







1.BatchNormalization
Batch Normalization简称BN,是2015年提出的一种方法《Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift》
原论文地址:https://arxiv.org/abs/1502.03167


1.1 引入BN的原因
在图像预处理的时候通常会对图像进行标准化处理,使得每张图片满足标准正态分布,原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,我们拿着训练数据训练的模型去测试数据上,效果就肯定不是那么好,那么网络的泛化能力也大大降低,这也就是“Internal covariate“问题。我们既然对输入图像进行了预处理操作,那么对于一个深度神经网络,当一张经过标准化处理的图片经过卷积之后这个分布就不一定满足像一开始那样的标准分布了,后面更是如此,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
Batch Normalization是用来解决“Internal covariate“,它的思想是能不能让每个隐层节点的激活输入分布固定下来,而这个思想是来自于可以参考白化(Whiten)(所谓白化,就是对输入数据分布变换到均值为0,方差为1的正态分布),那么神经网络就可以加速收敛。那回到图像上来,图像对应的神经网络的输入层,白化既然能加速收敛,那么对于一个具有隐藏层的深度神经网络,其中某个隐藏层的输出是下一个隐藏层的输入,这样就类似于输入层,只不过是相对下一层,那么能不能对每层都做个白化操作呢?所以BN就是这种思想:对每个隐层都做一个简化的白化操作。
注:“Internal covariate” 是指训练集的数据分布和测试集的数据分布不一样,那么当我们训练完再来预测肯定不是最好的结果,这种现象称为“covaraiteshift”问题,对于深度学习这种包含很多隐层的网络结构,在训练过程中,因为各层参数不停在变化,所以每个隐层都会面covariate shift的问题。也就是在训练过程中,隐层的输入分布老是变来变去,导致网络模型很难稳定的学规律,这就是所谓的“Internal Covariate Shift”,Internal指的是深层网络的隐层,是发生在网络内部的事情,而不是covariate shift问题只发生在输入层
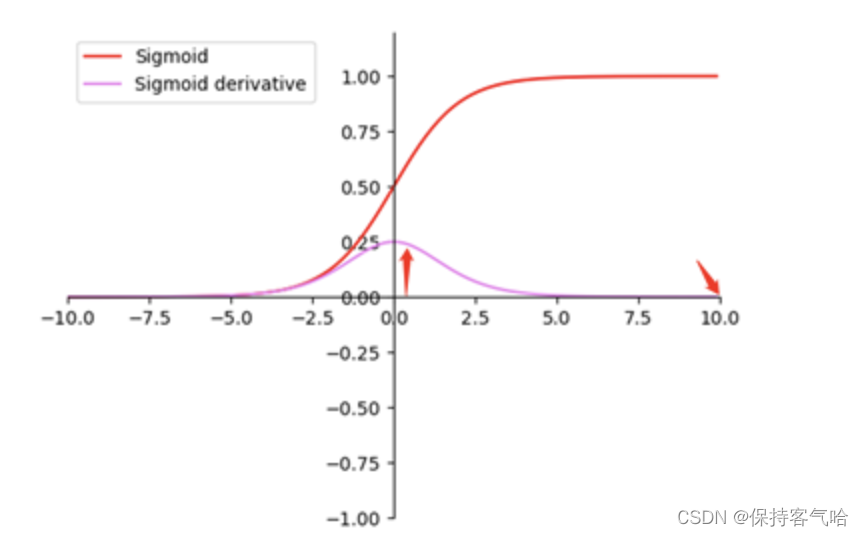
当数据不满足统一的分布时,这个时候将数据接入激活函数时,很可能输出的数据会落入激活函数的饱和区,导致神经网络在反向传播的时候梯度消失,导致收敛过慢。如下图所示当feature map的数据为10的时候,就会落入饱和区,影响网络的训练效果。这个时候我们引入Batch Normalization的目的就是使我们卷积以后的feature map满足均值为0,方差为1的分布规律。这样一些激活值就会在激活函数的非饱和区域(敏感区域),这样对于激活值的微小变化,也会导致最终的损失函数值产生对应的变化,梯度也就变大,避免了梯度消失现象,也能加快收敛速度。
1.2 BN的操作过程
就像激活函数层、卷积层、全连接层、池化层一样,BN(Batch Normalization)也属于网络的一层。在前面我们提到网络除了输出层外,其它层因为低层网络在训练的时候更新了参数,而引起后面层输入数据分布的变化。这个时候我们可能就会想,如果在每一层输入的时候,再加个预处理操作那该有多好啊,比如网络第三层输入数据X3(X3表示网络第三层的输入数据)把它归一化至:均值0、方差为1,然后再输入第三层计算,这样我们就可以解决前面所提到的“Internal Covariate Shift”的问题了。
而事实上,paper的算法本质原理就是这样:在网络的每一层输入的时候,又插入了一个归一化层,也就是先做一个归一化处理,然后再进入网络的下一层。不过文献归一化层,可不像我们想象的那么简单,它是一个可学习、有参数的网络层。
原论文中指到:“对于一个拥有d维的输入x,我们将对它的每一个维度进行标准化处理。” 假设我们输入的x是RGB三通道的彩色图像,那么这里的d就是输入图像的channels即d=3,,其中就代表我们的R通道所对应的特征矩阵,依此类推。标准化处理也就是分别对我们的R通道,G通道,B通道进行处理。上面的公式不用看,原文提供了更加详细的计算公式:


