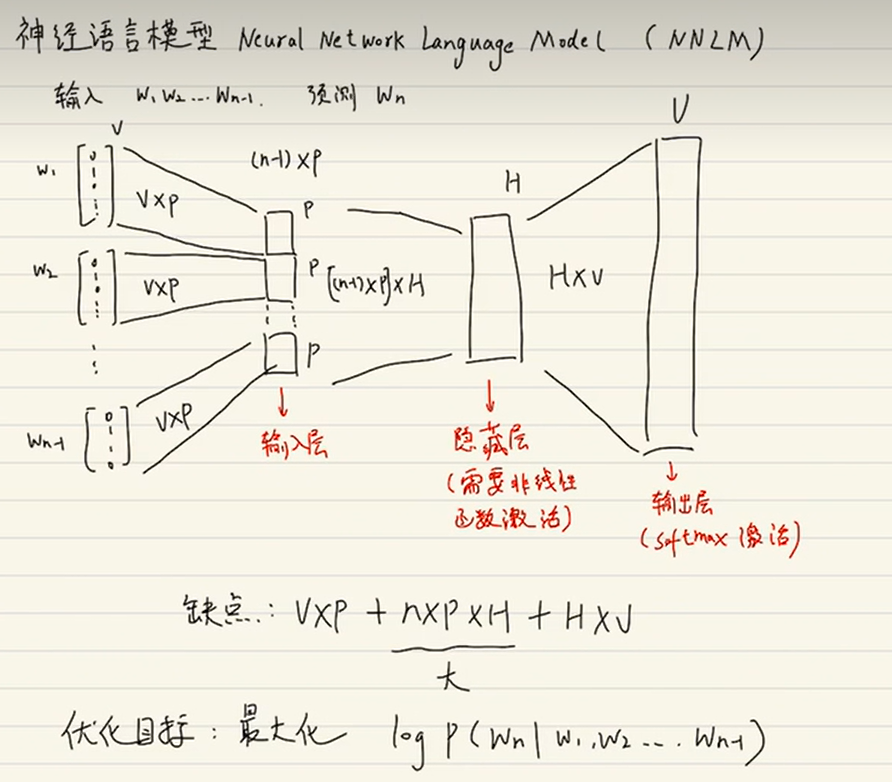
2.5 示例
设词典大小为1000,向量维度为25,N=3
先将前N个词表示成独热向量
输入矩阵为:[3, 1000]
权重矩阵:[1000, 25]
隐藏层:[3, 1000] * [1000, 25] = [3, 25]
输出层权重:[25, 1000]
输出矩阵:[3, 25] * [25, 1000] = [3, 1000] ==> [1, 1000],表示预测属于1000个词的概率.
其中,将[3,1000]转化过程可用求和、求均值、权重相加等方法,变成【1,1000】
3、Word2vec
目标:学习一个从高维稀疏离散向量到低维稠密连续向量的映射。
特点:近义词向量的欧氏距离比较小,词向量之间的加减法有实际物理意义。
Word2Vec由两部分组成:CBOW和Skip-Gram
3.1 CBOW
训练目标是最大化给定上下文时中心单词出现的概率
与NNLM区别:
将中间的隐藏层去掉。同时,用来预测object word的context word的词向量不再合并, 而是求平均
3.2 Skip-gram
4、共现矩阵
定义:共现(co-occurrence)矩阵指通过统计一个事先指定大小的窗口内的词语共现次数,以词语周边的共现词的次数做为当前词语的向量
主要用于发现主题,解决词向量相近关系的表示。将共现矩阵行(列)作为词向量
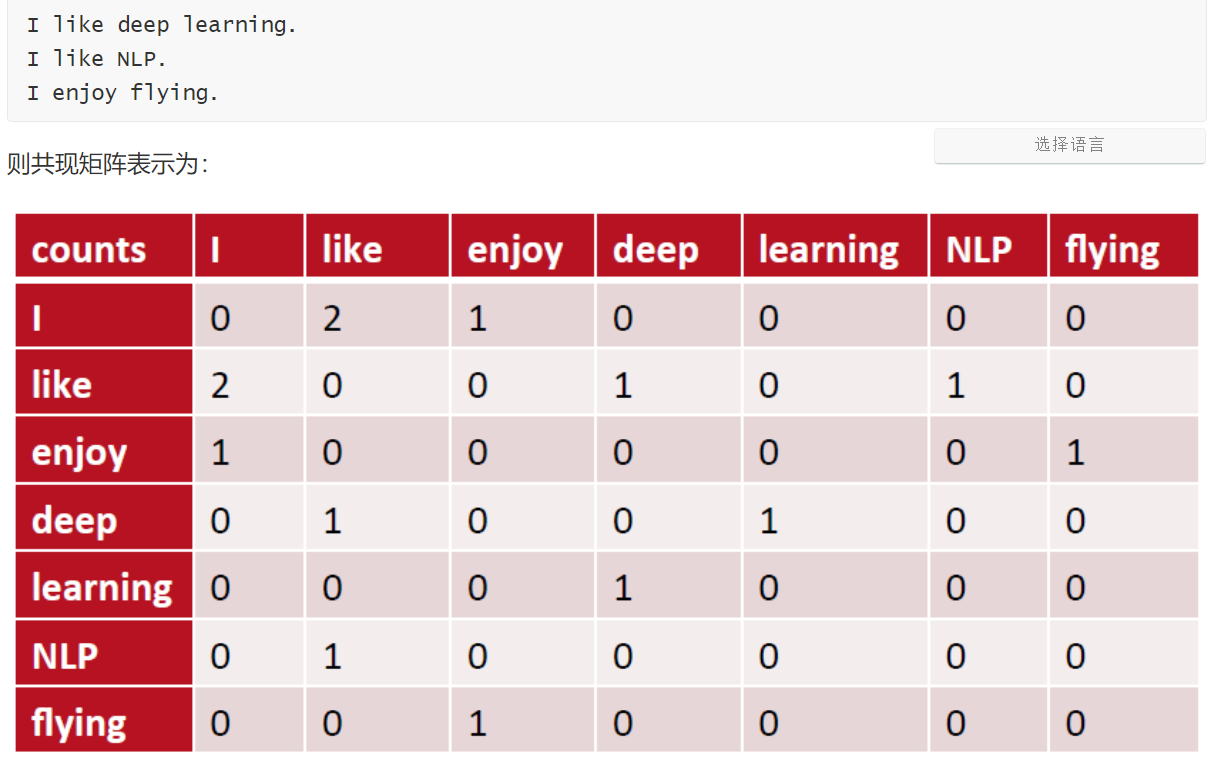
共现矩阵的不足
面临稀疏性问题、向量维数随着词典大小线性增长
解决:SVD、PCA降维,但是计算量大
5、随机游走-Random walk(RW)
5.1 概述
类似于布朗运动,是布朗运动的理想状态,任何无规则行走所带的守恒量都各自对应着一个扩散运输定律。
每过一个单位时间,游走者从x出发以固定概率随机移动一个单位。
参考及学习资料
书籍:深入浅出图神经网络(链接:https://pan.baidu.com/s/1GYm8FxUh0GbJDftr9RecCg
提取码:46ez )
斯坦福课程:https://www.youtube.com/playlist?list=PLoROMvodv4rPLKxIpqhjhPgdQy7imNkDn
课件:CS224W | Home (stanford.edu)
YouTube视频:CS224W: Machine Learning with Graphs

















 2179
2179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









