







1. PSA
PSA是一种新型元启发式优化算法,发表于SCI1区期刊,在本代码中它主要用于初始化学习率和调整L2正则化超参数,以优化神经网络的训练效果。PSA的具体步骤包括计算参数的比例、积分和微分信息,从而确定合适的初始学习率和L2正则化系数。这种方法可以帮助在训练初期更有效地控制梯度更新的速度和模型的复杂度,有助于避免过拟合和提高模型的泛化能力。

2. CNN (Convolutional Neural Network)
卷积神经网络(CNN)在时序预测中通常用于从序列数据中提取局部特征。其基本结构包括卷积层、池化层和激活函数。在时序数据中,卷积层可以有效地捕获数据中的空间和时间特征,提取有意义的模式。对于多维时序数据(如多变量时间序列),CNN可以并行处理各个变量或特征的时间维度,从而提高特征提取的效率和准确性。
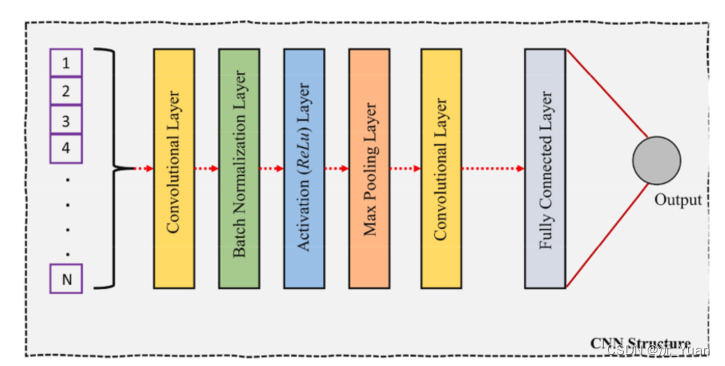
3. BiLSTM (Bidirectional Long Short-Term Memory)
双向长短期记忆网络(BiLSTM)是一种适用于时序数据的循环神经网络(RNN)变体。BiLSTM通过在每个时间步引入前向和后向的隐藏状态,能够更好地捕获序列数据中的长期依赖关系。传统的单向LSTM只能从过去到未来处理序列信息,而BiLSTM能够同时从过去和未来获取信息,因此更适合于对未来信息有较高依赖的时序预测任务。
