






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
摘要
知识图谱(KGs)是在Web上表示知识的一种流行方法,通常以节点/边标记的有向图形式表示。我们考虑时序知识图谱,其中边缘进一步用时间间隔标注,反映了实体之间的关系在何时保持。在本文中,我们着重于预测未注释边缘的时间效度。我们将这个问题作为关系嵌入的一种变化来引入。我们调整现有方法,并探索在学习过程中选择重要示例和纳入侧面信息。我们详细的介绍了我们的实验评估。
计算方法,时间推理;监督学习;
关键词:时序知识图谱,因式分解机。
一、引言
知识图谱(KGs)包含一个类知识表示模型,其中节点对应于实体,并以有向标记的边表示它们之间的关系。一些著名的知识图谱的例子包括谷歌的Knowledge Vault[5]、NELL [4]、YAGO [6]和DBpedia [1]。无论数据是由用户还是计算机程序生成和维护的,错误和遗漏都很容易激增,而且数据很快就会过时。更糟糕的是,一些用于数据发布的最流行的格式,包括RDF、JSON或CSV,并没有提供内置的机制,以便数据随时间变化而轻松地捕获和保留信息。作为一个例子,考虑从DBpedia数据集中提取的关于美国第22任和第24任总统格罗弗·克利夫兰的以下事实。
(GCleveland, birthPlace, Caldwell),
(GCleveland, office, POTUS),
(GCleveland, office, NewYork_Governor)
在这个例子中,缺乏时间信息是有问题的,原因有几个。这些事实都不是独立错误的,但格罗弗·克利夫兰不可能同时担任总统和州长。此外,由于格罗弗·克利夫兰曾两次担任总统,而且是在两个非连续的任期内,所以这些信息都是缺失的。因此,很明显,时间元数据将消除一些模糊性,但并非所有事实通常都需要这样的元数据。例如,他的出生地预计不会随着时间的推移而改变。
许多知识图谱不包含事实的有效期限,即事实被认为保持的期限。值得注意的例外包括Wikidata[20]和YAGO,其中一些事实被赋予了时间信息。我们的目标是学习知识图谱上的时间元数据,这些信息是不完整的。对于上面的例子,我们希望派生如下形式的注释:
(GCleveland, office, POTUS):[1885-1889;1893-1897],
(GCleveland, office, NewYork_Governor):[1883-1885]
请注意,格罗弗·克利夫兰在两届不同的、非连续的任期内担任总统。在下一节中,我们将提供一些正式的背景并回顾相关的工作。在第3节中,我们首先尝试从关系嵌入模型中继承技术,并研究这些方法的局限性。然后,我们继续表明,因式分解机特别适合于我们的时间范围预测任务,允许考虑有价值的侧信息。在第4节中,我们报告了早期的实验结果。
二、准备工作
下面,我们将正式地介绍时序知识图谱,以及本文所讨论的问题。我们提出了关系嵌入方法和因式分解机的可能扩展。
2.1 时序知识图谱
我们考虑G =(E,R)形式的知识图谱,其中E是一组称为实体的标记节点,R是一组称为关系的标记边。或者,我们可以将G称为(主语、谓词、对象)形式的三元组,其中主语和对象是节点标签,谓词是边标签。因此,我们假设有一组离散的时间点T,并在边缘上有一个附加的标记方案,该方案采用T上的一组时间间隔,表示一个事实被认为是正确的时间段。这就产生了一个时序知识图谱。
2.2 问题陈述
我们的目标是学习一个知识图谱的事实与T中的一个或多个时间点之间的联系。这使我们有能力处理以下任务:
- 时间预测: 给定一个四元组(s、p、o、?),预测事实被认为是有效/真实的时间点。
- 依赖于时间的查询回答: 给定一个时间点和一个缺少主语、谓词或对象的事实,预测最有可能的标签。
2.3 相关工作
我们从三个不同的角度提出了相关的工作:
(i)知识图事实的时间范围,
(ii)用于链接预测的关系嵌入,
以及(iii)用于三元组分类的因子分解机。
2.3.1知识图谱事实的时间范围
