









作者主页(文火冰糖的硅基工坊):https://blog.csdn.net/HiWangWenBing
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/119191407
目录
6.1 第一种是“学渣型”,考试不及格,不能毕业: “欠拟合”
6.2 第二种是“学霸型”,成绩理想,完成毕业:“拟合合适”
摘要:
用最朴实、最白话的语言,带你一起看看高大尚的机器学习的门楣:人工智能、机器学习、神经网络、深度学习、监督式学习、非监督式学习、强化学习训练、预测、推理、欠拟合、过拟合、标签、样本、训练数据集、验证数据集合、测试数据集、微调。
前言:
什么是机器学习?
这是一个答案很抽象的问题,对于专业技术人员来看,答案就是地地道道的数学算法。
这是一个答案很简单的问题,因为每个人都有过学习的经历和体验,成为当下的自己。
下面就跟随我一起从我们自身学习的体验来看看什么是机器学习?什么是深度学习?
第1部分. 没有“机器学习”能力的机器是什么样子的?

设想有一种不幸的远古人,出生后除了大脑有先天缺陷,其他生理都是正常的: 肚子饿了会吃饭,困了会睡觉,醒来会走动,看到刺眼的阳光会闭眼,遇到刺痛也会躲避,甚至看到异性也会流口水,一个生命体所有的复杂特征它都具备。
但它不认识周围的动物、植物、甚至父母,它听不懂其它人在说什么,也不会使用语言,更不会使用各种工具。他所有的一生的行为都是通过基因先天遗传而来的,与出生时一样,后天没有学习到任何新的行为。这就一个没有“学习”能力的人的样子。

传统的智能洗衣机、手机、汽车、电脑、宇宙飞船等这些“智能”设备或机器。虽然有智能,他们的外部行为和内部的逻辑都是预先设计好的,自从它们被生产出来后,他们的行为都是可预期的,直到报废。如果有一天或有一次,它们的行为与预期不一样,我们称之为bug。
因为机器没有“学习”能力,它们的智能行为是由一群被称为软、硬件工程师们赋于的。
第2部分. 有了学习能力的机器是什么样子的?

人出生之后就具备了先天的“学习”的能力,并从父母、老师、同学、朋友那里学习各种知识、技能,并逐渐演化成当下的自己,当下的自己已经不是出生时候的对这个世界一无所知的自己了。

传统的智能机器不是天生具备“学习”能力的,机器的“学习”能力是由一群人工智能科学家和工程师赋予的。
机器有了“学习”能力之后,人工智能的工程师们,不再需要预先给机器设计所有场景下的所有的行为,他们只需要给机器设计好不同场合的“学习”的方法,正所谓“授人以鱼不如授人以渔”。
有了学习能力之后,机器就能够通过学习使得自己具备原先不具有的能力。
第3部分. 机器学成之后是什么样子的?
我们长大后成为什么样的人,取决于在我们成长的过程中,学到了什么?可以成为工程师、教师、律师、医生等等。

机器学成后会是什么样子呢?其实也是取决于人工智能的工程师们让机器学习了什么。
也就是说,无论是人还是机器,其能力是习得的,而不是预先设计好,唯一设计好的就是由基因决定的学习的能力。机器的基因就是其人工神经网络的“模型”。
如下是机器学习之后,机器能做的一些事情的典型案例。实际上,远比这些多得多,现实生活中,人能做到的事,基本上机器未来都能做,在某些领域,甚至比大多数人做得更好,只是时间的问题。



学习完成之后,机器就能够无怨无悔、不辞辛劳的处理上述事务。
这个过程,在机器学习领域有一个专业的名字叫“预测”,又叫“推理”。
其实就是机器按照学习的结果在干活的过程。
第4部分. 学习的形式
4.1 监督式学习

