






一、数学基础术语
subject to 服从于
inf infimum的简写 最大下界
sup supremum的简写 最小上界
i.e. 也即
例子:The following subsections detail the three special features of MIMO-UNet, i.e., MISE, MOSD, and AFF.
下面的小节详细介绍了 MIMO-Unet 的三个特殊的特征,即 MISE, MOSD, and AFF
见最后附录
二、几何空间
1、三角函数
1.1 定义
三角函数是基本初等函数之一,是以角度(数学上最常用弧度制,下同)为自变量,角度对应任意角终边与单位圆交点坐标或其比值为因变量的函数
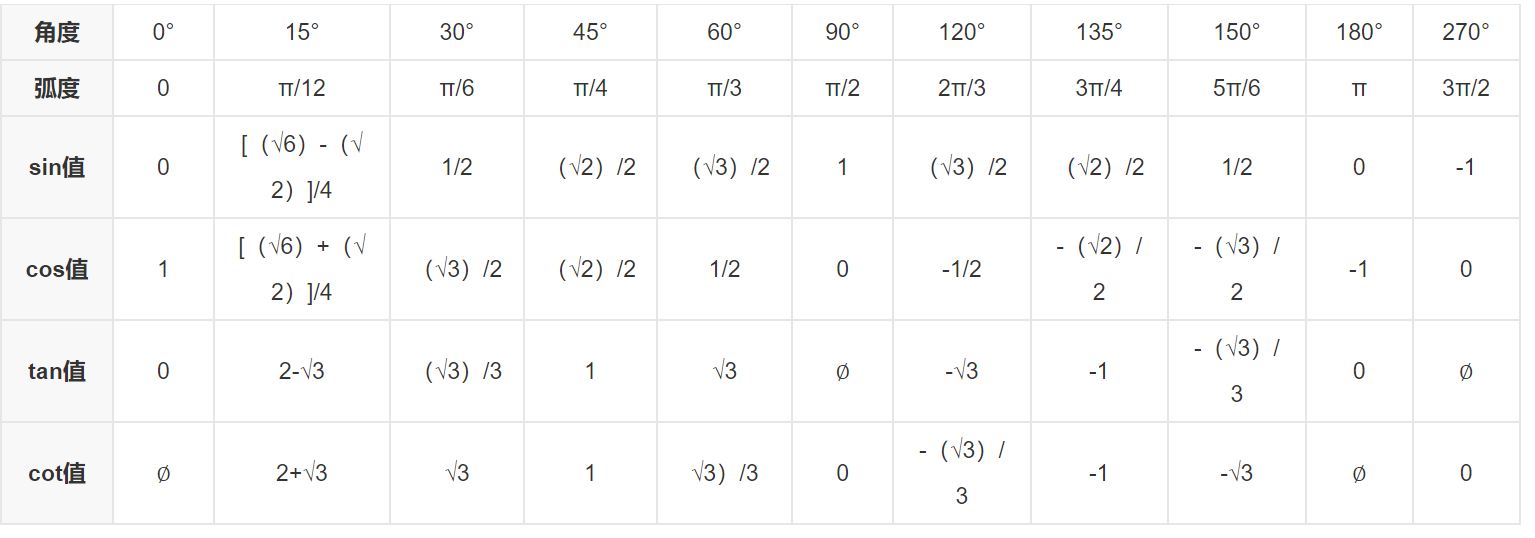
1.2 三角函数的特殊角度计算
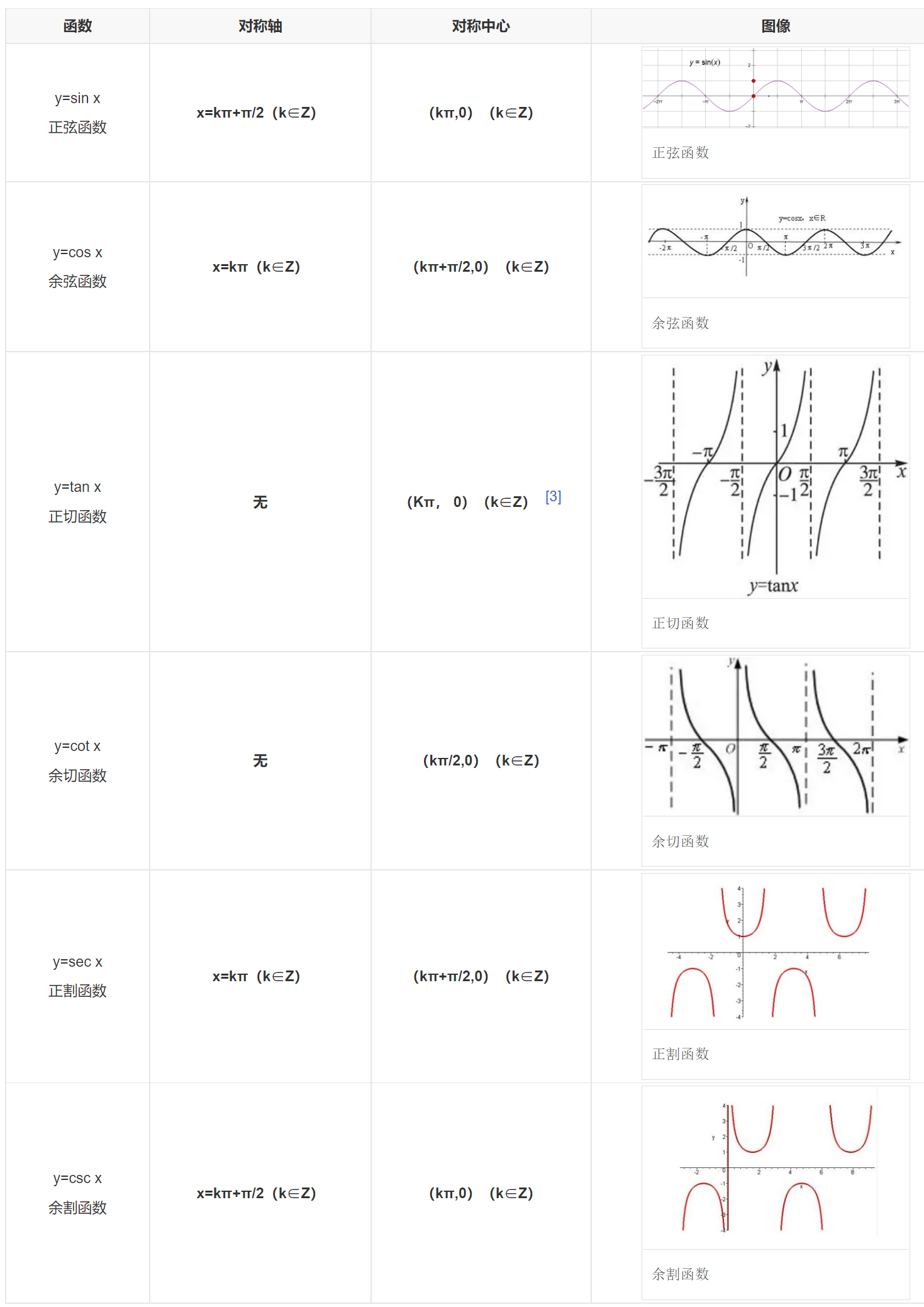
1.3 函数图像及性质
1.4 三角函数恒等式
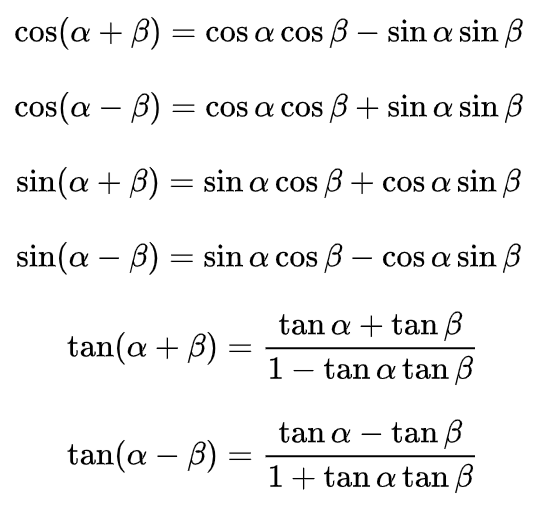

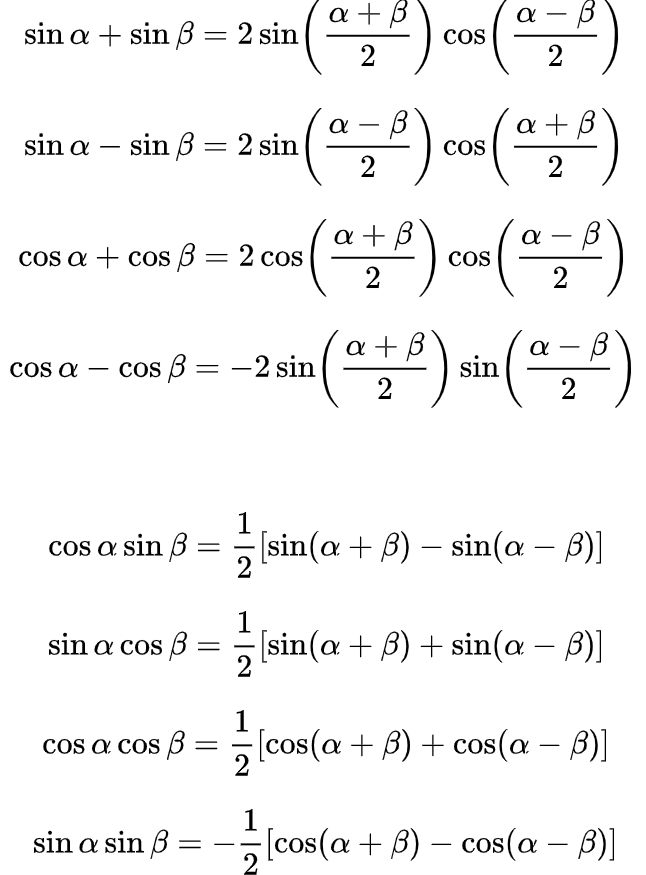
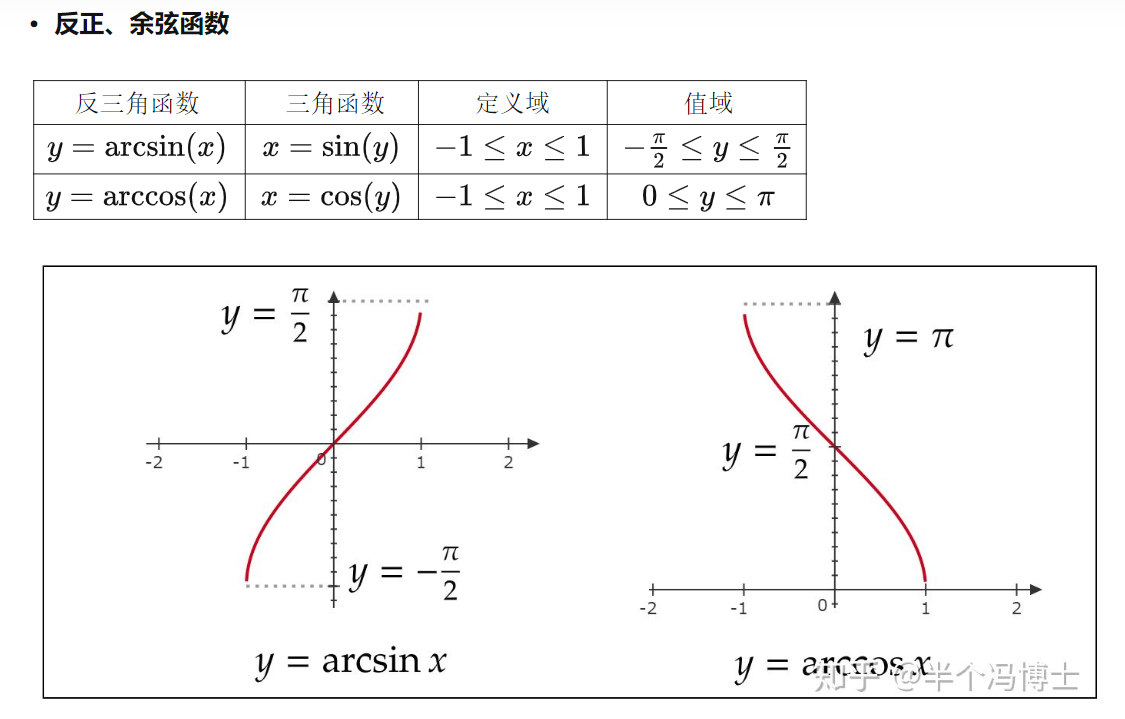
1.5 反三角函数
反三角函数的基本形式都是在特定的条件下定义的,它们并不直接代表三角函数的反函数,而是在特定区间上的三角函数的反函数。
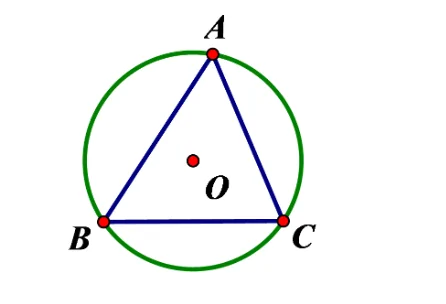
2、外接圆和内切圆
(1)三角形各边垂直平分线的交点,是外心。
(2)外心到三角形各顶点的距离相等。
(3)外心到三角形各边的垂线平分各边。
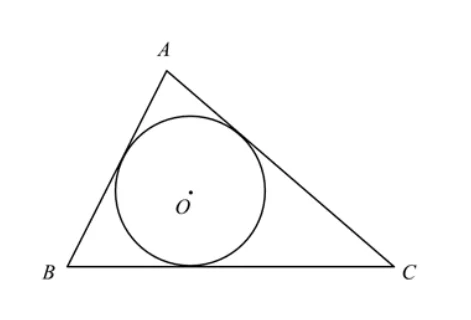
(1)三角形各内角平分线的交点,是内心。
(2)内心到三角形各边的距离相等。
(3)三角形任一顶点到内切圆的两切线长相等。
(4)三角形顶点到内切圆的切线长,是这点到圆心的距离与它圆外部分的比例中项
3、极坐标
基本公式
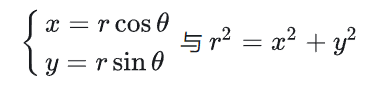
简单例子
一条直线的倾斜角是45°,求极坐标方程
y = x
psinθ = pcosθ
tanθ = 1
三、高等数学
1、距离计算
-
欧氏距离(Euclidean Distance)
-
曼哈顿距离
在曼哈顿街区要从一个十字路口开车到另一个十字路口,驾驶距离显然不是两点间的直线距离。这个实际驾驶距离就是“曼哈顿距离”。曼哈顿距离也称为“城市街区距离”(City Block distance)。
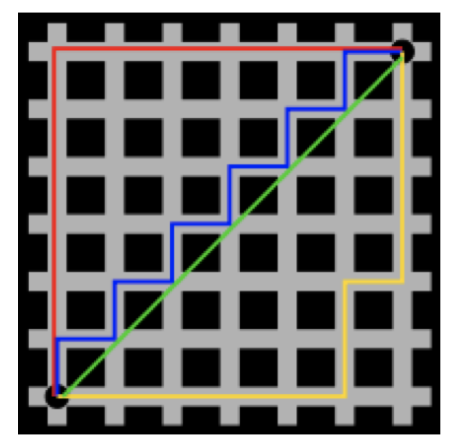
-
切比雪夫距离 (Chebyshev Distance)
