







【HUMANNORM: 学习高质量和逼真的3D人体生成的法线扩散模型】阅读笔记
HUMANNORM: LEARNING NORMAL DIFFUSION MODEL FOR HIGH-QUALITY AND REALISTIC 3D HUMAN GENERATION 原文
项目主页
前置知识
扩散模型
扩散模型有两个过程,分别为扩散过程(前向过程)和逆扩散过程(后向过程)。
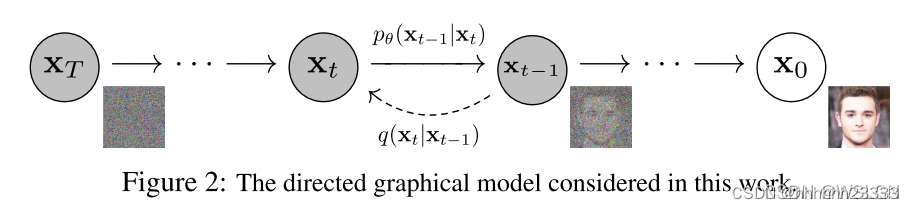
- 扩散过程为从右到左 ( X 0 → X T ) (X_0 \rightarrow X_T) (X0→XT)的过程,表示对图片逐渐加噪,且 X t + 1 X_{t+1} Xt+1是在 X t X_{t} Xt上加躁得到的,其只受 X t X_t Xt的影响,因此扩散过程是一个马尔科夫过程。 X 0 X_0 X0表示从真实数据集中采样得到的一张图片,对 X 0 X_0 X0添加 T T T次噪声,图片逐渐变得模糊,当 T T T足够大时, X T X_T XT为标准正态分布。在训练过程中,每次添加的噪声是已知的,即 q ( X t ∣ X t − 1 ) q(X_t|X_{t-1}) q(Xt∣Xt−1)是已知的,根据马尔科夫过程的性质,我们可以递归得到 q ( X t ∣ X 0 ) q(X_t|X_0) q(Xt∣X0),即 q ( X t ∣ X 0 ) q(X_t|X_0) q(Xt∣X0)是已知的。扩散过程最主要的就是 q ( X t ∣ X 0 ) q(X_t|X_0) q(Xt∣X0)和 q ( X t ∣ X t − 1 ) q(X_t|X_{t-1}) q(Xt∣Xt−1)的推导
- 逆扩散过程为从左到右
(
X
T
→
X
0
)
(X_T \rightarrow X_0)
(XT→X0)的过程,表示从噪声中逐渐复原出图片。如果我们能够在给定
X
t
X_t
Xt条件下知道
X
t
−
1
X_{t-1}
Xt−1的分布,即如果我们可以知道
q
(
X
t
−
1
∣
X
t
)
q(X_{t-1}|X_t)
q(Xt−1∣Xt),那我们就能够从任意一张噪声图片中经过一次次的采样得到一张图片而达成图片生成的目的。显然我们很难知道
q
(
X
t
−
1
∣
X
t
)
q(X_{t-1}|X_t)
q(Xt−1∣Xt),因此我们才会用
p
Θ
(
X
t
−
1
∣
X
t
)
p_{Θ}(X_{t-1}|X_t)
pΘ(Xt−1∣Xt)来近似
q
(
X
t
−
1
∣
X
t
)
q(X_{t-1}|X_t)
q(Xt−1∣Xt),
p
Θ
(
X
t
−
1
∣
X
t
)
p_{Θ}(X_{t-1}|X_t)
pΘ(Xt−1∣Xt)就是我们要训练的网络,在原文中就是个U-Net。而很妙的是,虽然我们不知道
q
(
X
t
−
1
∣
X
t
)
q(X_{t-1}|X_t)
q(Xt−1∣Xt),但是
q
(
X
t
−
1
∣
X
t
X
0
)
q(X_{t-1}|X_tX_0)
q(Xt−1∣XtX0)却是可以用
q
(
X
t
∣
X
0
)
q(X_t|X_0)
q(Xt∣X0)和
q
(
X
t
∣
X
t
−
1
)
q(X_t|X_{t-1})
q(Xt∣Xt−1)表示的:
q ( X t − 1 ∣ X t X 0 ) = q ( X 0 X t − 1 X t ) q ( X 0 X t ) = q ( X 0 X t − 1 X t ) q ( X 0 X t − 1 ) q ( X 0 X t − 1 ) q ( X 0 X t ) = q ( X t ∣ X t − 1 X 0 ) ∗ q ( X t − 1 ∣ X 0 ) q ( X t ∣ X 0 ) 由扩散过程是马尔科夫过程知 q ( X t ∣ X t − 1 X 0 ) = q ( X t ∣ X t − 1 ) 故 q ( X t − 1 ∣ X t X 0 ) = q ( X t ∣ X t − 1 ) ∗ q ( X t − 1 ∣ X 0 ) q ( X t ∣ X 0 ) q(X_{t-1}|X_tX_0)= \frac{q(X_0X_{t-1}X_t)}{q(X_0X_t)}= \frac{q(X_0X_{t-1}X_t)}{q(X_0X_{t-1})} \frac{q(X_0X_{t-1})}{q(X_0X_t)}=q(X_t|X_{t-1}X_0) * \frac{q(X_{t-1}|X_0)}{q(X_t|X_0)} \\ 由扩散过程是马尔科夫过程知q(X_t|X_{t-1}X_0)=q(X_t|X_{t-1}) \\ 故q(X_{t-1}|X_tX_0)=q(X_t|X_{t-1}) * \frac{q(X_{t-1}|X_0)}{q(X_t|X_0)} q(Xt−1∣XtX0)=q(X0Xt)q(X0Xt−1Xt)=q(X0Xt−1)q(X0Xt−1Xt)q(X0Xt)q(X0Xt−1)=q(Xt∣Xt−1X0)∗q(Xt∣X0)q(Xt−1∣X0)由扩散过程是马尔科夫过程知q(Xt∣Xt−1X0)=q(Xt∣Xt−1)故q(Xt−1∣XtX0)=q(Xt∣Xt−1)∗q(Xt∣X0)q(Xt−1∣X0)