出生后,我们来到了一个一无所知的完全陌生的世界。通过牙牙学语,知道了自己父母和周边的环境事物的名称。通过妈妈读绘本,知道大自然中动物、植物的名称。通过学校的课堂教育,学习了语言文字、各种知识、技能。所有这些学习,都有一个共同的特点:就是有人事先告诉我们标准答案:谁是爸爸妈妈,什么是小猫,小狗,什么是数字?什么是文字?这是我们学习的最主要的方式。
在机器学习领域,人工智能的科学家们,给机器的这种学习方式,取了一个专业的名词:“监督式学习”。这时候,机器学习的工程师们充当了机器的父母、老师的角色。
4.2 非监督式学习
有时候,不是所有的事物都有标准答案,比如下面这12幅画,我们并不知道他们的学名叫什么,假设也没有人告诉我们标准答案。

但这并不意味着,我们不能从上述图形中学习。学习后,我们可以把它们分为三类:

现在给我们任意下面的一幅画,我们也能很容易的辨认出它们属于记忆中的哪一类动物。

上述这个过程,在机器学习领域,有一个专业的名字叫“非监督式学习”。
4.3 强化学习

有时候,标准答案是自己自我摸索,比如小孩学习走路:站起来,保持平衡,迈一条腿,再迈一跳腿,迈出一步,再迈一步,摔倒了重新再来。最终小孩子会在没有他人的教导之下,也能通过自我的反复的成功或失败的反馈中学会走路。
上述这个过程,在机器学习领域,有一个专业的名字叫“强化学习”。
第5部分. 机器是咋学习的?----机器的学习过程
5.1 学习内容:数据集
要学习,得先准备素材,大自然的一草一木,一花一草,每一种动物,人类创造的语言,文字,音乐,还有各种考试的试题等等,都是学习的素材。
不同的领域,如学金融与学计算机,是完全不同的学习素材。

工程师们也需要给给机器提供它们能够看到的、听到的、感知到的大量的素材,
这些素材,在机器学习领域,称它们为“数据集”。
而数据集中其中的一部分称为“样本”。
“数据集”决定了机器学成之后能做什么!这就是为什么在大数据时代中,数据的重要价值之一!!!甚至比神经网络的模型还重要!!!
5.2 学习教材:数据标注

上述的素材,对于没有受过任何教育的幼儿来讲,就是一堆没有任何意义的图形。因此除了素材,还得为素材定义标准答案:哪些数字是0,1,2,3,4,5,7,8,9? 上图中的动物是叫猫还是狗?74-3是等于多少?有了这些标准答案,人类的文明才能代代相传。
在机器学习领域,上述素材的标准答案,科学家们称之为“数据标注”。
定义这些这些标准答案的过程,称为“打标签”。
5.3 教学对象:机器的学习模型

同样是学习,鹦鹉、大猩猩、人类的学习能力是不相同的;
同样是人类,不同的人的学习能力也有所不同,有些人是学霸,有些人就是天才,有些人学渣。
对机器的学习而言,也是如此。
不同机器的学习能力,取决于人工智能的科学家和工程师们,给不同的机器的学习建立的数学模型。不同的数学模型,用于学习的不同内容,学习的能力也不同。
一开始,这样的数学模型,使得机器的学习能力只能达到鹦鹉和大猩猩的水平,这类数学模型被称为“传统的机器学习”。
后来,有人就想,人类之所以这么聪明,是因为有强大的由一个个神经元组成的大脑神经网络,为啥不用数学模型来模拟人的神经网络呢?
几十年前,还真的还有人这么干了,只可惜,那时候,(1)人类对自身的大脑了解还不够充分,(2) 要让机器运行神经网络的模型,需要机器有大量的运算速度. (3) 一开始,没有完善的数学算法,因此最初很长一段时间,用神经网络模型搞成的机器,连鹦鹉和大猩猩的学习能力都达不到,自然输给了“传统的机器学习”。
不过人类本身的学习能力远远胜于鹦鹉和大猩猩,这是一个真真切切不争的事实,说明这种神经网络本身是具有内在优势的。
随着科技的发展,神经网络的学习模型经过三落三起,最终发挥其优势,完胜传统的机器学习,成为现在机器学习领域的主流的方法。
大量的神经元,是按层组织的。

