






摘要
大多数现有的知识库(KB)嵌入方法只从时间未知的事实三元组中学习,而忽略了知识库中的时间信息。在本文中,我们提出了一种新的基于时间感知的知识库嵌入方法。具体地说,我们使用时间顺序约束来建模时间敏感关系之间的转换,并强制嵌入在时间上一致并更加准确。我们在链接预测和三元组分类这两个任务中证实评估了我们的方法。实验结果表明,我们的方法在两个任务上始终优于其他基线模型。
1、引言
知识库(KBs),如Freebase(Bollacker等人,2008)和YAGO(Fabian等人,2007),在许多NLP相关应用中发挥着关键作用。知识库以三元组(ei, r, ej)的形式存储,表明头实体ei和尾实体ej是由关系r连接的。虽然知识库很大,但它们还远远不够完整。链接预测是基于现有的三元组来预测实体之间的关系,这可以缓解当前知识库的不完全性。最近,一种很有前途的方法称为知识库嵌入(Nickel 等人,2011;Bordes等人,2011;Socher等人,2013)的目标是将实体和关系嵌入到一个连续的向量空间中,同时保留知识库中图的某些信息。TransE(Bordes 等人,2013)是一个典型的知识库嵌入模型,它将关系向量作为头实体向量和尾实体向量之间的平移操作,即当(ei, r, ej)成立时,ei + r≈ej。
大多数现有的知识库嵌入方法只从时间未知的事实中学习,而忽略了知识库中有用的时间信息。事实上,在知识库中有许多时间事实(或事件),例如,(奥巴马,出生于,夏威夷)发生于1961年8月4日。(奥巴马,总统,美国)自2009年以来就一直是如此。当前的知识库,如YAGO和Freebase,可以直接或间接地存储这些时间信息。时间敏感事实的发生时间可能表明了事实的特殊时间顺序和时间敏感关系。例如,(爱因斯坦,出生与,乌尔姆)发生在1879年,(爱因斯坦,获奖,诺贝尔奖)发生在1922年,(爱因斯坦,去世于,普林斯顿)发生在1955年。我们可以从所有这些事实中推断出时间敏感关系的时间顺序:出生于→获奖→去世于。传统的知识库嵌入模型如TransE在预测(人,?,地点位置)时经常混淆“出生于”和“去世于”这样的关系,因为TransE只从时间未知的事实中学习,而不能区分具有相似语义的关系。为了能做出更准确的预测,现有的知识库嵌入方法合并时间顺序信息并非简单。
本文主要研究了结合时间顺序信息,并提出了一种具有时间感知能力的链接预测模型。一个新的时间维度被添加到事实三元组中,表示为四元组(ei, r, ej, tr),表示在时间tr处发生的事实。为了使嵌入空间在事实维数上与观察到的三元组嵌入空间相容,类似于TransE模型,关系向量表现为实体向量之间的平移。为了在成对的时间事实之间加入时间顺序信息,我们假设先验的时间敏感关系向量可以通过时间转换演化为后续的时间敏感关系向量。例如,我们有两个时间事实共享相同的头实体:(ei, ri, ej, t1)和(ei, rj, ek, t2),时间顺序约束t1< t2,即ri发生在rj之前,然后,我们提出了先验关系ri在时间转移后应该接近于后续关系rj的假设,即,riM≈rj,这里的矩阵M捕获关系之间的时间顺序信息。通过这种方式,在学习过程中语义和时间信息都嵌入到连续的向量空间中。据我们所知,我们是第一个考虑这样的时间信息的人。
我们在公共可用的数据集上评估了我们的方法,我们的方法在有时间感知的链接预测和三元组分类任务中优于最先进的方法。
原文献链接
2、时间感知知识库嵌入
传统的知识库嵌入方法只编码观察到的事实三元组,但忽略了对时间敏感的实体和事实之间的时间约束。为了解决这一限制,我们引入了时间感知知识库嵌入,它通过合并时间约束来限制任务。
为了考虑事实的发生时间,我们将一个时间顺序约束作为一个基于流形正则化项的优化问题。特别是,时间敏感事实中关系的时间顺序应该会影响知识库的表示。如果ri和rj共享相同一个头部实体ei,并且ri出现在rj之前,那么先验关系向量ri可以在时间维上演化为后续的关系向量rj。
为了编码时间敏感关系之间的转换,我们定义了一个=时间顺序关系对(ri,rj)之间的转换矩阵 M∈Rn×n。我们的优化要求正时序关系对的 s-cores(能量)低于负对,因此我们将时间顺序评分函数定义为:
g
(
r
i
,
r
j
)
=
∣
∣
r
i
M
−
r
j
∣
∣
1
g(r_i,r_j)=||r_iM-r_j ||_1
g(ri,rj)=∣∣riM−rj∣∣1
当关系对按时间顺序排列时,预计得分较低,否则得分较高。
为了使嵌入空间与观测到的三元组兼容,我们使用了三元组集∆,并采用了与TransE等以往方法相同的策略。
f
(
e
i
,
r
,
e
j
)
=
∣
∣
e
j
+
r
−
e
j
∣
∣
1
f(e_i,r,e_j)=||e_j + r - e_j||_1
f(ei,r,ej)=∣∣ej+r−ej∣∣1
对于每个候选三元组,它要求正的三元组的分数低于负的三元组分数。
优化的方法是为了最小化联合得分函数,

