






 文章讨论了如何处理输入为一系列不同长度向量的问题,如文本、声音、图像等,介绍了自注意力机制、多头自注意力以及位置编码在解决这个问题中的作用。重点提到Transformer、BERT和图像领域的应用,同时对比了CNN和自注意力处理多输入的区别。
文章讨论了如何处理输入为一系列不同长度向量的问题,如文本、声音、图像等,介绍了自注意力机制、多头自注意力以及位置编码在解决这个问题中的作用。重点提到Transformer、BERT和图像领域的应用,同时对比了CNN和自注意力处理多输入的区别。
要解决的问题:
以前输入的是一个向量,输出可能是一个类别一个数值。但是现在输入可能是一排向量,并且长度大小不一样,这样如何解决呢?比如文字处理、声音讯号、图、分子等输入的都是一堆向量(比如“我”这个用一个唯一特定的一维向量[1,0,0,0,......]表示,所以一个句子就是一堆向量),那么输出可能是一个输入向量对应于一个输出向量、输出可能是变为一个向量(比如声音讯号、分子等)、人工不能判断输出几个向量要让机器自己识别输入多少个向量(比如翻译、语言辨识)
一、输入和输出一样多的情况(sequence labeling)
每一个向量都进行全连接,但是对于文字处理的时候一个相同的词语却是有着不同的含义,这如何解决?这个时候就是想把一个句子的前后左右都串起来放到全连接,前后左右的大小是由window来决定的,如果window大太是不现实的,为了解决这个问题,self-attention出现了

