









前言:
该项目已在AI Studio平台开源,喜欢的同学,欢迎fork哦:AI Studio项目链接
首先在这里说一下,由于这个项目在比赛期间更改过多次,所以在运行的过程中可能会出现一些小小的插曲,还望各位小伙伴们见谅!!!不过,请相信这些小插曲是很容易就能解决的。如果实在是不能解决,请及时联系我。我会在文章的末尾留下我的联系方式。
另外,还有一点是有必要提醒一下大家的:该项目可在AI Studio上直接运行,环境是由百度飞桨配置好了的。如果想在本地运行,需要自己配置好paddlepaddle的环境。最好是直接在AI Studio上运行,因为我同时把项目文件也压缩上传到AI Studio的数据集中了,方便使用。
然后展示一下该项目的一个跟踪效果:
下面展示MOT20_5中第五、六帧跟踪的效果。
第五帧、第六帧:


下面是测试集跟踪效果:
依次为第八帧、第九帧的效果:


一、项目说明:
1、总述:
再说明一下deep_sort_paddle项目里各个文件夹里的内容,以及作用:
在进行各模块的说明之前,首先先看一下整个项目的一个思维导图:

一、存放模型参数及网络结构的一些文件夹
1、ShuffleNet_ReID_paddle、ResNet_ReID_paddle、GhostNet_ReID_paddle,这三个文件夹中存放的是用于提取特征的相应的网络模型结构及参数。这三个网络的训练请参考———。
2、ppyolo_person、ppyolo_mot这两个文件夹里存放的是使用不同数据集训练得到的ppyolo模型参数及其配置文件。ppyolo网络的训练请参考该项目——————链接。
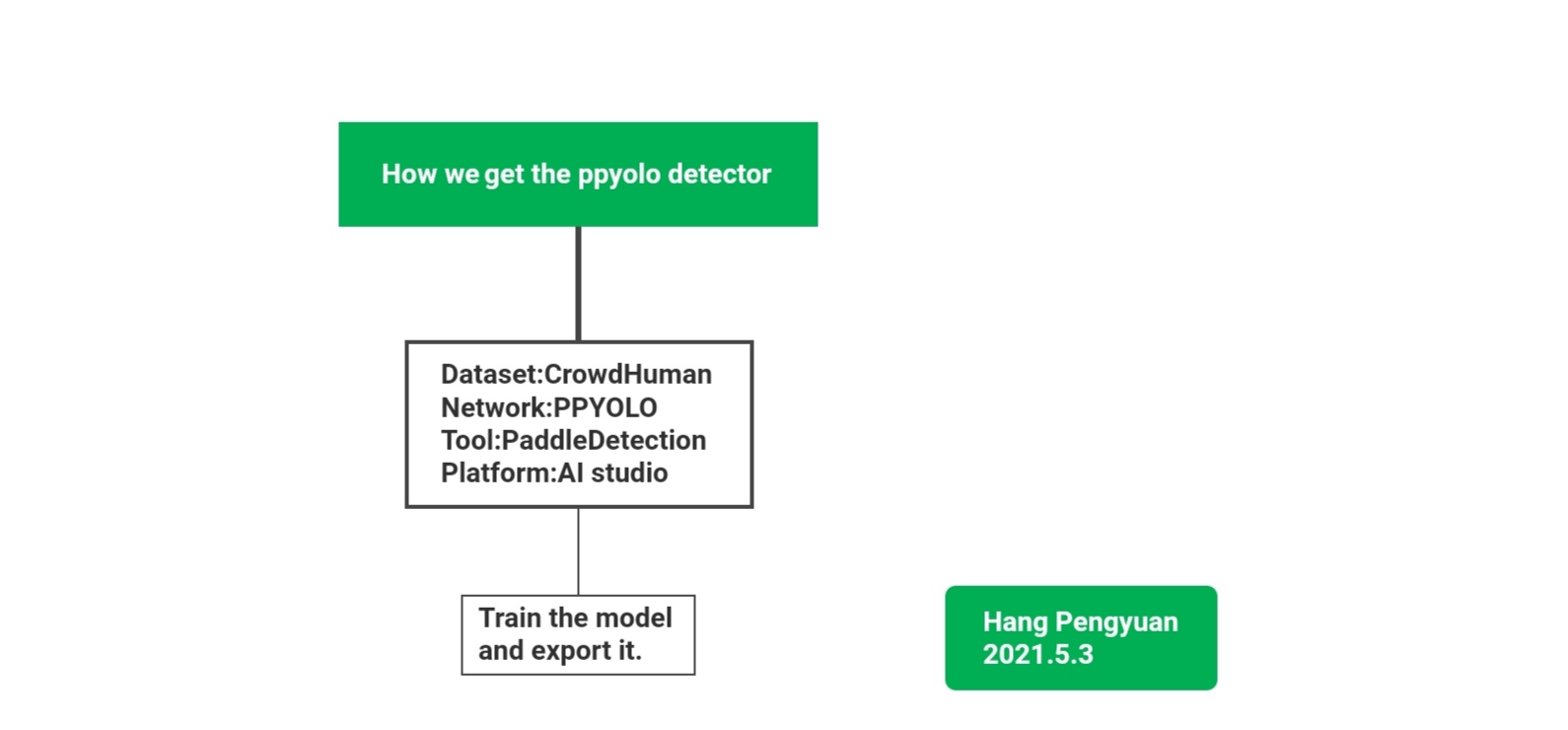
下面是行人检测模型训练的一个简单流程:
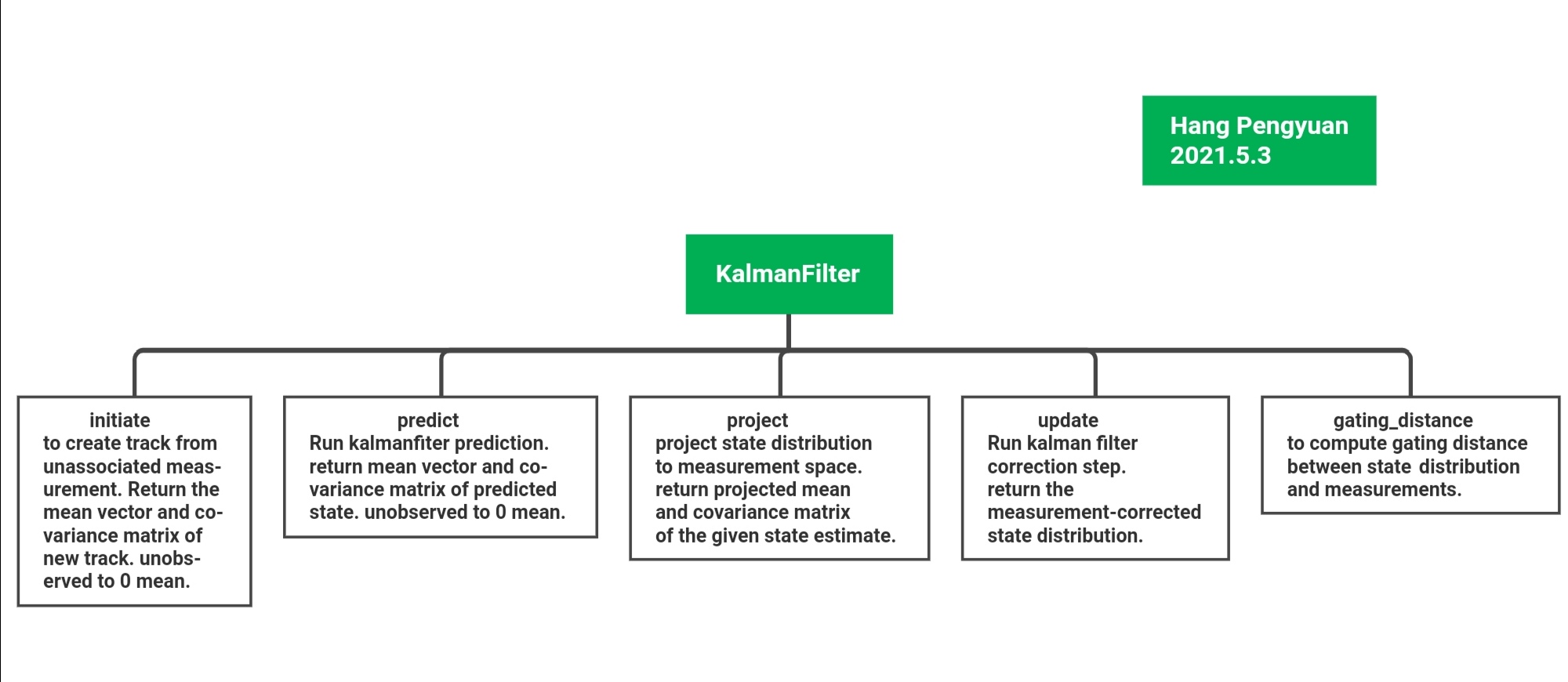
2、DeepSort算法的文件夹

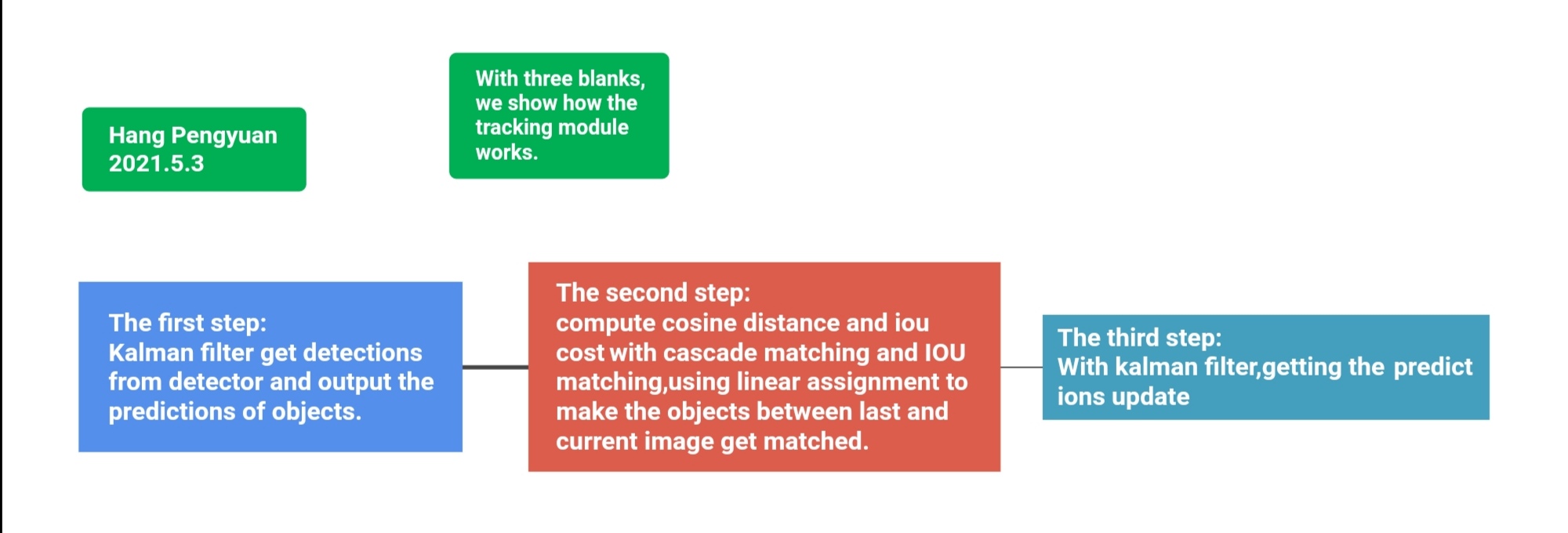
3、Tracking By Detection 最终的一些(.py)文件
1、detector_new.py
该程序是我们最初实验时用到的行人检测模型,我们直接调用了paddlehub中使用百度自建的大规模行人数据集训练,已经训练好的YOLO V3行人检测模型。该模型检测的准确性还是挺高的,使用起来也很简单快捷。但由于模型最初训练的时候,最终top_k只保留了前一百个结果,不满足线上赛“刷分的需求”,所以,它只作为我们的实验部分,仅供参考。
