






SVM
KNN分类问题,离哪些点较近,就归哪一类
SVM分类问题,找决策边界,把数据进行划分开
SVM
机器学习的一般框架:
训练集 => 提取特征向量 => 结合一定的算法(分类器:比如决策树、KNN)=>得到结果
支持向量机(support vector machines,SVM)是一种二分类模型,它将实例的特征向量映射为空间中的一些点,SVM 的目的就是想要画出一条线,以 “最好地” 区分这两类点,以至如果以后有了新的点,这条线也能做出很好的分类。
基本概念
将实例的特征向量(以二维为例)映射为空间中的一些点,如下图的实心点和空心点,它们属于不同的两类。SVM 的目的就是想要画出一条线,以“最好地”区分这两类点,以至如果以后有了新的点,这条线也能做出很好的分类。
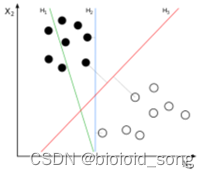
支持向量机
-
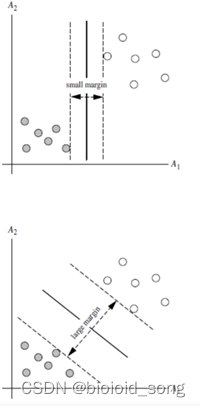
间隔(margin)是什么
对于任意一个超平面,其两侧数据点都距离它有一个最小距离(垂直距离),这两个最小距离的和就是间隔。以下两张图片中,两条虚线构成的带状区域就是 margin,虚线是由距离中央实线最近的两个点所确定出来的(也就是由支持向量决定)。第二张图的margin明显比第一张大很多,margin较大的更加接近我们的目标,因为大margin犯错的几率比较小。 -
支持向量是什么?
上图可以看出,虚线上的点到划分超平面的距离都是一样的,实际上只有这几个点共同确定了超平面的位置,因此被称作 “支持向量(support vectors)”,“支持向量机” 也是由此来的。 -
将两组数据划分开,怎么样的决策边界才会更好呢?
