







1. 前言
VGG在2014年由牛津大学著名研究组VGG(visual geometry group)提出,斩获该年ImageNet竞赛中Localization Task(定位任务)第一名和Classification Task(分类任务)第二名,原论文链接(Very Deep Convolutional Networks for Large-Scale Image Recognition)
2. 网络的亮点
通过堆叠多个33卷积核来替代大尺度卷积核(减少所需参数,可以更加steadily地增加层数得同时不会太过于担心计算量的暴增),论文中提到通过堆叠两个33卷积核来替代55卷积核,三个33卷积核来替代7*7卷积核,因为它们拥有相同的感受野。
3. 网络结构图
VGGNet模型有A-E五种结构网络,深度分别为11,11,13,16,19。其中较为典型的网络结构主要有vgg16和vgg19,本篇文章主要讲VGG16
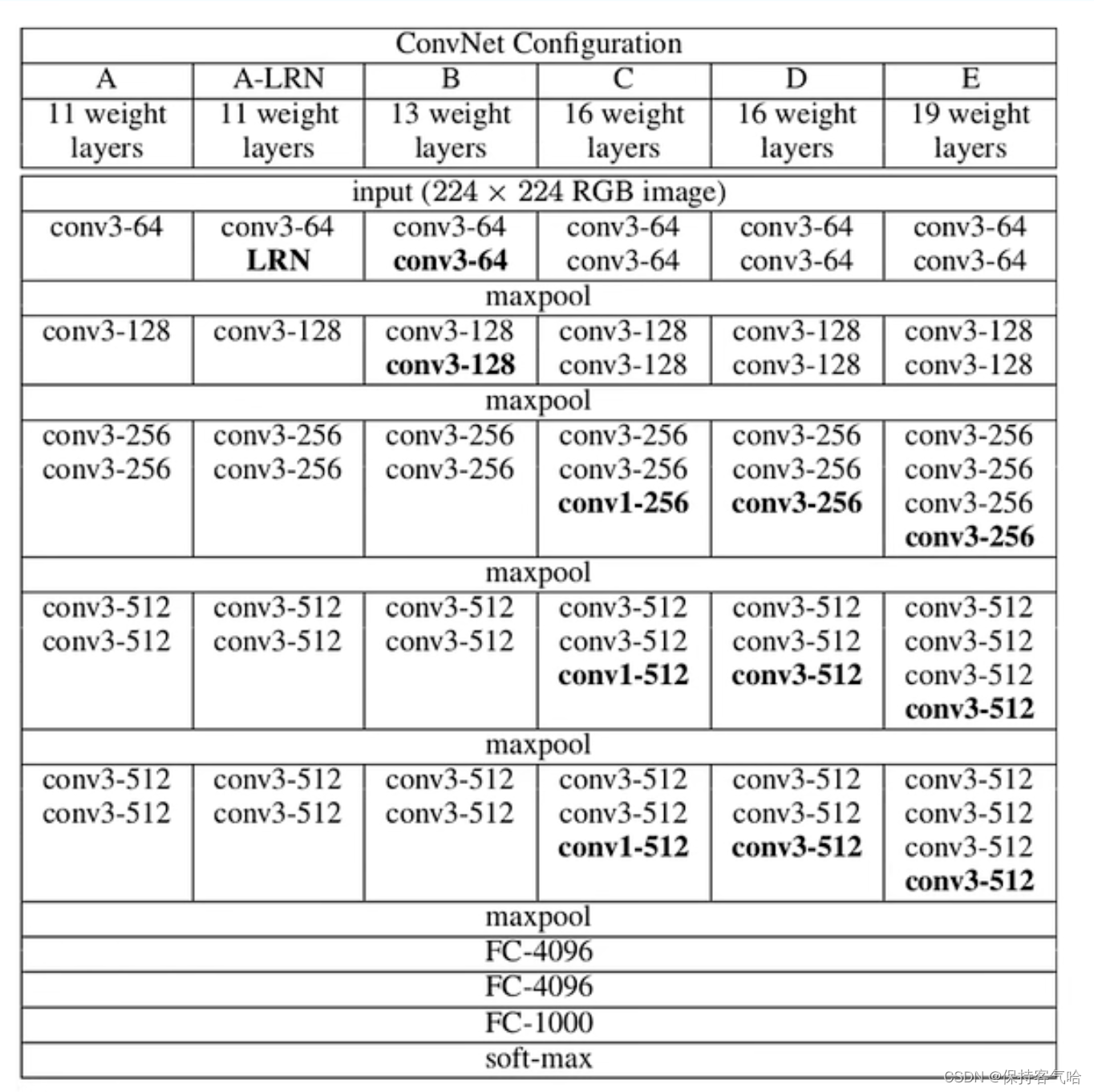
注:在表中:
- conv的padding为1,stride也是1(可以改变大小,也可以改变通道数)
- maxpool的size是2,stride也是2(只能改变大小)
- 卷积层全部都是3*3的卷积核,用上图中conv3-xxx表示,xxx表示通道数。
- input(224x224 RGB image) :指的是输入图片大小为224x244的彩色图像,通道为3,即224x224x3
