






摘要
知识图谱中链接预测的研究主要集中在静态多关系数据上。在这项工作中,我们考虑时序知识图谱,其中实体之间的关系可能只保持在一个时间间隔或一个特定的时间点上。与之前在静态知识图谱上的工作一致,我们提出通过学习潜在实体和关系类型表示来解决这个问题。为了整合时间信息,我们利用RNN来学习关系类型的时间感知表示,这可以与现有的潜在因子分界方法一起使用。所提出的方法被证明对现实世界中的共同挑战:时间表达式的稀疏性和异质性。实验表明了我们的方法在四个时序知识图谱上的好处。这些数据集在一个BSD-3的许可下是可用的。
1、引言
知识图谱(KGs)用于组织、管理和检索结构化信息。大多数现实世界中的知识图谱的不完备性激发了预测实体之间缺失关系的研究。一个知识图谱的形式是G =(E,R),其中E是一组实体,R是一组关系类型或谓词。可以将G表示为形如(主语、谓语、宾语)的三元组,记为(s、p、o)。链接预测问题寻求最可能补全的元组(s,p,?)或(?,p,o)(Nickel 等人,2016)。我们关注时序知识图谱,其中一些三元组被时间信息增强,链路预测问题要求给定时间信息的最可能完成。更正式地说,时序知识图谱 G = (E, R, T)是一个知识图谱,其中事实既可以为(主语,谓语,宾语,时间戳)或(主语,谓语,宾语,时间谓词,时间戳)形式,也可以为(s, p, o)形式的三元组。例如,诸如(巴拉克·奥巴马,出生于,美国,1961年)或(奥巴马,总统,美国,自2009-01年以来发生)等事实表达了与巴拉克·奥巴马相关的事实的时间信息。前者表示一个关系类型发生在一个特定的时间点,而后者使用时间谓词“发生自”来表示一个(开放的)时间间隔。后一个例子还说明了由于语言和序列化标准的变化而导致的时间表达式的异质性所带来的一个共同挑战。
大多数链接预测方法的特点是一个评分函数,该函数操作于三元组的实体和关系类型嵌入(Bordes等人,2013;Yang等人,2014;Guu等人,2015)。由于时间表达式的稀疏性和不规则性,学习携带时间信息的表征具有挑战性。然而,也有可能将时间表达式转化为表示上述时间信息的标记序列。此外,用于语言建模的字符级架构(Zhang等人,2015;Kim等人,2016)将字符作为原子单元来推导出单词嵌入。受这些模型的启发,我们提出了一种将时间信息纳入链路预测的标准嵌入模型中的方法。如果它们存在这些标记序列表示时间谓词和时间戳的数字,我们通过训练一个循环神经网络来学习时间感知表示。循环神经网络的最后一个隐藏状态与知识图谱补全文献中的标准评分函数相结合。
2、相关工作
利用知识库中的时间信息进行推理有着悠久的历史,并产生了许多时间逻辑(van Benthem,1995)。最近的一些方法通过时间推理能力扩展了统计关系学习框架(Chekol等人,2017年;Chekol和斯图肯施密特,2018年;Dylla等人,2013年)。