即 q ( X t − 1 ∣ X t X 0 ) q(X_{t-1}|X_tX_0) q(Xt−1∣XtX0)是可知的,因此我们可以用 q ( X t − 1 ∣ X t X 0 ) q(X_{t-1}|X_tX_0) q(Xt−1∣XtX0)来指导 p Θ ( X t − 1 ∣ X t ) p_{Θ}(X_{t-1}|X_t) pΘ(Xt−1∣Xt)进行训练。逆扩散过程最主要的就是 q ( X t − 1 ∣ X t X 0 ) q(X_{t-1}|X_tX_0) q(Xt−1∣XtX0)的推导。 - 训练
p
Θ
(
X
t
−
1
∣
X
t
)
p_{Θ}(X_{t-1}|X_t)
pΘ(Xt−1∣Xt)的目标函数:常见两种是负对数的最大似然概率,即
−
l
o
g
p
Θ
(
X
0
)
-logp_{Θ}(X_0)
−logpΘ(X0),或真实分布与预测分布的交叉熵,即
−
E
q
(
X
0
)
l
o
g
p
Θ
(
X
0
)
-E_{q(X_0)}logp_{Θ}(X_0)
−Eq(X0)logpΘ(X0),而显然这两种都不好搞,因此参考了VAE不去优化这两个东西,而是优化他们的变分上界(variational lower bound),定义
L
V
L
B
L_{VLB}
LVLB如下:
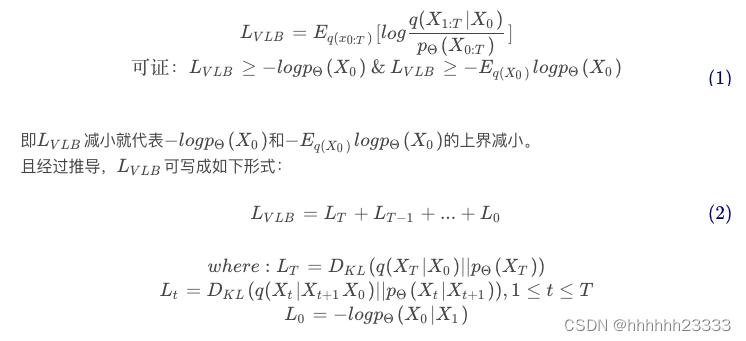
L t L_t Lt就是逆扩散过程中 q ( X t ∣ X t + 1 X 0 ) q(X_{t}|X_{t+1}X_0) q(Xt∣Xt+1X0)和 p Θ ( X t ∣ X t + 1 ) p_{Θ}(X_{t}|X_{t+1}) pΘ(Xt∣Xt+1)的KL散度(度量两个概率分布之间差异),即用 q ( X t ∣ X t + 1 X 0 ) q(X_t|X_{t+1}X_0) q(Xt∣Xt+1X0)来指导 p Θ ( X t ∣ X t + 1 ) p_{Θ}(X_t|X_{t+1}) pΘ(Xt∣Xt+1)进行训练。
高斯分布
又名正态分布,图像处理中最常用的滤波器类型为Gaussian滤波器(也就是所谓的正态分布函数)。若随机变量
X
X
X服从一个位置参数为
μ
\mu
μ、尺度参数为
σ
\sigma
σ的概率分布,记为:
X
∼
N
(
μ
,
σ
2
)
X \sim N(\mu , \sigma^2)
X∼N(μ,σ2)
其概率密度函数为:
f
(
x
)
=
1
σ
2
π
e
−
(
x
−
μ
)
2
2
σ
2
f(x)=\frac{1}{\sigma \sqrt{2 \pi}}e^{-\frac{(x-\mu)^2}{2 \sigma^2}}
f(x)=σ2π1e−2σ2(x−μ)2
标准正态分布是均值
μ
=
0
\mu = 0
μ=0,方差
σ
=
1
\sigma = 1
σ=1的正态分布。在特定条件下,大量统计独立的随机变量的平均值的分布趋于正态分布,这就是中心极限定理。
马尔科夫链
定义:考虑一个随机变量的序列
X
=
{
X
0
,
X
1
,
.
.
.
,
X
t
,
.
.
.
}
X=\{X_0,X_1,...,X_t,...\}
X={X0,X1,...,Xt,...},这里
X
t
X_t
Xt表示时刻
t
t
t的随机变量,
t
=
0
,
1
,
2
,
.
.
.
t=0,1,2,...
t=0,1,2,...。每个随机变量
X
t
(
t
=
0
,
1
,
2
,
.
.
.
)
X_t(t=0,1,2,...)
Xt(t=0,1,2,...)的取值集合相同,称为状态空间
S
S
S。随机变量可以是离散的,也可以是连续的。以上随机变量的序列构成随机过程。
假设在时刻0的随机变量
X
0
X_0
X0遵循概率分布
P
(
X
0
)
=
π
0
P(X_0)=\pi_0
P(X0)=π0,称为初始状态分布。在某个时刻
t
≥
1
t \geq 1
t≥1的随机变量
X
t
X_t
Xt与前一个时刻的随机变量
X
t
−
1
X_{t-1}
Xt−1之间有条件分布
P
(
X
t
∣
X
t
−
1
)
P(X_t|X_{t-1})
P(Xt∣Xt−1),如果
X
t
X_t
Xt只依赖于
X
t
−
1
X_{t-1}
Xt−1,而不依赖于过去的随机变量
X
=
{
X
0
,
X
1
,
.
