







 文章提出了一种新的分解方法DRF,通过解纠缠表示来融合可见光和红外图像。该方法依据成像原理分解图像信息来源,分别提取场景和传感器模态相关表示,然后采用不同策略融合这些表示,最后通过预训练的生成器生成融合图像。这种方法提高了融合的准确性和可解释性。
文章提出了一种新的分解方法DRF,通过解纠缠表示来融合可见光和红外图像。该方法依据成像原理分解图像信息来源,分别提取场景和传感器模态相关表示,然后采用不同策略融合这些表示,最后通过预训练的生成器生成融合图像。这种方法提高了融合的准确性和可解释性。
1.摘要
在这篇文章中,我们提出了一种新的分解方法,通过应用可见光和红外图像融合(DRF)的disentangled representation(解离化表示)。根据成像原理,我们根据可见光和红外图像的信息来源进行分解。更具体地说、 我们将图像分别通过相应的编码器分别将图像分解成与场景和传感器模态(属性)相关的表征。这样一来,由属性相关表示法所定义的独特信息就更接近于每一类传感器单独捕获的信息。因此,不适当地提取独特信息的问题可以得到缓解。然后,不同的策略被应用于这些不同类型表征的融合。最后,融合后的表征被送入预训练的生成器以生成融合的结果
注:解离化旨在对数据变化因素进行建模,是指将embedding拆分成不同维度,使得每一个维度可以代表一种语义。这样做一来可以增加可解释性,二来因为加了constraint而使模型更稳固。
2.引言
从源图像中提取特征的方法:
- 基于多尺度变换的方法:金字塔变换(将源图像分解为多尺度的空间频带),小波变换(将源图像分解为一系列高频和低频子图像);
- 基于稀疏表示的方法:不同类型源图像由相同的学习过完备字典及其各自的稀疏表示系数来进行稀疏表示;
- 低秩表示:从源图像中分解出低秩结构和显著成分。为了提取显著分量,学习并共享一个名为显著系数矩阵的投影矩阵,用于不同的源图像。
以上方法存在问题:即使源图像被分解为一系列部分,这些方法仍在这些分解的VIS和IR图像组件中使用相同的表示,而忽略了它们的不同模态。例如小波变换,相同频率的子图像就有相同的表示。(IR和VIS图像使用相同的表示是不合适的,会导致信息的冗余或失真。)
之前的融合方法中对VIS和IR都应用相同的表示,由于在红外图像中,高频信息表示不同物体和目标的边界,而在可见光图像中,高频信息表示大量的纹理信息,二者在融合后的图像中要保留的话,需要在高频这个尺度上进行融合,但这个过程必然会丢失其他信息,但如果加上其他尺度上的融合,可能存在这样的情况:红外图像和可见光图像的子图像都含有很少的信息,如果这样去保留信息必然会导致保留不太重要的信息。
