







参考链接
Certainly! Binary Cross Entropy (BCE) is a loss function commonly used in binary classification problems. It measures the difference between the predicted probabilities and the true labels for each example in your dataset. BCE is often used in conjunction with a sigmoid activation function, where the output is interpreted as the probability of belonging to the positive class.
Here’s a step-by-step explanation of how to calculate BCE:
-
Sigmoid Activation:
- The raw output (logit) from your model is passed through a sigmoid activation function to squash it between 0 and 1. The sigmoid function is defined as:
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
where ( x ) is the raw output.
This transforms the raw output into a probability.
-
Cross Entropy for Binary Classification:
-
The BCE loss for a single example is calculated using the formula:
BCE ( y , y ^ ) = − ( y ⋅ log ( y ^ ) + ( 1 − y ) ⋅ log ( 1 − y ^ ) ) \text{BCE}(y, \hat{y}) = -\left(y \cdot \log(\hat{y}) + (1 - y) \cdot \log(1 - \hat{y})\right) BCE(y,y^)=−(y⋅log(y^)+(1−y)⋅log(1−y^))where:
- y y y is the true label (0 or 1).
- y ^ \hat{y} y^ is the predicted probability.
This formula penalizes the model more when the predicted probability deviates from the true label.
-
-
Average Loss Across Examples:
-
If you have a batch of examples, the average BCE loss is often calculated across the batch. This helps in training models with different batch sizes.
BCE avg = 1 N ∑ i = 1 N BCE ( y i , y ^ i ) \text{BCE}_{\text{avg}} = \frac{1}{N} \sum_{i=1}^{N} \text{BCE}(y_i, \hat{y}_i) BCEavg=N1∑i=1NBCE(yi,y^i)
where ( N ) is the number of examples in the batch.
-
Here’s a simple Python example using PyTorch:
import torch
import torch.nn.functional as F
# Assuming sigmoid output from your model and true labels
sigmoid_output = torch.sigmoid(torch.randn(5)) # Simulating sigmoid output
true_labels = torch.randint(0, 2, (5,), dtype=torch.float) # Simulating true labels (0 or 1)
# BCE loss calculation
bce_loss = F.binary_cross_entropy(sigmoid_output, true_labels)
print("Sigmoid Output:", sigmoid_output)
print("True Labels:", true_labels)
print("BCE Loss:", bce_loss.item())
Sigmoid Output: tensor([0.4269, 0.1823, 0.6322, 0.6996, 0.6750])
True Labels: tensor([1., 0., 0., 1., 1.])
BCE Loss: 0.5605617165565491
In this example, sigmoid_output represents the predicted probabilities, and true_labels represents the true labels. The F.binary_cross_entropy function is used to calculate the BCE loss. The goal during training is to minimize this loss using techniques like gradient descent.
nn.CrossEntropyLoss() and nn.BCEWithLogitsLoss()
-
nn.CrossEntropyLoss:- This loss function is commonly used for multi-class classification problems.
- It expects raw scores (logits) for each class and the target labels (class indices).
- It combines a softmax activation and the negative log-likelihood loss in a single function.
- In the case of
nn.CrossEntropyLoss, you don’t need to explicitly apply softmax activation to your model’s output; the loss function takes care of that internally. - The target should be class indices (integers), and it assumes that each sample belongs to exactly one class.
Example:
criterion = nn.CrossEntropyLoss() logits = model(x) # Raw scores from the model loss = criterion(logits, labels) # Labels are class indices -
nn.BCEWithLogitsLoss:- This loss function is commonly used for binary classification problems.
- It’s suitable when each sample can belong to multiple classes (binary classification for each class independently).当每个样本可以属于多个类(每个类独立地进行二进制分类)时,这种方法是合适的。(PET预测脑疾病的两两二分类进行三分类或许可以用这个)
- It works with raw scores (logits) without applying a sigmoid activation function.
- It combines a sigmoid activation and binary cross-entropy loss in a single function.
- The target should be binary labels (0 or 1), indicating the presence or absence of each class.
Example:
criterion = nn.BCEWithLogitsLoss() logits = model(x) # Raw scores from the model loss = criterion(logits, labels) # Labels are binary (0 or 1)
交叉熵损失函数计算所提供的一组数据或随机变量的两个概率分布之间的差异。
因为交叉熵描述了两个概率分布的差异,然而神经网络输出的是向量,并不是概率分布的形式。所以需要 softmax激活函数将一个向量进行“归一化”成概率分布的形式,再采用交叉熵损失函数计算 loss。
本质上也是一种对数似然函数,可用于二分类和多分类任务中。
二分类问题中的loss函数(输入数据是softmax或者sigmoid(它的值域为(0, 1),刚好可以作为分类问题的预测结果为1的概率。)函数的输出):
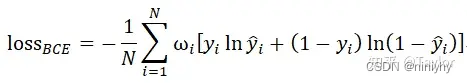
函数:torch. nn.BCELoss torch.nn.BCEWithLogitsLoss
多分类问题中的loss函数(输入数据通常是softmax函数的输出):
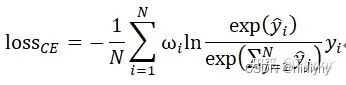
其中,N是多分类种类数。
函数:torch.nn.CrossEntropyLoss
在nn.CrossEntropyLoss()的代码实现中,实际是使用了log_softmax和nll_loss的组合:
return nll_loss(log_softmax(input,1),target,…)
与nn.CrossEntropyLoss对应的是nn.BCEWithLogitsLoss()
nn.BCELoss0不带sigmoid激活















 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