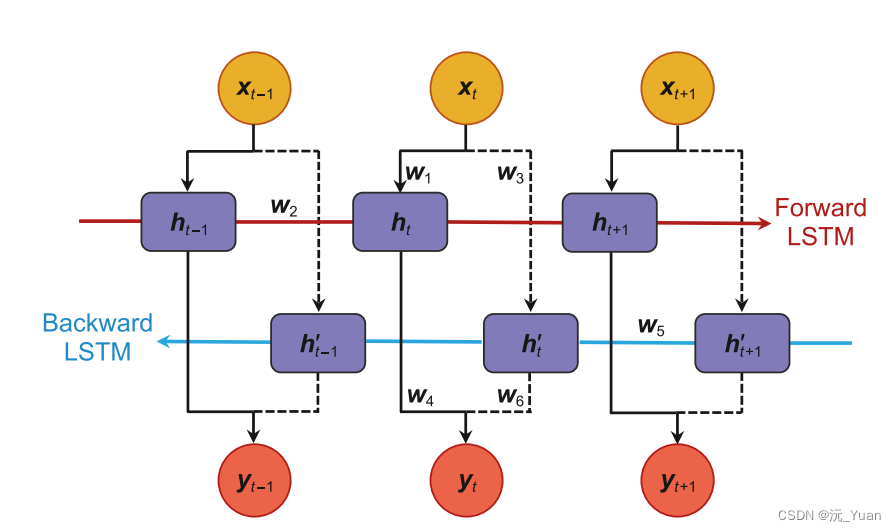
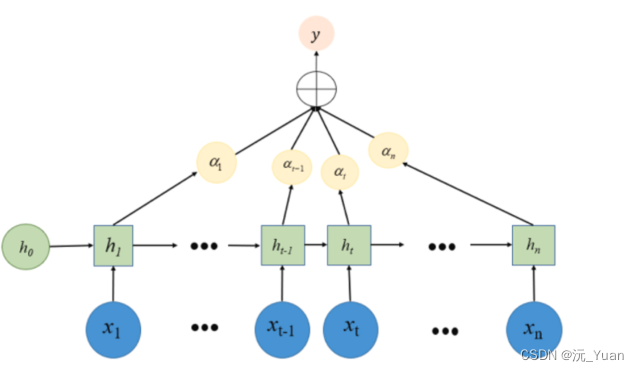
4. Attention Mechanism
注意力机制是一种用于增强神经网络对输入中特定部分关注程度的技术。在时序预测中,注意力机制可以帮助模型动态地学习序列中不同部分的重要性,并据此调整其预测。通过引入注意力机制,模型可以更有效地处理长序列和大量变量的时序数据,提升预测的精确度和鲁棒性。
结合PSA-CNN-BiLSTM-Attention混合神经网络
PSA-CNN-BiLSTM-Attention混合神经网络将以上几种技术结合在一起,形成一个更为强大和复杂的预测模型。在实际应用中,这种混合结构的优势在于:
特征提取能力增强:CNN能够有效地从序列数据中提取空间和时间特征,BiLSTM能够捕获长期依赖关系。
参数优化与调整:PSA优化算法有助于在训练初期调整学习率和正则化参数,提升模型的训练效率和泛化能力。
关注重点特征:通过Attention机制,模型可以动态地学习和调整对序列中不同部分的关注度,提升预测的准确性。
这种混合模型在多变量时序预测、时间序列分类和其他需要复杂模式识别的应用中表现出色,因其能够综合利用不同层次和类型的信息,提高模型对数据特征的理解和利用效率。