其中, x + = ( e i , r i , e j ) ∈ ∆ x^+=(e_i, r_i, e_j)∈∆ x+=(ei,ri,ej)∈∆ 为正三(四)元组, x − = ( e i ’ , r i , e j ’ ) ∈ ∆ ’ x^−=(e_i^’, r_i, e_j^’)∈∆^’ x−=(ei’,ri,ej’)∈∆’对应为负三元组。 y + = ( r i , r j ) ∈ Ω e i y^+ =(r_i,r_j)∈Ω_{ei} y+=(ri,rj)∈Ωei是相对于 ( e i , r i , e j , t x ) (e_i, r_i, e_j, t_x) (ei,ri,ej,tx)的正相关的关系排序对。已将其定义为:

其中,
r
i
r_i
ri和
r
j
r_j
rj共享同一个头实体
e
i
,
y
−
=
(
r
j
,
r
i
)
∈
Ω
e
i
e_i,y^−=(r_j, r_i)∈Ω_{ei}
ei,y−=(rj,ri)∈Ωei’为对应的负关系序对。在实验中,我们强制执行约束为||ei||2≤1,||ri||2≤1,||rj||2≤1和||riM||2≤1
式(3)中的第一项要求合成的嵌入空间与所有观察到的三元组兼容,第二项进一步要求空间在时间上要一致,更准确。超参数λ在这两种情况下进行了权衡。采用随机梯度下降(在小批处理模式下)来解决最小化问题。
3、实验
我们在两个任务中采用相同的评估指标:链接预测(Bordes等人,2013)和三元组分类(Socher等人,2013)。
3.1数据集
我们从YAGO2(Hoffart 等人,2013)中创建了两个由时间敏感的事实组成的时序数据集。在YAGO2中,元事实包含了所有为事实发生的时间。日期事实包含了实体的所有创建时间。首先,为了创建一个纯的时间敏感的数据集,其中所有的事实都有时间注释,我们选择了在元事实和数据事实中至少有2次提到的实体子集。这一结果导致了15914个三元组(四元组),随机分割的比例如表1所示。该数据集记为YG15k。其次,为了创建一个混合数据集,我们创建了YG36k,其中50%的事实有时间注释,50%没有。我们将根据要求公布这些数据。
3.2 链接预测
链接预测是在h、r或t缺失时补全三元组(h, r, t)。
3.2.1 实体预测
评估协议。对于每个缺少头实体或尾实体的测试三元组,将使用各种方法来计算所有候选实体的分数,并将它们按降序排列。我们使用两个指标来进行评估,如(Bordes等人,2013):正确实体排名的平均值(Mean Rank)和排名前10名的有效实体的比例(Hits@10)。正如在(Bordes 等人,2013)中提到的,当知识库中存在损坏的三元组时,这些指标是可取的,但却是有缺陷的。作为一种对策,我们在排序之前过滤掉了知识库中的所有这些有效的三元组。我们将第一个计算集命名为Raw,第二个计算集命名为Filter。
基线方法。为了进行比较,我们选择了TransE(Bordes等人,2013)、TransH(Wang等人,2014b)和TransR(Lin等人,2015b)等翻译方法作为我们的基线。然后基于这些方法使用时间感知嵌入,得到相应的时间感知嵌入模型。例如,一个具有时间感知嵌入的TransE模型被表示为“tTransE”。
实施细节。对于所有的方法,我们在每个数据集上创建了100个小批量。嵌入维数n设置在{20、50、100}范围内, 边缘γ1和γ2设置在{1、2、4、10}范围内。学习速率设置在{0.1、0.01、0.001}的范围内。正则化超参数λ在{10−1,10−2,10−3,10−4}中进行了调优。根据验证集中的平均排名来确定最佳配置。γ1=γ2=4,λ=10−2,学习率为0.001,取l1−范数。
结果表2报告了测试集上的结果。从结果中,我们可以看到,具有时间感知的嵌入方法在所有数据集和所有指标上都优于所有基线。这些改进通常是相当显著的。平均排名下降了约75%,而Hits@10上升了约19%到30%。这证明了我们的方法的优越性和通用性。在处理稀疏数据YG15k时,所有的时间信息都被用来对时间关联进行建模,使嵌入更加准确,因此在YG36k中比混合时间未知的三元组得到更好的改进。