国际象棋中,国王可以直行、横行、斜行,所以国王走一步可以移动到相邻8个方格中的任意一个。国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?这个距离就叫切比雪夫距离。
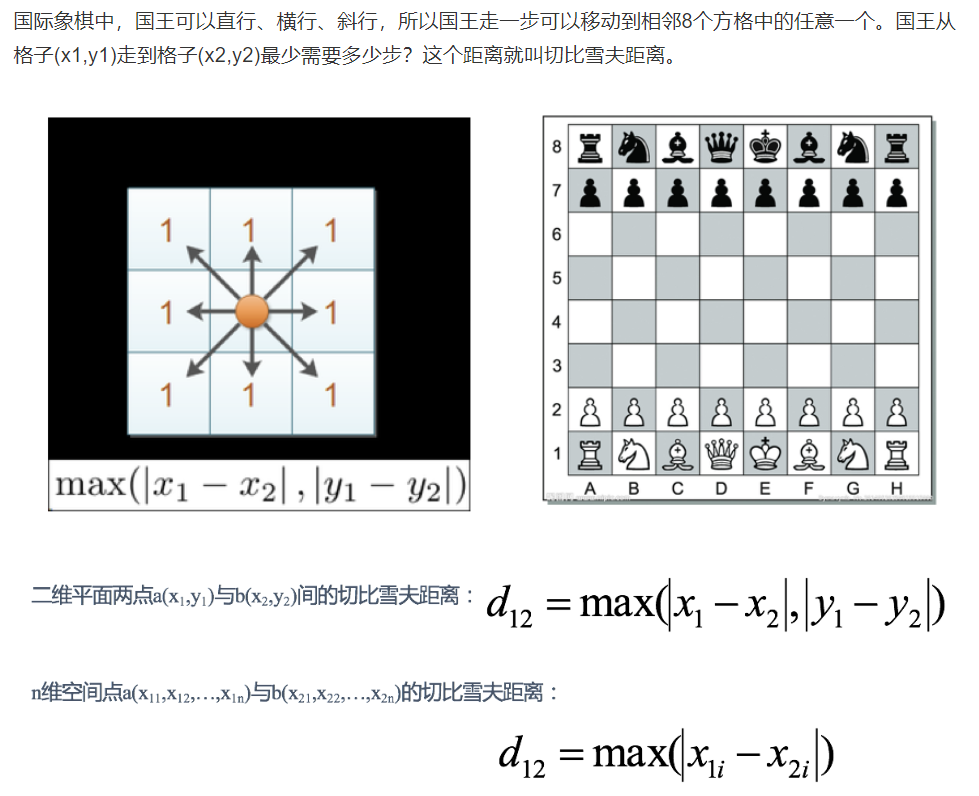
-
闵可夫斯基距离(Minkowski Distance)
闵氏距离不是一种距离,而是一组距离的定义,是对多个距离度量公式的概括性的表述。
两个n维变量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的闵可夫斯基距离定义为: -
标准化欧氏距离 (Standardized EuclideanDistance)
标准化欧氏距离是针对欧氏距离的缺点而作的一种改进。
思路:既然数据各维分量的分布不一样,那先将各个分量都“标准化”到均值、方差相等。 -
余弦距离(Cosine Distance)
7 汉明距离(Hamming Distance)
8、点到直线的距离
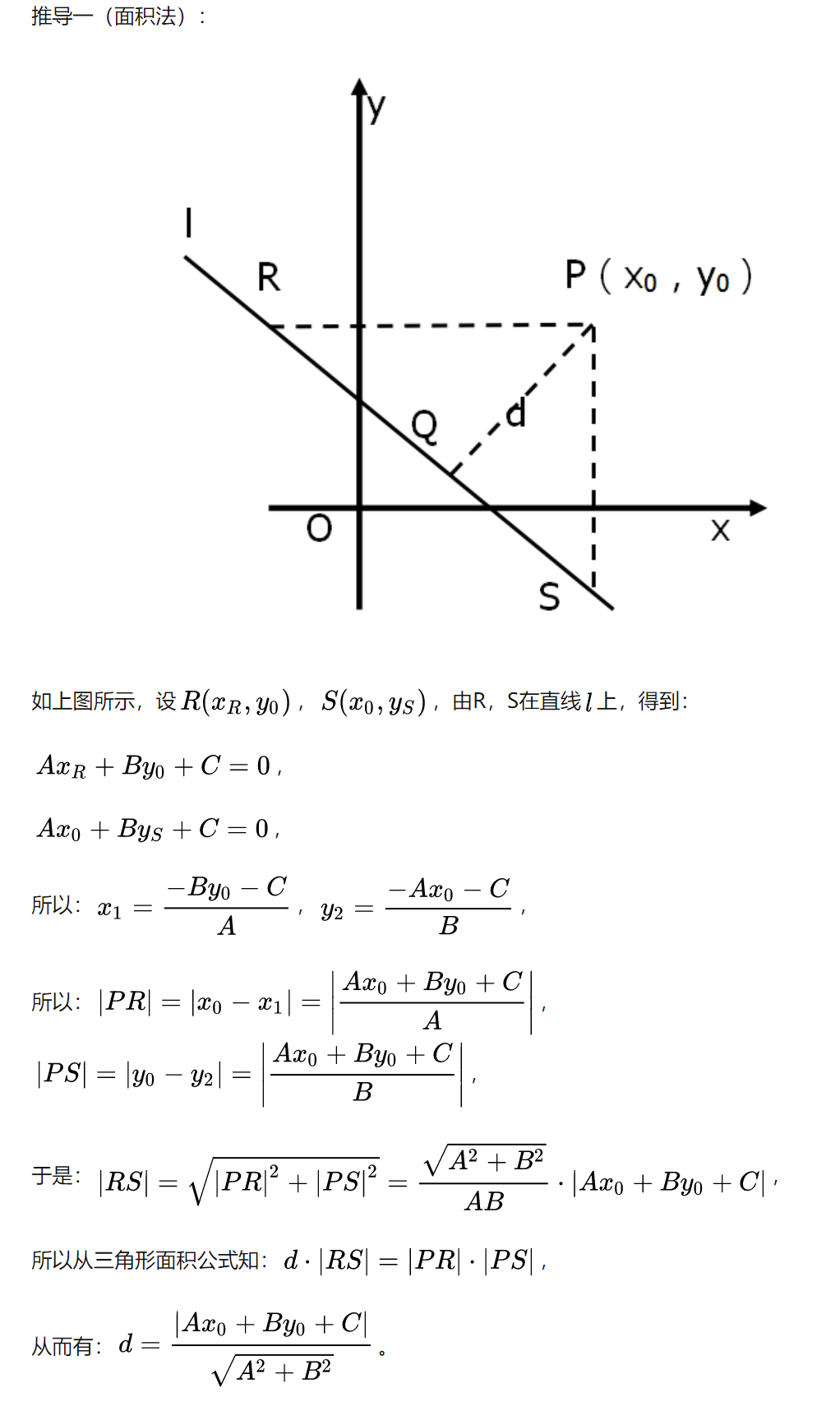
9、JS(Jensen-Shannon)距离
KL散度的替代
用于比较两个概率分布之间相似性的度量方法。它是基于KL(Kullback-Leibler)散度的一种改进,解决了KL散度不对称性的问题
给定两个离散概率分布P和Q,它们的JS距离定义如下:
JS(P||Q) = (1/2) * KL(P||(P+Q)/2) + (1/2) * KL(Q||(P+Q)/2)
其中,KL(P||Q)表示P相对于Q的KL散度,KL(Q||P)表示Q相对于P的KL散度。KL散度是衡量两个分布之间差异的一种指标。
JS距离的取值范围是0到1之间。当P和Q完全相同时,JS距离为0;当P和Q完全不同时,JS距离为1。JS距离还具有对称性,即JS(P||Q) = JS(Q||P)。
JS距离在信息检索、文本相似度计算和聚类分析等领域广泛应用,特别是在比较两个文档或语言模型之间的相似性时常被使用。
2、求导
2.1 简单求导公式
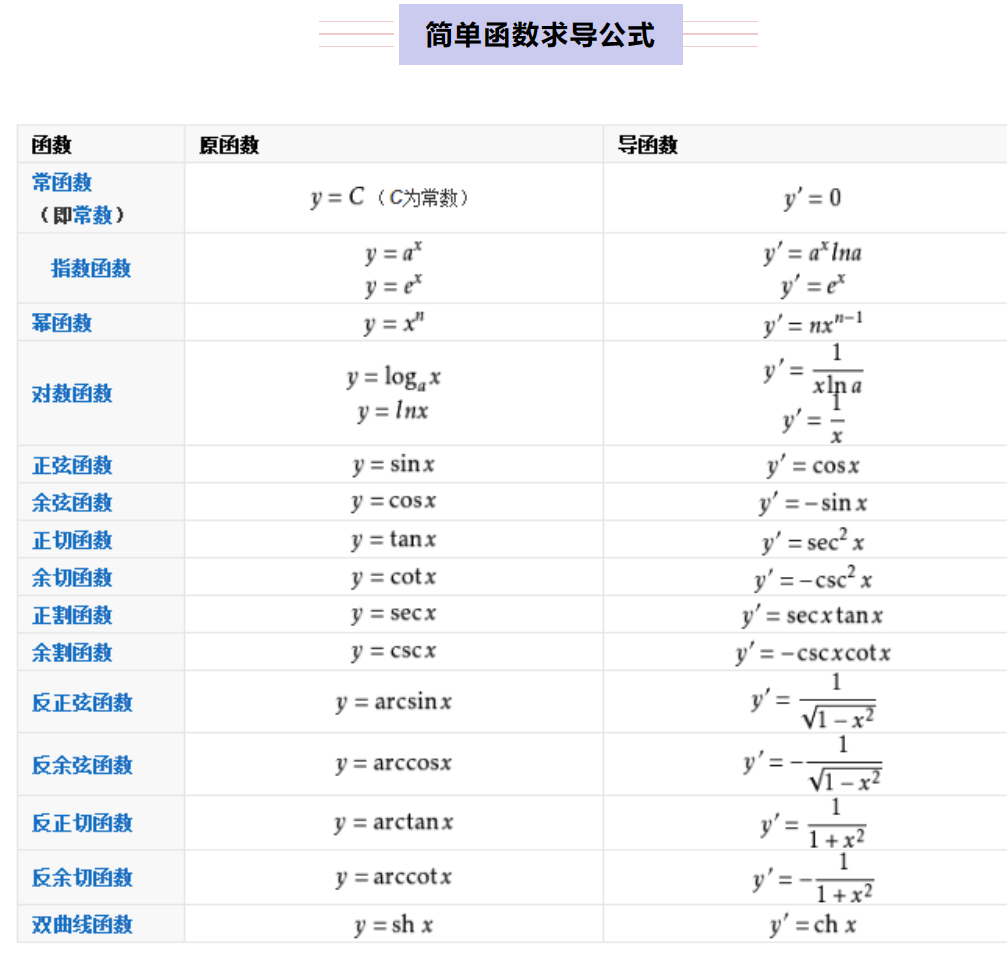
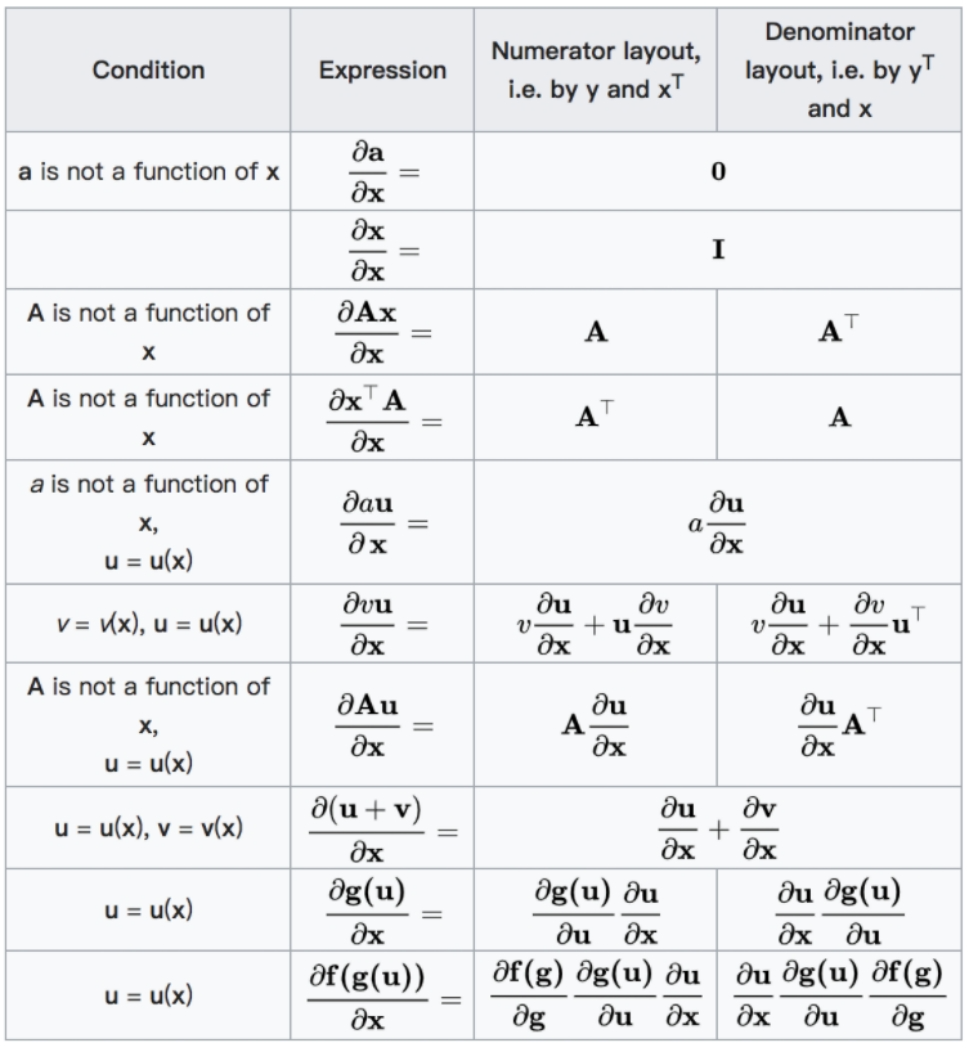
2.2 矩阵求导
3、微积分
4、无穷级数
4.1 等差等比数列
4.1 泰勒展开
4.2 欧拉公式
4.3 傅里叶变换
四、概率论
1 标准正态分布
2 大数定理
3 随机事件和概率
- 全概率事件
- 独立重复试验
- 先验概率和后验概率
- 常见的几种分布
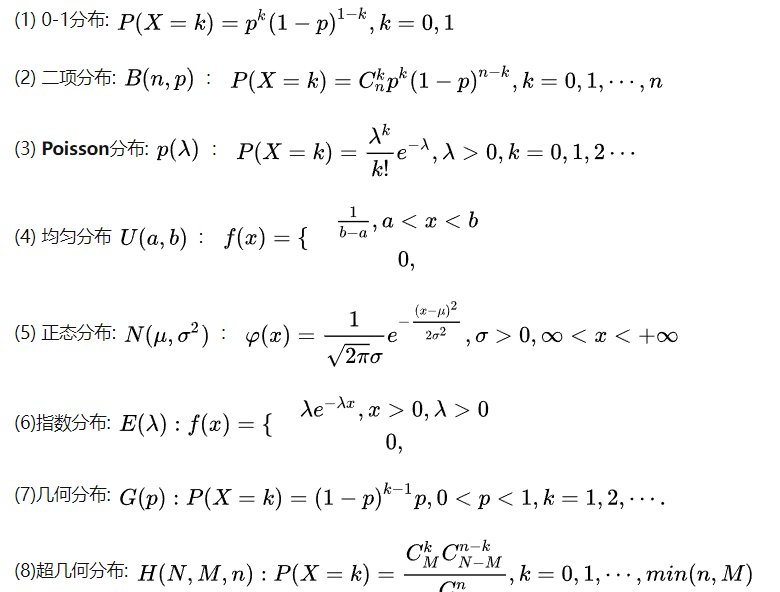
- 概率密度函数
五、线性代数
1、行列式

2、矩阵
2.1 注意事项
(1)矩阵乘法要求前列后行一致;
(2)矩阵乘法不满足交换律
2.2 转置
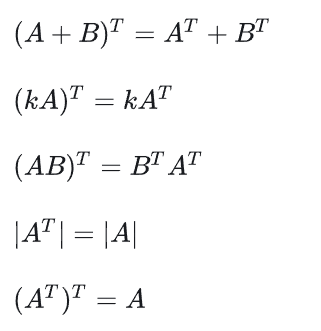
2.3 逆矩阵