关于推导知识图谱事实的时间范围的研究最近获得了发展势头。最近的一个是Know-Evolve[19]。KnowEvolve中的时序知识图谱是一组事实,其中每个事实都有一个带有时间戳的关系。对于嵌入实体和时间戳关系,他们使用双线性模型(RESCAL),并使用深度递归神经网络来学习非线性进化的实体。学习阶段支持一个点过程,通过这个点过程,对t时刻的事实是否成立的估计是基于t−1时刻的状态。也就是说,他们不像我们在这项工作中那样利用侧边信息。另一项密切相关的工作是Jiang等人[7]的时间感知知识图谱嵌入模型。他们关注于一个实体或关系的预测,给定一个时间点,其中事实应该是有效的。Know-Evolve和时间感知知识图谱补全方法都使用关系嵌入模型,下面将对此进行讨论。此外,在[18]中,作者使用张量分解来分配知识图谱事实的有效性范围。然而,正如论文中所报道的,他们的模型并没有足够好的表现。尽管如此,这可以通过包括我们在这里所做的附加信息来改进。
相比之下,Rula等人使用语法规则提取Web页面中包含的时间信息。该过程分为三个阶段,根据时间一致性规则对事实候选区间进行匹配、选择和合并。YAGO[6]是另一个较早的示例,其中使用语言提取规则提取时间和空间作用域,然后进行冲突解决后处理。
在[21]中,作者将时间作用域问题表述为状态变化检测问题。在这样做的过程中,他们用相关的上下文信息丰富了实体的时间概况(这些是围绕着一个实体的提及的缩略图,例如,对于实体Barack Obama,相关的缩略图包括“elect”、“senator”等等)。从那里,他们学习反映上下文变化模式的向量。例如,在“成为总统”之后,美国总统经常会发现,他们之前的职位头衔,如“参议员”或“州长”,被提到的次数会减少,取而代之的是“总统”这个头衔。
[15]开发的另一个时间作用域系统依赖于一个语言模型,该模型由自动从包含页面和主要实体的Wikipedia句子派生的模式组成从相应的信息框中提取的时态槽填充符。
Talukdar等人使用事实提及的频率计数来定义时间剖面(基本上是事件发生的时间序列),并分析这些事实的提及是如何随着时间的推移而上升和下降的。他们使用三阶段程序识别输入事实的时间范围。
然而,这种方法相当脆弱,因为它不能自动适应新的关系,并且需要人类专家在过程中的几个步骤。
Bader等人[2]对Enron电子邮件数据集使用矩阵分解,以估计丑闻的利益相关者之间随时间的关系。与我们的设置不同的是,这些关系没有被标记。
2.3.2关系嵌入方法
我们的问题更普遍地与关系嵌入模型有关,这是低维向量空间中的关系学习范式,已广泛用于链接预测和事实分类等任务。我们的问题更普遍地与关系嵌入模型有关,这是低维向量空间中的关系学习范式,已广泛用于链接预测和事实分类等任务。这样的嵌入可以看作是图嵌入的一个特例,这是一个非常活跃的研究课题,为了简洁起见,我们在这里省略了它。我们可以根据(i)平移距离,(ii)张量分解(双线性模型),以及最近的(iii)神经网络,将模型大致分为三类。在翻译模型中,向量用于学习实体和关系嵌入,而在双线性模型和神经网络中使用附加矩阵。翻译模型使用距离度量来度量事实的合理性,而双线性模型依赖于实体和关系嵌入的点积。最著名的平移模型之一是TransE[3]。它的简单性允许直接扩展[9]。三元组(s, p, o)的翻译嵌入对应于s + p ≈ o。一个评分函数对三元组(s, p, o)评分,可以用ℓ1或ℓ2范数,来衡量距离(即相似度)为:
s
c
o
r
e
(
s
,
p
,
o
)
=
−
∣
∣
s
+
p
−
o
∣
∣
L
1
/
2
score(s,p,o)= - ||s+p-o||_{L_{1/2}}
score(s,p,o)=−∣∣s+p−o∣∣L1/2
训练集包含正例(G)和反例(G’),生成如下:
G
(
s
,
p
,
o
)
∈
G
′
=
{
(
s
′
,
p
,
o
)
∣
s
′
∈
E
,
(
s
′
,
p
,
o
)
∉
G
}
∪
{
(
s
,
p
,
o
′
)
∣
o
′
∈
E
,
(
s
,
p
,
o
′
)
∉
G
}
G^\prime_{(s,p,o)\in G}= \left\{ (s^\prime,p,o)| s^\prime\in E, (s^\prime,p,o)\notin G\right\} \cup \left\{ (s,p,o^\prime)| o^\prime\in E, (s,p,o^\prime)\notin G\right\}
G(s,p,o)∈G′={(s′,p,o)∣s′∈E,(s′,p,o)∈/G}∪{(s,p,o′)∣o′∈E,(s,p,o′)∈/G}
