






Task2: 精排模型
1. DeepFM
首先,CTR点击率预估,是一个二分类问题。
输入:user,Item,context
输出:该item被点击的概率或者是否被点击(取决于是否使用了sigmoid函数)
传统方法通常是LR+GBDT,但是其在特征选择和组合上性能较差,随后DNN被引入到该问题中,其在特征组合方面有着巨大的优势,同时,为了解决DNN参数量过大的问题,又引入了分而治之的field思想,利用全连接层生成dense vector来表示高阶特征组合。
FNN和PNN:FNN是使用预训练好的FM模块,得到隐向量,然后把隐向量作为DNN的输入,但是经过实验进一步发现,在Embedding layer和hidden layer1之间增加一个product层(如上图所示)可以提高模型的表现,所以提出了PNN,使用product layer替换FM预训练层。
Wide and Deep: FNN和PNN由于串行模式,仍然难以学习到低阶特征组合,于是WAD模型同时从串行和并行出发,解决该表示问题,但是由于在output Units阶段直接将低阶和高阶特征进行组合,很容易让模型最终偏向学习到低阶或者高阶的特征,而不能做到很好的结合。
DeepFM:
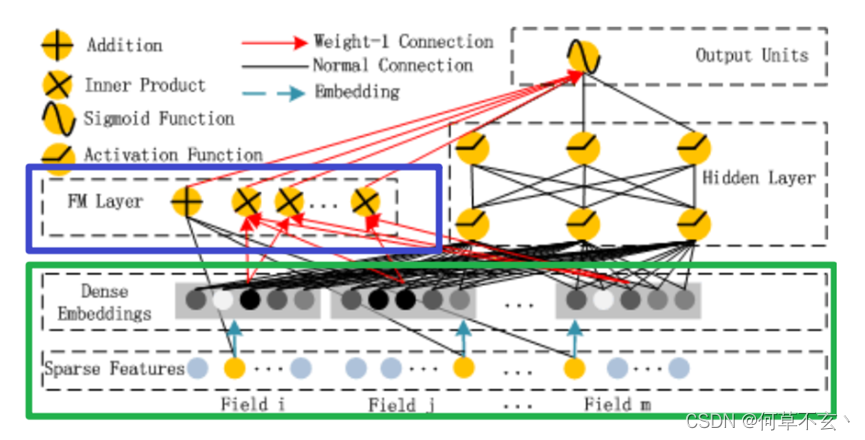
DeepFM将Wide部分替换为了FM layer,其中FM Layer是由一阶特征和二阶特征Concatenate到一起在经过一个Sigmoid得到logits
实现:
模型大致由两部分组成,一部分是FM,还有一部分就是DNN, 而FM又由一阶特征部分与二阶特征交叉部分组成,所以可以将整个模型拆成三部分,分别是一阶特征处理linear部分,二阶特征交叉FM以及DNN的高阶特征交叉。
def DeepFM(linear_feature_columns, dnn_feature_columns):
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
# linear_logits由两部分组成,分别是dense特征的logits和sparse特征的logits 分别是低阶特征组合和高阶特征
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
# embedding层用户构建FM交叉部分和DNN的输入部分
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
# 将输入到dnn中的所有sparse特征筛选出来
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
fm_logits = get_fm_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers) # 只考虑二阶项
# 将所有的Embedding都拼起来,一起输入到dnn中
dnn_logits = get_dnn_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)
# 将linear,FM,dnn的logits相加作为最终的logits
output_logits = Add()([linear_logits, fm_logits, dnn_logits])
# 这里的激活函数使用sigmoid
output_layers = Activation("sigmoid")(output_logits)
model = Model(input_layers, output_layers)
return model
2. DIN
DIN和DIEN都是阿里提出的时序推荐系统模型。其主要特点在于充分考虑历史的时序信息(即历史行为特征)对推荐系统的影响。
特征表示:工业上的CTR预测数据集一般都是multi-group categorial form的形式,就是类别型特征最为常见。常见的编码方式是multi-hot编码,而不是one-hot,因为用户可能购买了多个物体。
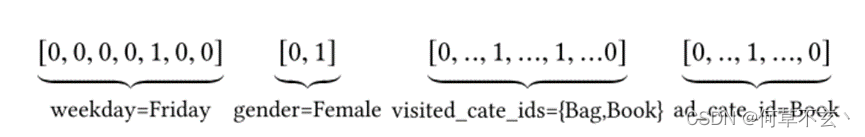
DIN利用了注意力机制。DIN通过给定一个候选广告,然后去注意与该广告相关的局部兴趣的表示来模拟此过程。 DIN不会通过使用同一向量来表达所有用户的不同兴趣,而是通过考虑历史行为的相关性来自适应地计算用户兴趣的表示向量(对于给的广告)。 该表示向量随不同广告而变化。
DIN的模型架构及实现
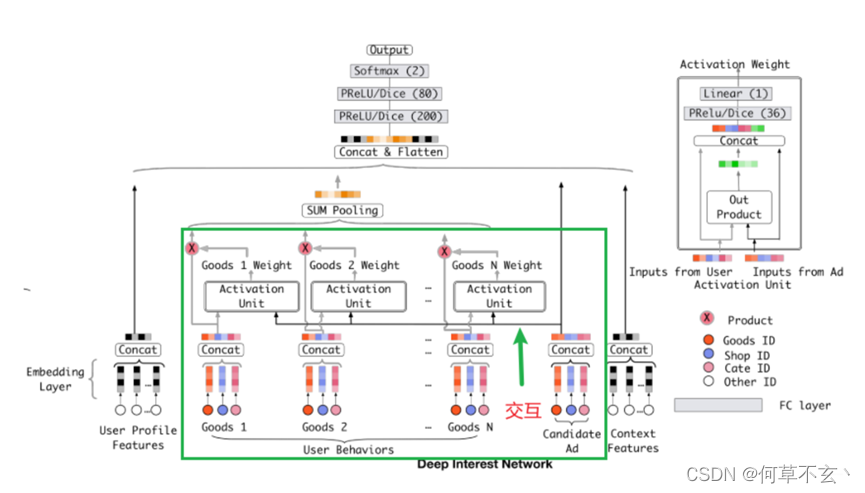
相比于base model, DIN加了一个local activation unit,其目的是计算历史行为和历史商品的注意力,把这个权重与原来的历史行为embedding相乘求和就得到了用户的兴趣表示:
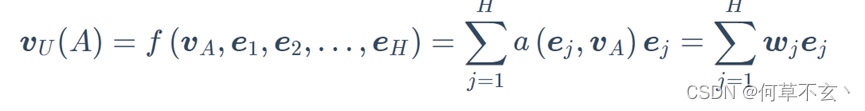
实现:DIN的实现代码最不同的一点是,存在了用户的历史行为数据(hist_behavior)
而这种历史行为是序列性质的特征, 并且不同的用户这种历史行为特征长度会不一样, 但是我们的神经网络是要求序列等长的,所以这种情况我们一般会按照最长的序列进行padding的操作(不够长的填0), 而到具体层上进行运算的时候,会用mask掩码的方式标记出这些填充的位置,好保证计算的准确性。