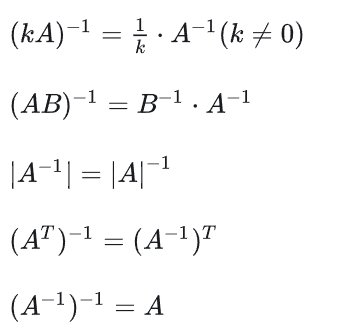
2.4 矩阵的秩
秩的定义: 非零子式的最高阶数


3、协方差矩阵
3.1 定义
- 标准差和方差是用来度量两个随机变量关系的统计量,协方差是度量各个维度偏离其均值的程度
- 协方差用于衡量两个变量的总体误差,方差是协方差的一种特殊情况,即当两个变量是相同的情况
期望值分别为E[X]与E[Y]的两个实随机变量X与Y之间的协方差Cov(X,Y)定义为
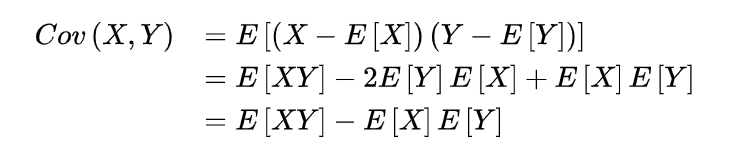
3.2 协方差的性质
D(X+Y)=D(X)+D(Y)+2Cov(X,Y)
D(X-Y)=D(X)+D(Y)-2Cov(X,Y)
2)协方差与期望值有如下关系:
Cov(X,Y)=E(XY)-E(X)E(Y)
3)协方差的性质:
(1)Cov(X,Y)=Cov(Y,X);
(2)Cov(aX,bY)=abCov(X,Y),(a,b是常数);
(3)Cov(X1+X2,Y)=Cov(X1,Y)+Cov(X2,Y)。
(4)Cov(X+a,Y+b) = Cov(X,Y)
4、自协方差矩阵
5、自相关矩阵
6、范数
范数,是具有“长度”概念的函数。范数定义了向量空间里的距离,它的出现使得向量之间的比较成为了可能。范数是一个函数,表示方式为||x||
L1范数,也叫曼哈顿距离:是一个向量中所有元素的绝对值之和。
L2范数,也叫欧几里得范数:是一个向量中所有元素取平方和,然后再开平方。
附录
1. 实数集
通常用大写字母R表示
包含所有有理数和无理数的集合
2. 标量:
一个标量就是一个单独的数。它不同于线性代数中研究的其他大部分对象(通常是多个数的数组)。我们用斜体表示标量。标量通常被赋予小写的变量名称。当我们介绍标量时,会明确它们是哪种类型的数。比如,在定义实数标量时,我们可能会说 ‘‘令 b ∈ R 表示一条线的斜率’’;在定义自然数标量时,我们可能会说 ‘‘令 M ∈ N 表示元素的数目’’。
3. 张量:
张量这一术语起源于力学,它最初是用来表示弹性介质中各点应力状态的,后来张量理论发展成为力学和物理学的一个有力的数学工具。张量之所以重要,在于它可以满足一切物理定律必须与坐标系的选择无关的特性。
张量概念是矢量概念的推广,矢量是一阶张量。张量是一个可用来表示在一些矢量、标量和其他张量之间的线性关系的多线性函数。
- 0阶张量:标量、常数,0-D Tensor
- 1阶张量:向量,1-D Tensor
- 2阶张量:矩阵,2-D Tensor
- 3阶张量 …
- N阶张量
3.1 张量与向量的区别
向量是一组标量组成的列表,向量也称为一维数组
矩阵是一组向量组成的集合,矩阵也称为二维数组
张量是矩阵的推广,描述N维数据
例如一张彩色图像,有宽度、高度,颜色通道RGB三通道,一张彩色图片就是三阶张量。
4. 点乘:也叫内积
数组相乘:对应位置相乘
矩阵相乘
5. 一组向量的生成子空间:
原始向量线性组合后所能到达的点的集合