在知识图补全方法中也有关于结合时间信息的工作。Jiang等人(2016)捕获了一些关系类型之间存在的时间排序以及额外的常识性约束,以生成更准确的链接预测。Esteban等人(2016)引入了一个链接预测的预测模型,该模型假设一个知识图谱的变化是由传入的事件引起的。这些事件被建模为一个单独的事件图,并用于预测未来链接的存在。Trivedi等人(2017)将一个事实的发生建模为一个点过程,其强度函数受到嵌入函数分配给该事实的分数的影响。Leblay和Chekol(2018)开发了一些评分函数,将时间表示纳入到TransE类型的评分函数中。之前的工作也纳入了数字但非时间的实体信息来进行知识库的补全(Garcia-Duran和Niepert,2017)。
与之前的所有方法不同,我们用RNN编码时间标记序列。这有助于用时间标记对关系类型进行编码,如“since”、“until”和时间戳的数字。此外,RNN编码为类似的时间戳(例如,那些发生在同一世纪的时间戳)之间的参数共享提供了一种归纳偏差。最后,我们的方法可以与所有现有的评分函数相结合。
3、时间感知表示
知识图谱补全的嵌入方法学习一个评分函数 f f f,该函数操作于 主语 e s e_s es、对象 e o e_o eo和三元组的谓词的嵌入 e p e_p ep。这个评分函数在一个三元组(s、p、o)上的值为 f ( s , p , o ) f(s,p,o) f(s,p,o),被认为与三元组为真的可能性成正比。评分函数的通常例子是:
TransE(Bordes等人,2013)
f
(
s
,
p
,
o
)
=
∣
∣
e
s
+
e
p
−
e
o
∣
∣
2
f(s,p,o)=||e_s+ e_p - e_o||_2
f(s,p,o)=∣∣es+ep−eo∣∣2
DistMult(yang等人,2014)
f
(
s
,
p
,
o
)
=
(
e
s
◦
e
o
)
e
p
T
f(s,p,o)=(e_s ◦e_o )e_p^T
f(s,p,o)=(es◦eo)epT
其中,
e
s
,
e
o
∈
R
d
e_s,e_o∈R^d
es,eo∈Rd是主体和对象实体的嵌入,
e
p
∈
R
d
e_p∈R^d
ep∈Rd是关系类型谓词的嵌入,
◦
◦
◦是元素级乘积。这些评分函数没有考虑到知识图谱中的时间信息。
给定一个时序知识图谱,其中一些三元组被时间信息增强,我们可以将一个给定的(可能是不完整的)时间戳分解为一个由以下一些时间标记组成的序列。
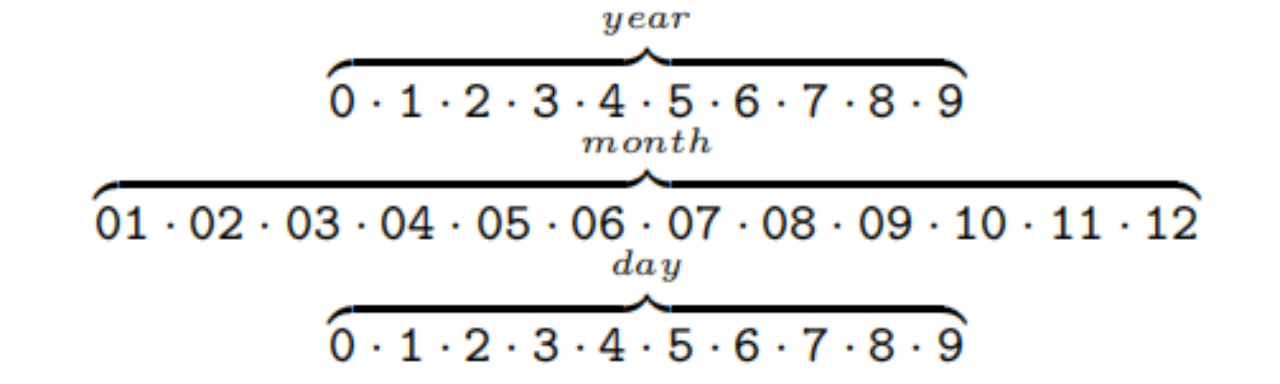