为了解决上述问题,也有方法选择用手动方式描述或拆分每个源图像中的独特/唯一信息,比如利用**像素强度分布(pixel intensity distribution)来描述IR图像中的热辐射信息,利用梯度(gradients)**表征VIS图像中的反射光照信息。但这些并不能完全表征每个源图像的独特信息。(比如IR图像的梯度中也包含独特的热辐射信息)
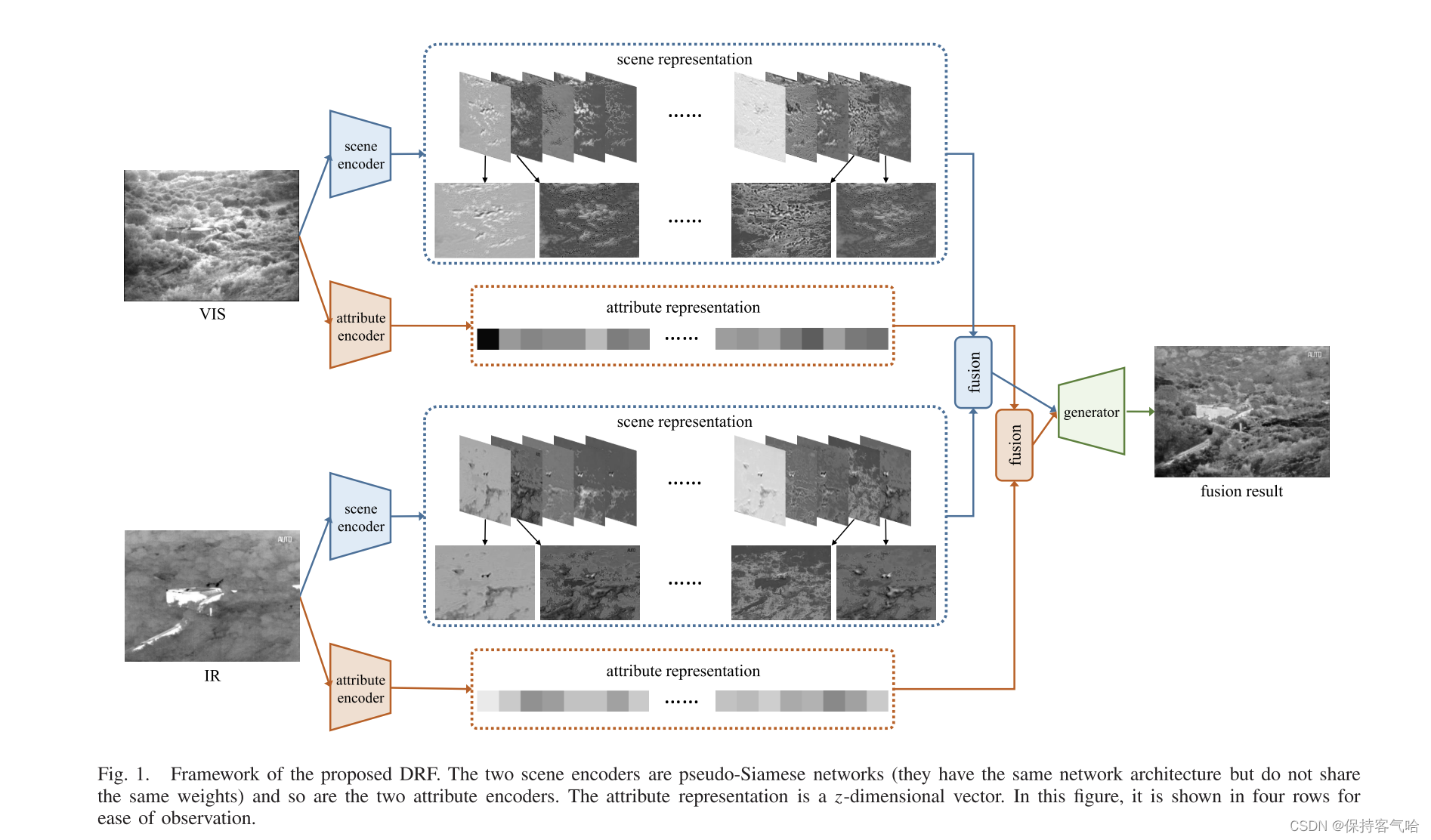
本文提出新的分解方法(DRF),目标是从源图像的成像过程出发,尽可能地从源图像中的公共信息中分离出独特信息。IR和VIS图像成像过程的异同点:相同点是同一场景拍摄,包含大量的信息;不同点是传感器使用特定的成像方式来捕获原始信息的一部分。IR和VIS图像以不同的表示呈现同一场景,包括梯度、对比度和光照度。因此,我们不是根据信息表示的形式(如频率、稀疏系数和显著成分(salient components))而是信息的来源进行分解。具体的说,将源图像分解为两部分:来自场景的信息(公共)和与传感器模态相关(独特)的信息。
在DRF中,我们应用disentangled表示法来分解源图像中的场景和属性表示。两种编码器,一个是scene encoder提取场景公共信息,一个是attribute encoder提取传感器属性信息。两个scene encoder构成伪暹罗网络(pseudo-Siamese),即有相同类型的网络结构但不共享权值。利用场景编码器提取场景表示作为公共信息,并且利用属性编码器提取属性表示作为唯一信息。
本文的贡献点是:
- 我们介绍了一种新的分解方法的图像融合。提出了一种新的观点,即源图像是由场景和传感器模态共同作用形成的。在此基础上,我们分解的源图像的信息来源,而不是在现有的基于分解的融合方法的信息表示形式。
- 从上述观点出发,我们引入了用于图像融合的分解表示。我们通过编码器将可视图像和红外图像分解为场景和属性相关的表示。然后,分别采用不同的策略对这些表征进行融合。最后,融合后的表征被送入一个预训练的生成器,以生成融合结果。因此,我们方法中的每个网络也有更好的可解释性。
3.方法
3.1 Disentangle Scene and Attribute Representations
给定一个VIS图像 x x x属于域 χ \chi χ和一个IR图像 y y y属于域 y \large y y,我们的目标就是把原图像分成一个共享域不变的场景空间和一个特定的属性空间,由于这个属性空间对于每个域是不同的,所以将域 χ \chi χ的属性空间表示为 A χ A_{\chi} Aχ以及域 y \large y y表示为 A y A_{\large y} Ay,IR和VIS图像对于场景信息的表示不同,所以对于 χ − > S \chi -> S χ−>S和 y − > S \large y ->S y−>S的映射不能以相同的方式实现,换句话也就是说不能用同样的函数/参数从源图像 x x x和 y y y中提取场景信息