另外,值得一提的是,大家可以多尝试使用paddlehub中的模型来实现自己的小创意!!!还有就是,由于我们最初选择了Tracking By Detection这样的一个两阶段跟踪思路,而没有选择一些单阶段的一些网络(FairMOT)。由于是两阶段的任务,不同阶段可以尝试不同的方法,然后排列组合一下,hhhhhh,方法就更多了。线上赛中间有段时间,我们是想尝试把Detector换成目标分割模型来得到Detections的,但后来由于某些不可抗拒的因素,我们还没尝试就放弃了。有兴趣的小伙伴可以尝试一下哦!!!
2、preprocess_img.py
该程序包含多个图像预处理的类,是用来预处理图片的。即在PPYOLO进行推理之前先进行预处理。
3、Detector_ppyolo.py
该程序用来加载训练好的PPy的网络模型及参数,并完成正向的推理得到目标。
4、ppyolo.py
该程序用于完成目标检测并进行特征提取。ppyolo.py调用Detector_ppyolo.py里的Detector类来加载模型,使用predict方法来完成目标检测。同时调用extractor_new.py里的Extractor类来完成目标区域的特征提取。最后返回positions与features。
5、extractor_new.py
该程序里是一个Extractor类,传入加载好的ReID模型初始化(以提高整个算法的速度),然后通过传入目标图片进行特征的提取。
6、main_deepsort_new.py
该程序用于连接各模块,最终实现行人跟踪。
二、“处理一下”要跑的数据集:
#第一步、解压MOT20数据集
!unzip -oq /home/aistudio/data/data77171/MOT20.zip
#由于该工程项目中的文件较多,所以我们打包成了压缩包上传,比较方便。
#第二步、解压一下该工程项目
#不过,后来,精简了一下,可以了,下面这个可以不用了。
#!unzip -oq /home/aistudio/data/data86710/deep_sort_paddle.zip
#为了跑完最后的官方发布的测试数据集而写:
!unzip -oq /home/aistudio/data/data87776/mot_images.zip
"""
我来解释一下这个小脚本的作用:它是用来生成一个txt文件的。
生成一个什么样的txt文件呢?生成一个存放了MOT20测试集或训练集图片路径的txt文件。