因此,G '包含三元组,其中s或o被集合E中的一个随机实体替换。
RESCAL[11]也被称为双线性模型,它通过在一个张量中表示三元组来使用一个张量因式分解模型。也就是说,对于每个三重
x
i
j
k
=
(
s
i
,
p
k
,
o
j
)
,
y
i
j
k
=
{
0
,
1
}
x_{ijk} = (s_i, p_k, o_j), y_{ijk} =\{0,1\}
xijk=(si,pk,oj),yijk={0,1}表示其在张量
Y
∈
{
0
,
1
}
∣
E
∣
×
∣
E
∣
×
∣
R
∣
Y∈\{0,1\}^{|E|× |E|× |R|}
Y∈{0,1}∣E∣×∣E∣×∣R∣中存在或不存在。RESCAL学习实体的向量嵌入,对于每个关系
r
∈
R
r∈R
r∈R,矩阵
W
p
∈
R
d
×
d
W_p∈R^{d×d}
Wp∈Rd×d,其中每个片
Y
Y
Y被分解为:$ Y ≈ s^TW_po $。因此,双线性模型的评分函数为:
s
c
o
r
e
(
s
,
p
,
o
)
=
s
T
W
p
o
score(s,p,o)=s^TW_po
score(s,p,o)=sTWpo
其他值得注意的关系嵌入模型是HolE[10]和神经张量网络(NTN)[16]。HolE通过使用循环相关操作(它压缩了两个实体之间的交互)对三元组进行评分,提高了效率。
几乎所有的关系嵌入方法都在一些训练数据集上最小化基于边缘的排序损失函数L。L由下式给出:
L
=
∑
(
s
,
p
,
o
)
∈
G
∑
(
s
,
p
,
o
)
′
∈
G
(
s
,
p
,
o
)
′
[
γ
+
s
c
o
r
e
(
(
s
,
p
,
o
)
)
−
s
c
o
r
e
(
(
s
,
p
,
o
)
′
)
]
+
L = \sum_{(s,p,o)\in G}\sum_{(s,p,o)^\prime\in G^\prime_{(s,p,o)}}[\gamma+score((s,p,o))-score((s,p,o)^\prime)]_+
L=(s,p,o)∈G∑(s,p,o)′∈G(s,p,o)′∑[γ+score((s,p,o))−score((s,p,o)′)]+
2.3.3分解机器
与向量空间嵌入模型不同,因子分解机(FMs)允许我们将上下文信息结合起来,从而提高预测性能。Rendle[12]引入FMs,使用因子分解参数对特征之间的相互作用进行建模。FMs的一大优点是,即使在非常稀疏的数据中,它们也可以估计出特征之间的所有交互作用。此外,FMs可以模拟许多不同的矩阵分解模型如偏矩阵分解、奇异值分解(SVD++)[8]和成对交互张量分解(PITF)[13]。FMs提供了特征工程的灵活性和较高的预测精度。此外,FMs可以应用于以下任务:回归、二元分类和排序。分解机的模型由下式给出:
s
c
o
r
e
(
x
)
:
=
w
0
+
∑
i
=
1
n
w
i
x
i
+
∑
i
=
1
n
∑
j
=
i
+
1
n
〈
v
i
,
v
j
〉
x
i
x
j
,
score(x):=w_0+\sum_{i=1}^n w_ix_i + \sum_{i=1}^n\sum_{j=i+1}^n 〈v_i,v_j〉x_ix_j,
score(x):=w0+i=1∑nwixi+i=1∑nj=i+1∑n〈vi,vj〉xixj,
〈
v
i
,
v
j
〉
:
=
∑
f
=
1
k
v
i
,
f
⋅
v
j
,
f
,
〈v_i,v_j〉:=\sum_{f=1}^k v_i,f·v_j,f,
〈vi,vj〉:=f=1∑kvi,f⋅vj,f,
其中
s
c
o
r
e
:
R
n
→
T
score: R^n→T
score:Rn→T是实值特征向量
x
∈
R
n
x∈R^n
x∈Rn到目标域的预测函数,
T
=
R
T = R
T=R用于回归,
T
=
+
,
−
T ={+,−}
T=+,−用于分类,以此类推。模型参数:
w
0
w_0
w0表示全局偏差;
w
i
w_i
wi表示
w
∈
R
n
内
w∈R^n内
w∈Rn内的第i个变量的强度,
n
n
n为特征向量的大小;
〈
v
i
,
v
j
〉
〈v_i, v_j〉
〈vi,vj〉建模第
i
i
i和第
j
j
j个变量之间的交互。
〈
.
