







 CompressAI是一个基于PyTorch的图像压缩库,它包含预训练模型和深度学习压缩算法。本文介绍了如何安装、训练模型、评估性能、编码和解码图像,以及与传统算法的比较。
CompressAI是一个基于PyTorch的图像压缩库,它包含预训练模型和深度学习压缩算法。本文介绍了如何安装、训练模型、评估性能、编码和解码图像,以及与传统算法的比较。
前言
CompressAI: a PyTorch library and evaluation platform forend-to-end compression research,我的理解是一个基于图像(视频)压缩的API库。他是建立在 PyTorch 之上的,用于基于深度学习的数据压缩的自定义操作、层和模型,其中包括了基于tensorflow.compression压缩包的部分移植,还包括包括一些用于压缩任务的预训练模型。其中可以直接用到的模型来自以下几篇文献:

- bmshj2018-factorized
Ballé J, Laparra V, Simoncelli E P. End-to-end optimized image compression[C]//ICLR 2017 - bmshj2018-hyperprior
Ballé J, Minnen D, Singh S, et al. Variational image compression with a scale hyperprior[C]//ICLR2018 - mbt2018-mean
Ballé J, Toderici G. Joint autoregressive and hierarchical priors for learned image compression[C]//NIPS 2018. - mbt2018
Minnen D, Ballé J, Toderici G. Joint autoregressive and hierarchical priors for learned image compression[C]//NIPS 2018. - cheng2020-anchor