6. 奇异矩阵
首先看矩阵是不是方阵,如果不是方阵,无所谓是不是奇异
性质:矩阵的秩是满秩
可逆矩阵就是奇异矩阵
笔记,奇异值分解 SVD 的详细讲解
7. 范数
为什么要引入范数
函数与几何图形往往有对应关系,在三维以下的空间中函数是几何图像的数学概括,而几何图像是函数的高度形象化。但当函数与几何超出三维空间时,难以获得较好的图像。于是有了映射的概念,进而引入范数的概念。
机器学习中,用来衡量向量的大小。
范数是具有“长度”的函数,在线性代数中,范数是一个函数,是矢量空间内的所有矢量赋予非零的正长度或大小。
宽泛定义:数学的一种基本概念。在泛函分析中,定义在赋范线性空间中,并满足一定的条件,即满足:
- 非负性
- 齐次性:也称为均匀性,输入函数扩大a倍,响应函数也扩大a倍
- 三角不等式
向量的范数可以简单形象的理解为向量的长度,或者向量到零点的距离,或者相应的两个点之间的距离。
向量的范数定义
8. 正交矩阵
正交矩阵充要条件:A的行(列)向量组是单位正交向量组。
数学含义
9. 方差——variance简写var
方差是在概率论和统计方差衡量随机变量或一组数据时离散程度的度量。概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。
统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。在许多实际问题中,研究方差即偏离程度有着重要意义。
方差是衡量源数据和期望值相差的度量值。
10. 标准差——standard deviation,简写STD或SD
是方差的平方根,标准差能反映一个 数据集的离散程度,平均数相同的两组数据,标准差未必相同。

注:
样本方差:其中n-1为贝塞尔校验,因为采集的样本不是无偏
总体方差与样本方差的分子计算不一样,样本方差为采集的计算
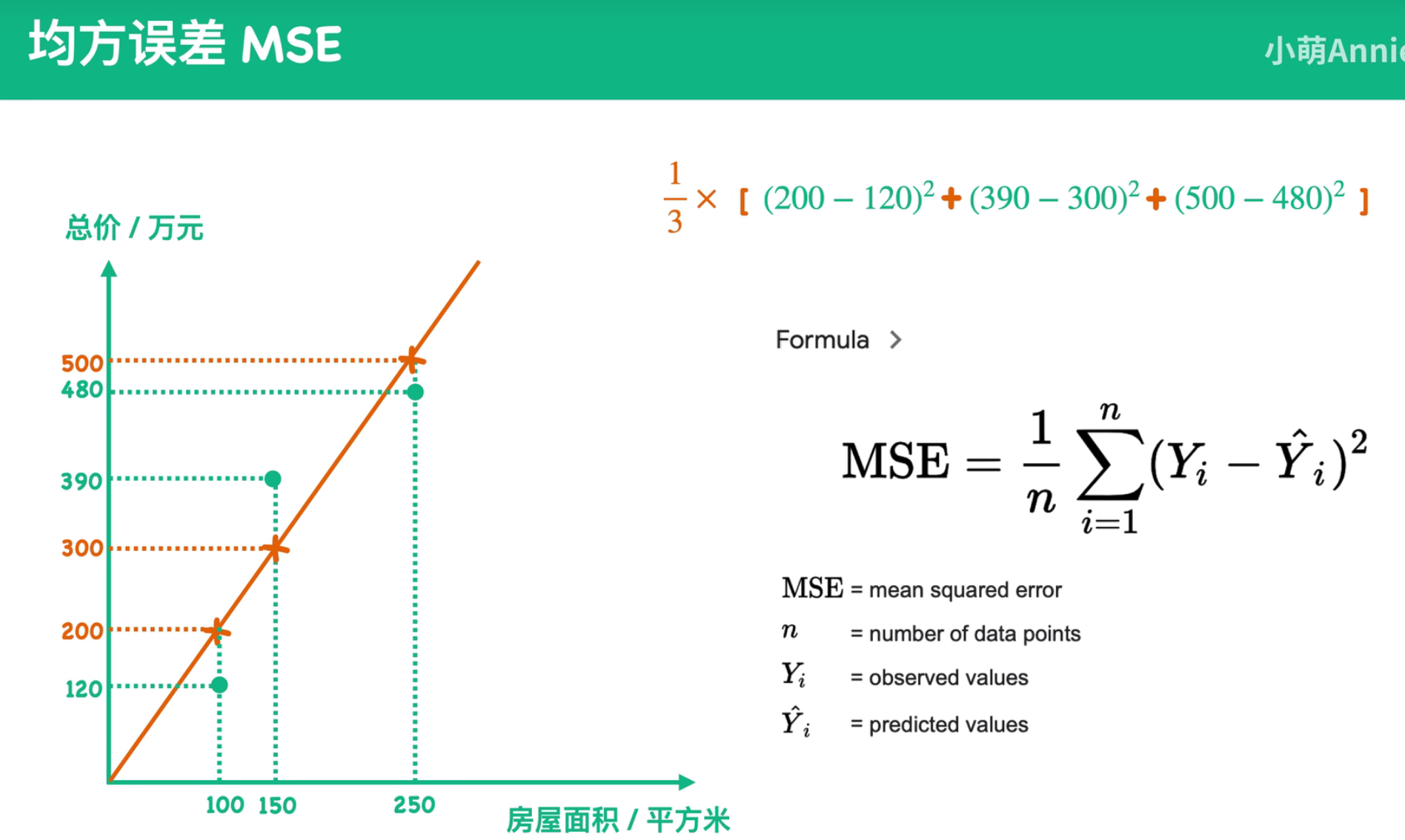
11. 均方根差(root mean square)-RMS
当我们在偏差更大和方差更大的估计中进行选择时,此时可以采用均方误差
MSE = E[(θ^-θ)²] = bias(θ^)² + Var(θ)
均方误差是各数据偏离真实值的距离平方和的平均数,也即误差平方和的平均数
样本点与真实值之间的差异
12. AUC
AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线,一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。
13. 协方差cov(X,Y)
方差是协方差的一种特殊情况,表示两个变量的总体误差。
公式:Cov(x,y) = ∑(x-x!)(y-y!) 其中x!,y!表示x,y的均值
14. 最小二乘法-least square method
 14.2 实例
14.2 实例