因此,时间标记的词汇量大小为32。此外,对于每个三元组标记,我们可以提取一个谓词标记序列,它总是由关系类型标记组成,如果可用,还可以提取一个时间修饰符标记,如“since”或“until”。我们将谓词标记序列和(如果有的话)时间标记序列的串联称为谓词序列 p s e q p_{seq} pseq。现在,一个时序知识图谱可以表示为 ( s , p s e q , o ) (s,p_{seq},o) (s,pseq,o)形式的三元组的集合,其中谓词序列可能包含时间信息。表1列出了来自一个时序知识图谱及其相应的谓词序列的此类事实的一些例子。我们使用后缀y、m和d来表示该数字是对应于年、月还是日的信息。正是这些标记序列被用作循环神经网络的输入。

3.1时间编码序列的LSTM
长短期记忆(LSTM)是一种特别适合用于建模序列数据的循环神经网络体系结构。定义一个LSTM的方程式是:

其中,i、f、o和g分别为输入、遗忘、输出和输入更新门。c和h分别为单元状态和隐藏状态。所有的向量都在 R h R^h Rh中。 x n ∈ R d x_n∈R^d xn∈Rd是一个序列的第 n n n个元素的表示。本文设置了 h = d h = d h=d。 σ g , σ c 和 σ h σ_g,σ_c和σ_h σg,σc和σh是激活函数。
输入序列 p s e q p_{seq} pseq的每个标记首先通过一个线性层映射到其相应的d维嵌入,并将结果的嵌入序列用作LSTM的输入。每个长度为N的谓词序列由LSTM的最后一个隐藏状态表示,即 e p s e q = h N e_{pseq} = h_N epseq=hN。携带时间信息的谓词序列表示 e p s e q e_{pseq} epseq ,现在可以与标准评分函数中的主语 e s e_s es和对象嵌入 e o e_o eo一起使用。例如,具有时间感知能力的TRANSE和DISTMULT,我们称之为TA-TRANSE和TA-DISTMULT,对三组 ( s , p s e q , o ) (s,p_{seq},o) (s,pseq,o)具有以下评分函数:
TA-TransE:
f
(
s
,
p
,
o
)
=
∣
∣
e
s
+
e
p
s
e
q
−
e
o
∣
∣
2
f(s,p,o)=||e_s+ e_{p_{seq} }- e_o||_2
f(s,p,o)=∣∣es+epseq−eo∣∣2
TA-DistMult
f
(
s
,
p
,
o
)
=
(
e
s
◦
e
o
)
e
p
T
f(s,p,o)=(e_s ◦e_o )e_p^T
f(s,p,o)=(es◦eo)epT
采用随机梯度下降的方法,将评分函数的所有参数与LSTM的参数联合学习。字符级模型为链接预测提供编码时间信息的优点是:
(1)使用数字和修饰符,如“since”作为原子标记,促进了跨类似时间戳的信息传递,从而提高了效率(例如,词汇量较小);
(2)在测试时,可以得到一个时间戳的表示,即使它不是训练集的一部分;
(3)模型可以使用带时间信息和不带时间信息的三元组作为训练数据。

图1说明了我们的方法的一般工作方式。
4、实验
我们在四个不同的知识图谱补全数据集上进行了实验,其中事实的一个子集被时间信息增强。
4.1 数据集