Cheng Z, Sun H, Takeuchi M, et al. Learned Image Compression With Discretized Gaussian Mixture Likelihoods and Attention Modules[C]//CVPR 2020 - cheng2020-attn
Cheng Z, Sun H, Takeuchi M, et al. Learned Image Compression With Discretized Gaussian Mixture Likelihoods and Attention Modules[C]//CVPR 2020
注意: bmshj2018-factorized代码里使用的熵编码方法是Variational image compression with a scale hyperprior提出的全分解方法。官方的tensorflow库里也改了的。
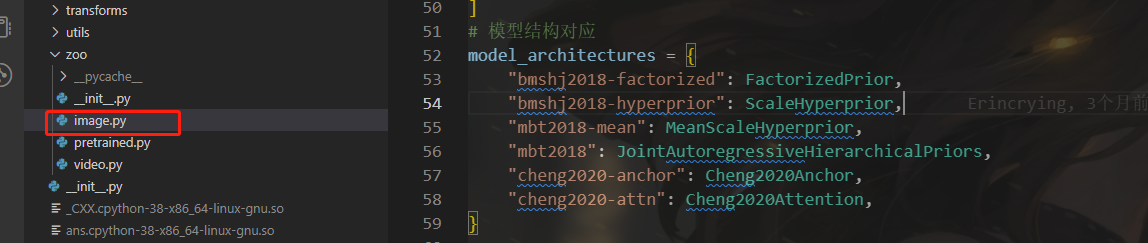
以上六篇论文在代码中对应关系如下
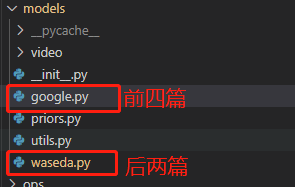
前四个位于google.py中,后两个位于waseda.py中
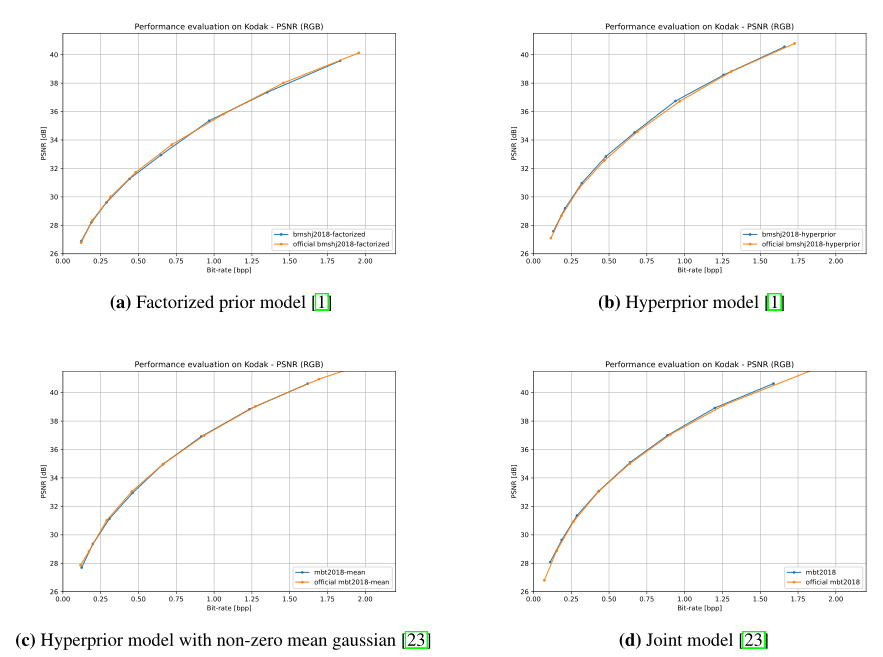
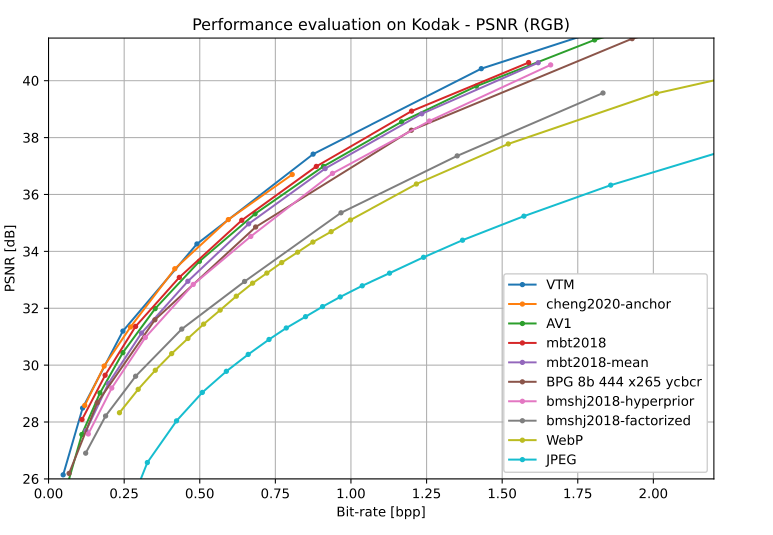
同时提供了与原作者实验对比的测试数据的性能值
并且可以与传统的算法比较效果
相关地址
github:github地址
compressAi简介:简介说明以及使用说明
环境安装
1、pytorch环境
整个项目基于pytorch环境,安装过程可以参考pytorch-gpu版本安装
2、compressai安装
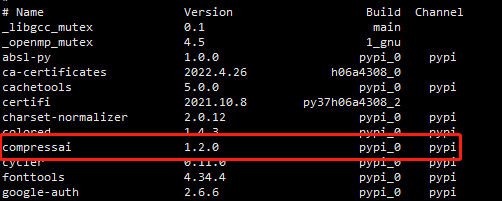
(1)普通版本
pip install compressai
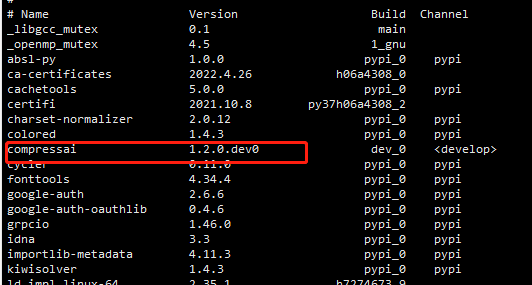
(2)开发版本
git clone https://github.com/InterDigitalInc/CompressAI compressai
cd compressai
pip install -U pip && pip install -e .
