







在pytorch中,数据加载可以通过自动逸的数据集对象来实现,数据集对象被抽象为Dataset类,实现自定义的数据集需要继承Dataset,并实现相应的方法。
下面针对给定任务进行重写Dataset类:
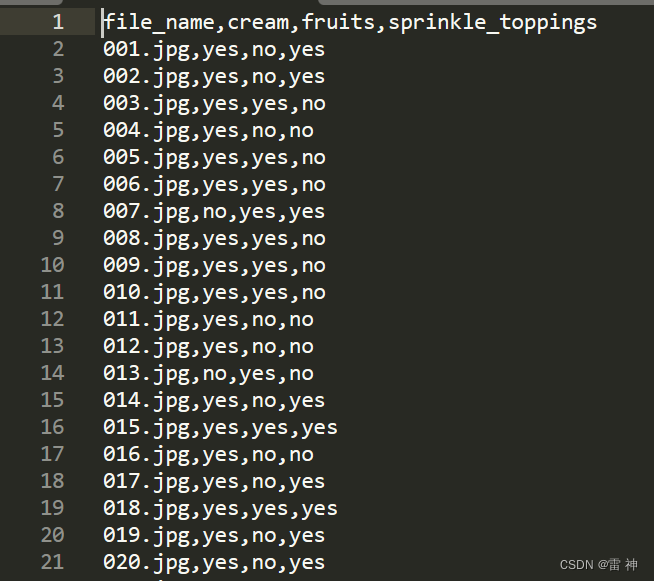
我们所有的图片都是在一个文件下,每个图像的标签含在一个csv文件中,所以不能利用Pytorch中的ImageFolder进行加载,所以需要自己重写DataSet类,实现读写数据。
重写DataSet类,需要重写3个方法:
- __init__:该方法主要就是一些参数初始化工作,定义一些路径或者变量什么的
- __getitem__:该方法是加载数据用的,用于读取每一条数据,他会有一个参数idx,就是对应的索引,从0开始,由于我们的图片是从001.jpg到280.jpg,所以可以利用这个索引依次读取文件夹中的所有图片,然后从标签csv中读取它对应的行拿到对应的标签,然后返回即可
- __len__:返回整个数据集的大小
# 加载数据集,自己重写DataSet类
class dataset(Dataset):
# image_dir为数据目录,label_file,为标签文件
def __init__(self, image_dir, label_file, transform=None):
self.image_dir = image_dir # 图像文件所在路径
self.label_file = pd.read_csv(label_file) # 图像对应的标签文件
self.transform = transform # 数据转换操作
# 加载每一项数据
def __getitem__(self, idx):
# 每个图片,其中idx为数据索引
img_name = os.path.join(self.image_dir, '%.3d.jpg' % (idx + 1)) # 加载每一张照片
image = Image.open(img_name)
# 对应标签
labels = (self.label_file[['cream', 'fruits', 'sprinkle_toppings']] == 'yes').astype(int).values[idx, :]
if self.transform:
image = self.transform(image)
# 返回一张照片,一个标签
return image, labels
# 数据集大小
def __len__(self):
return (len(self.label_file))
如果上面任务能够明白,其实Dataset类不局限于这么写,它可以实现多种数据读取方法,只需要把读取数据以及数据处理逻辑写在__getitem__方法中即可,然后将处理好后的数据以及标签返回即可。
















 1972
1972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