.
.
,
X
t
−
2
}
X=\{X_0,X_1,...,X_{t-2}\}
X={X0,X1,...,Xt−2},这一性质称为马尔科夫性质,即
P
(
X
t
∣
X
0
,
X
1
,
.
.
.
,
X
t
−
1
)
=
P
(
X
t
∣
X
t
−
1
)
,
t
=
1
,
2
,
.
.
.
P(X_t|X_0,X_1,...,X_{t-1})=P(X_t|X_{t-1}) ,t=1,2,...
P(Xt∣X0,X1,...,Xt−1)=P(Xt∣Xt−1),t=1,2,...
具有马尔科夫性的随机序列
X
=
{
X
0
,
X
1
,
.
.
.
,
X
t
,
.
.
.
}
X=\{X_0,X_1,...,X_t,...\}
X={X0,X1,...,Xt,...}称为马尔科夫链,或马尔科夫过程。条件概率分布
P
(
X
t
∣
X
t
−
1
)
P(X_t|X_{t-1})
P(Xt∣Xt−1)称为马尔科夫链的转移概率分布。转移概率分布决定了马尔科夫链的特性。
- 时间齐次的马尔可夫链: 转移概率分布
P
(
X
t
∣
X
t
−
1
)
P(X_t|X_{t-1})
P(Xt∣Xt−1)与
t
t
t无关,即
P ( X t + s ∣ X t − 1 + s ) = P ( X t ∣ X t − 1 ) , t = 1 , 2 , . . . ; s = 1 , 2 , . . . P(X_{t+s}|X_{t-1+s})=P(X_t|X_{t-1}),t=1,2,...; \quad s=1,2,... P(Xt+s∣Xt−1+s)=P(Xt∣Xt−1),t=1,2,...;s=1,2,... - 以上定义的是一阶马尔可夫链,可以扩展到n阶马尔可夫链,满足n阶马尔可夫性
P ( X t ∣ X 0 X 1 . . . X t − 2 X t − 1 ) = P ( X t ∣ X t − n . . . X t − 2 X t − 1 ) P(X_t|X_0X_1...X_{t-2}X_{t-1})=P(X_t|X_{t-n}...X_{t-2}X_{t-1}) P(Xt∣X0X1...Xt−2Xt−1)=P(Xt∣Xt−n...Xt−2Xt−1)
采样
把一幅图像表示为二元函数形式:f(x, y),那么该函数在不同的坐标点有不同的幅度值,而这些幅度值是连续的,无法使用计算机进行处理,所以我们需要对幅度值进行离散化(数字化),这个过程即为图像量化处理,一般常见的量化方式是将图像用黑白两种颜色表示,称为二值图像。一幅图像可以表示为在 x 轴和 y 轴上连续的信号,但计算机无法处理连续信号,所以我们需要将图像在这两个维度进行离散化处理,该过程就称为图像的采样处理,即对图像的坐标轴进行数字化。
- 上采样(upsampling):或称为放大图像或图像插值(interpolating),主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上。采用差值算法实现。
- 下采样(subsampled):或称为缩小图像或降采样(downsampled),主要目的为使得图像符合显示区域的大小或生成对应图像的缩略图。采用池化技术实现,保持旋转、平移、伸缩不变形等。采样有最大值采样,平均值采样,求和区域采样和随机区域采样等,池化有最大值池化,平均值池化,随机池化,求和区域池化等。
U-net
CNN(卷积神经网络):通常是由一系列的卷积层之后跟一个池化层作为一个基础模块,重复这个模块构成;输入图像在卷积神经网络的过程中,其宽度和高度会由于下采样而不断减少,但其通道数会因为深层神经网络提取到的特征更加复杂而不断增加。下图是一个例子:
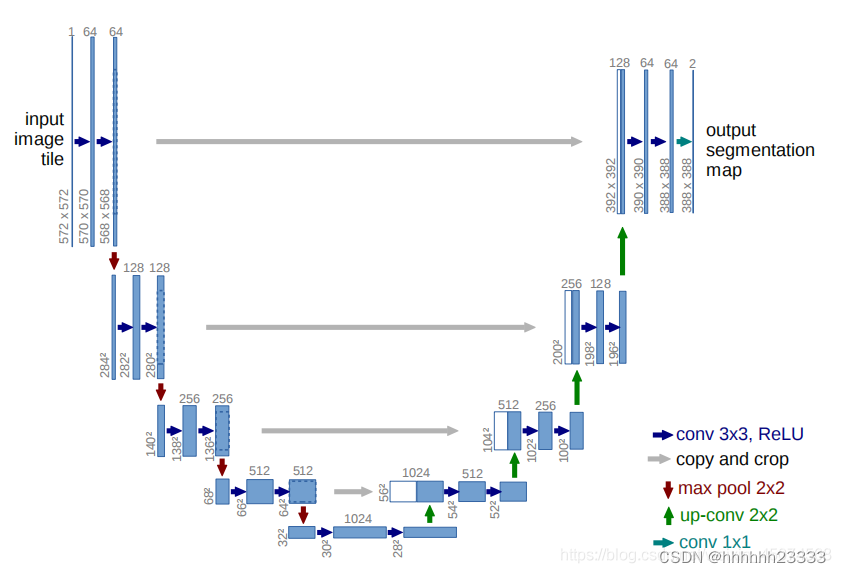
U-Net:一种图像分割网络,输入一幅图,编码,或者说降采样,然后解码,也就是升采样,然后输出一个分割结果。根据结果和真实分割的差异,反向传播来训练这个分割网络。
- UNet采用全卷积神经网络。
- 左边网络为特征提取网络:使用conv和pooling
- 右边网络为特征融合网络:使用上采样产生的特征图与左侧特征图进行concatenate操作。(pooling层会丢失图像信息和降低图像分辨率且是永久性的,对于图像分割任务有一些影响,对图像分类任务的影响不大,为什么要做上采样呢?上采样可以让包含高级抽象特征低分辨率图片在保留高级抽象特征的同时变为高分辨率,然后再与左边低级表层特征高分辨率图片进行concatenate操作)