综合危机预警系统(ICEWS)是一个包含具有特定时间戳的政治事件的存储库。这些政治事件通过逻辑谓词(例如“访问”或“明确意图会面或谈判”)将实体(例如“国家、总统”)与许多其他实体关联起来。其他信息可以在http://www.icews.com/上找到。存储库以转储组织,包含1995年到2015年每年发生的事件。我们从这个存储库中创建了两个时序知识图谱,i)一个包含2014年所有事件的短期版本,以及ii)另一个包含2005-2015年之间发生的所有事件的长期版本。我们将这两个数据集分别称为ICEWS2014和ICEWS2005-15. 由于大量的实体,我们选择了图中最经常出现的实体的子集,以及所有主题和对象都是实体子集一部分的事实。我们将这些事实分别按80%/10%/10%的比例分为训练集、验证集和测试集。
创建这些数据集的协议与之前工作中遵循的相同(Bordes等人,2013)。为了创建YAGO15K,我们使用了FREEBASE15K(Bordes等人,2013)(FB15K)作为蓝图。我们将从FB15K到YAGO(Hoffart等人,2013)的实体与YAGO转储2中包含的SAMEAS关系进行了对齐,并保留了涉及这些实体的所有事实。最后,我们用来自“yagoDateFacts”转储的时间信息来增加事实集合。与ICEWS数据集相反,YAGO15k确实包含时序修饰符;即“OccurSince”和“OccuiUntil”。与之前的工作(Leblay和Chekol,2018)相反,所有事实都保持的时间信息与在这些数据集来自的原始转储中可以找到的粒度级别相同。
我们还对从(Leblay和Chekol,2018)中提取的WIKIDATA数据集中提取的时间事实进行了实验。这些事实只有关于年份的信息,因为作者丢弃了更细粒度的信息。所有的事实都被构建在一个时间间隔内(即,它们包含时间修改符“OccurSince”和“OccuiUntil”)。用单个时间点注释的事实与该时间点作为开始时间和结束时间点相关联。由于该数据集的大量实体,阻碍了标准知识图谱补全度量的计算,我们选择了最常见实体的一个子集,并保留了主题和对象都是该实体子集的一部分的所有事实。这组过滤后的事实用之前相同的比例分成训练集、验证集和测试集。
表2列出了时序知识图谱的一些统计数据。所有四个数据集及其相应的训练集、验证集和测试集分割都可以在https://github.com/nle-ml/mmkb上找到。
4.2一般设置
我们通过回答补全查询的能力来评估各种方法,其中i)除事实的所有参数都是已知的,ii)除对象实体之外的事实的所有参数都是已知的。对于前者,我们依次用每个知识库中的实体E替换主题,根据不同方法返回的分数对三元组进行排序,并计算正确实体的排名。我们对第二个补全任务重复了相同的过程,并对结果取平均值。这是知识图谱补全文献中的标准程序。我们还报告了如(Bordes等人,2013)中所述的过滤设置。计算所有排名的平均值是平均排名MR(越低越好),排名前n的正确实体的比例称为hits@n(越高越好)。我们还计算了平均倒数排名(越高越好),这一指标更不容易受到异常值的影响。