西瓜书中基于均方误差最小化求解模型。线性回归中,最小二乘法就是试图找到一条直线,使所有样本到直线上的欧氏距离之和最小。
15. 期望
15.1 定义
每次可能的结果概率乘以其结果的总和,可以反映随机变量平均取值的大小。期望值是该变量输出值的平均数
大数定理表明,随着重复次数接近无穷大,数值的算数平均值收敛于期望值
15.2 离散型变量期望
离散型随机变量取值为X1,X2,。。。,Xn,对应概率为P(x1),P(x2),…,P(xn),故期望或加权平均为下式
15.3 连续型随机变量
二维随机变量的期望

16. max与argmax

17.MAE(平均绝对误差损失即 L1 损失)
所有单个观测值与算术平均值的偏差的绝对值的平均
19 正态分布
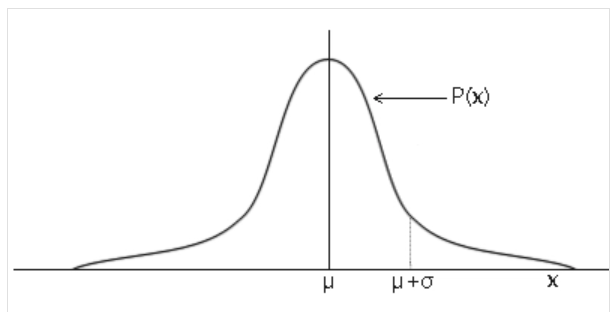
标准正态分布又称为u分布,是以0为均数、以1为标准差的正态分布,记为N(0,1)。
标准正态分布曲线下面积分布规律是:在-1.96~+1.96范围内曲线下的面积等于0.9500,在-2.58~+2.58范围内曲线下面积为0.9900
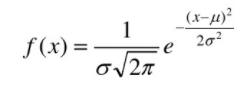
其中μ为平均数,δ^2为方差
则称随机变量x服从正态分布,记为X~N(μ,δ^2) .概率密度分布函数为
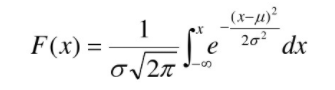
20 残差
残差在数理统计中是指实际观察值与估计值(拟合值)之间的差
21、 R²(R squared, Coefficient of determination):决定系数,
反映的是模型拟合数据的准确程度,一般R² 的范围是0到1。其值越接近1,表明方程的变量对y的解释能力越强,这个模型对数据拟合的也较好
22、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)
理论上,MAPE 的值越小,说明预测模型拟合效果越好,具有更好的精确度
25、argminf(x)函数
使目标函数f(x)取最小值时的变量x的值
26、偏差
偏差又称为表观误差,是指个别测定值与测定的平均值之差,它可以用来衡量测定结果的精密度高低
26.1 偏差分类
绝对偏差:是指某一次测量值与平均值的差异。 相对偏差:是指某一次测量的绝对偏差占平均值的百分比。
标准偏差:是指统计结果在某一个时段内误差上下波动的幅度。统计学名词。一种量度数据分布的分散程度之标准,用以衡量数据值偏离算术平均值的程度。标准偏差越小,这些值偏离平均值就越少,反之亦然。标准偏差的大小可通过标准偏差与平均值的倍率关系来衡量。
均偏差:是指单项测定值与平均值的偏差(取绝对值)之和,除以测定次数。
相对平均偏差:是指平均偏差占平均值的百分率。平均偏差和相对平均偏差都是正值。
26.2 误差与偏差
误差是测量值与真值之间的差值。用误差衡量测量结果的准确度,用偏差衡量测量结果的精密度;误差是以真实值为标准,偏差是以多次测量结果的平均值为标准。
