







文章目录
0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解及成果,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
在此前文章【单点知识】基于PyTorch讲解自动编码器(Autoencoder)中已经介绍了自动编码器,本文将再继续介绍自动编码器的变种——变分自动编码器VAE。
1 为什么需要自动变分编码器?
变分自动编码器(VAE)是Diederik P. Kingma和Max Welling在2013年提出的(原文:https://arxiv.org/pdf/1312.6114)。VAE通过引入概率模型来生成数据。编码器输出的是一个概率分布(通常为高斯分布),解码器从这个分布中采样生成数据。
回忆我们之前说明的自动编码器的原理:编码器将输入数据 x x x映射到一个低维的编码表示 z z z,即 g ϕ ( x ) = z g_{\phi}(x)=z gϕ(x)=z,这里 z z z(也称隐变量,潜在变量)是一个固定的值(或者向量,或者矩阵),这就非常影响生成的多样性。
而VAE是一种生成模型,结合了自动编码器(Autoencoder)的思想和概率图模型的概念。与传统的自动编码器不同,VAE 不仅学习数据的压缩表示,还通过引入概率分布来生成新的数据样本。VAE 在生成模型领域有着广泛的应用,特别是在图像生成、文本生成和数据增强等方面。
举个例子:如果没有自动变分编码器,那我们向现在的文生图AI工具输入“请画一只猫”,那AI工具永远只会生成一只固定的猫。而有了自动变分编码器,AI工具就可以输出黑猫、白猫、长毛猫、短毛猫等各种猫。
2. VAE工作原理
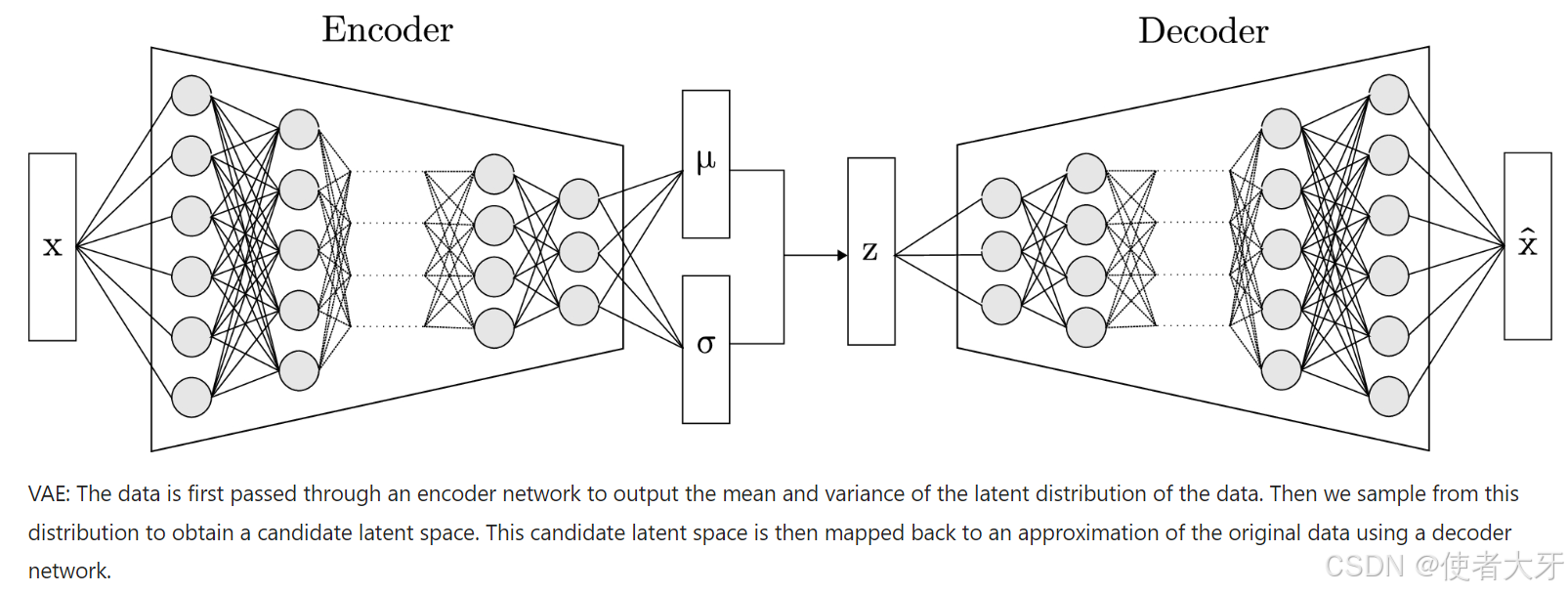
2.1 编码器(Encoder)
编码器将输入数据 x x x映射到一个潜在空间中的概率分布参数。具体来说,编码器输出两个向量:均值 μ \mu μ 和方差 σ \sigma σ。这两个向量定义了一个高斯分布 q ϕ ( z ∣ x ) q_{\phi}(z|x) qϕ(z∣x),其中 z z z 是潜在变量,这个分布表示了给定输入数据 x x x时,潜在变量 z z z的概率分布。
2.2 重参数化技巧(Reparameterization Trick)
为了使潜在变量
z
z
z可以通过梯度下降进行优化,VAE 使用重参数化技巧。具体来说,从标准正态分布
N
(
0
,
1
)
\mathcal{N}(0, 1)
N(0,1) (均值为0,标准差为1)中采样一个随机变量
ϵ
\epsilon
ϵ,然后通过以下公式生成
z
z
z:
z
=
μ
+
σ
⋅
ϵ
z = \mu + \sigma \cdot \epsilon
z=μ+σ⋅ϵ
这样,
z
z
z 的梯度可以通过
μ
\mu
μ 和
σ
\sigma
σ传递,从而实现端到端的训练。
2.3 解码器(Decoder)
解码器将潜在变量 z z z映射回原始数据空间,生成重构数据 x ′ x' x′。解码器的目标是最小化重构数据 x ′ x' x′和原始数据 x x x之间的差异,通常使用均方误差(MSE)或交叉熵损失函数。
3. 损失函数
变分自动编码器(VAE)的损失函数由两部分组成:重构损失(Reconstruction Loss)和KL散度(Kullback-Leibler Divergence)。这两部分共同指导模型的学习过程,确保生成的样本既忠实于输入数据又具有多样性。
3.1 重构损失(Reconstruction Loss)
重构损失衡量的是模型生成的重构数据 x ′ x' x′与原始输入数据 x x x 之间的差异。常用的重构损失函数包括:
-
均方误差(Mean Squared Error, MSE):
L recon = 1 N ∑ i = 1 N ( x i − x i ′ ) 2 \mathcal{L}_{\text{recon}} = \frac{1}{N} \sum_{i=1}^{N} (x_i - x'_i)^2 Lrecon=N1i=1∑N(xi−xi′)2
其中 ( N ) 是数据点的数量。 -
二元交叉熵(Binary Cross-Entropy):
L recon = − 1 N ∑ i = 1 N [ x i log x i ′ ) + ( 1 − x i ) log ( 1 − x i ′ ) ] \mathcal{L}_{\text{recon}} = -\frac{1}{N} \sum_{i=1}^{N} \left[ x_i \log x'_i) + (1 - x_i) \log(1 - x'_i) \right] Lrecon=−N1i=1∑N[xilogxi′)+(1−xi)log(1−xi′)]
适用于二值数据或概率分布。
3.2 KL 散度(Kullback-Leibler Divergence)
KL 散度衡量的是编码器生成的潜在分布 q ϕ ( z ∣ x ) q_{\phi}(z|x) qϕ(z∣x) 与先验分布 p ( z ) p(z) p(z) 之间的差异。在 VAE 中,先验分布 p ( z ) p(z) p(z) 通常选择为标准正态分布 N ( 0 , 1 ) \mathcal{N}(0, 1) N(0,1)。
对于高斯分布
q
ϕ
(
z
∣
x
)
=
N
(
μ
,
σ
2
)
q_{\phi}(z|x) = \mathcal{N}(\mu, \sigma^2)
qϕ(z∣x)=N(μ,σ2),KL 散度可以表示为:
KL
(
q
ϕ
(
z
∣
x
)
∥
p
(
z
)
)
=
1
2
∑
i
=
1
D
(
σ
i
2
+
μ
i
2
−
1
−
log
(
σ
i
2
)
)
\text{KL}(q_{\phi}(z|x) \| p(z)) = \frac{1}{2} \sum_{i=1}^{D} \left( \sigma_i^2 + \mu_i^2 - 1 - \log(\sigma_i^2) \right)
KL(qϕ(z∣x)∥p(z))=21i=1∑D(σi2+μi2−1−log(σi2))
其中
D
D
D 是潜在变量
z
z
z 的维度,
μ
i
\mu_i
μi 和
σ
i
\sigma_i
σi 分别是编码器输出的均值和标准差。
3.3 总的损失函数
VAE 的总损失函数是重构损失和KL散度的加权和:
L
=
L
recon
+
β
⋅
KL
(
q
ϕ
(
z
∣
x
)
∥
p
(
z
)
)
\mathcal{L} = \mathcal{L}_{\text{recon}} + \beta \cdot \text{KL}(q_{\phi}(z|x) \| p(z))
L=Lrecon+β⋅KL(qϕ(z∣x)∥p(z))
其中
β
\beta
β 是一个超参数,用于平衡重构损失和KL散度的影响。通常情况下,
β
=
1
\beta = 1
β=1,但在某些变体中,
β
\beta
β可以调整以改变模型的行为。
4. 总结
VAE通过引入概率分布和重参数化技巧,不仅能够学习数据的高效表示,还能生成新的数据样本。VAE 在生成模型领域有着广泛的应用,特别是在需要生成高质量新样本的任务中表现出色。


















 5284
5284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