安装成功进行验证
python
import compressai
这样一来可以直接在对应环境中引入compressai进行调用
import compressai.models as models
1、总览文件结构
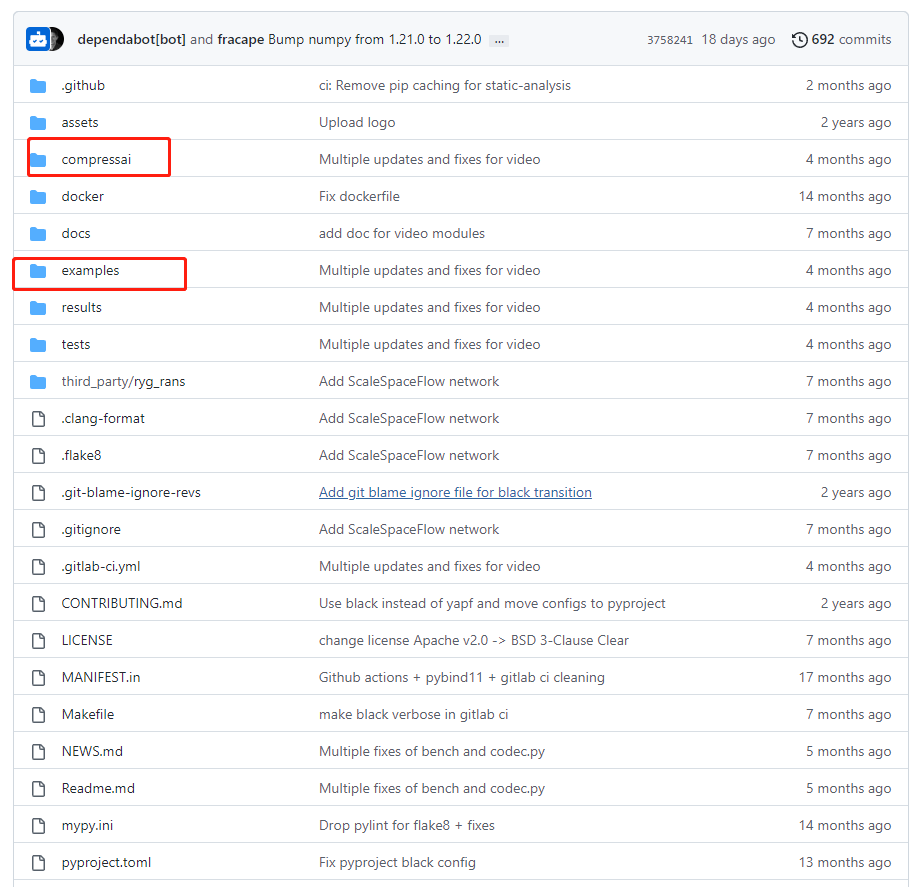
这里主要看compressai和example两个文件夹
1、compressai
封装了相关的api,其中models可以看到是封装的模型
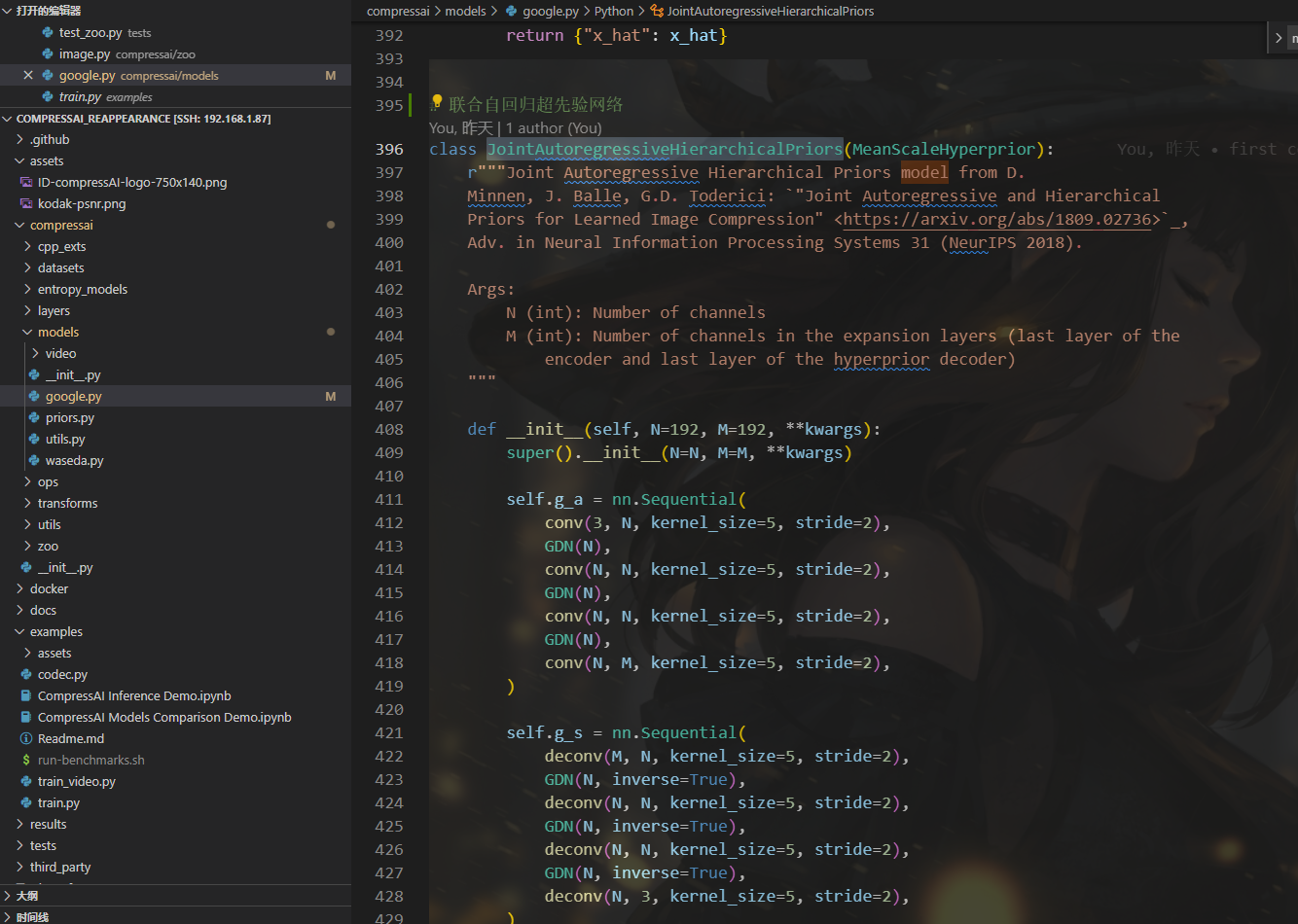