- 最后再经过两次卷积操作,生成特征图,再用两个卷积核大小为1*1的卷积做分类得到最后的两张heatmap,例如第一张表示第一类的得分,第二张表示第二类的得分heatmap,然后作为softmax函数的输入,算出概率比较大的softmax,然后再进行loss,反向传播计算。
introduction
- 已有的3D内容生成方法及问题:
- 使用3D表示(如体素或三角形平面)来训练生成模型,如GAN或扩散模型。由于当前3D数据集的稀缺性,导致多样性受限且泛化效果不佳。
- 采用一种2D引导方法,核心框架建立在预训练的文本到图像扩散模型之上,并通过分数蒸馏抽样(SDS)损失和可微分渲染从2D生成的图像中提取3D内容。借助从大规模数据集中学到的图像生成先验知识,这一框架实现了更多样化的3D生成。然而,当前的文本到图像扩散模型主要强调生成自然的RGB图像,这导致对3D几何结构和视角方向的感知有限。这一限制可能导致双面伪影和平滑的几何形状。
- 引入人体模型,如SMPL和imGHUM,但仍未解决文本到图像扩散模型的基本限制。这导致几何结构次优,呈卡通风格,尤其在服装皱纹等领域。
- 本文思路:
- 使用从3D人体扫描和具有视角相关文本的渲染生成的多视图法线图来训练一个适应法线的扩散模型。与文本到图像扩散模型相比,适应法线的扩散模型滤除了纹理的影响,可以直接生成与视角相关文本相对应的高保真度表面法线图。这确保了3D几何细节的生成,避免了Janus伪像。
- 由于法线图缺乏深度信息,还学习了一个适应深度的扩散模型,以进一步增强对3D几何的感知。
- 为了进行纹理生成,从法线-图像对中学习了一个法线对齐的扩散模型。这个模型有效地将人体几何信息整合到纹理生成过程中,考虑到了由几何褶皱引起的阴影等因素,并将生成的纹理与表面法线对齐。
- 本文的主要贡献如下:
- 引入了适应法线的扩散模型,可以从具有视角相关文本的提示中生成法线图,从而提高了2D扩散模型在3D人体生成中的基本能力。
- 学习了法线对齐的扩散模型,以将生成的纹理与表面法线对齐,将物理几何细节转化为逼真的外观。
- 提出了一种用于生成高质量几何的渐进几何生成策略和用于生成逼真纹理的粗到细纹理生成方法。
preliminary
扩散引导的3D生成框架
在3D生成过程中,通过随机采样相机c并通过可微分渲染函数
g
(
θ
,
c
)
g(θ, c)
g(θ,c)进行渲染,获得渲染的图像
x
0
x_0
x0。输入文本为
y
y
y,为使
x
0
x_0
x0与扩散模型生成的图像分布
p
(
x
0
∣
y
)
p(x_0|y)
p(x0∣y)对齐,假设从不同角度渲染的图像分布为
q
θ
(
x
0
∣
y
)
=
∫
q
θ
(
x
0
∣
y
,
c
)
p
(
c
)
d
c
q^θ(x_0|y) = \int q^θ(x_0|y, c)p(c)dc
qθ(x0∣y)=∫qθ(x0∣y,c)p(c)dc,扩散引导的3D生成框架的优化目标可以表示为:
m
i
n
θ
D
K
L
(
q
θ
(
x
0
∣
y
)
∣
∣
p
(
x
0
∣
y
)
)
(1)
\underset {\theta}{min}D_{KL}(q^{\theta}(x_0|y)||p(x_0|y)) \tag{1}
θminDKL(qθ(x0∣y)∣∣p(x0∣y))(1)
其中KL散度定义为
D
K
L
(
p
∣
∣
q
)
=
Σ
[
p
(
x
)
∗
l
o
g
p
(
x
)
q
(
x
)
]
D_{KL}(p||q) = Σ [p(x) * log \frac {p(x)}{q(x)}]
DKL(p∣∣q)=Σ[p(x)∗logq(x)p(x)]
为了进一步提高几何质量,在3D表示
θ
θ
θ中将几何
θ
g
θ_g
θg和外观
θ
c
θ_c
θc分离。在纹理阶段仍保留上述方法,在几何阶段,利用渲染函数
g
(
θ
g
,
c
)
g(θ_g, c)
g(θg,c)来渲染法线图
z
0
n
z^n_0
z0n,并使渲染的法线图分布
q
θ
g
(
z
0
n
∣
y
)
q^{θ_g}(z^n_0|y)
qθg(z0n∣y)与
p
(
x
0
∣
y
)
p(x_0|y)
p(x0∣y)对齐:
m
i
n
θ
g
D
K
L
(
q
θ
g
(
z
0
n
∣
y
)
∣
∣
p
(
x
0
∣
y
)
)
(2)
\underset {\theta_g}{min}D_{KL}(q^{\theta_g}(z^n_0|y)||p(x_0|y)) \tag{2}