我们刚刚有说让feature map满足某一分布规律,理论上是指整个训练样本集所对应feature map的数据要满足分布规律,也就是说要计算出整个训练集的feature map然后在进行标准化处理,对于一个大型的数据集明显是不可能的,所以论文中说的是Batch Normalization,也就是我们计算一个Batch数据的feature map然后在进行标准化(batch越大越接近整个数据集的分布,效果越好)。我们根据上图的公式可以知道代表着我们计算的feature map每个维度(channel)的均值,注意是一个向量不是一个值,向量的每一个元素代表着一个维度(channel)的均值,代表着我们计算的feature map每个维度(channel)的方差,然后根据和计算标准化处理后得到的值。下图给出了一个计算均值和方差的示例:
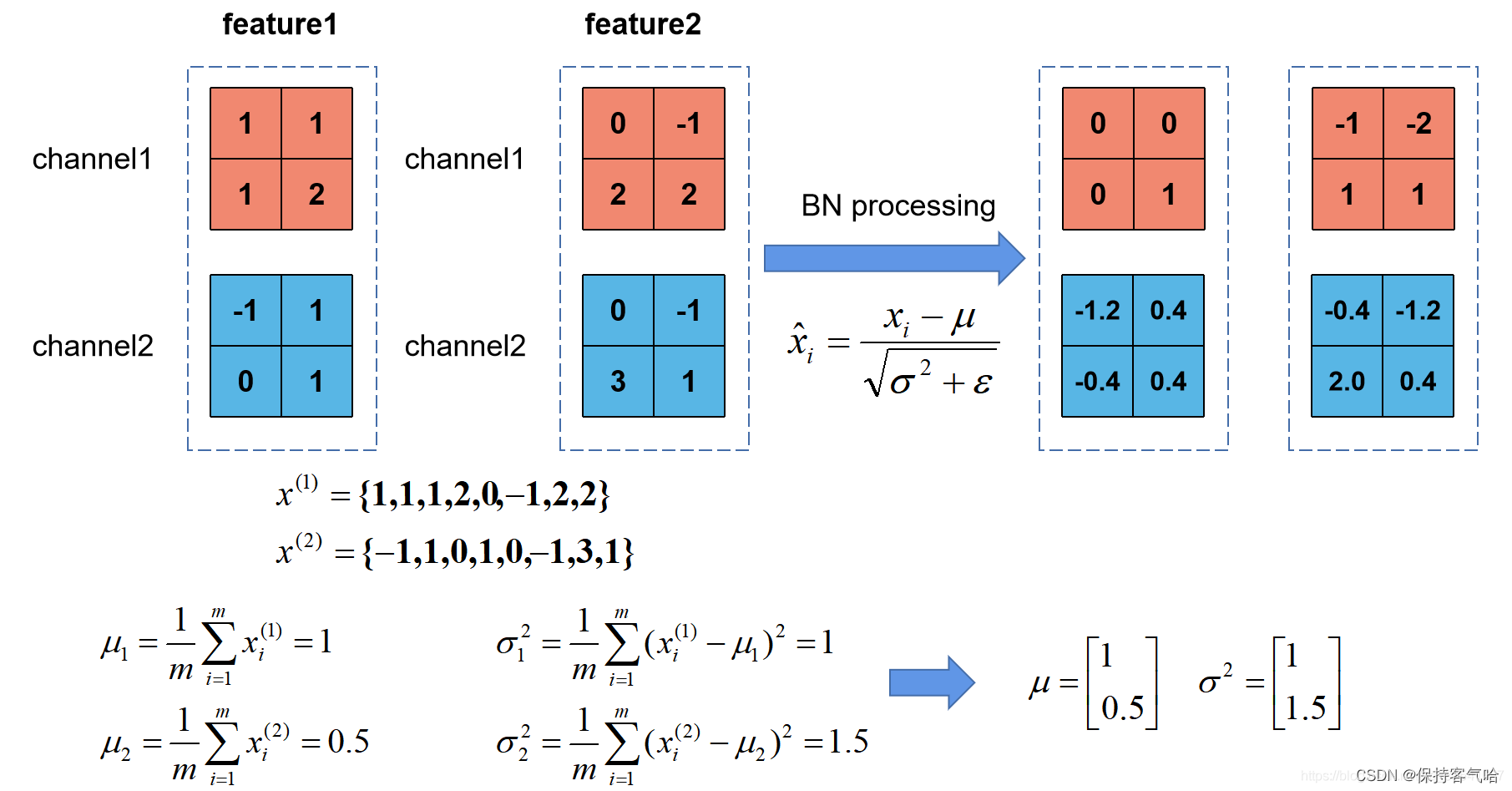
上图展示了一个batch size为2(两张图片)的Batch Normalization的计算过程,假设feature1、feature2分别是由image1、image2经过一系列卷积池化后得到的特征矩阵,feature的channel为2,那么代表该batch的所有feature的channel1的数据,同理代表该batch的所有feature的channel2的数据。然后分别计算和的均值与方差,得到我们的和两个向量。然后在根据标准差计算公式分别计算每个channel的值(公式中的是一个很小的常量,防止分母为零的情况)。在我们训练网络的过程中,我们是通过一个batch一个batch的数据进行训练的,但是我们在预测过程中通常都是输入一张图片进行预测,此时batch size为1,如果在通过上述方法计算均值和方差就没有意义了。所以我们在训练过程中要去不断的计算每个batch的均值和方差,并使用移动平均(moving average)的方法记录统计的均值和方差,在训练完后我们可以近似认为所统计的均值和方差就等于整个训练集的均值和方差。然后在我们验证以及预测过程中,就使用统计得到的均值和方差进行标准化处理。