,
.
〉
〈., .〉
〈.,.〉是两个大小为k的向量的点积。
此外,
V
∈
R
n
×
k
V∈R^{n×k}
V∈Rn×k中的模型参数
v
i
vi
vi描述了具有
k
k
k个因子的第
i
i
i个变量。
k
k
k是一个定义因子分解维数的超参数。
在本研究中,由于我们需要预测(可能多个)时间点的事实的有效性,我们使用因子分解机进行分类,而不是回归或排序。
3、时间范围预测
接下来我们考虑关系嵌入模型和因子分解机的时间范围预测。
3.1 时序知识图谱的关系嵌入模型
我们提出了在向量空间中表示时序知识图谱的各种方法。特别地,我们研究了现有的关系嵌入方法的几个扩展。
3.1.1 TTransE
作为时序TransE的简称,这是著名的嵌入模型TransE[3]的扩展,通过替换它的评分函数。
(a) 朴素的TTransE:时间是通过综合关系来编码的。对于词汇表中的每个关系r和每个时间点
t
∈
T
t∈T
t∈T,我们假设一个综合关系
r
:
t
r:t
r:t。例如,时间事实(GCleveland, office, POTUS):1888,编码为(GCleveland, office:1888, POTUS)。评分函数保持不变(如等式(1)所示):
s
c
o
r
e
(
s
,
p
:
t
,
o
)
=
−
∣
∣
s
+
p
:
t
−
o
∣
∣
l
1
/
2
score(s,p:t,o)= -||s+p:t-o||_{l_{1/2}}
score(s,p:t,o)=−∣∣s+p:t−o∣∣l1/2
虽然这个模型很简单,但它是不可扩展的。此外,链接预测并不能区分两个连续的时间点,例如,对于任务(GClivan, ?, POTUS),office:1988和office:1989都是可能的链接。
(b) 基于向量的TTransE:在这种方法中,时间与实体和关系表示在相同的向量空间中。评分函数变为:
s
c
o
r
e
(
s
,
p
,
o
,
t
)
=
−
∣
∣
s
+
p
+
t
−
o
∣
∣
l
1
/
2
score(s,p,o,t)=-||s+p+t-o||_{l_{1/2}}
score(s,p,o,t)=−∣∣s+p+t−o∣∣l1/2
在这种方法中,时间点有嵌入表示,就像实体和关系一样。这个评分函数背后的基本原理是,相对于任何有效的时间点,驱动(主语,谓词)接近正确的对象。
© 基于系数的TTransE:时间点(或更确切地说是其归一化)被用作影响三元组时间点的主体和关系嵌入的系数。
s
c
o
r
e
(
s
,
p
,
o
,
t
)
=
−
∣
∣
t
∗
(
s
+
p
)
−
o
∣
∣
l
1
/
2
score(s,p,o,t)=-||t*(s+p)-o||_{l_{1/2}}
score(s,p,o,t)=−∣∣t∗(s+p)−o∣∣l1/2
作为一个变体,只有关系受时间的影响:
s
c
o
r
e
(
s
,
p
,
o
,
t
)
=
−
∣
∣
s
+
p
∗
t
−
o
∣
∣
l
1
/
2
score(s,p,o,t)=-||s+p*t-o||_{l_{1/2}}