θgminDKL(qθg(z0n∣y)∣∣p(x0∣y))(2)
扩散引导的3D生成的瓶颈:扩散引导的3D生成的瓶颈在于T2I(文本到图像)扩散模型,它限制了自身对自然RGB图像的概率分布进行参数化,表示为p(x0|y)。因此,当前的T2I扩散模型缺乏对视角方向和几何结构的理解。因此,直接由T2I扩散模型引导的3D生成(公式1)会导致双面伪影和低质量的几何结构。尽管Fantasia3D分离了几何和纹理,但它仍然在几何和纹理阶段遇到了源自T2I扩散模型的问题。在几何阶段,直接将渲染的法线图分布
q
θ
g
(
z
0
n
∣
y
)
q^{θ_g}(z^n_0|y)
qθg(z0n∣y)与自然图像分布
p
(
x
0
∣
y
)
p(x_0|y)
p(x0∣y)对齐是不合适的,因为法线图与RGB图像明显不同,这种对齐导致几何形状失真和伪影。在纹理阶段,最小化
q
θ
c
(
x
0
∣
y
)
q^{θ_c}(x_0|y)
qθc(x0∣y)和
p
(
x
0
∣
y
)
p(x_0|y)
p(x0∣y)之间的差异会导致纹理与几何不对齐。
扩散模型的引导损失
SDS损失(Score Distillation Sampling):广泛应用于各种扩散引导的3D生成框架中。它将公式1中的优化目标转化为在具有扩散噪声的两个分布之间的差异优化,从而实现3D生成:
m
i
n
θ
L
S
D
S
(
θ
)
≈
E
c
,
t
[
(
σ
t
/
α
t
)
ω
(
t
)
D
K
L
(
q
t
θ
(
x
t
∣
c
,
y
)
∣
∣
p
t
(
x
t
∣
y
)
)
]
(3)
\underset {\theta}{min}L_{SDS}(θ)\approx E_{c,t}[(σ_t/α_t)ω(t)D_{KL}(q^θ_t(x_t|c, y) || p_t(x_t|y))] \tag{3}
θminLSDS(θ)≈Ec,t[(σt/αt)ω(t)DKL(qtθ(xt∣c,y)∣∣pt(xt∣y))](3)
其中
t
t
t表示扩散过程中的时间步,
x
t
x_t
xt对应于在时间步
t
t
t时带有噪声
ϵ
ϵ
ϵ的渲染图像
x
0
x_0
x0。
σ
t
σ_t
σt、
α
t
α_t
αt和
ω
(
t
)
ω(t)
ω(t)是扩散调度器的参数。用
ϵ
p
(
⋅
)
ϵ_p(·)
ϵp(⋅)表示预先训练的扩散模型。SDS损失的梯度可以如下计算:
∇
L
S
D
S
(
θ
)
≈
E
c
,
t
,
ϵ
[
ω
(
t
)
(
ϵ
p
(
x
t
,
t
,
y
)
−
ϵ
)
∂
g
(
θ
,
c
)
∂
θ
]
(4)
∇L_{SDS}(θ) ≈ E_{c,t,ϵ}[ω(t)(ϵ_p(x_t, t, y) - ϵ) \frac{∂g(θ, c)}{∂θ}] \tag{4}
∇LSDS(θ)≈Ec,t,ϵ[ω(t)(ϵp(xt,t,y)−ϵ)∂θ∂g(θ,c)](4)
多步SDS和感知损失:多步SDS和感知损失主要用于3D编辑和减轻纹理生成中的过饱和问题(生成的图像中某些区域的颜色或亮度过于强烈,导致生成的纹理看起来不真实或与实际场景不匹配,因为自然环境中的颜色和亮度通常是平衡和温和的)。与SDS损失不同,它需要多个扩散步骤来恢复给定
x
t
x_t
xt时RGB图像分布
p
t
(
x
0
∣
x
t
,
y
)
p_t(x_0|x_t, y)
pt(x0∣xt,y)并最小化以下目标:
m
i
n
θ
L
m
u
l
t
i
S
D
S
(
θ
)
≈
E
c
,
t
[
(
σ
t
/
α
t
)
ω
(
t
)
D
K
L
(
q
t
θ
(
x
t
∣
c
,
y
)
∣
∣
p
t
(
x
0
∣
x
t
,
y
)
)
]
(5)
\underset {\theta}{min}L_{multiSDS}(θ)\approx E_{c,t}[(σ_t/α_t)ω(t)D_{KL}(q^θ_t(x_t|c, y) || p_t(x_0|x_t,y))] \tag{5}
θminLmultiSDS(θ)≈Ec,t[(σt/αt)ω(t)DKL(qtθ(xt∣c,y)∣∣pt(x0∣xt,y))](5)
多步SDS损失在优化过程中促进稳定性,避免陷入局部最优解。为了进一步防止过饱和效应,还应用了感知损失以保持来自
g
(
θ
,
c
)
g(θ, c)
g(θ,c)的渲染图像
x
0
x_0
x0和来自
p
t
(
x
0
∣
x
t
,
y
)
p_t(x_0|x_t, y)