为什么要生成这样的一个文件呢?这里是为了满足mian_deepsort_new.py的需求。打开该文件(main_deepsort_new.py)就能满足你的好奇心。
参数:
train_txt_root_img是最终存放txt文件的根地址
train_img_root_dir是存放MOT20数据集图片的根地址
"""
import os
#train_txt_root_dir = 'deep_sort_paddle/MOT_train_txt'
train_txt_root_dir = 'deep_sort_paddle/Final_test'
#train_img_root_dir = 'MOT20'
train_img_root_dir = 'mot_images'
"""def generate_txt_file(root_path, train_txt_root_file):
img_dirs = []
for type_img in os.listdir(root_path):
if type_img == 'train':
MOT_path = '{}/{}'.format(root_path, type_img)
for MOT_dir in os.listdir(MOT_path):
img1_dir = '{}/{}'.format(MOT_path, MOT_dir)
with open('{}/{}.txt'.format(train_txt_root_dir, MOT_dir), 'w') as f:
for img1 in os.listdir(img1_dir):
if img1 == 'img1':
img_path = '{}/{}'.format(img1_dir, img1)
for img_dir in os.listdir(img_path):
img_dirs.append(img_dir)
len_ = len(img_dirs)
for i in range(1, len_+1):
#print(i)
i = str('%06d'%i)
img_dir = '{}/{}.jpg'.format(img_path, i)
f.write('{}\n'.format(img_dir))
img_dirs = []
else:
pass"""
def generate_txt_file(root_path, train_txt_root_file):
for_lens = []