score(s,p,o,t)=−∣∣s+p∗t−o∣∣l1/2
与基于向量的TTransE不同,时间点用(0,1]中的实数表示,因此不受优化的直接影响。
3.1.2 TRESCAL
TRESCAL是RESCAL的一个时序扩展版本。我们扩展其双线性时间评分函数如下。就像朴素的TTranse一样,时间是通过合成关系编码的。
s
c
o
r
e
(
s
,
p
,
o
,
t
)
=
s
T
W
p
:
t
o
score(s,p,o,t)=s^TW_{p:t}o
score(s,p,o,t)=sTWp:to
该模型是双线性模型的直接扩展。虽然比较简单,但扩展性不大,预测结果较差。
3.2 时序知识图谱的因式分解机
在目前所描述的方法中,简单的方法不能很好地随时间域的大小或分辨率的增加而扩展。虽然基于向量的TTransE方法总体上比其他技术表现得更好,但它在实践中并没有显示出足够好的性能来解决我们的问题。接下来,我们将展示如何使用因数分解机来解决可伸缩性和性能问题。
数据/特征表示。我们考虑一个知识图谱
G
=
G
t
∪
G
c
G = G_t ∪ G_c
G=Gt∪Gc,其中
G
t
G_t
Gt是一组四元组或带时间戳的三元组,而
G
c
G_c
Gc是一组时序的三元组,我们称之为上下文图。例如,下面是一个时序知识图谱
G
t
G_t
Gt:
(GCleveland, office, POTUS):1888,
(GCleveland, office, POTUS):1895,
它的上下文图
G
c
G_c
Gc如下所示:
(GCleveland, birthPlace, Caldwell)
FM的输入是数据对
(
G
t
、
G
c
)
(G_t、G_c)
(Gt、Gc)的特征向量表示。特征向量编码可以通过多种方式构建,如单热编码、单词袋(表示包或多集中的KG实体和关系)和[12]等。与形式
(
s
、
p
、
o
)
(s、p、o)
(s、p、o)相关的特征是
{
b
o
w
(
s
)
、
p
、
b
o
w
(
o
)
}
\{bow(s)、p、bow(o)\}
{bow(s)、p、bow(o)},其中
b
o
w
(
x
)
bow(x)
bow(x)返回与主语x相关的所有文字的单词袋。
生成示例。为了生成正例子,我们使用了时间采样,在输入参数TS的指导下,即在事实的有效性区间内均匀采样st时间点。第二个参数NS指导负采样,使用与[3]中相同的随机破坏技术,为每个基于正时间点的事实/示例产生sn。
4、实验
我们基于RESCAL和TransE和libFM/pywFM的scikit-kge库实现了我们的方法。
4.1 数据集
我们最初尝试使用相关工作中常用的Freebase数据库(我们的第一组实验)。然而,由于这些数据集上没有时间信息,我们通过随机选择两年并使用它们作为开始和结束有效日期,为它们中的一个子集随机生成这样的元数据。因此,很难将我们的结果与非时间关系嵌入场景中的相应工作进行比较。Freebase有大约14K个实体,以及1000个关系,有60k个例子。后来,我们决定切换到Wikidata知识库,这是一个拥有相当高质量时间信息的知识库。更重要的是,Wikidata要大得多,而且是最新的。我们只简要地介绍了在前一个数据集中获得的结果,结果大部分是否定的。此外,由于缺乏可利用的侧信息,使用Freebase和WordNet数据集和因子分解机的方法是不可能的:数据集包含的纯文本非常少。