前期的人工神经网络只有几层,这样的网络模型被称为“浅层神经网络”。
随着人工神经网络层数增加,从数层到几十层,甚至上百层,称为“深层神经网络”。
为了区分浅层的人工神经网络,便取了一个更响亮的名字:“深度学习”。
之所以称为深度学习,一方面是因为神经网络的层数很深,更重要的是,随着神经元数目和层数的增加,机器能够学到更多的抽象的、深层次的特征信息,甚至是人类都无法表述的信息。这就是为甚人们戏称深度学习的神经网络模型是“老中医”。
5.4 开始教学---训练过程与训练数据集

所谓教学,一是老师“教”,而是学生“学”。
这一教一学的同一个过程,在机器学习领域,称为“训练”和“机器学习”。
“训练”是站在工程师角度,站在老师、家长的角度。
“机器学习”站在机器的角度,站在学生、学习者的角度。
既然是教学,就需要教材,前面提到的“素材”+ “标签”就是教材。
在“教与学”过程中使用的教材,机器学习领域称为:“训练数据集”。
5.5 学习效果的如何?---验证过程与验证数据集
如何检验教学的效果呢?中国的学生深有体会和经验了,那就是考试啊?
为了能考个高分,在正式考试前,学生需要进行各种自测考试和摸底考试。

在机器学习领域,
上述自测和摸底考试的过程,称为“验证”。
上述过程中用到的考试试题,称为“验证数据集”。
而考试得到的分数,称为”正确率”。
5.6 啥时候可以毕业?---测试与测试数据集
自测和摸底考试的分数达到自己预想的成绩之后,就可以参加正式的全球统一试题的考试了。当然,不同的科目,考试的试题是不太一样。

在机器学习领域,
这种正式的统一考试,称为“测试”。
这类考试用到的试题,称为“测试数据集”。
考试得到的分数,称为”正确率”,比如98%,就是98分。
只有考试的分数能够达到指定的目标,方能毕业或学成之后,被录取。
第6部分. 学成之后的状态:过拟合、欠拟合、拟合合适
检验学生学习好坏的最直接的方法就是考试,机器学习也一样。
分数决定一切!通过考试,把学生大致分成三种:
6.1 第一种是“学渣型”,考试不及格,不能毕业: “欠拟合”
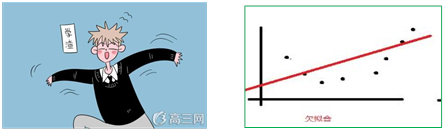
在机器学习领域,称这种机器学习为“欠拟合”。
6.2 第二种是“学霸型”,成绩理想,完成毕业:“拟合合适”
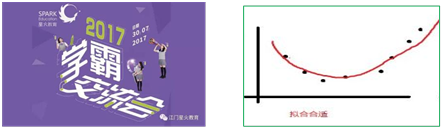
这种没啥好说,称为“拟合合适”。
6.3 第三种是“书呆子型”: “过拟合”
这种学生,模拟考成绩优异(验证数据集),正式考试分数总是不理想。这种学生过于机械、不够灵活、死记硬背学习教材和模拟试题答案。遇到灵活性的考试,如考题内容或形式一有变化,就答错题。
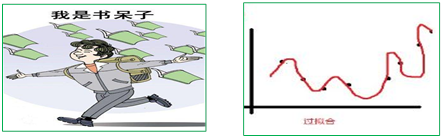
在机器学习领域,称这种机器学习为“过拟合”。
过拟合,就是考试得高分,应对实际能力就很差,就是所谓的“高分低能”。
第7部分. 机器学习与人类学习的区别?
7.1 机器学习不能学什么?当前的学习水平?
学成之后的,机器在某些特定的领域已经达到,甚至超过人类的水平,比如特定领域的语言识别、图像识别或下棋。