2、example
example下包含了一些代码使用的案例,还有train.py
我这里着重看了train.py,包含了我们设置的一些参数以及训练模型的主要流程,调用这个py文件通过命令的方式进行,在命令中设置数据集地址、训练参数等信息,调用此文件进行训练
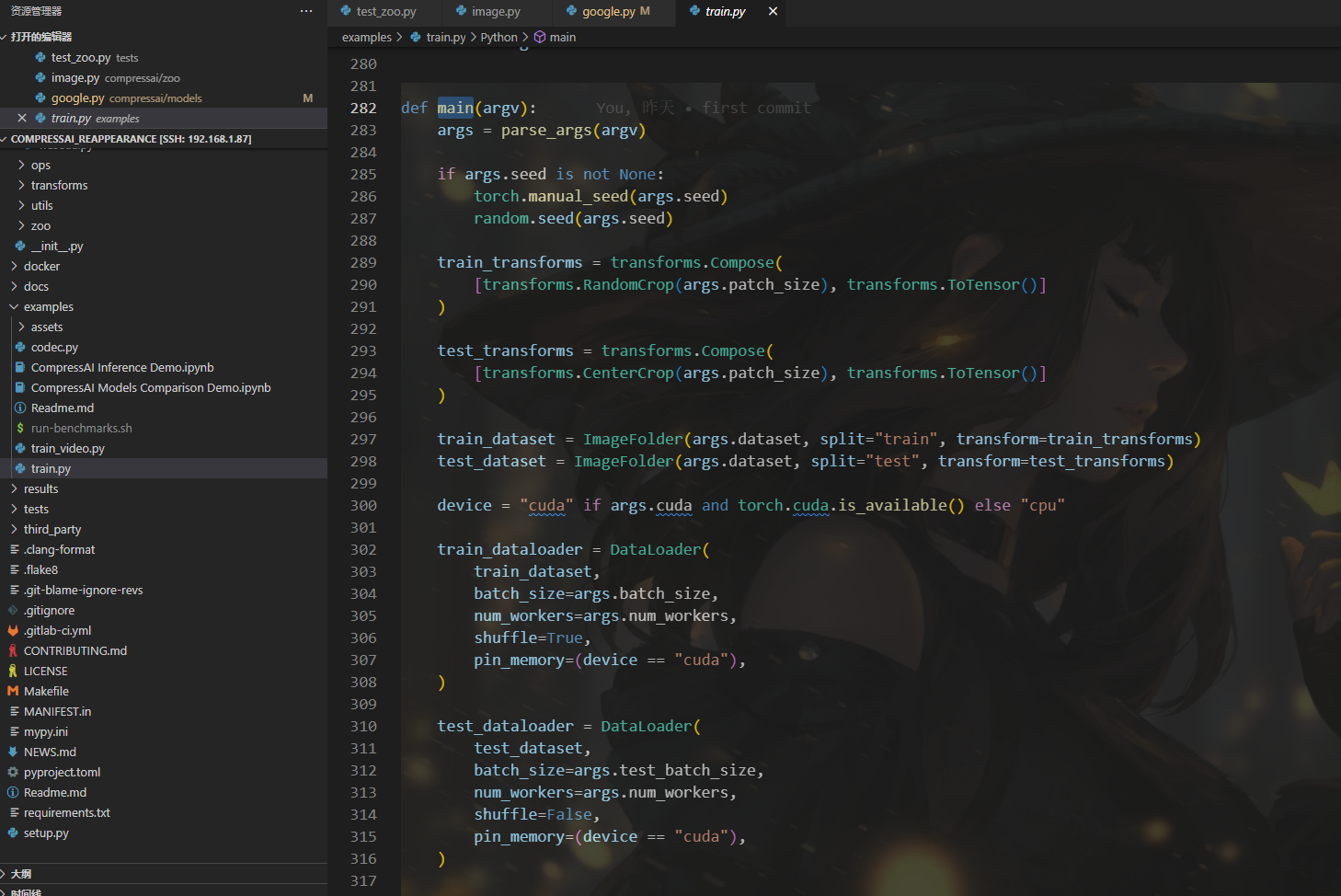
2、使用方法
1、准备数据集
首先我们要在特定文件夹下放好数据集,根据官方给的地址是/path/to/my/image/dataset/,我们这里采用我们存放数据集的地址,该