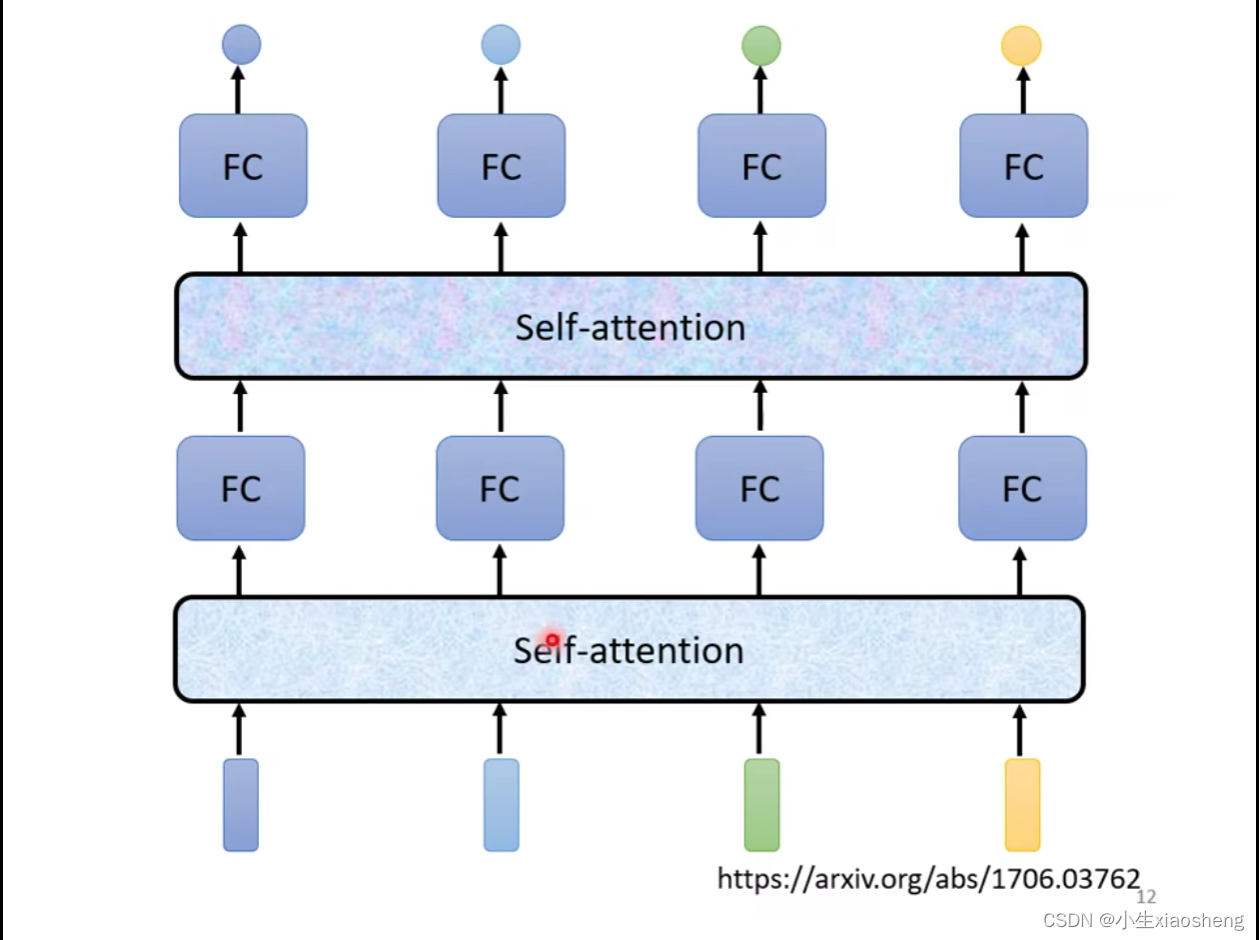
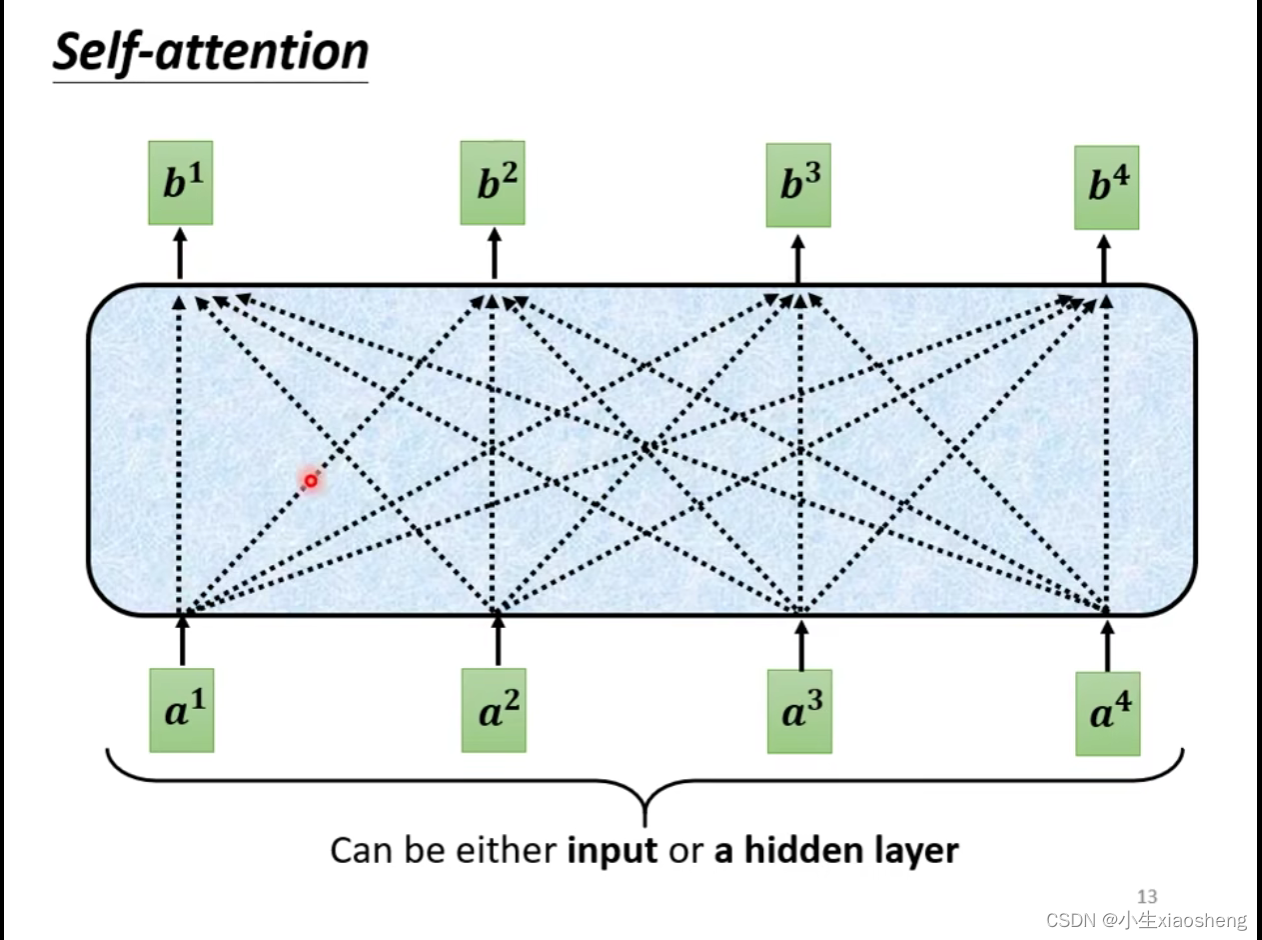
self-attention出现来解决window窗口大小的问题,self-attention里面会把所有的输入全考虑到然后再生成对应的一个向量,四个输入它会输出四个对应的向量,每一个输出的向量都是考虑到四个输入的向量。和
表示向量由激活函数得到,
是network的参数,实际上是被learn出来的

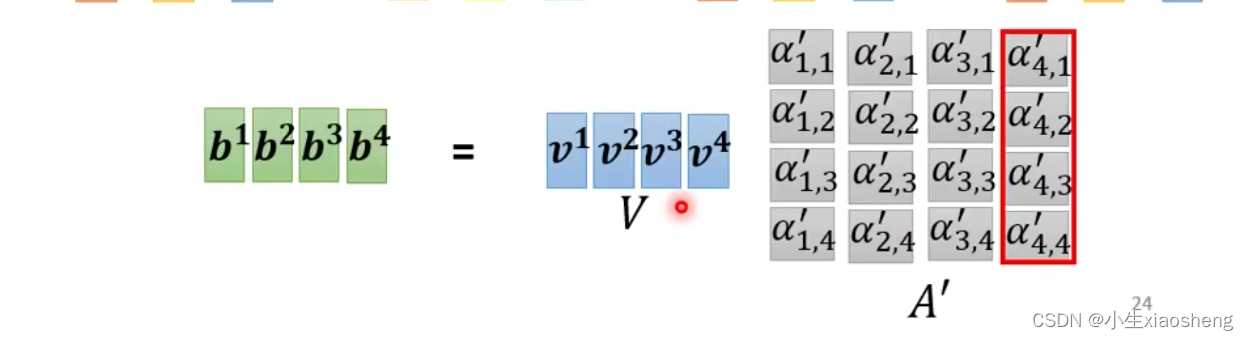
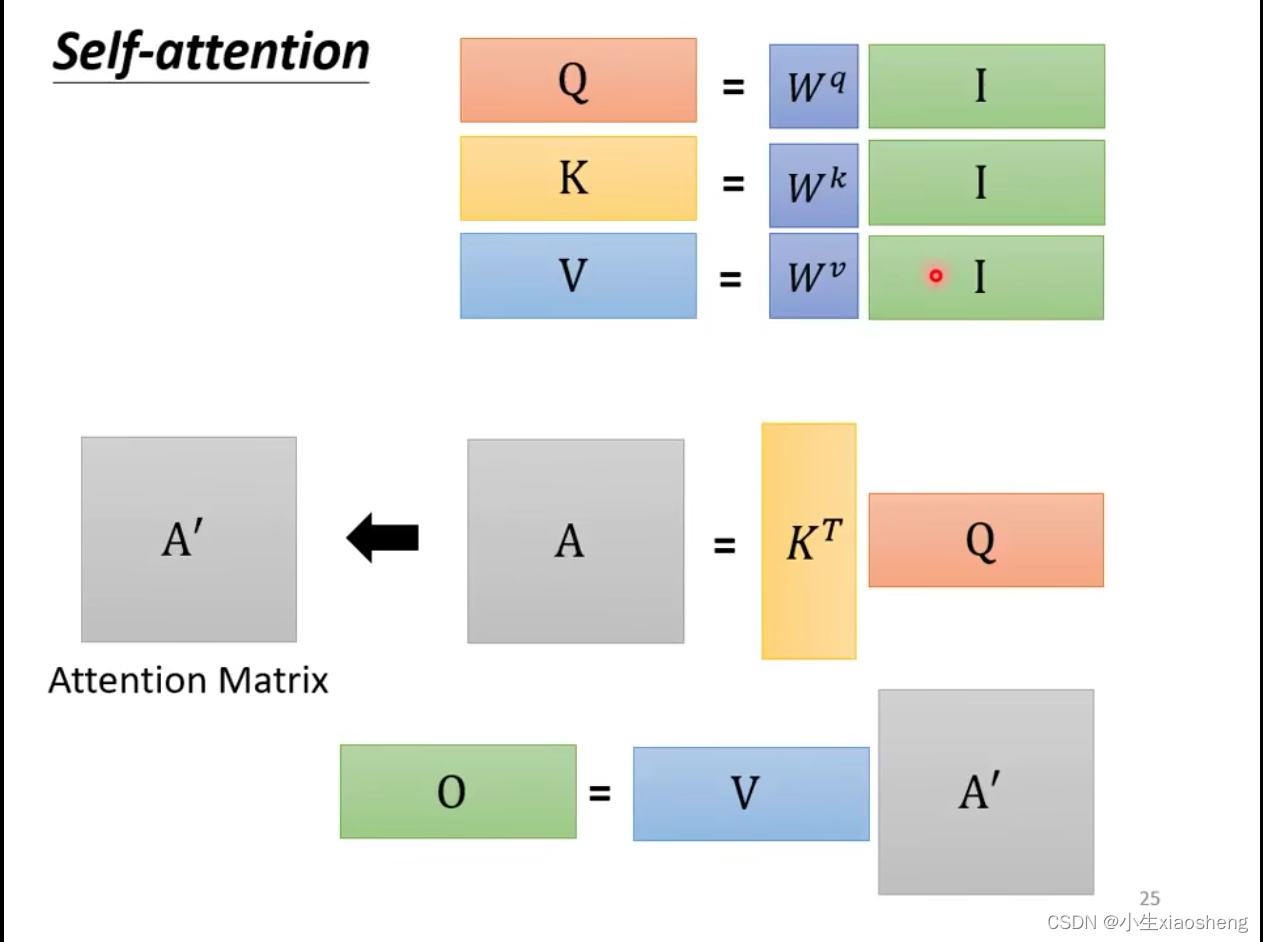