27、调和平均数Harmonic Average,又称为倒数平均数
变量倒数的算法平均数的倒数
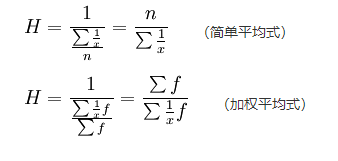
27.1 计算公式:给定数据的倒数算数平均数的倒数
28、大数定律
在随机事件的大量重复出现中,往往呈现几乎必然的规律,这个规律就是大数定律。
通俗地说,这个定理就是,在试验不变的条件下,重复试验多次,随机事件的频率近似于它的概率。偶然中包含着某种必然。
例如,抛硬币出现正反面的概率
29、残差平方和(Residual Sum of Squares,即RSS),又称剩余平方和
数据点与它在回归直线上相应位置的差异称为残差,把每个残差平方之后加起来称为残差平方和,它表示随机误差的效应。
30、均方误差MSE、均方根误差RMSE、平均绝对误差MAE、相对误差、绝对误差
1)相对误差:y-y’
2)绝对误差:(y-y’)/y
- 平均绝对误差(Mean Absolute Error, MAE):
是绝对误差的平均值,可以更好地反映预测值误差的实际情况
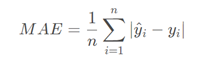
4)均方误差(Mean Square Error, MSE):
是真实值与预测值的差值的平方,然后求和的平均,一般用来检测模型的预测值和真实值之间的偏差
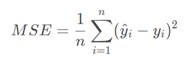
5)均方根误差(Root Mean Square Error)
RMSE:即均方误差开根号,方均根偏移代表预测的值和观察到的值之差的样本标准差
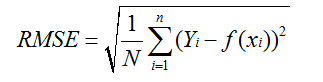
应用:
大部分时间,模型的预测效果优秀,然而,RMSE却一直很差,原因为存在严重的离群点
解决方式:三个角度
1.数据预处理将噪声过滤
2.提高模型预测能力,将离群点产生机制考虑
3.找更合适的指标来评估模型,例如MAPE
31、概率密度函数
概率密度函数用数学公式表示就是一个定积分的函数,定积分在数学中是用来求面积的,而在这里,你就把概率表示为面积即可
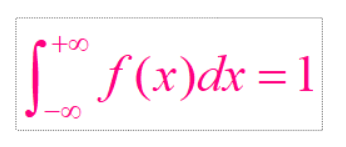
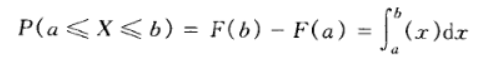
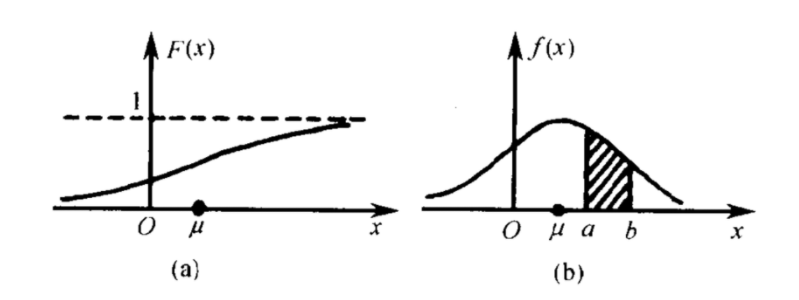
左边是F(x)连续型随机变量分布函数画出的图形,右边是f(x)连续型随机变量的概率密度函数画出的图像,它们之间的关系就是,概率密度函数是分布函数的导函数。
对比两张图,如果用右图中的面积来表示概率,利用图形就能很清楚的看出,哪些取值的概率更大!所以,我们在表示连续型随机变量的概率时,用f(x)概率密度函数来表示,是非常好的!
32、泰勒展开公式
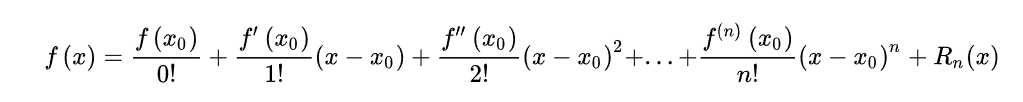