3.2.2关系预测
关系预测的目的是预测给定的两个实体的关系。由于空间有限,仅对YG15K的评估结果见表3,我们报告了Hits@1而不是Hits@10。表4比较了TransE和tTransE的示例预测结果。例如,在测试(Billy_Hughes,?,London,1862)时,TransE很容易混合关系“wasBornIn”和”diedIn”,但知道(Billy_Hughes,isAffiliatedto,National_Labor_Party)发生在1916年,tTransE学习时间顺序,wasBornIn→isAffiliatedto→diedIn,所以正规化术语 ∣ r b o r n T − r a f f i l i a t e d ∣ |r_{born}T − r{affiliated}| ∣rbornT−raffiliated∣小于 ∣ r d i e d T − r a f f i l i a t e d ∣ |r_{died}T − r_{affiliated}| ∣rdiedT−raffiliated∣,所以正确答案“wasBornIn”排名高于”diedIn”。


3.3三元组分类
三元组分类的目的是判断一个看不见的三元组分类是否正确。
评估协议。我们遵循与Socher等人(2013年)相同的评估方案。为了创建用于分类的标记数据,对于测试和验证集中的每个三元组,我们通过随机破坏实体来构造一个相应的负三元组。要损坏一个位置(头部或尾部),只允许出现在该位置上的实体。在三元组分类过程中,如果分数低于特定于关系的阈值δr,则预测三元组为正;否则为负。我们报告了在测试集上的平均精度。
实施细节。我们使用与链接预测任务中相同的超参数设置。关系特定的阈值δr是通过最大化验证集上的平均精度来确定的。
结果表5报告了测试集上的结果。结果表明,时间感知嵌入始终优于所有基线。时间顺序信息可能有助于区分正、负三元组,因为不同的头实体可能有不同的时间相关关系。如果时间顺序与大多数事实相同,正则化项有助于它获得更低的能量,反之亦然。