b¹如何得到---先找到与a¹所有相关的其他向量,关联程度用α(数值)1表示,α如何求?一个方法是dot-product。qkv一般是预先给定的,然后通过w训练进行改进,v¹表示重要程度,q¹和k¹是用来计算关联程度的。最后通过v¹和α相乘之后再相加就得到了b¹。softmax让所有相加为1


矩阵是如何计算出来的:唯一要学习的参数就是、
、
三个矩阵,输出就是b


进阶版的自注意力机制--多头自注意力机制multi-head self-attention。再乘以两个矩阵得到子
和
,1的下标只和1相关的进行运算


位置编码(positional encoding)--没有位置信息在自注意力机制上,为了解决这个问题,给每一个位置设置唯一位置向量,然后
+
来求得qkv。这个位置信息
是通过sin和cos来设置的,也可以是通过其他方法来实现。
自注意力机制运用到比较广的领域是:transformer、bert、speech、image(一个很长的向量,比如GAN、DETR就是把自注意力机制运用到图像上)、graph。
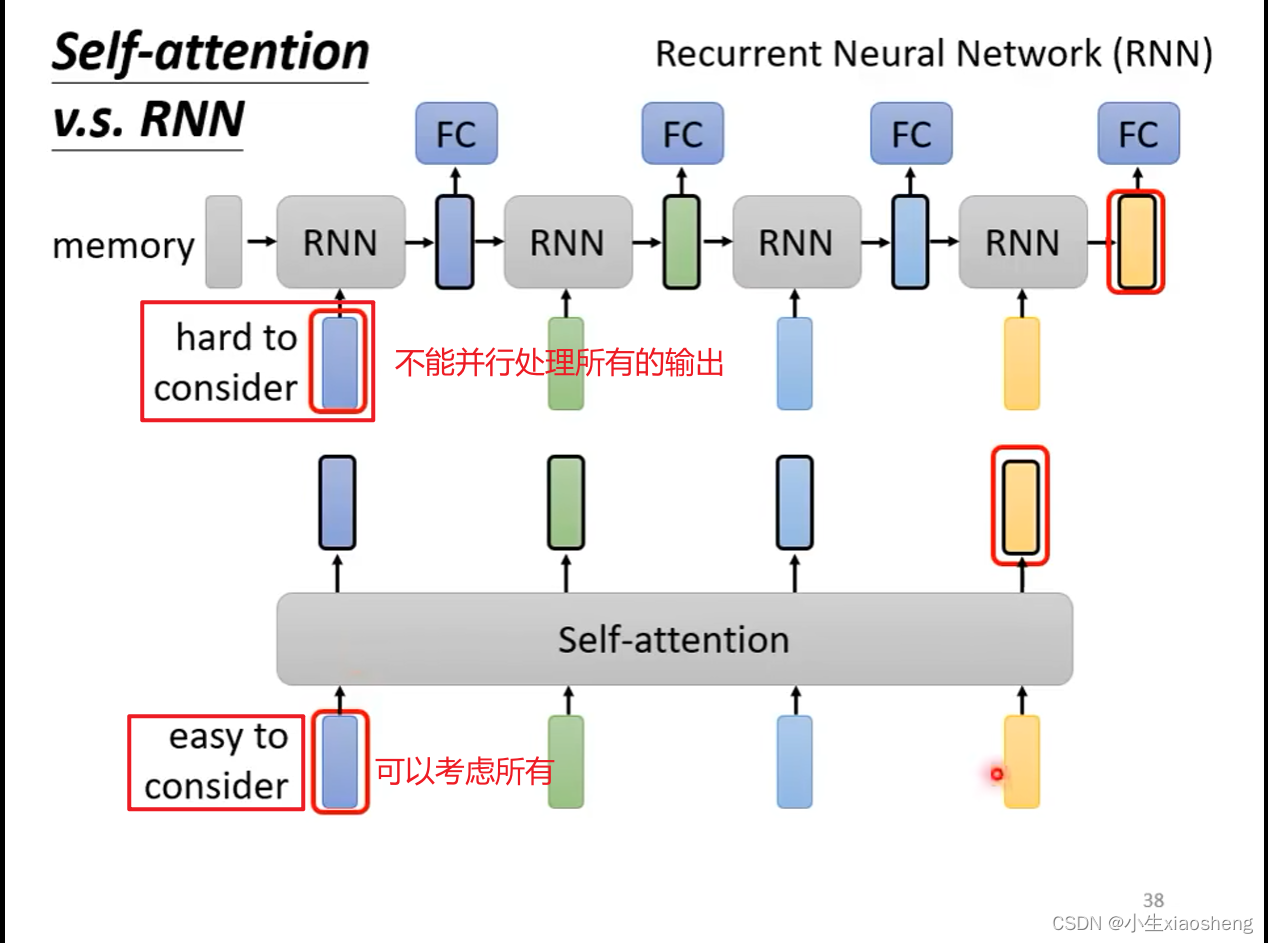
cnn和self-attention的区别 rnn(也要处理多个输入)和self-attention的区别



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