数据集文件夹下分为了两个部分,一个train,一个test,这部分可以和train.py的代码中看到,根据字符串截取获取了对应数据集的文件

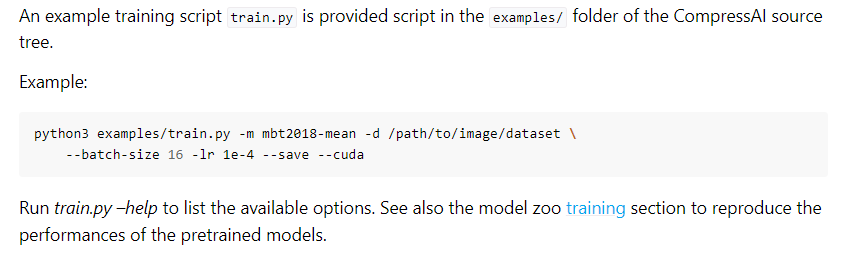
2、通过命令行进行调用train.py
官方给的命令是
python3 examples/train.py -d /path/to/my/image/dataset/ --epochs 300 -lr 1e-4 --batch-size 16 --cuda --save
相关命令说明在代码里有
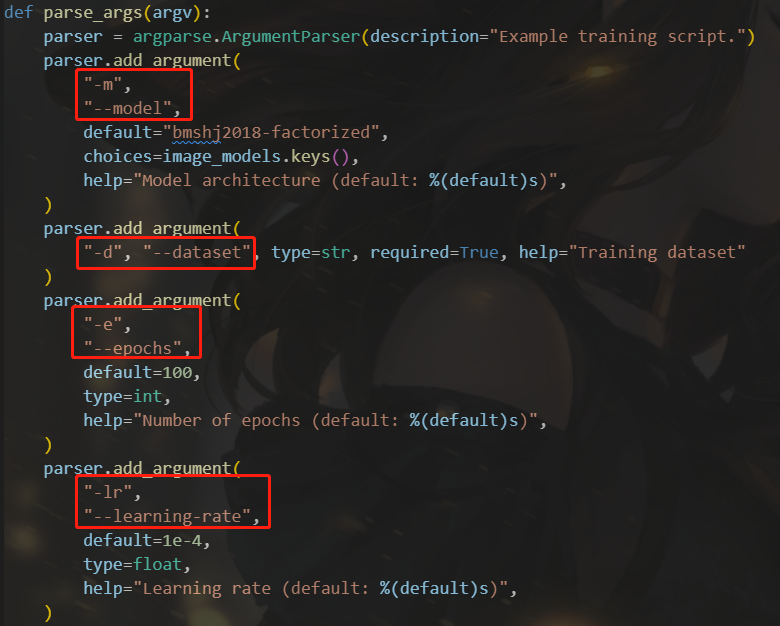
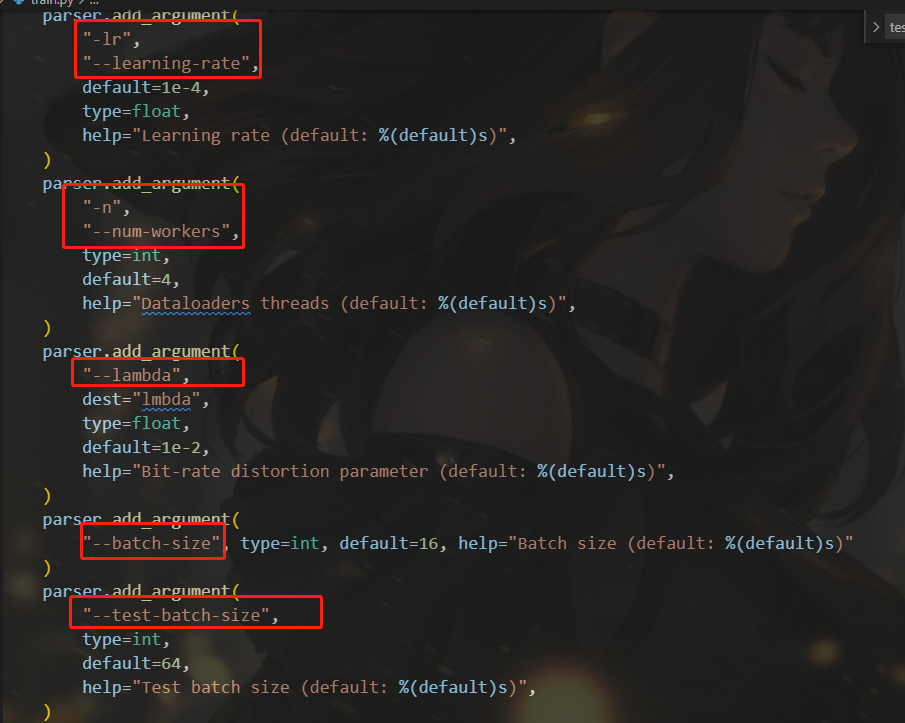
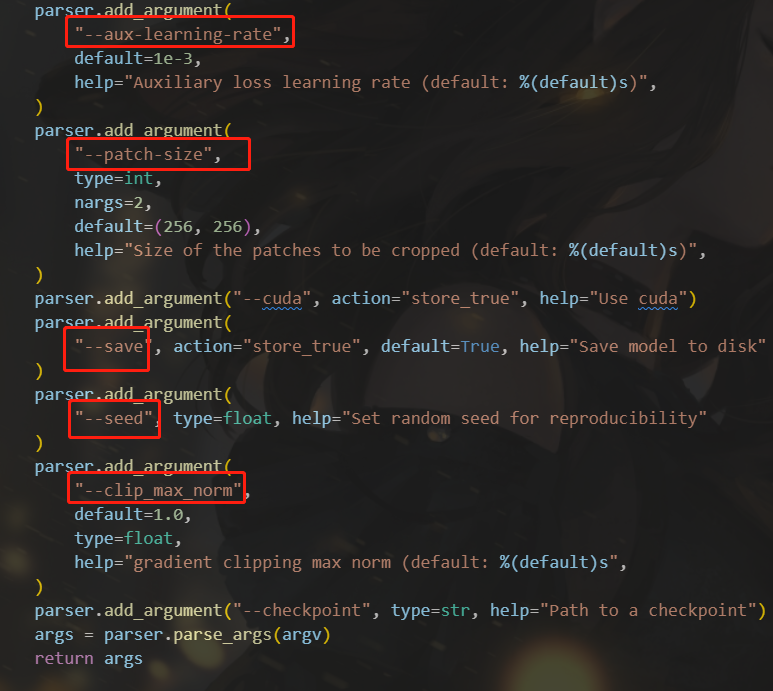
我们将根据我们需要的命令、数据集地址、调用的模型等参数进行修改
整理训练过程
- 加载训练命令,如上述图片的数据集、 e p o c h epoch
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