4、相关工作
已提出许多KB嵌入模型(Nickel等,2011;Bordes等,2013;Socher等,2013)。外部信息被用来改进知识库的嵌入,如文本(Riedel等,2013;Wang等人,2014a;Zhao等人,2015)、实体类型和关系域(郭等人,2015;Chang等人,2014)和关系路径(Lin等人,2015a;Gu等人,2015)。然而,这些方法仅依赖于三元组事实,而忽略了事实之间的时间顺序约束。研究了文本中的关系排序等时间信息(Talukdar等,2012;钱伯斯等,2014;贝萨德,2013;卡西迪等人,2014;钱伯斯等人,2007;钱伯斯和尤拉夫斯基,2008年)。本文提出了一种利用时间顺序约束来改进知识库嵌入的时间感知嵌入方法。
5、结论和未来的工作
在本文中,我们提出了一种通用的时间感知知识库嵌入,它包含了实体的创建时间,并对嵌入空间的几何结构施加时间顺序约束,并使其在时间上更一致和更准确。作为未来的工作: (1)我们将纳入事实的有效时间。(2)在YAGO2中,一些对时间敏感的事实缺乏时间信息,我们将从文本中挖掘这些时间信息。
本研究由国家重点基础研究计划资助项目(2014CB340504)和国家自然科学基金资助项目(61375074,61273318)资助。
总结
本文在三元组的基础上添加了时间维度,形成四元组(h ,r, t, τ),表示(h ,r, t)这个事实在时间间隔或时间点τ时有效。本文还假设了先前的关系向量可以通过一个时间演化矩阵变成后续的关系向量,提出了TransE-TAE-ILP模型。
如下图所示,TransE-TAE-ILP模型使用时间演化矩阵M,用来捕获关系之间的时间顺序信息,如“wasbornin”可以演化为“diedin”。但是后续的关系向量不能演化为之前的关系向量,即“diedin”不能演化为“wasbornin”。这样,语义和时间信息一起被嵌入到连续的向量空间中。对于共享同一个头实体的两个四元组,为了使正确时间顺序的关系的损失比错误时间顺序的关系的损失低,本文还定义了一个关于时间顺序的损失函数:
g ( r i , r j ) = ∣ ∣ r i M − r j ∣ ∣ 1 g(r_i,r_j) = || r_iM-r_j ||_1 g(ri,rj)=∣∣riM−rj∣∣1
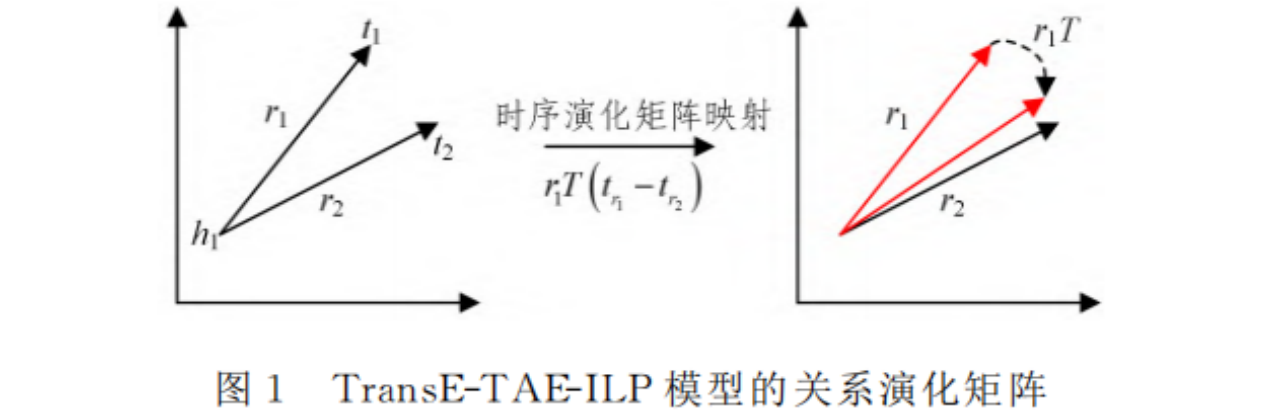
L = ∑ x + ∈ Δ [ ∑ x − ∈ Δ ′ [ γ 1 + f ( x + ) − f ( x − ) ] + + λ ∑ y + ∈ Ω e i , y − ∈ Ω e i ‘ [ γ 2 + g ( y + ) − g ( y − ) ] + ] L = \displaystyle \sum_{x^+∈\Delta} \left[\sum_{x^-∈ \Delta'}[\gamma_1+f(x^+)-f(x^-)]_++\lambda\sum_{y^+∈\Omega_{e_i},y^-∈\Omega_{e_i}^`}[\gamma_2+g(y^+)-g(y^-)]_+ \right] L=x+∈Δ∑⎣ ⎡x−∈Δ′∑[γ1+f(x+)−f(x−)]++λy+∈Ωei,y−∈Ωei‘∑[γ2+g(y+)−g(y−)]+⎦ ⎤
其中,Δ是合法三元组集合,Δ’是替换相应实体的错误三元组集合,对于四元组(ei, ri, ej, tx),y- =(rj,ri)∈Ωei’是通过对合法的时序关系对进行逆转操作构造的错误的时序关系对。
在对时序关系对进行建模的基础上,TransE-TAE-ILP考虑了3种时间一致性信息。
(1)时序不相交性:任何两个具有相同一对一关系以及相同头实体的事实的时间间隔是不能重叠的,例如一个人在一段时间内只能是另一个人的配偶。
(2)关系时间顺序:对于某些具有时间顺序的关系,一个事实三元组总会先于另一个事实三元组发生,例如一个人出生于某地肯定是发生在他毕业于某学校之前。
(3)时序范围性:有些事实仅在特定时间段内是正确的,超出该时间范围则无效。
TransE-TAE-ILP模型的方法也可以移植到TransH和TransR等模型。由于对于关系的演化过程进行了建模以及利用时间一致性信息进行了约束,TransE-TAE-ILP模型在实体预测、链接预测等问题上的性能均优于传统的TransE模型。自TransE-TAE-ILP模型被提出以来,越来越多的工作开始聚焦于时序知识图谱的表示学习,并对TransE-TAE-ILP模型进行改进与扩展。
基于翻译模型的方法可以灵活地对逆反关系(如“上位词”和“下位词”)、复合关系(如“父亲”和“母亲”和“丈夫”的复合关系)进行建模,但是无法对对称关系 (如“婚姻”)灵活建模

















 8350
8350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