常用泰勒展开公式

33、双曲函数
33.1 双曲函数公式
sinh、cosh、tanh
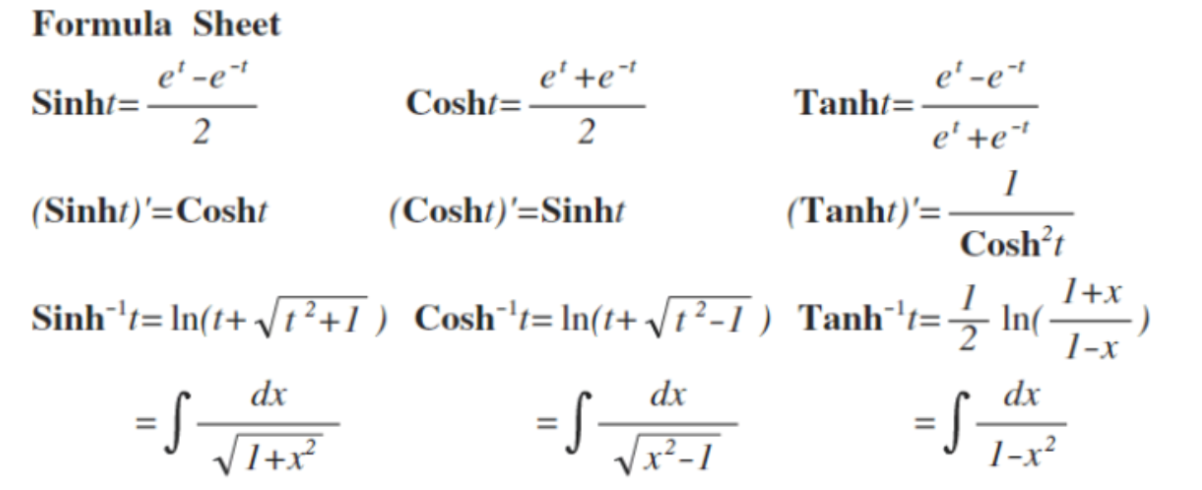
33.2 双曲函数的图像
34、导数与梯度的关系
方向导数是沿各个方向的导数,梯度是一个向量。梯度本身是有方向的
- 函数在梯度这个方向的方向导数最大。一个函数在各个方向都有方向导数,其中梯度这个方向的导数为最大。
- 函数方向导数的最大值为梯度的模。
35、KKT条件
KKT(Karush-Kuhn-Tucker)条件作为带约束可微分优化问题的最优性条件。针对约束优化非常通用的解决方案
36、反函数
36.1 映射与反映射
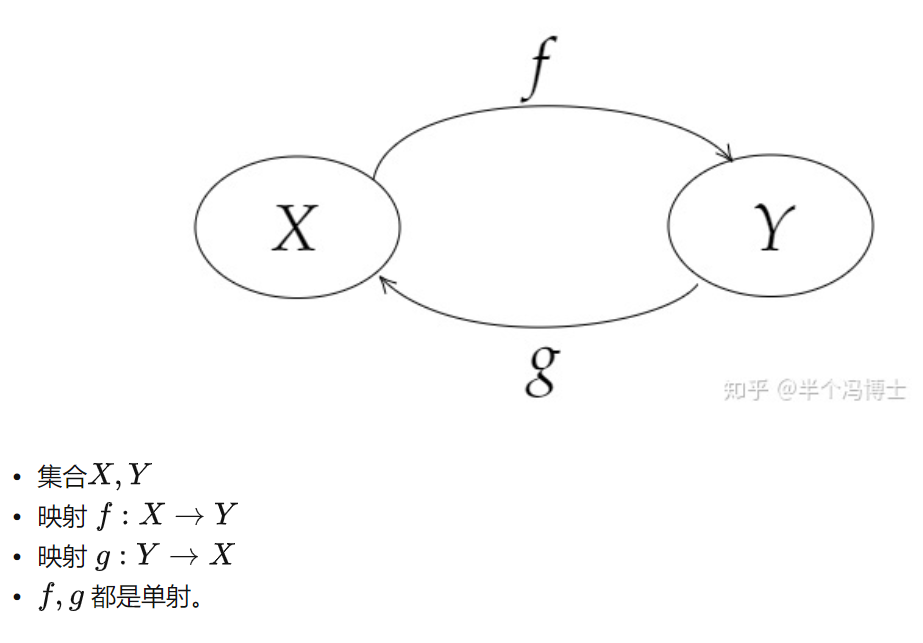
36.2 函数与反函数
把前节内容中所有
- 映射换成函数
- 逆换成反
- 单射,映射换成单调函数
- 直接函数与反函数关于y=x轴对称
36.3 实例

36.4 反三角函数
反三角函数的基本形式都是在特定的条件下定义的,它们并不直接代表三角函数的反函数,而是在特定区间上的三角函数的反函数。
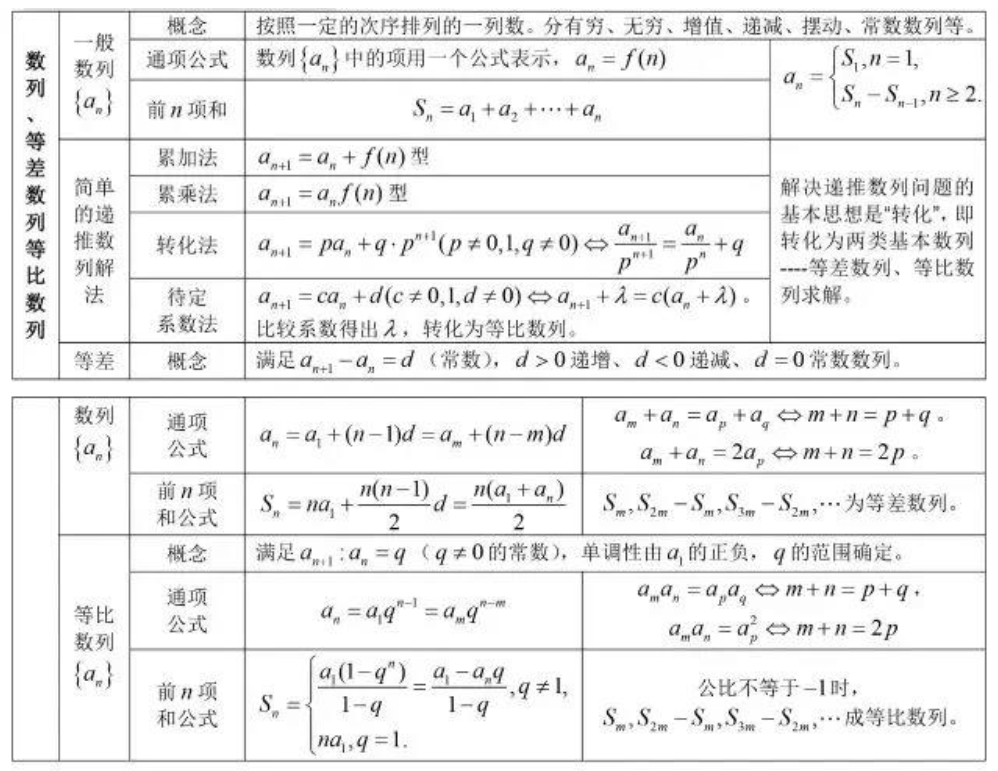
37、求和公式
38、零阶矩、一阶矩、二阶矩
数学中矩的概念来自物理学。在物理学中,矩是表示距离和物理量乘积的物理量,表征物体的空间分布
物理学中
- 零阶矩 是总质量
- 一阶原点矩 是质心
- 二阶原点矩 是转动惯量
数学中:“矩”是一组点组成的模型的特定的数量测度
几何矩、正交矩、复数矩和旋转矩
一阶矩就是期望值,换句话说就是平均数(离散随机变量很好理解,连续的可以类比一下)
二阶(非中心)矩就是对变量的平方求期望,二阶中心矩就是对随机变量与均值(期望)的差的平方求期望
39、概率、统计、似然和似然函数
似然:影响概率的未知参数。参数未知,观察结果,求未知参数的可能取值
概率(probabilty):一件事情发生的可能性。参数已知时随机变量的结果。
概率研究的问题是,已知一个模型和参数,怎么去预测这个模型产生的结果的特性(例如均值,方差,协方差等等)
统计(statistics):有一堆数据,要利用这堆数据去预测模型和参数
似然函数(likelihood function):关于模型参数的概率密度函数的对数值
40、对数似然
似然函数是多个数相乘,计算复杂,也不宜求导,因此将其取对数
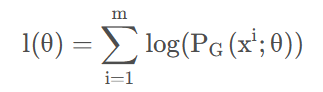
41 负对数似然
由于对数似然是对概率分布求对数,概率P(x)取值为【0,1】,取对数后值域为【-无穷,0】,加负号改变值域
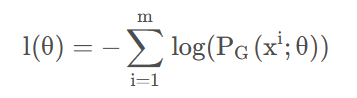
42、极大似然原理
一个随机试验如有若干个可能的结果A,B,C,… ,若在一次试验中,结果A出现了,那么可以认为实验条件对A的出现有利,也即出现的概率P(A)较大。
