









【学习笔记】基于分解的多目标进化算法中带Bandits的自适应算子选择——MOEA/D-FRRMAB
算法概述
算法提出初衷: 在进化算法(EA)中,算法的性能很大程度的取决于参数的设置,而操作算子也可以视为EA中的一个参数。自适应算子选择(AOS)用于根据不同算子在优化过程中的近期表现,在线确定其应用率。一般来说,在单目标进化算法中,经常用到AOS操作,因为在大多数基于Pareto优势的多目标进化算法中,很难定量地度量适应度的改进,因此在多目标进化计算中对AOS的研究还很少。于是本文便提出了一种基于bandit的AOS方法,将其与MOEA/D算法框架结合,成功的将AOS操作应用到多目标的框架中。
相关知识
AOS方法基本任务:
- 【信誉分配】根据算子最近在搜索过程中的表现决定为其分配多少奖励(即下文提到的信誉值)
- 【算子选择】根据当前的奖励值决定下一个时间节点算法应该使用的算子
AOS的两项主要任务背后其实是EVE困境的一种体现,与EVE的思想紧密关联;
EVE困境
我们希望给有较好表现的算子更多机会(开发),但也希望在未来的搜索(探索)中探索较差的算子,因为操作算子可能在不同的搜索阶段执行显著不同的操作,或者说不同的算子适合不同的开发阶段。
multiarmed bandit (MAB) problem
MAB问题在本文中也多次提到,关于MAB(多臂老虎机问题),可以访问多臂老虎机(Multi-armed bandit problem),解决MAB问题常用的是UCB方法。
参数调整方法
参数调整:基于从多次运行中提取的统计信息以脱机方式设置参数,并提供可用于解决新实例的固定参数设置。
- 确定性方法,它根据一些预定义的问题特定规则调整参数。
- 自适应方法,通过在候选解的基因型中编码参数值,使参数值自行演化。
- 自适应或基于反馈的方法,该方法根据从先前搜索步骤接收到的反馈调整参数值
FRRMAB——算法框架
信誉分配
信誉分配最关键的部分,是衡量算子的指标,你怎样确定一个算子的好坏,并为它分配信誉。
- 如何衡量算子在应用过程中造成的影响
- 如何根据测量的影响为其分配适合的信誉值
对于1,最常用的衡量算子质量的指标是,与给定的基线解决方案相比,通过新解决方案获得的适应度改进。比如当前种群的最优解作为基线,亦或者是父代个体作为基线。
本文所使用的方法为 直接使用因被评估操作算子最近使用而导致的适应度改进的原始值。但是这样会有一个问题: 原始适应度改进的范围因问题而异,甚至在优化过程的不同阶段也是如此。通常情况下,初始适应度改善值在早期阶段比后期阶段大得多。为了缓解这个问题,我们提出的方法使用适应度改进率(FIR)。
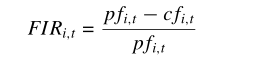
p代表父代,c代表子代;
本文使用了一个固定大小的滑动窗口用于存储最近使用的运算符的FIR值。它可以看作一个先进先出(FIFO)队列。使用滑动窗口的主要原因是,在动态AOS环境中,操作算子在非常早期阶段的性能可能与其当前性能无关。滑动窗口确保存储的FIR信息用于搜索的当前情况。滑动窗口的结构如下图:

op为算子的索引号,或者说是算子池中的某一个算子,FIR为算子的改进值;
为了能给最佳表现的算子更多的机会,削弱其他算子的影响,引入了衰减机制。
这个操作过程如下:
-
首先计算Rewardi ,Rewardi为滑动窗口中算子i的所有FIR值之和
-
对Rewardi 进行降序排序,并分配Rank
-
第一名rank为1,以此类推。
-
将Rewardi 转换为Decayi;根据以下公式:
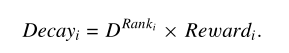
其中D~[0,1],为衰减因子,Drank 代表的是D的rank次方,第一名就是D1,以此类推。 -
计算信誉值FRR。
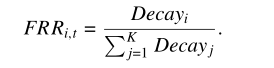
可以看出, D值越小,对最佳算子的影响越大。这里有一组不同D值,所取得的Drank ,其中rank为15个等级。

信誉分配伪代码如下:

算子选择
本文使用的是传统MAB问题中常使用的UCB算法的变体,也就是本文提出的一种基于Bandit的方法。
传统的UCB方法使用的是以下公式:
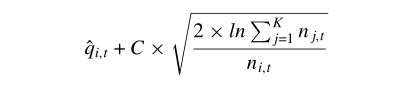
UCB方法的具体步骤就是:
- 为每一个老虎机(臂、算子)分配以上公式的一个值
- 选择出最大值的那个 老虎机(臂、算子)作为接下来使用的老虎机(臂、算子)
其中,qi,t这项代表的是一个经验质量值,ni代表的是最近过程中第i个算子所被选中的次数
与传统的UCB方法不同的是,基于bandit的方法将 qi,t用FRRi值代替了。
UCB方法能够提供渐进最优的保证。
另外,值得注意的是,在搜索开始时尚未应用任何算子;因此,在这种情况下,我们给每个算子一个平等的选择机会。在每个算子至少应用一次之前,不得使用FRRMAB。
算子选择伪代码如下

MOEA/D-FRRMAB算法伪代码
MOEA/D-FRRMAB为FRRMAB和算法MOEA/D-DRA 的结合。
由于在运行过程中,一个新解需要在邻域范围内进行替换,因此不像单目标,一个新解可能会替换多个解,因此其适应度改进率为替换了所有的解的改进率之和。文章最后提到 的奖励值: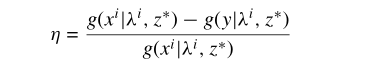
就是一个新解替换某个父代解的改进率。
文章中算子池使用了四个DE算子,即

前两个算子变异完之后需交叉,后两个不用,另外产生的实验解需要进行多项式变异(以一定概率)。
















 1581
1581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









