







AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis
概述
效果视频
以一个目标说话人物的简短视频片段作为输入用于训练,首先提取视频帧,并利用相位分析技术,将图像分解为背景、头部和躯干区域,然后利用多帧光流估计对人像中的头部姿态参数进行回归。对于音频轨迹,采用预先训练好的深度语音模型DeepSpeech来提取时间序列特征。经过所有预处理,将音频特征和位姿参数作为输入条件,并将它们发送到隐式函数中。隐式函数模型由两个模块组成:第一个模块是对头部进行建模,继最近先进的神经辐射场设计之后,头部模型将头部区域视为前景像素,并沿多条光线预测颜色和密度值;第二个模块是人体躯干,在这个阶段,我们将躯干区域内的像素作为前景,三角形辐射场将存储隐式场景表示。隐式场景表示不仅受输入位姿参数的影响,而且还受音频信号的影响,通过这种方式,可以使用隐式模型来呈现高保真的结果。隐式函数将音频特征映射到神经辐射场后,使用体积渲染从神经辐射场渲染视觉人脸。
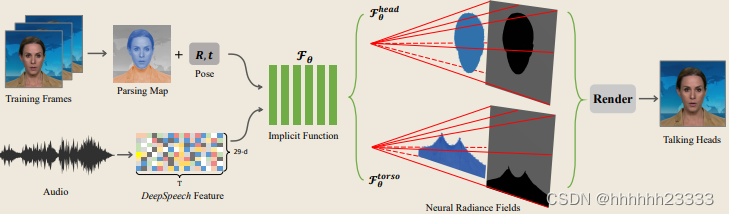
Method
- 说话头神经辐射场:使用条件隐式函数,以附加的音频码作为输入,给出了一个会说话的头部的条件辐射场。除了观看方向
d
d
d和3D位置
x
x
x,音频
a
a
a的语义特征将作为隐式函数
F
θ
F_θ
Fθ的另一个输入。
F
θ
F_θ
Fθ由多层感知器(MLP)实现的。有了所有的输入向量(a, d, x),网络将沿多条光线估计颜色值c和密度值σ。整个隐式函数可以表述为:
F θ : ( a , d , x ) → ( c , σ ) (1) F_{\theta}:(a,d,x)\rightarrow(c,\sigma) \tag{1} Fθ:(a,d,x)→(c,σ)(1)
使用和NeRF相同的隐式网络结构,包括位置编码。- 语义音频功能:使用DeepSpeech模型为每20ms的音频片段预测一个29维特征码,提取语义信息。几个连续帧的音频特征被联合发送到一个时域卷积网络,以消除原始输入中的噪声信号。具体来说,使用来自16个相邻帧的特征 a ∈ R 16 × 29 a∈R^{16×29} a∈R16×29来表示音频模态的当前状态。使用音频特征代替回归表达式系数或面部标记,有利于减轻中间翻译网络的训练成本,防止音频和视觉信号之间潜在的语义不匹配问题。
- 使用辐射场的体渲染:利用隐式
F
θ
F_θ
Fθ模型预测的颜色c和密度σ,采用体渲染,沿着投射到每个像素的光线累计采样的密度和RGB值,计算图像渲染结果的输出颜色。与NeRF一样,摄像机射线
r
(
t
)
=
o
+
t
d
r(t) = o + td
r(t)=o+td,摄像机中心为
o
o
o,观察方向为
d
d
d,近界
t
n
t_n
tn和远界
t
f
t_f
tf的期望颜色
C
C
C的取值为:
C ( r ; θ , Π , a ) = ∫ t n t f σ θ ( r ( t ) ) ⋅ c θ ( r ( t ) , d ) ⋅ T ( t ) d t (2) C(r;\theta,\Pi,a)=\int_{t_n}^{t_f}\sigma_{\theta}(r(t))\cdot c_{\theta}(r(t),d)\cdot T(t)dt \tag{2} C(r;θ,Π,a)=∫tntfσθ(r(t))⋅cθ(r(t),d)⋅T(t)dt(2)
其中 c θ ( ⋅ ) c_θ(·) cθ(⋅)和 σ θ ( ⋅ ) σ_θ(·) σθ(⋅)为上述隐函数 F θ F_θ Fθ的输出。 T ( t ) T(t) T(t)为沿光线从 t n t_n tn到 T T T的累计透射率:
T ( t ) = e x p ( − ∫ t n t σ ( r ( s ) ) d s ) (3) T(t)=exp(-\int_{t_n}^t\sigma(r(s))ds) \tag{3} T(t)=exp(−∫tntσ(r(s))ds)(3)
Π \Pi Π为人脸的估计刚性位姿参数,由旋转矩阵 R ∈ R 3 × 3 R∈R^{3×3} R∈R3×3和平移向量 t ∈ R 3 × 1 t∈R^{3×1} t∈R3×1表示,即 Π = R , t \Pi = {R, t} Π=R,t。 Π \Pi Π用于将采样点转换为规范空间。在训练阶段,只使用头部姿势信息,而不是任何3D面部形状的网络。使用两阶段集成策略,即首先使用粗网络来预测沿光线的密度,然后在细网络中对高密度区域的更多点进行采样。 - 特化NeRF表示:
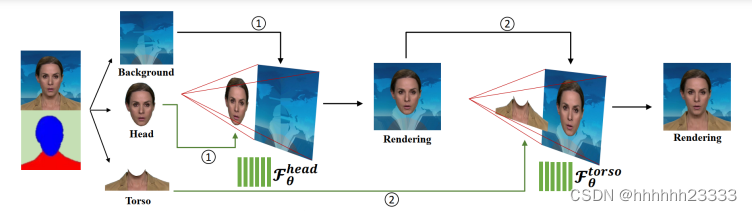