然而从综合学习能力和综合水平来看,目前的机器的学习能力和学成后的水平,与人类相比,还相差甚远,特别是在随机应变的能力方面。
7.2 素材或样本的量
人类只需要很少量的素材,就可以完成抽象的学习,比如一只猫,只需要几个猫的场景或图片,婴幼儿就能够识别出各个大小、形状、体态、颜色的猫。
然而,机器要做到这一点,往往需要学习几千张、几万张,甚至百万张的图片样本。
7.3 自然演进VS无限复制
人类个体,无论出生富贵与贫穷,要想自身的能力上超过别人,都需要自己不断刻苦的学习,父母给予的只是外部的条件:不同的学习素材、学习方法。因此每一个新生命的人类个体出生后都需要从头开始学习,无法对大脑进行思想的复制。
机器的强大优势在于,可以无限制的复制其他机器已经学得能力,不需要每台机器都从头开始训练和学习。这是机器相对于人的强大优势之一。
这个过程就是直接利用被人已经训练好的模型,做预测应用。
7.4 再学习能力
实际上,在人工智能的应用领域,大量的公司和工程技术人员都是在利用他人已经训练好的模型和参数,至多在别人训练好的模型和参数的基础之上进行再开发。
就像一张白纸的大学生进入第一家公司,经过自己几年辛辛苦苦的学习和公司的训练,成为公司的骨干和专家。后来跳槽到一家新公司,在新公司,只需要简单的学习,就成为这个新公司的专家。
机器学习领域,上述经过简单学习成为新公司专家的过程,称为“微调或Fine Tuning”
第8部分. 机器学习与人工智能
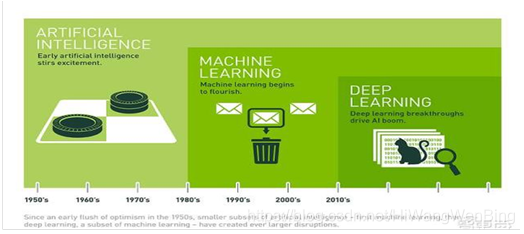
学习能力只是人类从外界获取信息,使得个体不断进化的最重要的手段。
丧失学习能力的人,依然是一个非常复杂的生物体,一样具备原先的智能,只是不能自我进化而已。
广义上讲,所有模拟人类智能的机器,都是可以成为人工智能,包括模拟人的思维的计算机、模拟人的记忆的计算机内存、模拟人五官的各种传感器都是人工智能。
而深度学习,也是只是机器学习的一种,是一种通过数学模型来模拟人类的神经系统来模拟人类学习的其中一种方法而已。
第9部分. 机器的学习水平
深度学习的技术突破,导致了人工智能的飞速发展,各大公司,无论是互联网行业的巨无霸,还是老牌的通信巨头,都在战略布局人工智能。未来会有大量的职业岗位会被人工智能所替代,然而从综合水平上看,即使具有了学习的机器,与人类的发展水平还相差甚远,如果硬性的与一个人的发展能力相比,可能也就达到是幼儿到儿童之间。

第10部分. 机器的前世、今生、来世?
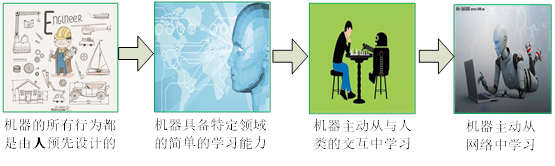

如果说,是上帝创造了整个宇宙,创造了人类,那么整个宇宙按照上帝最初定制的宇宙法则有条不紊的运行。
人类创造了机器,由机器构成计算机网络、互联网网络和物联网等虚拟世界,按照人类预先设计的方式在有条不紊的运行。终究有一天,会学习的机器也会思考“我们是从哪里来?到哪里去?”
至此,人类或许就成为了机器的心中的上帝。或是沦落为机器的生物电池?
作者主页(文火冰糖的硅基工坊):https://blog.csdn.net/HiWangWenBing
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/119191407
















 978
978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