部分代码实现:
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
tic
rng('default');
%% 导入数据
res = xlsread('data.xlsx');
%% 数据分析
num_size = 0.7; % 训练集占数据集比例
outdim = 1; % 最后一列为输出
num_samples = size(res, 1); % 样本个数
%res = res(randperm(num_samples), :); % 打乱数据集(不希望打乱时,注释该行)
num_train_s = ceil(num_size * num_samples)+1; % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
bilstmnumber = 10;
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 数据平铺
% 将数据平铺成1维数据只是一种处理方式
% 也可以平铺成2维数据,以及3维数据,需要修改对应模型结构
% 但是应该始终和输入层数据结构保持一致
p_train = double(reshape(p_train, f_, 1, 1, M));
p_test = double(reshape(p_test , f_, 1, 1, N));
t_train = double(t_train)';
t_test = double(t_test )';
%% 数据格式转换
for i = 1 : M
Lp_train{i, 1} = p_train(:, :, 1, i);
end
for i = 1 : N
Lp_test{i, 1} = p_test( :, :, 1, i);
end
% %% 优化算法
% 参数设置
SearchAgents = 20; % 种群数量 25
Max_iterations = 20; % 迭代次数 80-150
lowerbound = [1e-5 1e-5]; %三个参数的下限
upperbound = [1e-1 1e-1]; %三个参数的上限
dim = 2; %数量,即要优化的BILSTM超参数个数
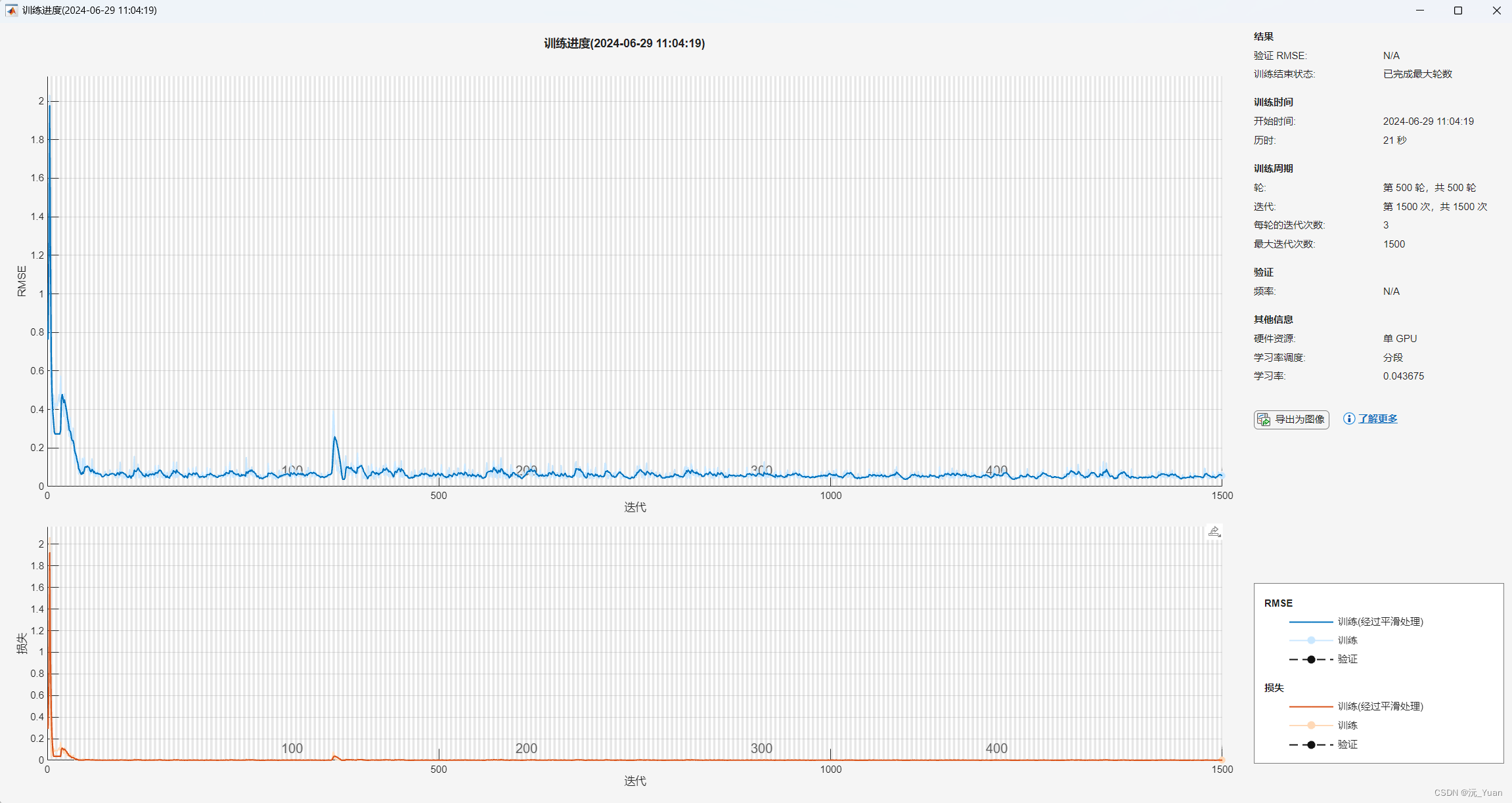
训练进度:
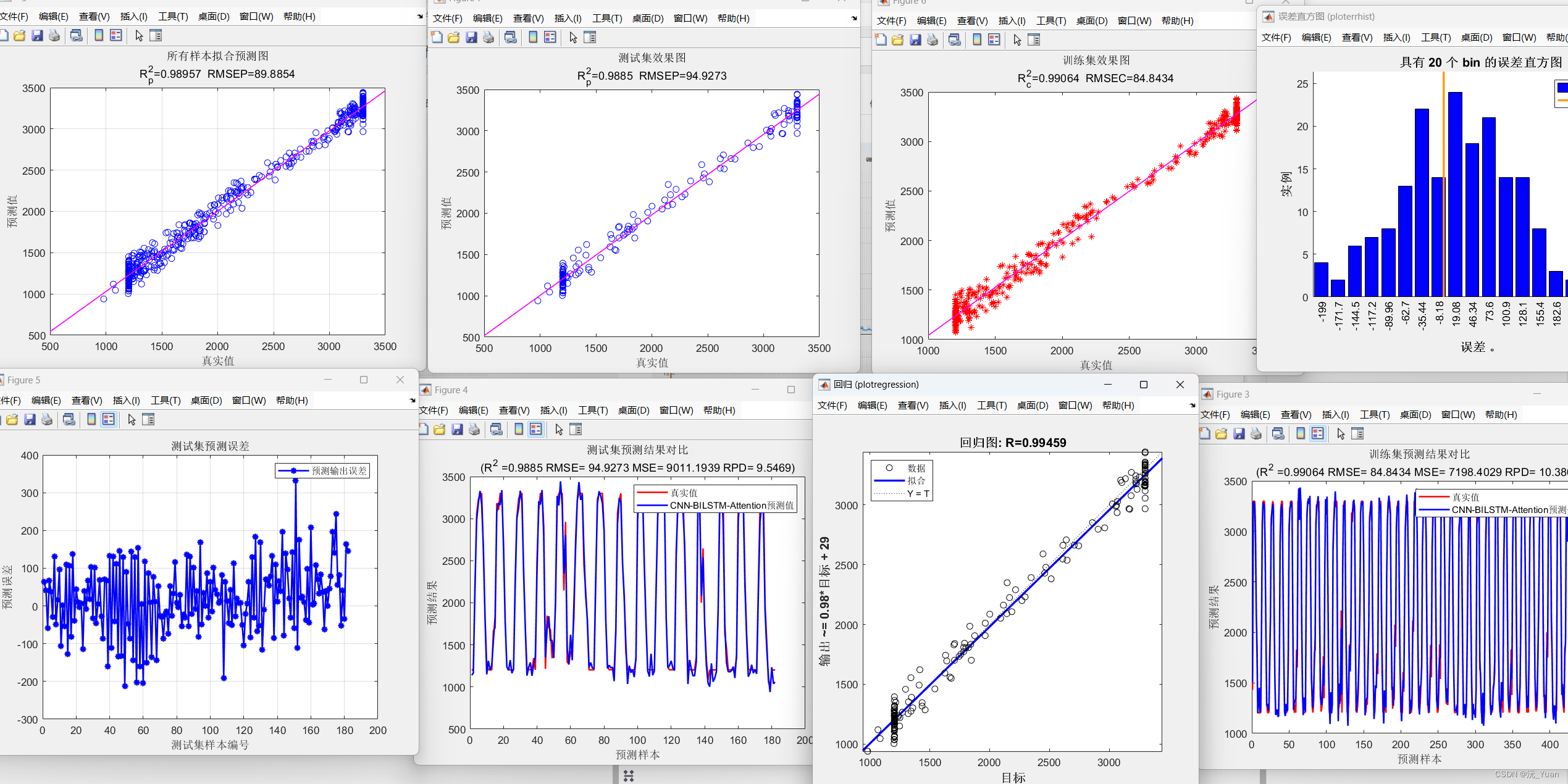
训练结果:
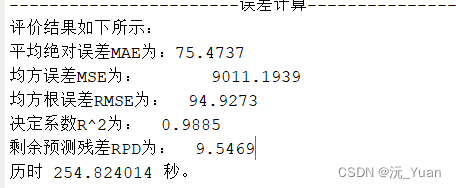
误差计算:

















 785
785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











