







数据集的选择(一)
来到实验室后,我就思考我想从图神经网络对脑部CT扫描来预测抑郁症患者这个方向入手来处理问题。但是当我看到论文中的数据集(ABIDE、FTD)这两个数据集都是图片的形式在网上出现的,而我需要的是时序的数字化后的数据集。对比了一下这个数据集的处理难度,我决定放弃,改成另外的一个方向(分子和细胞)。
我选择这个方向的理由主要是两个方面:1.这个方向的数据集都是数据的形式呈现的。2.要是做这个方面的实验可以发两个方向的论文一个就是生物,一个是化学。当然还可以是生化类的。接下来我就根据2022年6月到9月份的二区以上的论文中实验上使用的数据集在下面做一个简单的汇总:
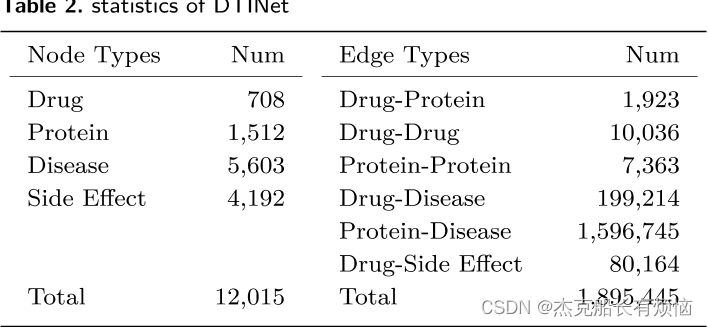
1. A heterogeneous network-based method with attentive meta-path extraction for predicting drug-target interactions
DTINet
2. Metapath Aggregated Graph Neural Network and Tripartite Heterogeneous Networks for Microbe-Disease Prediction.
在本研究中,我们整合了从不同来源获得的信息。首先,我们从Peryton (Skoufos等人,2020年)和MicroPhenoDB (Yao等人,2021年)收集微生物和疾病相关数据。其中,Peryton包含了43种疾病和1396种微生物之间超过7900种关系。MicroPhenoDB中的数据收集自一些公共数据集,如人类微生物疾病协会数据库(HMDAD;Kong等人,2017),Disbiome (Yorick等人,2018),毒力因子数据库(VFDB;Chen L. et al., 2016)等。MicroPhenoDB在515种疾病和1717种微生物之间有5565种关系。剔除相同疾病和微生物的冗余后,我们总共获得了538种疾病和2491种微生物之间的9202个关联。此外,我们从微生物-药物协会数据库(MDAD;Sun等人,2018)、drugVirus (Andersen等人,2020)和aBiofilm (Akanksha等人,2017),并删除冗余记录,总共获得132种微生物、1933种药物和3345种微生物药物关联。然后,我们从drugBank (Wishart et al., 2017)和比较毒理学基因组学数据库(CTD;Davis et al., 2012)数据库,去冗余后,我们获得了127种疾病和247种药物之间的9,604种相互作用。
3. DACPGTN: Drug ATC Code Prediction Method Based on Graph Transformer Network for Drug Discovery.
KEGG (Kanehisa and Goto, 2000)和Drugbank (Wishart et al., 2008)收集了与药物相关的靶蛋白和疾病,这两个数据库是公开的,涉及描述药物、疾病、靶蛋白及其相互作用的大量数据。
4. Learning size-adaptive molecular substructures for explainable drug-drug interaction prediction by substructure-aware graph neural network.
我们在drugbank和TWOSIDES两个真实数据集中评估了模型的性能。
- DrugBank是一个独特的生物信息学和化学信息学资源,它结合了详细的药物数据和全面的药物靶点信息它包含1706种药物和191 808个DDI元组。86种相互作用类型描述了一种药物如何影响另一种药物的代谢。每种药物都表示为简单的分子输入线输入系统(SMILES),我们使用RDKit将其转换为分子图。使用Wang等人描述的策略,DrugBank中的每个DDI元组都是一个阳性样本,从中生成一个阴性样本。38在DrugBank数据集中,每个药物对只与单一类型的相互作用相关。
- TWOSIDES由Zitnik等人构建。39对原始TWOSIDES数据集进行过滤和预处理。40它包含645种药物,963种相互作用类型,4 576 287个DDI元组。与DrugBank数据集相比,这些相互作用是在表型水平(例如,头痛、喉咙痛和其他),而不是代谢。阴性样本的生成过程与DrugBank数据集相同。
。阴性样本的生成过程与DrugBank数据集相同。















 3638
3638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