for img_files in os.listdir(root_path):
img_file = "{}/{}".format(root_path, img_files)
print(img_file)
with open('{}/{}.txt'.format(train_txt_root_dir, img_files), 'w') as f:
for for_len in os.listdir(img_file):
for_lens.append(for_len)
len_ = len(for_lens)
for i in range(1, len_+1):
i = str('%05d'%i)
img_dir = '{}/{}.jpg'.format(img_file, i)
f.write("{}\n".format(img_dir))
for_lens = []
generate_txt_file(train_img_root_dir, train_txt_root_dir)
三、使用PaddleHub进行的小尝试:
这段代码是调用了paddlehub中已经训练好了的行人检测模型,检测效果挺好,使用起来也比较简单,鼓励尝试paddlehub,然后修改插入到该项目中。(第一次实验阶段尝试的)
这里从Detector_new.py中拿出来只是为了测试使用的。
import paddlehub as hub
import cv2
import time
import os
import numpy as np
#os.environ['CUDA_VISIBLE_DEVICES'] = '0'
object_detector = hub.Module(name="yolov3_darknet53_pedestrian")
#object_detector = hub.Module(name="faster_rcnn_resnet50_fpn_coco2017")
time_ = time.time()
k = 0
img = cv2.imread("mot_images/0/00278.jpg")
results = object_detector.object_detection(images=[img], use_gpu=False, score_thresh=0.00)
for result in results[0]['data']:
if result['label'] == 'pedestrian':
k += 1
print(k)