所以我们设计了两个场景encoder { E χ s : χ − > S , E y s : y − > S \lbrace E^s_{\chi}:\chi ->S,E^s_y:y->S {
Eχs:χ−>S,Eys:y−>S,如下图2所示,两个encoder有相同的网络架构但没有相同的权重,此外由于两种模态差异很大,也设计了两个属性encoder { E χ a , E y a } \lbrace E^a_{\chi},E^a_y\rbrace {
Eχa,Eya}去学习 χ − > A χ a n d y − > A y \chi ->A_{\chi}\quad and\quad \large y ->A_y χ−>Aχandy−>Ay
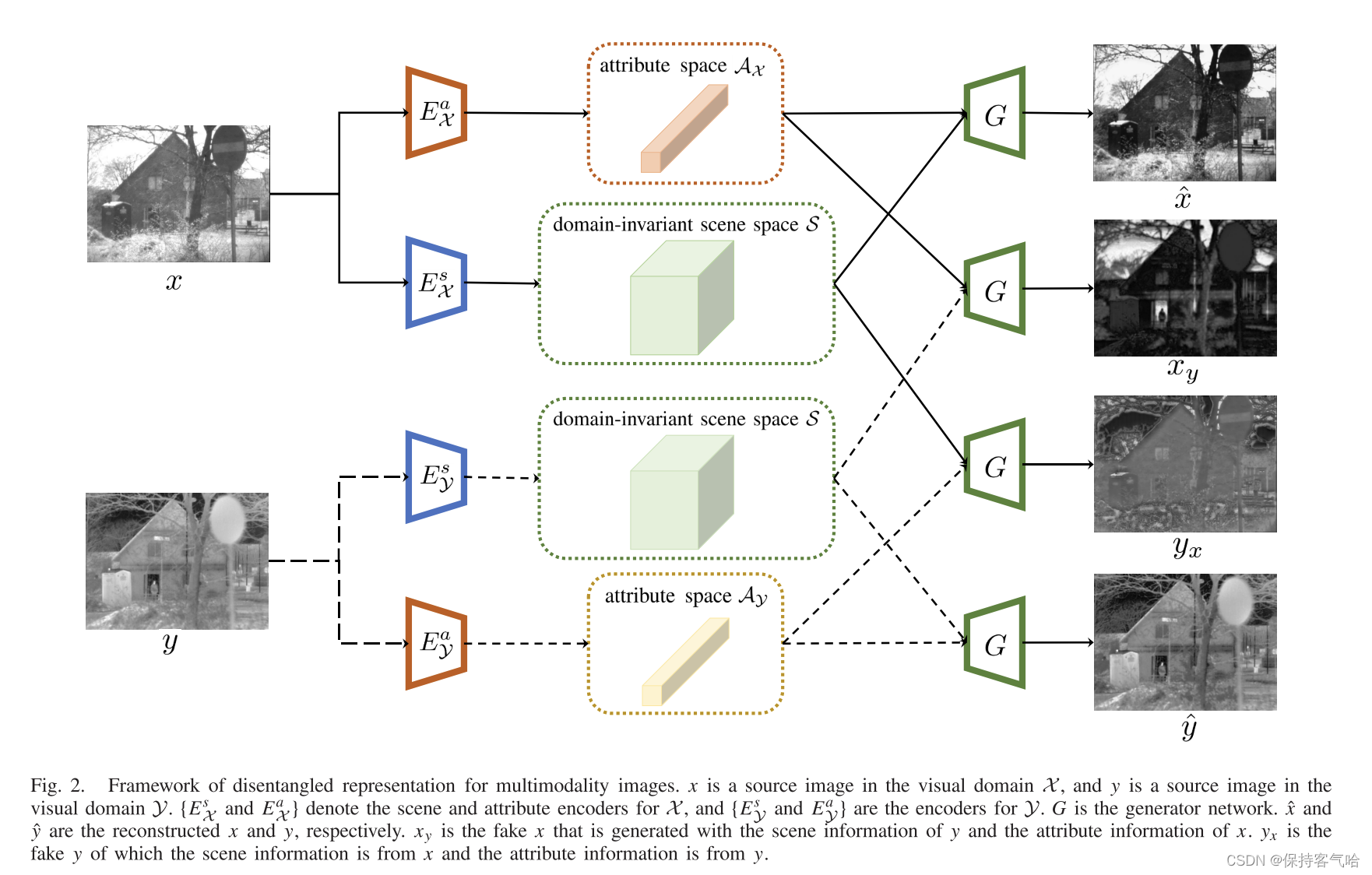
考虑到场景信息与空间和位置直接相关,场景表示以特征图的形式呈现,如图1所示,而属性与传感器模态相关,并且不期望携带场景信息。因此,向量的形式比特征图更适合于属性信息。对于源图像 x x x,场景特征 s x s_x sx和属性向量 a x a_x ax可以被编码为 { s x , a x } = { E χ s ( x ) , E χ a ( x ) } , s x ∈ S , a x ∈ A χ \lbrace s_x,a_x \rbrace = \lbrace E^s_{\chi}(x),E^a_{\chi}(x) \rbrace, \quad s_x\in S,a_x \in A_{\chi} {
sx,ax}={
Eχs(x),Eχa(x)},sx∈S,ax∈Aχ
同理,源图像y可以被表示为 { s y , a y } = { E y s ( y ) , E y a ( y ) } , s y ∈ S , a x ∈ A y \lbrace s_y,a_y \rbrace = \lbrace E^s_{y}(y),E^a_{y}(y) \rbrace,\quad s_y\in S,a_x \in A_{y} { sy,ay}={ Eys(y),Eya(y)},sy∈S,ax∈
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4133
4133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









