







FaceFormer: Speech-Driven 3D Facial Animation with Transformers
概述
基于端到端transformer的自回归模型FaceFormer,可以自回归合成一系列具有精确嘴唇运动的真实3D面部运动
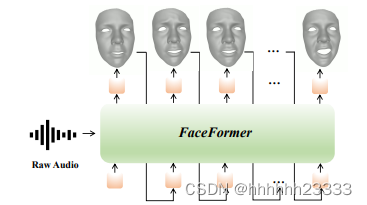
将语音驱动的3D面部动画构建为序列对序列(seq2seq)学习问题,利用具有Transformer架构的编码器-解码器模型将原始音频作为输入,并自回归生成一系列动画3D人脸网格。
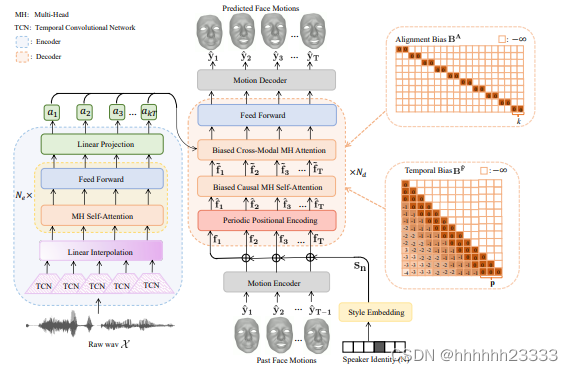
FaceFormer编码器的总体设计遵循wav2vec 2.0,由音频特征提取器(多个TCN)和多层transformer编码器(MH自注意和前馈层)组成。此外,在时间卷积网络TCN后添加线性插值层,对音频特征进行重采样。用相应的预先训练的wav2vec 2.0权值初始化编码器。FaceFormer解码器由两个主要模块组成:一个带有周期性位置编码(PPE)的有偏因果MH自我注意,用于泛化较长的输入序列;一个带有偏倚的跨模态多头(MH)注意,用于对齐音频运动模态。在训练过程中,TCN的参数是固定的,而模型的其他部分是可学习的。添加风格嵌入层包含一组可学习的嵌入S,表示说话人身份。编码器将原始音频X转化为对应视觉帧数的序列
A
T
′
A_{T'}
AT′,解码器以
A
T
′
A_{T'}
AT′、S和过去的面部动作为条件,预测面部运动序列
Y
^
T
\hat{Y}_T
Y^T。
Approach
输入真实3D面部动作序列
Y
T
=
(
y
1
,
.
.
.
,
y
T
)
Y_T=(y_1,...,y_T)
YT=(y1,...,yT)(T表示视觉帧数)和原始音频X,输出与
Y
T
=
(
y
1
,
.
.
.
,
y
T
)
Y_T=(y_1,...,y_T)
YT=(y1,...,yT)相似的预测面部动作序列
Y
T
^
\hat{Y_T}
YT^。编码器首先将X转化为语音表示
A
T
′
=
(
a
1
,
.
.
.
,
a
T
′
)
A_{T'}=(a_1,...,a_{T'})
AT′=(a1,...,aT′),
T
′
T'
T′表示帧长。风格嵌入层
S
=
(
s
1
,
.
.
.
,
s
N
)
S=(s_1,...,s_N)
S=(s1,...,sN)。解码器自回归预测
Y
^
T
=
(
y
^
1
,
.
.
.