下图是根据D模型进行绘制的:利用out = (in - F+2P)/S+1 进行验证
F是卷积核大小,P是padding的size,S是stride ,in是输入特征图大小,out是输出特征图大小
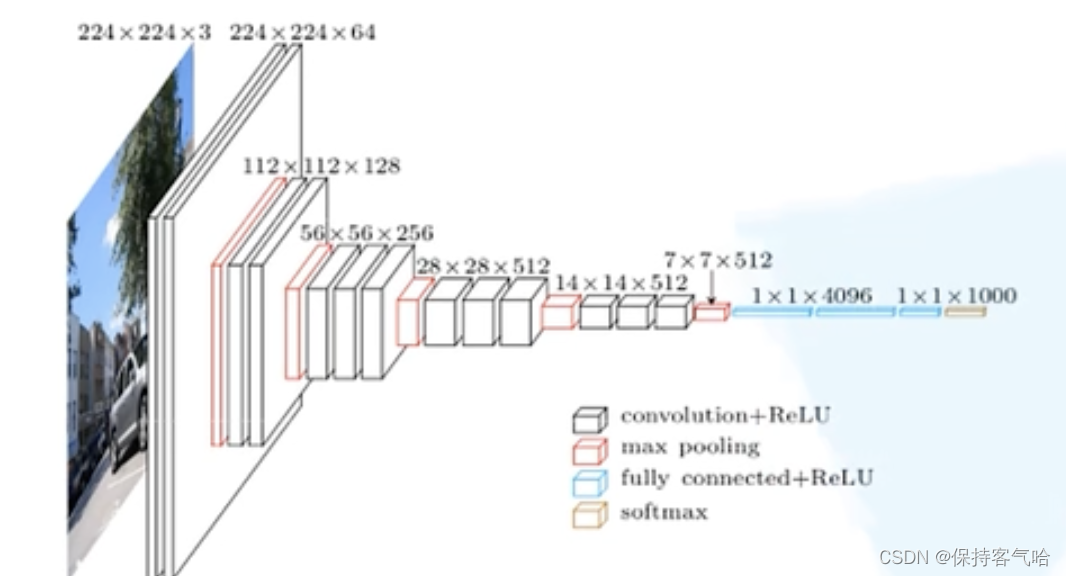
详细介绍:
- conv3-64 :是指第三层卷积后维度变成64,同样地,conv3-128指的是第三层卷积后维度变成128;
- input(224x224 RGB image) :指的是输入图片大小为224✖️244的彩色图像,通道为3,即224✖️224✖️3;
- 通道数分别为64,128,512,512,512,4096,4096,1000。卷积层通道数翻倍,直到512时不再增加。通道数的增加,使更多的信息被提取出来。全连接的4096是经验值,当然也可以是别的数,但是不要小于最后的类别。1000表示要分类的类别数
- 用池化层作为分界,VGG16共有6个块结构,每个块结构中的通道数相同。因为卷积层和全连接层都有权重系数,也被称为权重层,其中卷积层13层,全连接3层,池化层不涉及权重。所以共有13+3=16层
- 13层卷积层和5层池化层负责进行特征的提取,最后的3层全连接层负责完成分类任务















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