print(results)
time__ = time.time()
print(time__-time_)
在实验阶段,我们还有尝试使用MOT20数据集以及CrowdHuman数据集来训练CenterNet,但由于最终效果不好,我们并没有使用该检测模型。下面这段代码现在是不能够运行的,因为我把CenterNet从该项目中移除了。
from PIL import Image
from deep_sort_paddle.CenterNet.centernet import CenterNet
centernet = CenterNet()
import matplotlib.pyplot as plt
from PIL import Image
%matplotlib inline
save_path = 'deep_sort_paddle/CenterNet/inference_test/3.jpg'
img = 'MOT20/train/MOT20-03/img1/000245.jpg'
image = Image.open(img)
_image, boxs, confidences = centernet.detect_image(image)
_image.save(save_path)
plt.imshow(_image)
plt.show()
print(boxs)
image)
_image.save(save_path)
plt.imshow(_image)
plt.show()
print(boxs)
print(confidences)
四、行人跟踪:
最后,运行该程序来完成行人跟踪!!!
!python deep_sort_paddle/main_deepsort_new.py
五、跨镜头的目标跟踪:
我们正在做这个项目,先不要着急哦,后面会第一时间在AI Studio上公开的哦!!!
最后来个自我介绍:(欢迎小伙伴们关注我哦!!!)
我是一名热爱计算机视觉的小白一枚,现就读于成都信息工程大学电子信息科学与技术专业。
再说点无聊的废话吧:我希望自己能够永远保持自己的热情,并且能够保持简单纯粹的思想理念,像个孩子那样保持着好奇。所以我的ID及其他一些ID,均命名为韩三岁或者HanSansui等。
该项目已在AI Studio平台开源:















 3012
3012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









