






1、结构风险最小化
我们想要在未知的数据上得到低的错误率,这叫做structural risk minimization;相对的,训练误差叫做empirical risk minimization
要是我们能有这样一个式子就好了:
Test error rate
<
=
train error rate
+
f
(
N
,
h
,
p
)
\text { Test error rate }<=\text { train error rate }+f(N, h, p)
Test error rate <= train error rate +f(N,h,p)
其中,
N
=
\mathrm{N}=
N= size of training set,
h
=
\mathrm{h}=
h= measure of the model complexity,
p
=
p=
p= the probability that this bound fails
我们需要一个 p p p来限制最差的测试集的情况。然后我们就能通过选择模型复杂度 h h h来最小化测试误差率的上界。
2、VC维(Vapnik-Chervonenkis dimension)
VC维就是衡量模型复杂度的一个重要概念
选择
n
n
n个样本点,我们随机的给它们分配标签,如果我们的模型都能将它们分开,则样本的VC维
>
=
n
>=n
>=n,我们不断地增大
n
n
n,直到模型不能分开为止。模型能分开的最大的
n
n
n值就是模型的VC维。
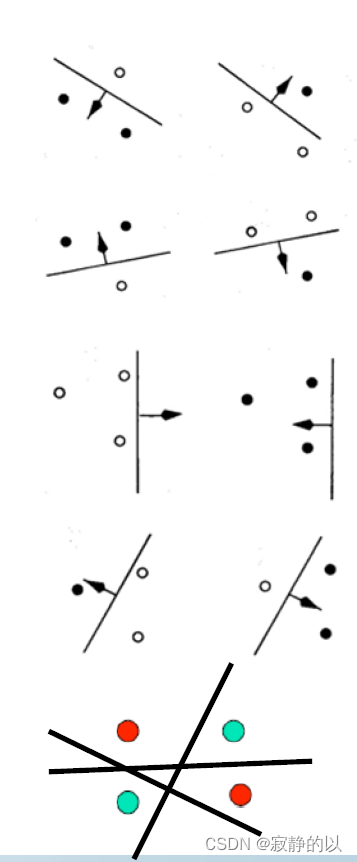
考虑一条二维空间的一条直线的复杂度。如上图所示,对于三个数据点,无论我们如何分配标签,直线都能很好的将样本正确分类。但是对于四个数据点,直线无法处理异或问题。因此,二维空间中一条直线的VC维是3.
二维空间中的超平面的VC维是3。更一般的,k维空间的超平面的VC维是k+1。
超平面的VC维与参数的数目相等。但这只是个巧合,事实上,模型的参数和模型的复杂度并没有必然的联系。例如,一个正弦曲线的VC维是正无穷大,但是它的参数只有3个。
f
(
x
)
=
a
sin
(
b
x
+
c
)
f(x)=a \sin (b x+c)
f(x)=asin(bx+c)

最近邻分类器的VC维是无穷大的,因为无论你有多少数据点,你都能在训练集上得到完美的分类器。而当 1-NN → K-NN \text { 1-NN } \rightarrow \text { K-NN } 1-NN → K-NN ,相当于减小了VC维。
一般来说,VC维越高,模型的分类能力更强,更flexible。但是VC维更多的是作为一个概念,实际上很难去计算一个模型的VC维。
回到刚才,经过前人推导,我们得到了一个测试集误差的上界如下:
E
test
≤
E
train
+
(
h
+
h
log
(
2
N
/
h
)
−
log
(
p
/
4
)
N
)
1
2
E_{\text {test }} \leq E_{\text {train }}+\left(\frac{h+h \log (2 N / h)-\log (p / 4)}{N}\right)^{\frac{1}{2}}
Etest ≤Etrain +(Nh+hlog(2N/h)−log(p/4))21
N
=
\mathrm{N}=
N= size of training set
h
=
V
C
h=V C
h=VC dimension of the model class
p
=
p=
p= upper bound on probability that this bound fails
从上式看,
Good generalization
→
large
N
and small
h
\text { Good generalization } \rightarrow \text { large } N \text { and small } h
Good generalization → large N and small h
这是符合我们的直觉的。上面这个式子的推导很复杂,但是在实际中也没啥用,因为它给的上界太松了,一个很松的上界又有什么意义呢。
3、Hard-Margin SVM

对于上面这个两类分类问题,我们用直线进行分类,会发现有好多种分类方法。而SVM所选择的那条直线,是将Margin 最大化的直线。
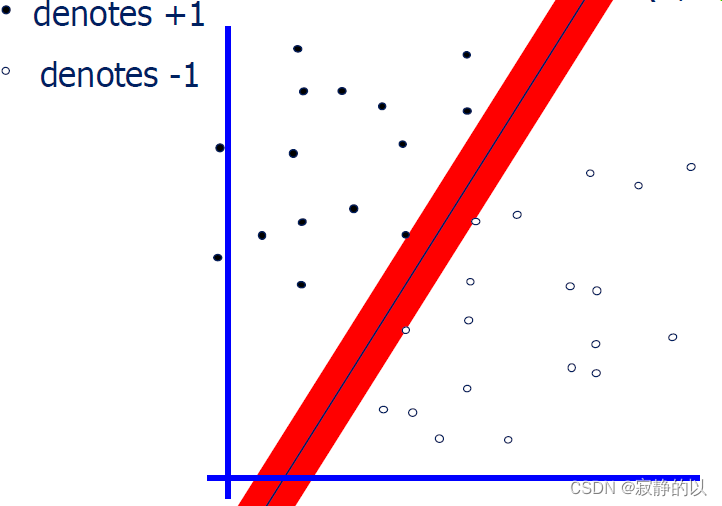
为什么要最大化Margin?