,
y
^
T
)
\hat{Y}_T=(\hat{y}_1,...,\hat{y}_T)
Y^T=(y^1,...,y^T):
y
t
^
=
F
a
c
e
F
o
r
m
e
r
θ
(
y
^
<
t
,
s
n
,
X
)
(1)
\hat{y_t}=FaceFormer_\theta(\hat{y}_{<t},s_n,X) \tag{1}
yt^=FaceFormerθ(y^<t,sn,X)(1)
其中θ表示模型参数,t是序列中的当前时间步
- FaceFormer编码器
- 自我监督预训练言语模型:
- 音频提取器:由多个TCN组成,将输入的原始波形转换为频率为 f a f_a fa的特征向量
- 线性插值层:重新采样音频特征,频率从 f a f_a fa变为面部运动数据捕获频率 f m f_m fm,输出长度为 k T kT kT, k = ⌈ f a f m ⌉ k=\lceil \frac{f_a}{f_m} \rceil k=⌈fmfa⌉
- transformer编码器:由多个MH自注意和前馈层组成的堆栈,将音频特征向量转换为上下文化的语音表示
- 线性投影层:随机初始化,输出 A k T = ( a 1 , . . . , a k T ) A_{kT}=(a_1,...,a_{kT}) AkT=(a1,...,akT)
- 自我监督预训练言语模型:
- FaceFormer解码器
- 周期性位置编码(PPE):用于注入时间顺序信息,同时与ALiBi(线性偏差注意方法,通过在查询键注意评分上增加恒定偏差来提高泛化能力)兼容。修改了transformer的正弦位置编码方法,使其相对于表示周期的超参数p具有周期性:
P P E ( t , 2 i ) = s i n ( ( t m o d p ) / 1000 0 2 i / d P P E ( t , 2 i + 1 ) = c o s ( ( t m o d p ) / 1000 0 2 i / d (2) PPE_{(t,2i)}=sin((t \quad mod \quad p)/10000^{2i/d} \\ PPE_{(t,2i+1)}=cos((t \quad mod \quad p)/10000^{2i/d} \tag{2} PPE(t,2i)=sin((tmodp)/100002i/dPPE(t,2i+1)=cos((tmodp)/100002i/d(2)
其中t表示序列中的标记位置或当前时间步长,d是模型维度,i是维度索引。在PPE之前首先通过一个运动编码器(一个有d个输出的全连接层)将 y t ^ \hat{y_t} yt^输入到d维空间中。为了建模说话风格,通过风格嵌入层(有d个输出的嵌入层)将one-hot说话者身份嵌入到d维向量 s n s_n sn中,并将其添加到面部运动表示中:
f t = { ( W f ⋅ y ^ t − 1 + b f ) + s n , 1 < t ≤ T s n , t = 1 (3) f_t= \begin{cases} (W^f\cdot \hat{y}_{t-1}+b^f)+s_n,\quad 1<t\leq T\\ s_n, \quad t=1 \end{cases} \tag{3} ft={(Wf⋅y^t−1+bf)+sn,1<t≤Tsn,t=1(3)
其中, W f W^f Wf是权重, b f b^f bf是偏差, y ^ t − 1 \hat{y}_{t-1} y^t−1是来自上一个时间步的预测。然后对 f t f_t ft应用PPE,周期性提供时序信息:
f t ^ = f t + P P E ( t ) (4) \hat{f_t}=f_t+PPE(t) \tag{4} ft^=ft+PPE(t)(4) - 有偏因果MH自注意:给定
F
t
^
=
(
f
^
1
,
.
.
.
,
f
^
t
)
\hat{F_t}=(\hat f_1,...,\hat f_t)
Ft^=(f^1,...,f^t),有偏因果MH自注意首先将
F
^
t
\hat F_t
F^t线性投影到
d
k
d_k
dk维的查询
Q
F
^
Q^{\hat F}
QF^、键
K
F
^
K^{\hat F}
KF^和值
V
F
^
V^{\hat F}
VF^,详见Self-Attention 结构。为了了解过去面部动作序列中每一帧之间的依赖关系,通过执行缩放点积注意力来计算一个加权上下文表示:
A t t ( Q F ^ , K F ^ , V F ^ , B F ^ = s o f t m a x ( Q F ^ ( K F ^ ) d k + B F ^ ) V F ^ (5) Att(Q^{\hat F},K^{\hat F},V^{\hat F},B^{\hat F}=softmax(\frac{Q^{\hat F}(K^{\hat F})}{\sqrt{d_k}}+B^{\hat F})V^{\hat F} \tag{5} Att(QF^,KF^,VF^,BF^=softmax(dkQF^(KF^)+BF^)VF^(5)
其中 B F ^ B^{\hat F} BF^是我们添加的时间偏差,以确保因果关系,并提高推广到更长序列的能力。 B F ^ B^{\hat F} BF^是一个在上三角形全为负无穷的矩阵,以避免查看未来帧来进行当前预测。为提高泛化能力,将静态和非学习偏差添加到 B F ^ B^{\hat F} BF^的下三角中。引入周期p,并为每个周期([1:p], [p + 1: 2p],…)注入时间偏差。定义i和j为 B F ^ B^{\hat F} BF^的下标(1≤i≤t, 1≤j≤t),将更高的注意力权重分配给更近的时间段,则时间偏差
B F ^ B^{\hat F} BF^的公式为:
