






0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解及成果,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
You Only Look Once(YoLo)是当前在目标检测领域中备受瞩目的实时检测算法。相比于其他算法,YoLo在保持高速度的同时,进一步提升了检测精度。本文将深入探讨YoLo V4模型的训练过程,帮助读者理解其背后的技术原理和实践细节。
1. YoLo V4模型概述
YoLo V4在前代基础上整合了大量优化策略,如Mish激活函数、CSPNet结构、SPP模块以及多尺度特征融合等,以提升模型性能。模型的整体架构采用“Backbone-Neck-Head”的经典设计,其中Backbone用于提取丰富的底层到高层语义特征,Neck部分进行跨层特征融合,Head负责输出预测框及其置信度。
2. 训练准备
-
数据集准备:YoLo V4通常在大型图像数据集上进行训练,如COCO数据集,包含丰富的物体类别和各种场景。首先需要对数据集进行预处理,包括划分训练集、验证集和测试集,标注出图像中的目标位置与类别信息。
-
模型初始化:YoLo V4的部分组件如Backbone可以选择预训练权重(如Darknet-53),以便于模型快速收敛并提高最终性能。
-
损失函数设定:YoLo V4使用多任务损失函数,包括分类损失、定位损失和置信度损失。其中,定位损失采用了改进后的IoU loss(GIOU, CIoU或DIoU)以更好地优化边界框的位置预测。
3. 训练过程思路
-
模型训练:在PyTorch或TensorFlow等深度学习框架下搭建YoLo V4网络结构,设置好学习率、优化器(如Adam)以及批次大小等参数后启动训练过程。通过反向传播计算梯度,并应用梯度下降法更新网络权重。
-
训练策略:YoLo V4采用了分阶段训练策略,先训练Backbone,然后逐步加入 Neck 和 Head 部分进行联合训练,这样的渐进式训练有助于模型稳定收敛。
-
学习率调整:YoLo V4在训练过程中采用余弦退火策略调整学习率,使得模型在初始阶段能较快收敛,在后期又能精细优化参数。
-
早停策略:根据验证集上的性能指标(如mAP),当模型性能不再显著提升时,提前终止训练,避免过拟合。
4. 训练技巧与优化
-
数据增强:在训练过程中利用随机翻转、裁剪、缩放、颜色抖动等数据增强技术,可以有效增加模型泛化能力。
-
Batch Normalization:在各卷积层后添加BN层,能够加速模型训练速度并改善模型性能。
-
多尺度训练:在训练过程中动态改变输入图像尺寸,模拟不同尺度的目标检测,进一步提升模型在实际场景下的表现。
5. 训练示例
5.1 配置超参数
需要配置的超参数如下:
在机器学习中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。
#这里只列举一部分参数
batch=64
subdivisions=64
width=608
height=608
channels=3
momentum=0.949
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=0.1
mixup=1
epoch和batch的区别:神经网络中Batch和Epoch之间的区别
5.2 build_target
简单来说,这一步就是建立YoLo学习的标准,用于训练模型参数。分为以下六个步骤:


5.3 损失函数计算
损失函数计算流程:
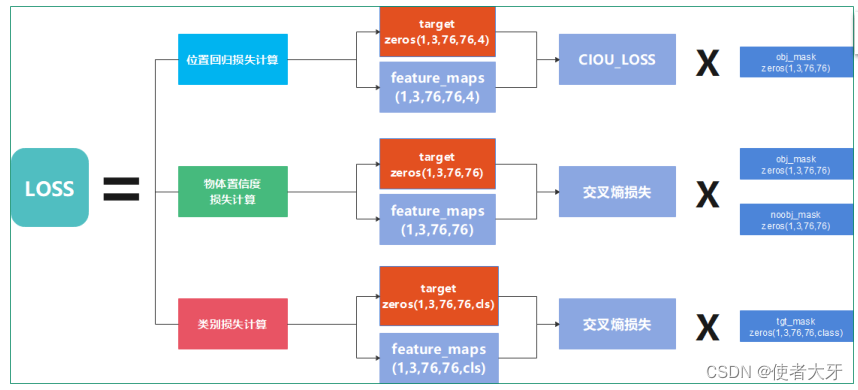
IoU的全称为交并比(Intersection over Union),是目标检测中使用的一个概念,IoU计算的是“预测的边框”和“真实的边框”的交叠率-,即它们的交集和并集的比值。最理想情况是完全重叠,即比值为1
位置回归损失使用的就是IoU
损失函数算法:
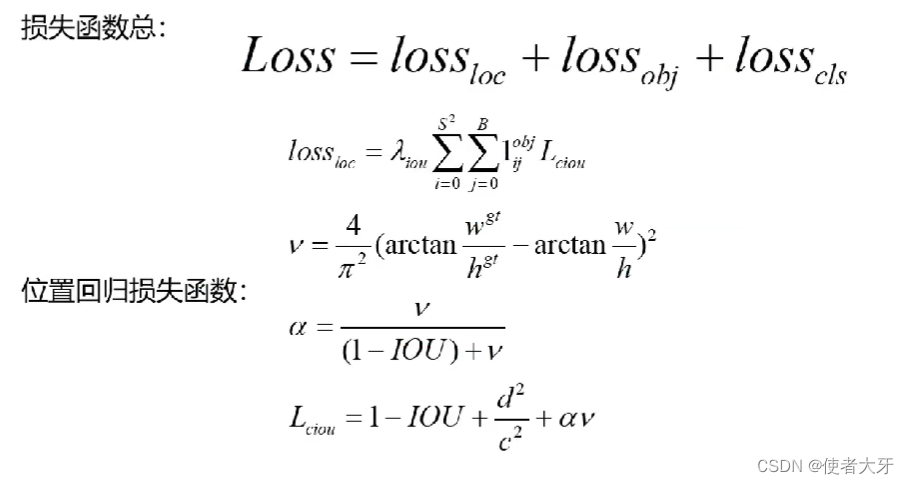
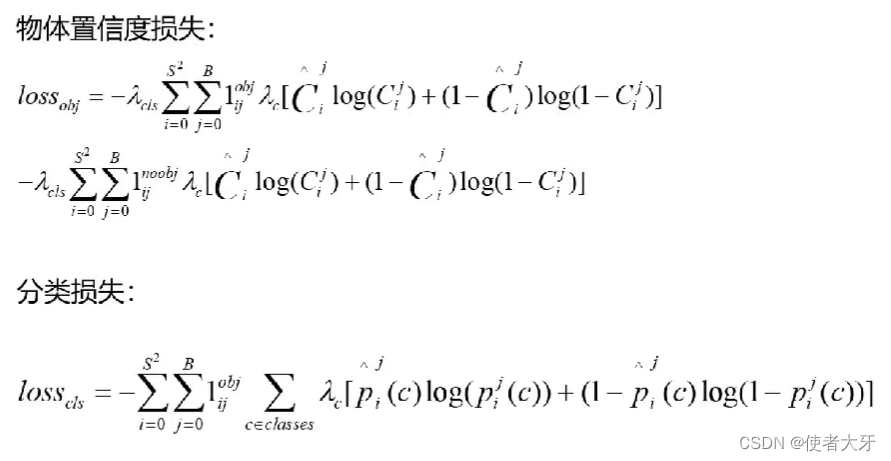
6. 结语
YoLo V4模型的训练过程是一个结合了多种深度学习优化策略和技术的过程。理解并掌握这些关键环节,不仅能让我们更好地运用YoLo V4解决实际问题,还能启发我们在未来的研究和实践中探索更多创新的可能性。















 422
422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