我们准备Wikidata数据集的过程如下。我们从最近的转储中提取了三元组,并将它们划分为两组: (i)时间事实:具有一些时间注释的事实,如时间点、开始时间、结束时间或其任何子属性,(ii)不受时间影响的事实:非时间的事实,没有这样的注释。注释时间事实的时间属性包括"start time", “inception”, "demolition time"等。在这项工作中,我们只考虑年,从而将所有的年份都规范化为公历,丢弃粒度更细的信息。用单个时间点标注的事实与该时间点关联,作为开始时间和结束时间。
在学习阶段,时间事实被用来生成积极和消极的例子,而不受时间影响的事实被用来收集边信息。完整的数据有420万个时间事实。在大约3600个不同的属性中,有2770个是严格不受时间影响的属性,也就是说,它们对应的三元组是没有时间注释的。在剩下的属性中,有17个是严格受时态影响的,即它们对应的所有三元组都有时态注释。而对于剩下的813个属性,只有一些三元组被注释。我们将三元组划分为两个集合,分别为有和没有时间注释,前者是我们的原始示例集。从这个示例集(时间事实)中,我们排除了严格的时间事实(因为它们不是预测的候选对象),具有最频繁的单频繁属性的事实(覆盖近1.2万个例子),以及那些属性覆盖不到10个例子的事实(大约397个属性)。最终,我们的示例集包含250万个示例,远远超过了相关方法中使用的大多数数据集(参见示例[3,10])。我们还报告了这个数据集的精简版本,包含180K的结果时间注释的事实(即,大约。5%的整体数据)。我们的数据集可在网上找到(http://staff.aist.go.jp/julien.leblay/datasets/)。
第二组三元组(不受时间影响的事实)用于生成特征。我们还删除了具有低语义内容的三元组集,例如那些将Wikidata实体ID映射到其他数据集的实体ID。
4.2 时序关系嵌入
在这个实验中,我们使用修改后的Freebase数据集,并使用相关工作中稍微修改的版本来评估方法,该工作使用查询三元组进行评估,即其中一项需要模型预测的事实。对于查询回答,省略了s或o,而在链接预测中省略了p。评价指标是所有答案中正确答案的平均排名,按它们的预测概率排序。越低越好。指标还包括“Hits@K”,即正确答案在前K结果中的情况的百分比。Hits@10是一个流行的度量标准,但对于小领域(如链接预测),Hits@1通常是首选。在我们的设置中,我们处理四元组,因此我们将过程扩展到时间预测,其中时间被省略,并将评估预测的效度时间点在事实的实际效度区间内的频率。