最近的工作(Leblay和Chekol,2018)评估了在时序知识图谱中执行链接预测的不同方法。学习每个时间戳的独立表示并使用这些表示作为翻译向量的方法,类似于(Bordes et al.,2013),可以得到最好的结果。这种方法被称为基于矢量的TRANSE,为了本文中的简单性,我们把它称为TTRANSE。我们将我们的方法TA-TRANSE和TA-DISTMULT与TTRANSE以及标准嵌入方法TRANSE和DISTMULT进行比较。对于所有方法,我们使用ADAM (Kingma and Ba, 2014)在学习速率为0.001的小批设置中进行参数学习,使用分类交叉熵(Kadlec等人,2017)作为损失函数,并将epoch数设置为500。我们每20轮进行一次验证,当验证集的MRR值下降时,就停止学习。所有实验的批量数设置为512,负样本数设置为500。嵌入维数d=100。我们将dropout (Srivastava等人,2014)应用于所有嵌入。我们验证了从值{0,0.4}对所有实验的dropout。对于TA-TRANSE和TA-DISTMULT,激活门
σ
g
σ_g
σg为
s
s
s型函数;选择
σ
c
σ_c
σc和
σ
h
σ_h
σh为线性激活函数。
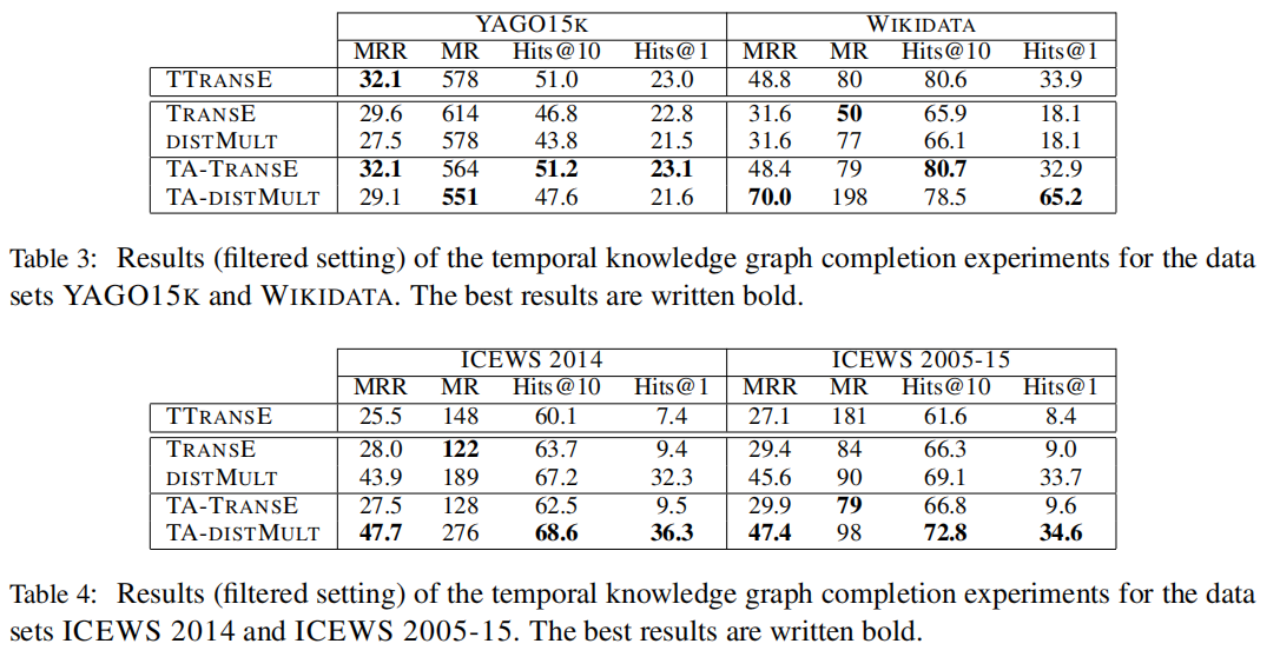
4.3结果
表3和表4列出了知识图谱补全任务的结果。在几乎所有情况下TA-TRANSE和TA-DISTMULT都系统地改善了TRANSE和DISTMULT,中的MRR,hits@10和hits@1。平均等级是一个非常容易受到异常值影响的度量标准,因此这些改进是不一致的。网络学习训练集中包含的每个时间戳的独立表示。在测试时,在训练期间未看到的时间戳用空向量表示。这就解释了TTRANSE只有在YAGO15K中才具有竞争力,其中不同的时间戳的数量非常小(见表2中的#不同的TS),因此存在足够的训练示例来学习健壮的时间戳嵌入。在WIKIDATA中,TTRANSE的性能类似于我们的时间感知的版本TRANSE,即TA-TRANSE。类似地,TTRANSE可以学习健壮的时间戳表示,因为这个数据集的不同时间戳数量较少。
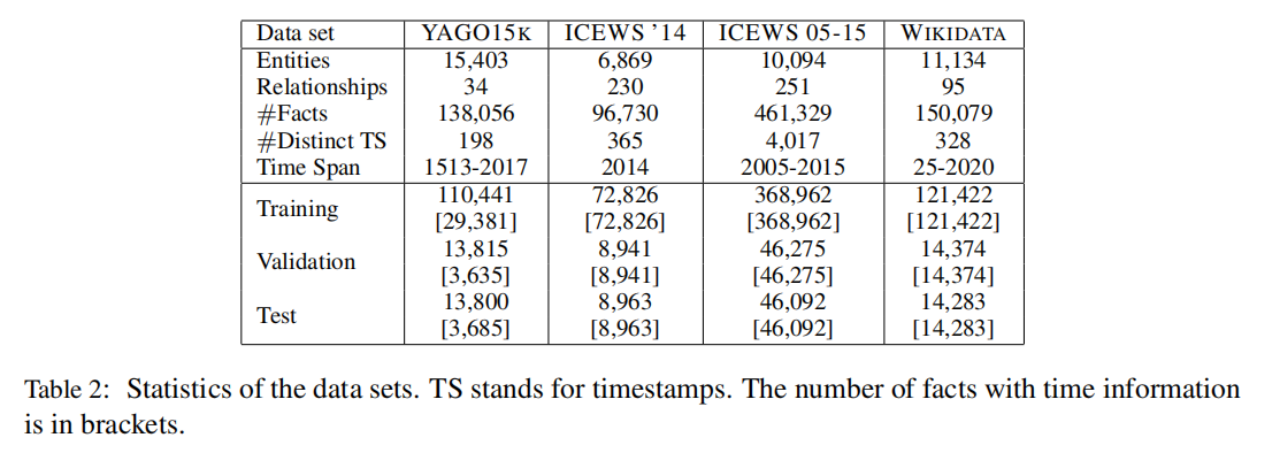
图2显示了T-SNE (Maaten and Hinton,2008)为谓词序列pseq = [playsFor, occursSince, date]学习的嵌入可视化,其中date对应于date令牌序列。这说明学习到的关系类型嵌入携带时间信息。