B F ^ ( i , j ) = { ⌊ ( i − j ) / p ⌋ , j ≤ i − ∞ , o t h e r w i s e (6) B^{\hat F}(i,j)= \begin{cases} \lfloor(i-j)/p\rfloor,\quad j\leq i\\ -\infty, \quad otherwise \end{cases} \tag{6} BF^(i,j)={⌊(i−j)/p⌋,j≤i−∞,otherwise(6)
采用MH注意机制,由H个平行缩放点积注意组成,从多个表示子空间中联合提取互补信息。将H个头的输出连接在一起,并通过参数矩阵 W F ^ W^{\hat F} WF^向前投影:
M H ( Q F ^ , K F ^ , V F ^ , B F ^ ) = C o n c a t ( h e a d 1 , . . . , h e a d H ) W F ^ , h e a d h = A t t ( Q h F ^ , K h F ^ , V h F ^ , B h F ^ ) B h F ^ = B F ^ ⋅ m (7) MH(Q^{\hat F},K^{\hat F},V^{\hat F},B^{\hat F})=Concat(head_1,...,head_H)W^{\hat F},\\ head_h=Att(Q^{\hat F}_h,K^{\hat F}_h,V^{\hat F}_h,B^{\hat F}_h) \tag{7} \\ B^{\hat F}_h=B^{\hat F}\cdot m MH(QF^,KF^,VF^,BF^)=Concat(head1,...,headH)WF^,headh=Att(QhF^,KhF^,VhF^,BhF^)BhF^=BF^⋅m(7)
m初始值为 2 − 2 ( − l o g 2 H + 3 ) 2^{-2^{(-log_2H+3)}} 2−2(−log2H+3),每次自乘一个初始值,例如H=4时,m值为 2 − 2 , 2 − 4 , 2 − 6 , 2 − 8 2^{-2},2^{-4},2^{-6},2^{-8} 2−2,2−4,2−6,2−8。 - 有偏跨模态MH注意:旨在结合Faceformer编码器的输出(语音特征)和有偏因果MH自我注意(运动特征)来对齐音频和运动模式。为此在查询键注意评分中添加了一个对齐偏差
B
A
B^A
BA(1≤i≤t, 1≤j≤kT):
B A ^ ( i , j ) = { 0 , k i ≤ j < k ( i + 1 ) − ∞ , o t h e r w i s e (8) B^{\hat A}(i,j)= \begin{cases} 0,\quad ki\leq j<k(i+1)\\ -\infty, \quad otherwise \end{cases} \tag{8} BA^(i,j)={0,ki≤j<k(i+1)−∞,otherwise(8)
若有偏因果MH自注意的输出为 F t ~ = ( f 1 ~ , . . . , f t ~ ) \tilde{F_t}=(\tilde{f_1},...,\tilde{f_t}) Ft~=(f1~,...,ft~), F t ~ \tilde{F_t} Ft~和 A k T A_{kT} AkT都被输入有偏跨模态注意层, A k T A_{kT} AkT被转换为两个独立的矩阵键 K A K^A KA和值 V A V^A VA, F ~ t \tilde F_t F~t被转换为查询 Q F ~ Q^{\tilde F} QF~,输出 V A V^A VA的加权和
A t t ( Q F ~ , K A , V A , B A ) = s o f t m a x ( Q F ~ ( K A ) T d k + B A ) V A (9) Att(Q^{\tilde F},K^A,V^A,B^A)=softmax(\frac{Q^{\tilde F}(K^A)^T}{\sqrt{d_k}}+B^A)V^A \tag{9} Att(QF~,KA,VA,BA)=softmax(dkQF~(KA)T+BA)VA(9)
有偏跨模态MH自注意也拓展到H个头部。最后通过运动解码器(v个输出的全连接层)将d维的隐藏状态投影回v维的3D顶点空间,得到预测的面部运动 y ^ t \hat y_t y^t - 训练和测试:不用teacher-forcing而是用自回归,最小化均方误差(MSE)来训练模型:
L M S E = ∑ t = 1 T ∑ v = 1 V ∣ ∣ y ^ t , v − y t , v ∣ ∣ 2 (10) L_{MSE}=\sum_{t=1}^T\sum_{v=1}^V||\hat y_{t,v}-y_{t,v}||^2 \tag{10} LMSE=t=1∑Tv=1∑V∣∣y^t,v−yt,v∣∣2(10)
V表示三维人脸网格的顶点数。
- 周期性位置编码(PPE):用于注入时间顺序信息,同时与ALiBi(线性偏差注意方法,通过在查询键注意评分上增加恒定偏差来提高泛化能力)兼容。修改了transformer的正弦位置编码方法,使其相对于表示周期的超参数p具有周期性:
实验
数据集:BIWI、VOCASET
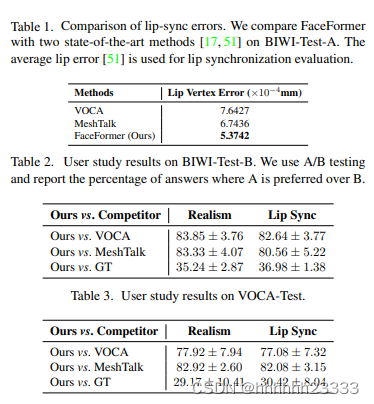
效果评估:
总结
- 提出了一种基于自回归变换的语音驱动3D面部动画架构。编码器有效地利用了自监督预训练的语音表示,内部的自注意可以捕获远程音频上下文依赖性。具有周期性位置编码策略的解码器注意模块可用于跨模态对齐和较长序列的泛化。
- 该模型的主要瓶颈是自注意机制的二次记忆和时间复杂度,不适合实时应用,需要提高效率。

















 4985
4985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