pt(x0∣xt,y)的生成图像
x
^
0
\hat{x}_0
x^0的自然样式:
L
p
=
E
x
^
0
∼
p
t
(
x
0
∣
x
t
,
y
)
(
∣
∣
V
(
x
0
)
−
V
(
x
^
0
)
∣
∣
2
2
)
(6)
L_p = E_{\hat{x}_0∼p_t(x_0|x_t,y)}(||V (x_0) − V (\hat{x}_0)||_2^2) \tag{6}
Lp=Ex^0∼pt(x0∣xt,y)(∣∣V(x0)−V(x^0)∣∣22)(6)
其中V是VGG网络的前k层。将扩散模型的多步图像生成函数表示为
h
(
x
t
,
t
,
y
)
h(x_t, t, y)
h(xt,t,y),多步SDS和感知损失的梯度可以形式化如下:
∇
L
m
u
l
t
i
s
t
e
p
(
θ
)
≈
E
c
,
t
,
ϵ
[
ω
(
t
)
(
h
(
x
t
,
t
,
y
)
−
x
0
)
∂
g
(
θ
,
c
)
∂
θ
]
+
λ
p
∇
L
p
(7)
∇L_{multistep}(θ) ≈ E_{c,t,ϵ}[ω(t)(h(x_t, t, y) − x_0) \frac{∂g(θ, c)}{∂θ}] + λ_p∇L_p \tag{7}
∇Lmultistep(θ)≈Ec,t,ϵ[ω(t)(h(xt,t,y)−x0)∂θ∂g(θ,c)]+λp∇Lp(7)
method
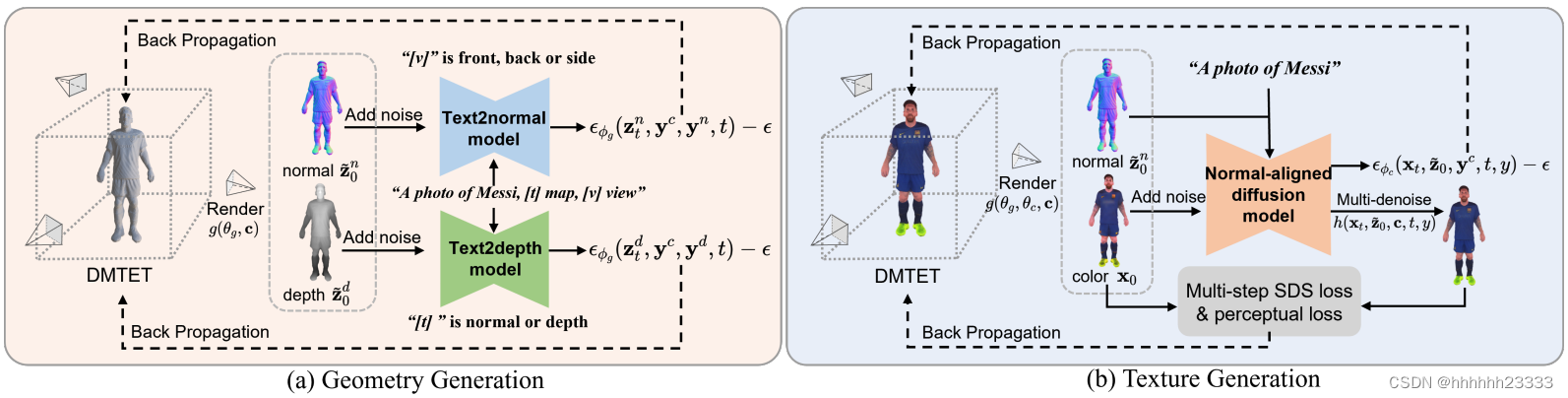
HumanNorm概述
我们的方法旨在从给定的提示生成高质量和逼真的3D人体。整个框架由几何和纹理生成组成。首先,我们为几何生成提出了适应法线和适应深度的扩散模型。这两个模型可以通过SDS损失引导渲染的法线和深度图逼近高保真法线和深度图的学习分布,从而实现高质量的几何生成。在纹理生成方面,我们引入了法线对齐的扩散模型并采用粗到细策略。法线对齐的扩散模型利用法线图作为引导线索,以确保生成的纹理与几何结构对齐。在粗略级别,我们专门使用SDS损失,而在细致级别,我们结合多步SDS和感知损失来实现逼真的纹理生成。
法线扩散模型
在追求从给定文本目标
y
y
y生成高质量和逼真的3D人物时,第一个挑战在于实现准确的几何生成。这涉及到将从多个视区
c
c
c渲染的法线图分布
q
θ
g
(
z
0
n
∣
c
,
y
)
q^{θ_g} (z^n_0 |c, y)
qθg(z0n∣c,y)与理想的法线图分布
p
^
(
z
0
n
∣
c
,
y
)
\hat{p}(z^n _0 |c, y)
p^(z0n∣c,y)进行对齐。下一个挑战是生成逼真的纹理
θ
c
θ_c
θc,同时确保其与已建立的几何
θ
g
θ_g
θg保持一致。因此,最小化渲染图像分布
q
θ
c
(
x
0
∣
c
,
y
)
q^{θ_c}(x_0|c, y)
qθc(x0∣c,y)与理想的几何对齐图像分布
p
^
(
x
0
∣
c
,
θ
g
,
y
)
\hat{p}(x_0|c, θ_g, y)
p^(x0∣c,θg,y)之间的差异变得至关重要。理想的优化目标可以如下所示:
m
i
n
θ
g
,
θ
c
D
K
L
(
q
θ
g
(
z
0
n
∣
c
,
y
)
∣
∣
p
^
(
z
0
n
∣
c
,
y
)
)
⏟
几何生成目标
+
D
K
L
(
q
θ
c
(
x
0
∣
c
,
y
)
∣
∣
p
^
(
x
0
∣
c
,
θ
g
,
y
)
)
⏟
纹理生成目标
(8)
\underset{θ_g,θ_c}{min}\underbrace{D_{KL}(q^{θ_g}(z^n_0 |c, y)||\hat{p}(z^n_0|c, y))}_{几何生成目标}+\underbrace{D_{KL}(q^{θ_c}(x_0|c, y)||\hat{p}(x_0|c, θ_g, y))}_{纹理生成目标} \tag{8}
θg,θcmin几何生成目标
DKL(qθg(z0n∣c,y)∣∣p^(z0n∣c,y))+纹理生成目标
DKL(qθc(x0∣c,y)∣∣p^(x0∣c,θg,y))(8)
然而,现有的T2I(文本到图像)扩散模型仅限于参数化自然RGB图像的分布,表示为
p
(
x
0
∣
y
)
p(x_0|y)
p(x0∣y),这与理想的分布
p
^
(
z
0
n
∣
c
,
y
)
\hat{p}(z^n_0 |c, y)
p^(z0n∣c,y)和
p
^
(
x
0
∣
c
,
θ
g
,
y
)