极大似然原理的直观想法我们用下面例子说明。
设甲箱中有99个白球,1个黑球;乙箱中有1个白球.99个黑球。现随机取出一箱,再从抽取的一箱中随机取出一球,结果是黑球,这一黑球从乙箱抽取的概率比从甲箱抽取的概率大得多,这时我们自然更多地相信这个黑球是取自乙箱的
43、极大似然估计——Maximum Likelihood Estimate,MLE
一种求估计的方法。已知某个随机样本满足某种概率分布,但是其中的参数不清楚,参数估计就是通过若干次试验,观察结果,利用结果推断参数的大概取值。
极大似然估计就是建立在这样的基础上:已知某个参数使这个样本出现的概率最大, 把这个参数作为估计的真实值。
极大似然估计中采样需满足一个重要的假设,就是所有的采样都是独立同分布的
一句话概括:模型已定,参数未知
极大似然估计:
所有样本都被预测正确这个事件,概率最大化
事件预测的概率计算方法为所有事件的概率结果相乘
为方便求解对其求对数,改为相加
单调性没有改变,还是求其最大化
求极大似然函数估计值的步骤:
1)写出似然函数
2)对似然函数取对数,并整理
3)求导数
4)解似然方程

表示从u节点出发,到达v的概率

44、最大似然估计
1.简介
最大似然原理:概率最大的事件是最可能发生的
最大似然估计:利用最大似然原理完成参数估计。利用一只样本结果,反推最优可能导致出现这样结果的参数时多少。
2 数学解释
是一种关于统计模型参数的函数。给定输出x时,关于参数θ的似然函数L(θ|x)(在数值上)等于给定参数θ后变量X的概率:L(θ|x)=P(X=x|θ)。
注意:似然与概率不同。概率描述的是已知参数时的随机变量的输出结果。似然描述已知变量结果,未知参数的可能取值给定输出x时,关于参数θ的似然函数L(θ|x)(在数值上)等于给定参数θ后变量X的概率:
3、最大似然估计的一般步骤
(1) 写出似然函数;
(2) 对似然函数取对数,得到对数似然函数;
(3) 求对数似然函数的关于参数组的偏导数,并令其为0,得到似然方程组;
(4) 解似然方程组,得到参数组的值。
45、最大似然估计和极大似然估计
思想和方法都不同
最大似然估计:不断挑选使得似然函数值最大的参数值,直到满足预设的显著性水平或者达到一定的迭代次数。
极大似然估计:通过建立一个概率模型来估计参数,该模型会通过搜索最优的参数组合来尽可能地逼近参数真实的分布。它的思想是通过建立一个概率模型,将样本的结果映射到模型中,然后利用模型来估计参数,使得估计结果尽可能地逼近参数的真实值。
区别
最大似然估计是在样本已有结果的情况下,尽可能地搜索参数的值,以得到最大的信息量;而极大似然估计是在建立概率模型的基础上,通过搜索最优的参数组合来估计参数,以得到最接近真实值的结果。
















 5080
5080











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