![图2显示了T-SNE (Maaten and Hinton,2008)为谓词序列pseq = [playsFor, occursSince, date]学习的嵌入可视化,其中date对应于date令牌序列。这说明学习到的关系类型嵌入携带时间信息。](https://img-blog.csdnimg.cn/8f54026573d84d1e86339ff3d9d25e8f.png#pic_center)
图3显示了YAGO15K的TRANSE和TA-TRANSE训练损失的比较。在相同的设置下,TA-TRANSE从时间信息中学习的能力导致的训练损失低于TRANSE。

5、结论
我们提出了一个数字级的LSTM来学习时间增强的知识图谱事实的表示,它可以与现有的链接预测模型的评分函数一起使用。在四个时序知识图谱上的实验证明了该方法的有效性。
总结
为了改善传统的双线性模型忽略时间信息、仅从时间未知的事实三元组中学习知识表示、预测性能较差的缺陷,Garcia-Duran等人针对双线性模型DISTMULT提出了对应的时间敏感版本模型——TA-DISTMULT。
TA-DISTMULT模型将时间戳分解为由时间token组成的序列。例如事实(巴拉克奥巴马,出生于,美国,1961年),该事实的时间戳为1961年,可以分解为[1y, 9y, 6y, 1y]。并且对于每个携带时间信息的四元组,TA-DISTMULT都可以提取出一个谓词序列pseq,该谓词序列由四元组中的关系和时序修饰符“自从”、“直到”等以及分解后的token组成。例如四元组(乔拜登,总统,美国,自从2021年1月7日),该事实的谓词序列
p
s
e
p
p_{sep}
psep由关系“总统”,时序修饰符“自从”和token序列[2y, 0y, 2y, 1y, 01m, 7d]组成。
TA-DISTMULT模型将谓词序列
p
s
e
p
p_{sep}
psep中的每一个token映射到低维向量空间,并将
p
s
e
p
p_{sep}
psep转化的Embedding序列作为长短期记忆网络LSTM的输入,长度为N的谓词序列由LSTM的最后一个隐藏状态表示成如下定义:
然后,TA-DISTMULT将事实的头实体,谓词序列和尾实体重新建模成一个三元组 ( e h , p s e p , e t ) (e_h, p_{sep}, e_t) (eh,psep,et),再将头实体和尾实体的嵌入表示以及谓词序列表示输入到DISTMULT的评分函数中进行训练:
重新构建后的三元组
(
e
h
,
p
s
e
p
,
e
t
)
(e_h, p_{sep}, e_t)
(eh,psep,et)即包含头实体和尾实体之间的关系信息,也包含了事实发生的事时间信息,相比于传统的DISTMULT模型大大提高了知识图谱补全的性能。
基于双线性模型的方法可以灵活地对逆反关系和对称关系进行建模,但是不能很好的建模复合关系。















 1824
1824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