会发现,在原论文公式中不是还有,两个参数吗?是的,是用来调整数值分布的方差大小,是用来调节数值均值的位置。这两个参数是在反向传播过程中学习得到的,伽马的默认值是1,贝塔的默认值是0。
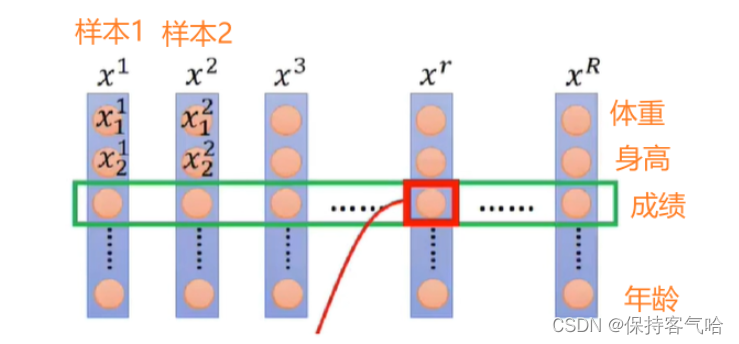
附上一张更好理解的图片:我们会对R个样本的“成绩”这个特征维度做归一化,求其均值和方差
1.3 使用BN需要注意的问题
(1)训练时要将traning参数设置为True,在验证时将trainning参数设置为False。在pytorch中可通过创建模型的model.train()和model.eval()方法控制。
(2)batch size尽可能设置大点,设置小后表现可能很糟糕,设置的越大求的均值和方差越接近整个训练集的均值和方差。研究表明对于ResNet类模型在ImageNet数据集上,batch从16降低到8时开始有非常明显的性能下降。所以BN不适应于当训练资源有限而无法应用较大的batch的场景。
(3)建议将bn层放在卷积层(Conv)和激活层(例如Relu)之间,且卷积层不要使用偏置bias,因为没有用,参考下图推理,即使使用了偏置bias求出的结果也是一样的
1.4 BN的缺点
BN虽然带来了很多好处,不过BN的缺点还是有一些的:
- BN特别依赖Batch Size;当Batch size很小的适合,BN的效果就非常不理想了。在很多情况下,Batch size大不了,因为你GPU的显存不够。所以,通常会有其他比较麻烦的手段去解决这个问题,比如MegDet的CGBN等
- BN对处理序列化数据的网络比如RNN是不太适用的;So,BN的应用领域减少了一半
- BN只在训练的时候用,inference的时候不会用到,因为inference的输入不是批量输入。这也不一定是BN的缺点,但这是BN的特点。
2. Layer Normalization
论文标题:Layer Normalization