所谓决策边界就是能够把样本正确分类的一条边界,主要有线性决策边界(linear decision boundaries)和非线性决策边界(non-linear decision boundaries)。在上面的举例图中就是 划分超平面
支持向量要小的,要考虑里自己最近的雷才最安全
决策边界要大的,要最宽的道路才能行动的更快,更不容易踩雷 -
是先找支持向量,还是先找决策边界?
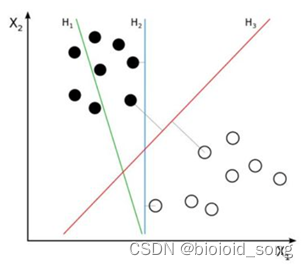
线性分类器:假设在一个二维线性可分的数据集中,我们要找到一个超平面把两组数据分开,已知的方法有我们已经学过的线性回归和逻辑回归,这条直线可以有很多种,如下图的H1、H2、H3哪一条直线的效果最好呢,也就是说哪条直线可以使两类的空间大小相隔最大呢?
我们凭直观感受应该觉得答案是H3。首先H1不能把类别分开,这个分类器肯定是不行的;H2可以,但分割线与最近的数据点只有很小的间隔,如果测试数据有一些噪声的话可能就会被H2错误分类(即对噪声敏感、泛化能力弱)。H3以较大间隔将它们分开,这样就能容忍测试数据的一些噪声而正确分类,是一个泛化能力不错的分类器。
因此我们把这个划分数据的决策边界就叫做超平面。离这个超平面最近的点就是”支持向量”,点到超平面的距离叫做间隔,支持向量机的意思就是使超平面和支持向量之间的间隔尽可能的大,这样才可以使两类样本准确地分开。
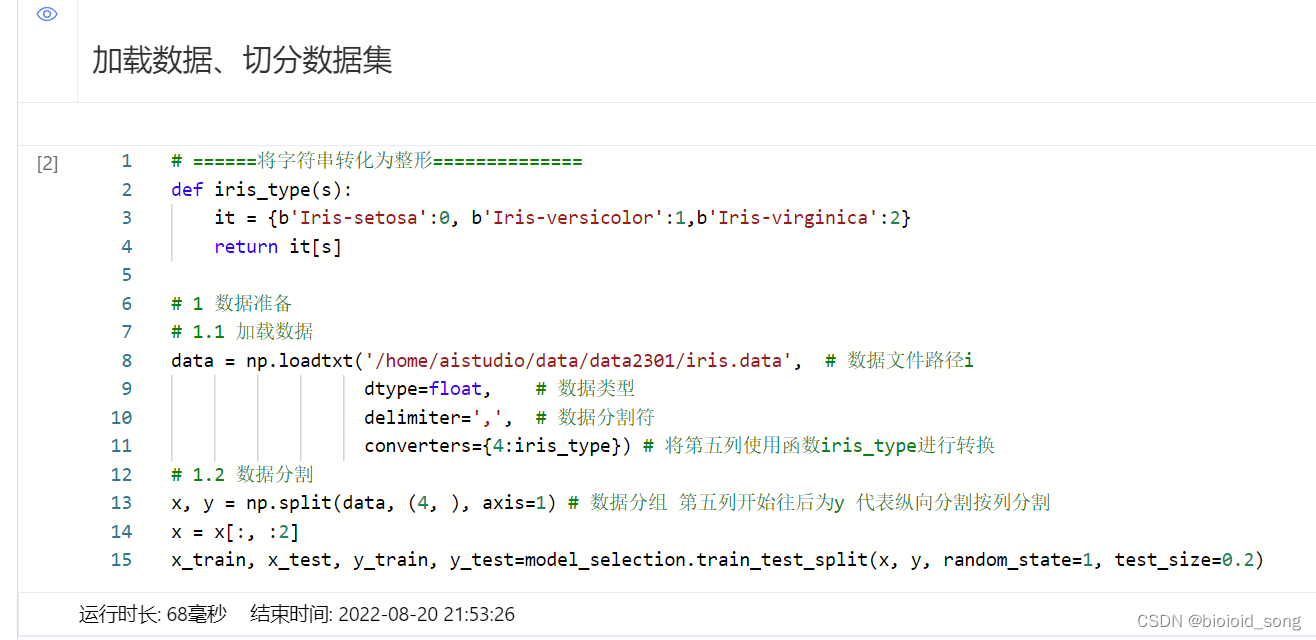
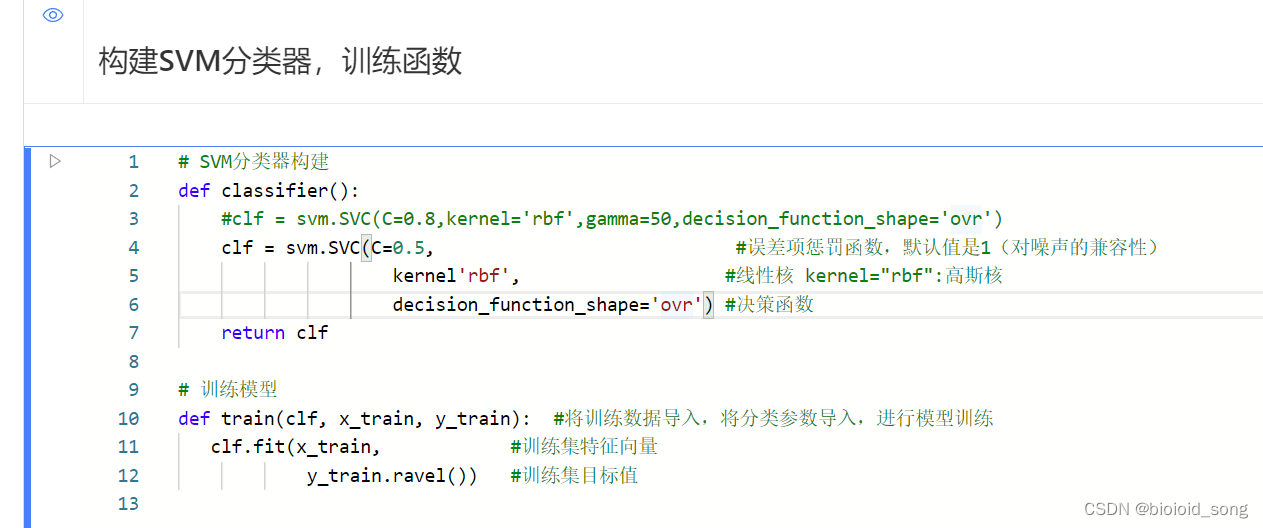
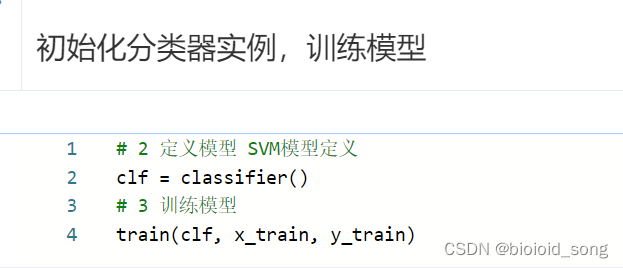
使用百度飞桨调用SVM代码
用 鸢尾花分类项目 进行测试。
















 820
820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