\hat{p}(x_0|c, θ_g, y)
p^(x0∣c,θg,y)存在显著差异。为了弥合这一差距,我们提出将法线图对齐,代表人体几何的2D感知,纳入T2I扩散模型中以近似
p
^
(
z
0
n
∣
c
,
y
)
\hat{p}(z^n_0 |c, y)
p^(z0n∣c,y)和
p
^
(
x
0
∣
c
,
θ
g
,
y
)
\hat{p}(x_0|c, θ_g, y)
p^(x0∣c,θg,y)。对于几何部分,我们建议微调扩散模型,使其适应生成法线图分布
p
(
z
0
n
∣
y
)
p(z^n_0 |y)
p(z0n∣y)。在纹理方面,我们利用ControlNet和法线图
z
0
n
z^n_0
z0n作为条件来指导扩散模型
p
(
x
0
∣
z
0
n
,
y
)
p(x_0|z^n_0 , y)
p(x0∣z0n,y)生成与法线图对齐的图像,从而确保生成的纹理与几何对齐。包括法线图的优化目标如下所示:
m
i
n
θ
g
,
θ
c
D
K
L
(
q
θ
g
(
z
0
n
∣
y
)
∣
∣
p
(
z
0
n
∣
y
)
)
+
D
K
L
(
q
θ
c
(
x
0
∣
y
)
∣
∣
p
(
x
0
∣
z
0
n
,
y
)
)
(9)
\underset{θ_g,θ_c}{min}D_{KL}(q^{θ_g}(z^n_0 |y)||p(z^n_0 |y)) + D_{KL}(q^{θ_c}(x_0|y)||p(x_0|z^n_0 , y)) \tag{9}
θg,θcminDKL(qθg(z0n∣y)∣∣p(z0n∣y))+DKL(qθc(x0∣y)∣∣p(x0∣z0n,y))(9)
此外,我们还将摄像机参数c翻译为与视角相关的文本
y
c
y^c
yc,作为扩散模型的附加条件。这个翻译确保生成的图像与视角一致,如下图所示。

我们方法的优化目标如下:
m
i
n
θ
g
,
θ
c
D
K
L
(
q
θ
g
(
z
0
n
∣
c
,
y
)
∣
∣
p
(
z
0
n
∣
y
c
,
y
)
)
+
D
K
L
(
q
θ
c
(
x
0
∣
c
,
y
)
∣
∣
p
(
x
0
∣
z
0
n
,
y
c
,
y
)
)
(10)
\underset{θ_g,θ_c}{min}D_{KL}(q^{θ_g}(z^n_0 |c,y)||p(z^n_0 |y^c,y)) + D_{KL}(q^{θ_c}(x_0|c,y)||p(x_0|z^n_0 , y^c,y)) \tag{10}
θg,θcminDKL(qθg(z0n∣c,y)∣∣p(z0n∣yc,y))+DKL(qθc(x0∣c,y)∣∣p(x0∣z0n,yc,y))(10)
适应法线的几何生成扩散模型
构建用于高质量几何生成的正常适应扩散模型面临几个挑战。首先,现有的3D人物数据集稀缺,导致用于训练的正常图数量有限。因此,我们采用了一种微调策略,将文本到图像扩散模型改编为文本到正常扩散模型。然后,我们发现渲染的正常图在不同视角下会发生显著变化,这可能导致过度拟合或欠拟合的问题。为了减轻这种影响并鼓励扩散模型专注于感知几何的细节,我们通过相机参数的旋转R来转换正常图
z
0
n
z^n_0
z0n。变换后的正常图
z
~
0
n
\tilde{z}^n_0
z~0n用于训练正常适应扩散模型。此外,我们还将视角相关文本
y
c
y^c
yc和正常感知文本
y
n
y^n
yn(“正常图”)作为条件添加到扩散模型中。微调过程采用与原始扩散模型相同的优化目标: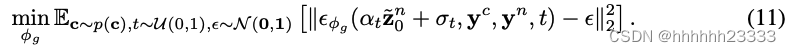
训练后的正常适应扩散模型可以通过正常SDS损失来引导几何生成:
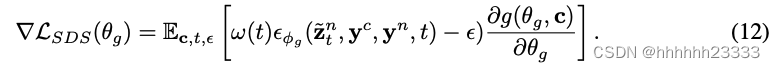
除了正常SDS损失,我们采用了一些策略来增强3D人物生成的效率和鲁棒性,如下所述:
深度SDS损失由深度适应扩散模型计算:我们还通过简单地将正常图更改为深度图来微调深度适应扩散模型以计算深度SDS损失。我们发现深度SDS损失可以减少几何失真和几何生成中的伪影。
DMTET表示和初始化:我们采用了高效的3D表示DMTET,并基于自然人体网格进行初始化,以增强3D人物生成的鲁棒性。DMTET中的SDF函数通过Instant-NGP的哈希编码进一步加速。
渐进式几何生成:我们提出了一种渐进策略,包括渐进哈希编码和渐进SDF损失,以减少几何噪音并提高几何生成的整体质量。渐进哈希编码在初始阶段使用掩码来抑制SDF函数中的高频组件。这允许网络专注于几何的低频组件,并在开始时提高训练稳定性。随着培训的进行,我们逐渐减少高频组件的掩码。从而增强衣物褶皱等细节。对于渐进SDF损失,我们首先记录SDF函数