2.1 引入LN的原因
Layer Normalization是针对自然语言处理领域提出的,例如像RNN循环神经网络。为什么不使用直接BN呢,因为在RNN这类时序网络中,时序的长度并不是一个定值(网络深度不一定相同),比如每句话的长短都不一定相同,所有很难去使用BN。
Layer Normalization (LN) 的一个优势便是无需批训练,其在单个样本内部就能归一化。BN的操作是,对同一批次的数据分布进行标准化,得出的均值方差,其可信度受batch size影响。很容易可以想到,如果我们对小batch size得出均值方差,那势必和总数据的均值方差有所偏差。这样就解释了BN的第一个缺点:BN特别依赖Batch Size;对于 LN 与 BN 而言,BN 取的是不同样本的同一个特征,而 LN 取的是同一个样本的不同特征
2.2 LN的操作过程
LN的操作对同一层网络的输出做一个标准化。注意,同一层的输出是单个图片的输出,比如对于一个batch为32的神经网络训练,会有32个均值和方差被得出,每个均值和方差都是由单个图片的所有channel之间做一个标准化。这么操作,就使得LN不受batch size的影响。举个例子,如下图:由于样本不定长,所以LN就是对每个样本的不同维度(每个字是一个维度)作归一化操作。

它们的公式都是差不多的,就是减去均值,除以标准差,再施以线性映射。(只不过在对哪些维度求均值、方差,以及参数γ 和β怎么对应有差异)
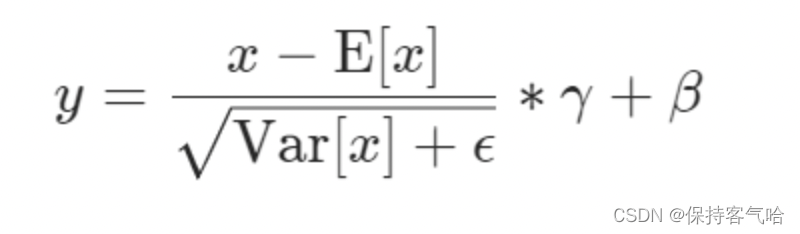
为了更好理解:LN的操作如下图所示,我们沿着Channel方向去求其均值和方差(图中红色虚线部分)


3.Instance Normalization

instance normalization是一种归一化方法,它将每个样本的均值和标准差归一化到特定的值。这种方法通常用于卷积神经网络(CNN)中,可以加速训练和提高模型的稳健性。
原论文:Instance Normalization: The Missing Ingredient for Fast
Stylization
原论文链接:https://arxiv.org/abs/1607.08022
对于IN,它是一种更适合对单个像素有更高要求的场景的归一化算法(IST,GAN)所以,其在风格迁移领域被广泛应用。
IN是计算归一化统计量时考虑单个样本、单个通道的所有元素。
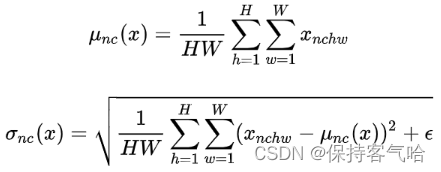
4.Group Normalization