在表1中,我们只报告了每种方法获得的最佳结果。我们在{0.01,0.1]中运行了具有学习率(LR)的方法,{2、10}之间的边距(M),{20、50、100、200}之间的向量空间维数(D),以及学习超过500或1000个epochs (E)。从表中可以清楚地看出,这些效果并不令人满意。然而,我们可以区分出两个普遍的问题。对于幼稚的方法(公式4-8),空间从方法所包含的“虚拟关系”的乘法中爆发出来。这就是为什么虽然实现了显著的成本降低,但性能却很差。然而,其他方法并不能完全降低成本。对此,我们最好的解释是,仅从图的结构(即不使用其他外部信息)学习时间效度是非常困难的。这个结论使我们转向因子分解机方法,它更类似于侧信息的合并。

4.3 FM上的分类任务
对于分类任务,学习是在(s,p, o,t) =±1形式的四元组上进行的,建模三元组(s,p, o)在时间t时是否成立。抽样后,有效样本数增加。例如TS = (GCleveland, office, POTUS):[1885,1889],将生成时间点1885,1887,1889的正例。反过来,评估是在时间点而不是时间间隔上执行的。我们使用了预测、召回、F -测度和准确性的标准定义。这些指标的定义如下:

我们使用了最优化函数交替最小二乘(ALS)和马尔可夫链蒙特卡罗(MCMC)。我们在表2中报告了精度、召回率、f测度和准确性,其中显示了在180K和2.5M示例的Wikidata数据集上运行的实验结果,使用单词袋作为边信息,随着时间采样大小的增加。高NS的结果被省略,因为更多的负面例子倾向于模型偏向于负面预测,导致高精度,尽管精度较差。通过一组平衡的正负例子,精度与TS呈正相关。使用100的时间采样,我们较小的数据集,经过100次迭代后,准确率和召回率峰值分别为74.5%和92%,f1度量和准确率约为82%。使用10的时间采样大小,使用我们更大的数据集,f1度量和精度达到90%。增加样本量,也提高了性能,但在一个时间间隔内对所有时间点产生积极的例子会降低性能,这可能是由于过度拟合。我们的结果还表明,仅需10次迭代就可以达到70%左右的精度。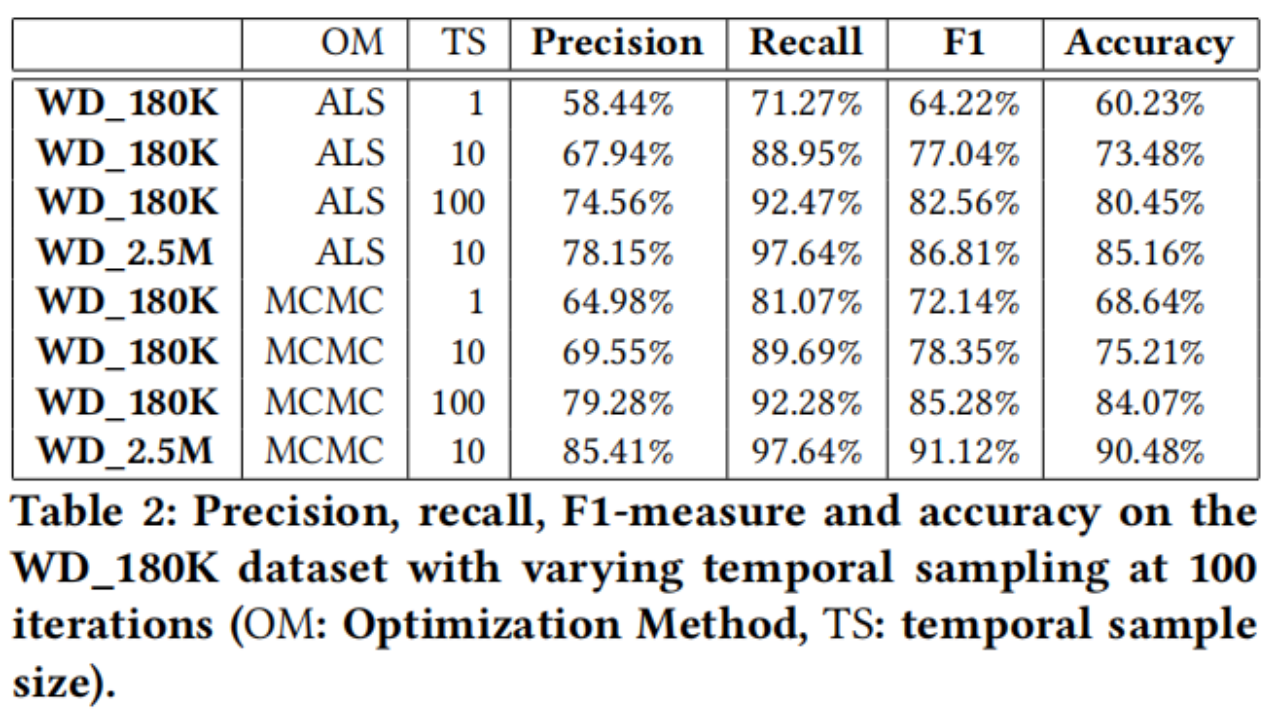
我们最苛刻的实验花了6个多小时才能完成,配备16GB内存,2.8 GHz英特尔酷睿i5处理器。
我们已经排除了TTransE和TRESCAL的实验结果,因为我们的结果表明,这两种方法没有竞争力。
5、 结论
在这项工作中,我们研究了时间范围预测的问题。我们采用了几种现有的关系嵌入方法,我们的实验结果表明,它们存在可伸缩性或准确性问题。因子分解机器克服了这些缺点,因为它们提供了一种合并边信息的方法,从而提高了预测性能。通过仔细分析维基达塔,我们设计了一个新的数据集,并进行了几个实验。我们相信我们的实验结果很有希望的。接下来,我们计划将注意力转向基于神经网络的方法,扩展我们当前的框架,以支持有时间感知的链接预测和查询回答,并将我们的发现应用于其他类型的上下文预测,如空间或来源。我们都计划在一个开放的信息提取设置中应用该方法。

















 5724
5724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