s
(
x
)
s(x)
s(x)在减少高频掩码之前。然后随着训练的进行,我们添加SDF损失以减轻高频噪音或奇怪的几何变形:其中
s
~
θ
g
(
x
)
\tilde{s}_{θ_g}(x)
s~θg(x)是DMTET中的SDF函数,P是随机采样点集。
法线对齐的纹理生成扩散模型
在纹理生成中,我们固定几何参数
θ
g
θ_g
θg并引入了法线对齐扩散模型作为指导。法线对齐扩散模型能够将物理几何细节转化为逼真的外观,并确保生成的纹理与几何对齐。具体而言,我们使用 ControlNet来将转化后的法线图
z
~
0
n
\tilde{z}^n_0
z~0n作为 T2I 扩散模型的引导条件。法线对齐扩散模型的训练目标如下:
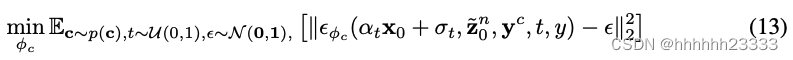
接着,我们提出了基于法线对齐扩散模型的粗到细策略。
粗到细纹理生成:在粗略层面,我们利用法线对齐扩散模型的 SDS 损失
ϵ
ϕ
c
ϵ_{ϕ_c}
ϵϕc用于纹理生成:
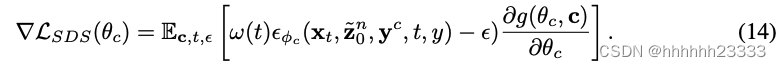
虽然 SDS 损失可能导致过饱和的风格,看起来不太自然,但它能够高效地优化一个合理的纹理作为初始值。我们随后通过多步 SDS 和感知损失来进一步优化纹理:
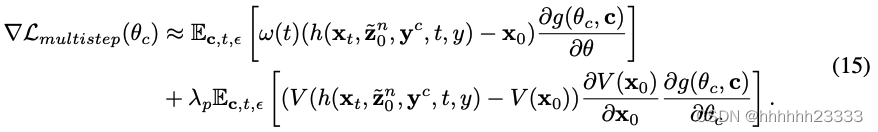
由于法线对齐扩散模型执行完整的多步扩散过程,生成的图像看起来更自然,不容易出现过饱和的效果。
experiment
效果评估

与文本到3D内容方法的比较:与DreamFusion、LatentNeRF、TEXTure和Fantasia3D比较效果如上图所示,文本到3D内容方法生成的结果存在一些挑战。生成的3D人物往往存在比例失真,纹理过饱和和噪点。DreamFusion难以生成完整的全身人物,甚至在提供了“全身…”这样的提示时,通常会遗漏脚部。相比之下,我们的方法提供了更准确的几何形状和更真实的纹理,生成结果更具优势。
与文本到3D人物方法的比较:与DreamHuman、AvatarVerse和TADA比较效果如上图所示,文本到3D人物方法由于集成了SMPL和imGHUM人体模型,因此能够提供更精细的几何形状。与这些方法不同,我们的方法能够创建具有更高几何细节水平的3D人物,如衣物皱纹和独特的面部特征。此外,文本到3D人物方法还存在过度饱和的问题,而我们的方法通过粗到细的纹理生成策略能够生成更真实的颜色。
消融实验
( a-b ) 使用文本到图像扩散模型而不是法线对齐和深度适应的扩散模型。( c ) 删除多步SDS和感知损失。

法线对齐和深度适应扩散模型的有效性:在图(a)中,我们展示了由文本到图像扩散模型生成的几何形状,而不是使用我们的法线对齐和深度适应扩散模型。可以看到,该方法难以生成面部几何形状,耳朵上出现了空洞。此外,结果显示出更平滑的服装褶皱和粗糙的表面。这个实验证明了我们的法线对齐和深度适应扩散模型在生成高质量几何形状方面的益处。
法线对齐扩散模型的有效性:在图(b)中,我们尝试移除法线对齐扩散模型,而选择使用文本到图像扩散模型进行纹理生成。结果纹理略显模糊,无法准确显示几何细节。这是因为文本到图像扩散模型难以使生成的纹理与几何形状对齐。然而,使用法线对齐扩散模型,我们的方法能够克服这些限制,实现更精确和精细的细节,从而显著提高了3D人物的外观。
粗到细纹理生成策略的有效性:在图(c)中,我们展示了仅使用SDS损失的粗阶段结果。生成的纹理明显过饱和。然而,如图(d)所示,通过粗到细策略生成的纹理呈现出更真实和自然的颜色,突显了我们粗到细纹理生成策略的有效性。

深度SDS的有效性:现有方法,如Fanasia3D和TADA,通过计算法线SDS损失来优化几何形状。然而,我们发现仅使用法线图作为监督可能会导致某些区域的几何形状失败。如图(a)所示,在仅使用法线SDS损失时,耳朵显示出了伪影。这是因为伪影的法线与头部的法线相似,使其对扩散模型来说不明显。相比之下,我们可以在深度图中清楚地看到伪影。在图(b)中,可以明显看到,通过基于我们的深度适应扩散模型添加深度SDS损失后,伪影得到了减少,这证明了深度SDS的有效性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