- 直觉上感觉这最安全
- 实际工作中确实不错
- 当数据有小波动时错分的概率小一些
- 模型只与support vector有关
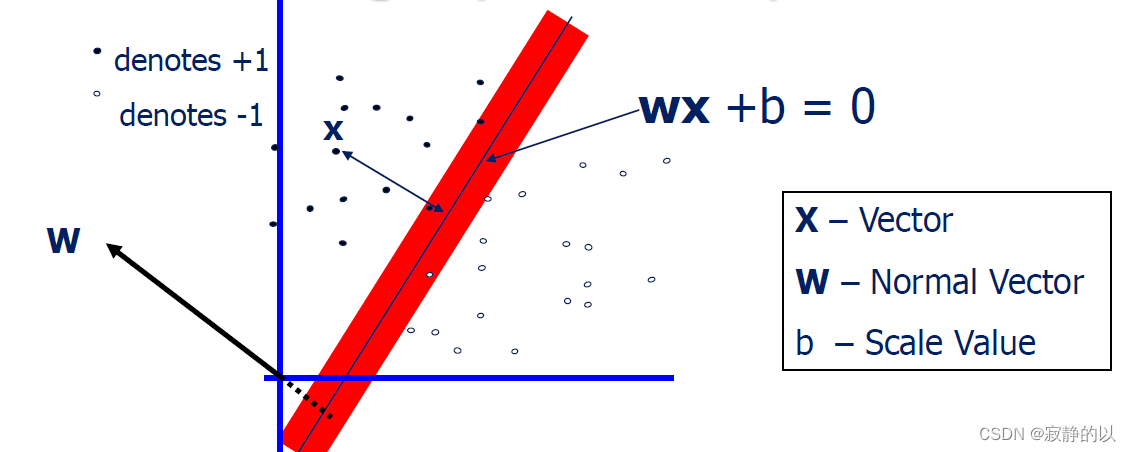
点到直线的距离:
d ( x ) = ∣ x ⋅ w + b ∣ ∥ w ∥ 2 2 = ∣ x ⋅ w + b ∣ ∑ i = 1 d w i 2 d(\mathbf{x})=\frac{|\mathbf{x} \cdot \mathbf{w}+b|}{\sqrt{\|\mathbf{w}\|_2^2}}=\frac{|\mathbf{x} \cdot \mathbf{w}+b|}{\sqrt{\sum_{i=1}^d w_i^2}} d(x)=∥w∥22∣x⋅w+b∣=∑i=1dwi2∣x⋅w+b∣
定义Margin:
margin ≡ arg min x ∈ D d ( x ) = arg min x ∈ D ∣ x ⋅ w + b ∣ ∑ i = 1 d w i 2 \operatorname{margin} \equiv \underset{\mathbf{x} \in D}{\arg \min } \,d(\mathbf{x})=\underset{\mathbf{x} \in D}{\arg \min } \frac{|\mathbf{x} \cdot \mathbf{w}+b|}{\sqrt{\sum_{i=1}^d w_i^2}} margin≡x∈Dargmind(x)=x∈Dargmin∑i=1dwi2∣x⋅w+b∣
所以我们就要考虑如何来最大化这个Margin了。
那么我们的问题就可以建模为:
argmax
w
,
b
margin
(
w
,
b
,
D
)
=
arg
max
w
,
b
arg
min
x
i
∈
D
d
(
x
i
)
=
arg
max
w
,
b
arg
min
x
i
∈
D
∣
b
+
x
i
⋅
w
∣
∑
i
=
1
d
w
i
2
\begin{aligned} & \underset{\mathbf{w}, b}{\operatorname{argmax}} \operatorname{margin} (\mathbf{w}, b, D) \\ & =\underset{\mathbf{w}, b}{\arg\max}\, \underset{\mathbf{x}_i \in D}{\arg \min } \,d\left(\mathbf{x}_i\right) \\ & =\underset{\mathbf{w}, b}{\arg\max} \,\underset{\mathbf{x}_i \in D}{\arg \min } \frac{\left|b+\mathbf{x}_i \cdot \mathbf{w}\right|}{\sqrt{\sum_{i=1}^d w_i^2}} \end{aligned}
w,bargmaxmargin(w,b,D)=w,bargmaxxi∈Dargmind(xi)=w,bargmaxxi∈Dargmin∑i=1dwi2∣b+xi⋅w∣
如果只是这样的话,肯定是不行的,想像一下,一条直线离两类都非常远,也是符合上式的,因此需要附加条件,也就是直线能正确分类。
W
X
i
+
b
≥
0
iff
y
i
=
1
W
X
i
+
b
≤
0
iff
y
i
=
−
1
y
i
(
W
X
i
+
b
)
≥
0
\begin{gathered} \mathbf{W X _ { i }}+b \geq 0 \text { iff } y_i=1 \\ \mathbf{W X _ { i }}+b \leq 0 \text { iff } y_i=-1 \\ y_i\left(\mathbf{W X _ { i }}+b\right) \geq 0 \end{gathered}