DIN模型的输入特征大致上分为了三类: Dense(连续型), Sparse(离散型), VarlenSparse(变长离散型),第三种就是历史行为特征。
与前面不同的是,在Sparse特征中,训练好的embedding还需要与用户行为特征作注意力机制的计算,得到最后特征。
# DIN网络搭建
def DIN(feature_columns, behavior_feature_list, behavior_seq_feature_list):
""" 这里搭建DIN网络,有了上面的各个模块,这里直接拼起来
:param feature_columns: A list. 里面的每个元素是namedtuple(元组的一种扩展类型,同时支持序号和属性名访问组件)类型,表示的是数据的特征封装版
:param behavior_feature_list: A list. 用户的候选行为列表
:param behavior_seq_feature_list: A list. 用户的历史行为列表
"""
# 构建Input层并将Input层转成列表作为模型的输入 input_layer_dict = build_input_layers(feature_columns) input_layers = list(input_layer_dict.values()) # 筛选出特征中的sparse和Dense特征, 后面要单独处理 sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), feature_columns)) # 获取Dense Input dnn_dense_input = [] for fc in dense_feature_columns: dnn_dense_input.append(input_layer_dict[fc.name]) # 将所有的dense特征拼接 dnn_dense_input = concat_input_list(dnn_dense_input) # (None, dense_fea_nums) # 构建embedding字典 embedding_layer_dict = build_embedding_layers(feature_columns, input_layer_dict) # 离散的这些特特征embedding之后,然后拼接,然后直接作为全连接层Dense的输入,所以需要进行Flatten dnn_sparse_embed_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=True) # 将所有的sparse特征embedding特征拼接 dnn_sparse_input = concat_input_list(dnn_sparse_embed_input) # (None, sparse_fea_nums*embed_dim) # 获取当前行为特征的embedding, 这里有可能有多个行为产生了行为列表,所以需要列表将其放在一起 query_embed_list = embedding_lookup(behavior_feature_list, input_layer_dict, embedding_layer_dict) # 获取历史行为的embedding, 这里有可能有多个行为产生了行为列表,所以需要列表将其放在一起 keys_embed_list = embedding_lookup(behavior_seq_feature_list, input_layer_dict, embedding_layer_dict) # 使用注意力机制将历史行为的序列池化,得到用户的兴趣 dnn_seq_input_list = [] for i in range(len(keys_embed_list)): seq_embed = AttentionPoolingLayer()([query_embed_list[i], keys_embed_list[i]]) # (None, embed_dim) dnn_seq_input_list.append(seq_embed) # 将多个行为序列的embedding进行拼接 dnn_seq_input = concat_input_list(dnn_seq_input_list) # (None, hist_len*embed_dim) # 将dense特征,sparse特征, 即通过注意力机制加权的序列特征拼接起来 dnn_input = Concatenate(axis=1)([dnn_dense_input, dnn_sparse_input, dnn_seq_input]) # (None, dense_fea_num+sparse_fea_nums*embed_dim+hist_len*embed_dim) # 获取最终的DNN的预测值 dnn_logits = get_dnn_logits(dnn_input, activation='prelu') model = Model(inputs=input_layers, outputs=dnn_logits) return model














 726
726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