论文:Group Normalization
论文链接:https://arxiv.org/abs/1803.08494
4.1 GN的由来
Group Normalization(GN)是针对Batch Normalization(BN)在batch size较小时错误率较高而提出的改进算法,因为BN层的计算结果依赖当前batch的数据,当batch size较小时(比如2、4这样),该batch数据的均值和方差的代表性较差,因此对最后的结果影响也较大。
4.2 GN的操作过程
GN在Channel方向分组(group),然后在每个group内进行归一化
有了前面的介绍,其实GN直观上像是LN的和IN的折中,当分组数量为1时,GN就变成了LN,分组数量等于通道数时,GN就变成了IN。
5.总结
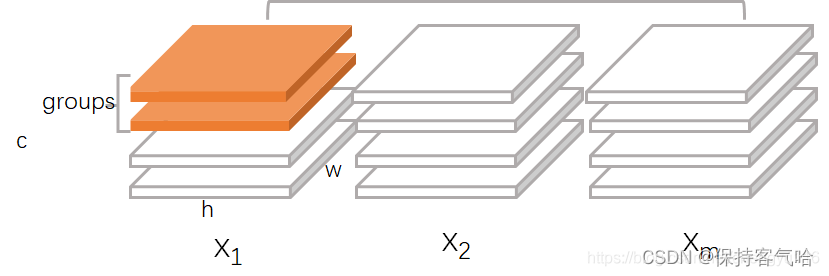
下面是几种归一化方式的对比(Bartch Norm、Layer Norm、Instance Norm和Group Norm),可以一并回顾下BN算法。Figure2中的立方体是三维,其中两维C和N分别表示channel和batch size,第三维表示H,W,可以理解为该维度大小是H*W,也就是拉长成一维,这样总体就可以用三维图形来表示。可以看出BN的计算和batch size相关(蓝色区域为计算均值和方差的单元),而LN、BN和GN的计算和batch size无关。同时LN和IN都可以看作是GN的特殊情况(LN是group=1时候的GN,IN是group=C时候的GN)
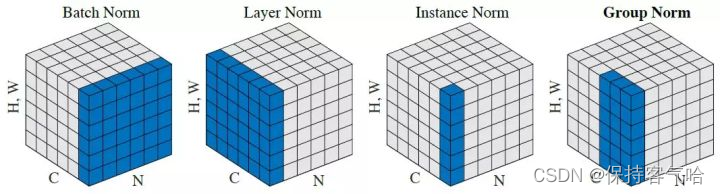
BN,LN,IN,GN从学术化上解释差异:
- BatchNorm:batch方向做归一化,算NHW的均值
- LayerNorm:channel方向做归一化,算CHW的均值
- InstanceNorm:一个channel内做归一化,算H*W的均值
- GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值
计算机视觉(CV)领域的数据x xx一般是4维形式,如果把![]() 类比为一摞书,这摞书总共有 N 本,每本有 C 页,每页有 H 行,每行 W 个字符。
类比为一摞书,这摞书总共有 N 本,每本有 C 页,每页有 H 行,每行 W 个字符。
计算均值时:
- BN 相当于把这些书按页码一一对应地加起来(例如:第1本书第36页,加第2本书第36页…),再除以每个页码下的字符总数:N×H×W,因此可以把
BN 看成求“平均书”的操作(注意这个“平均书”每页只有一个字)- LN 相当于把每一本书的所有字加起来,再除以这本书的字符总数:C×H×W,即求整本书的“平均字”
- IN 相当于把一页书中所有字加起来,再除以该页的总字数:H×W,即求每页书的“平均字”
- GN 相当于把一本 C 页的书平均分成 G 份,每份成为有 C/G 页的小册子,对这个 C/G 页的小册子,求每个小册子的“平均字”
原文链接:https://blog.csdn.net/qq_43827595/article/details/121877901















 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