WXi+b≥0 iff yi=1WXi+b≤0 iff yi=−1yi(WXi+b)≥0
也就是
argmax
w
,
b
arg
min
x
i
∈
D
∣
b
+
x
i
⋅
w
∣
∑
i
=
1
d
w
i
2
subject to
∀
x
i
∈
D
:
y
i
(
x
i
⋅
w
+
b
)
≥
0
\begin{aligned} & \underset{\mathbf{w}, b}{\operatorname{argmax}} \,\underset{\mathbf{x}_i \in D}{\arg \min } \frac{\left|b+\mathbf{x}_i \cdot \mathbf{w}\right|}{\sqrt{\sum_{i=1}^d w_i^2}} \\ & \text { subject to } \forall \mathbf{x}_i \in D: y_i\left(\mathbf{x}_i \cdot \mathbf{w}+b\right) \geq 0 \end{aligned}
w,bargmaxxi∈Dargmin∑i=1dwi2∣b+xi⋅w∣ subject to ∀xi∈D:yi(xi⋅w+b)≥0
这边对一个限制条件进行强化,假设
∀
x
i
∈
D
:
∣
b
+
x
i
⋅
w
∣
≥
1
\forall \mathbf{x}_i \in D:\left|b+\mathbf{x}_i \cdot \mathbf{w}\right| \geq 1
∀xi∈D:∣b+xi⋅w∣≥1
因为咱们是对w进行优化,所以本质上其实是一样的,就是一个缩放的问题。
那么对里层的优化,有:
arg
min
x
i
∈
D
∣
b
+
x
i
⋅
w
∣
∑
i
=
1
d
w
i
2
≥
arg
min
x
i
∈
D
1
∑
i
=
1
d
w
i
2
=
1
∑
i
=
1
d
w
i
2
\underset{\mathbf{x}_i \in D}{\arg \min } \frac{\left|b+\mathbf{x}_i \cdot \mathbf{w}\right|}{\sqrt{\sum_{i=1}^d w_i^2}} \geq \underset{\mathbf{x}_i \in D}{\arg \min } \frac{1}{\sqrt{\sum_{i=1}^d w_i^2}}=\frac{1}{\sqrt{\sum_{i=1}^d w_i^2}}
xi∈Dargmin∑i=1dwi2∣b+xi⋅w∣≥xi∈Dargmin∑i=1dwi21=∑i=1dwi21
对于外层优化,只需最大化里层的下界就行,于是问题化为:
argmin
w
,
b
∑
i
=
1
d
w
i
2
subject to
∀
x
i
∈
D
:
y
i
(
x
i
⋅
w
+
b
)
≥
1
\begin{aligned} & \underset{\mathbf{w}, b}{\operatorname{argmin}} \sum_{i=1}^d w_i^2 \\ & \text { subject to } \forall \mathbf{x}_i \in D: y_i\left(\mathbf{x}_i \cdot \mathbf{w}+b\right) \geq 1 \end{aligned}
w,bargmini=1∑dwi2 subject to ∀xi∈D:yi(xi⋅w+b)≥1
















 1064
1064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