用两个单独的神经辐射场为头部和躯干这两个部分建模:首先利用自动人脸解析模型MaskGAN将训练图像分为静态背景、头部和躯干三部分。首先训练头部部分 F θ h e a d F_θ^{head} Fθhead的隐函数。在此步骤中,我们将解析映射确定的头部区域视为前景,其余区域视为背景。头部姿势 Π Π Π应用于沿光线投射到每个像素的采样点。假设射线上的最后一个样本位于背景上,其颜色固定,即射线对应的像素的颜色来自背景图像。然后将 F θ h e a d F^{head}_θ Fθhead渲染的图像转换为新的背景,躯干部分作为前景。然后训练第二隐式模型 F θ t o r s e F_θ^{torse} Fθtorse,在这个阶段,躯干区域没有可用的姿势参数。因此假设所有点都存在于规范空间中(即不使用头部姿势 Π Π Π转换它们),并添加面部姿势 Π Π Π作为辐射场预测的另一个输入条件(结合点位置x、观看方向d和音频特征a),即隐式地将头部姿势 Π Π Π作为一个附加输入,而不是使用 Π Π Π在 F θ t o r s o F_θ^{torso} Fθtorso内进行显式转换。在推理阶段,头部部分模型 F θ h e a d F^{head}_θ Fθhead和躯干部分模型 F θ t o r s o F^{torso}_θ Fθtorso接受相同的输入参数,包括音频条件编码a和姿态系数 Π Π Π。体渲染过程将首先通过头部模型积累所有像素的采样密度和RGB值。渲染的图像将覆盖静态背景上的前景头部区域。然后躯干模型通过预测躯干区域的前景像素来填补缺失的身体部分。一般来说,这种单独的神经辐射场表示设计有助于建模不一致的头部和上身运动,并产生自然的说话头部结果。 - 说话头视频编辑:由于两种神经辐射场都以语义音频特征和姿态系数为输入来控制说话内容和说话头的运动,我们的方法可以分别通过替换音频输入和调整姿态系数来实现音频驱动和姿态操纵的说话头视频生成。由于我们使用背景图像上对应的像素作为每条射线的最后一个样本,隐式网络学会了预测前景样本的低密度值,如果射线穿过背景像素,预测前景样本的高密度值。通过这种方式将前景和背景区域解耦,并通过替换背景图像来实现背景编辑。
- 训练细节:
- 数据集:对于每个目标人员收集一个带有音频轨道的短视频序列用于训练。平均视频长度为3-5分钟,所有视频都是25帧/秒。记录相机和背景都假设是静态的。在测试中,允许任意的音频输入,如来自不同身份、性别和语言的语音。
- 训练数据预处理:
- 网络与损失函数:神经辐射场网络有两个主要约束条件:
- 时间平滑滤波器:处理窗口大小为16的DeepSpeech,16个连续的音频特征将被发送到一个一维卷积网络中,以回归每帧潜在代码。为了保证音频信号内部的稳定性,采用自注意思想对连续音频编码训练时间滤波器。该滤波器采用具有softmax激活函数的一维卷积层实现。因此,最终的音频条件a由经过时间滤波的潜码给出。
- 将渲染图像约束为与训练真实图像相同的图像。设
I
r
∈
R
W
×
H
×
3
I_r∈R^{W×H×3}
Ir∈RW×H×3为渲染图像,
I
g
∈
R
W
×
H
×
3
I_g∈R^{W×H×3}
Ig∈RW×H×3为真实图像,优化目标是减小
I
r
I_r
Ir与
I
g
I_g
Ig之间的光测量重构误差。损失函数表述为:
L p h o t o ( θ ) = ∑ w = 0 W ∑ h = 0 H ∣ ∣ I r ( w , h ) − I g ( w , h ) ∣ ∣ 2 I r ( w , h ) = C ( r w , h ; θ , Π , a ) (4) L_{photo}(\theta)=\sum_{w=0}^W \sum_{h=0}^H||I_r(w,h)-I_g(w,h)||^2 \\ I_r(w,h)=C(r_{w,h};\theta,\Pi,a) \tag{4} Lphoto(θ)=w=0∑Wh=0∑H∣∣Ir(w,h)−Ig(w,h)∣∣2Ir(w,h)=C(rw,h;θ,Π,a)(4)
结论
- 提出基于NeRF的高保真说话头合成方法AD-NeRF,将人体肖像场景的神经辐射场分解为两个分支,分别建模头部和躯干,直接从音频信号合成人的头部和上身,而不依赖于中间表示。模型允许来自不同身份、性别和语言的任意音频输入,并支持自由的头部姿势操作,这是虚拟会议和数字人类中高度要求的功能。
- 在跨身份听觉驱动的结果中,由于训练语言和驱动语言之间的不一致,合成的口型有时看起来不自然。因为头部姿势和音频功能不能完全确定实际的躯干运动,有时躯干部分看起来很模糊。















 3826
3826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









