







博主目前研一,研究大模型方向,具体点说的话是AI for science,但是大模型相关的论文都会看看。
每周组会导师都会让每个同学分享最新的论文1-2篇,按照下面的模板去总结,并且要求我们每篇论文不要讲的太啰嗦,要学会抓住重点,通过这种方式读论文,可以培养我们读论文的能力,提升学术品位。
组会大概已经进行了17周,但是最近3-4周才开始用这种模板去总结论文,感觉这样确实可以很快地把握住一篇工作。因此打算之后每周都把自己组会上分享的论文挪过来存个档,供以后阅读和学习。不会写很具体,只贴重要的文字和图片,组会的时候就是看着这个大纲分享论文的。
论文标题和作者

链接:https://arxiv.org/abs/2406.02536
标签:LLM;ICL
1. 研究内容
本文研究了如何通过缩放单一维度来缓解大语言模型(LLMs)处理长上下文时的位置偏差问题。
2. 研究动机
现有的方法在处理长上下文任务时,LLMs无法有效且一致地利用上下文中的所有信息,尤其容易忽略中间的关键信息,表现出明显的“中间丢失”的位置偏差现象。
3. 技术动机(Insight)
本文通过实验分析发现,除了位置嵌入外,因果掩码也会引入位置偏差。本文还通过实验发现,因果掩码可以导致与绝对位置相关的隐藏状态。因此,本文试图通过缩放”位置隐藏状态“来减弱因果掩码对位置偏差的影响。
4. 解决方案
现象
实验1:证实了注意力权重在transformer内部存在位置偏差
传统注意力权重计算公式:
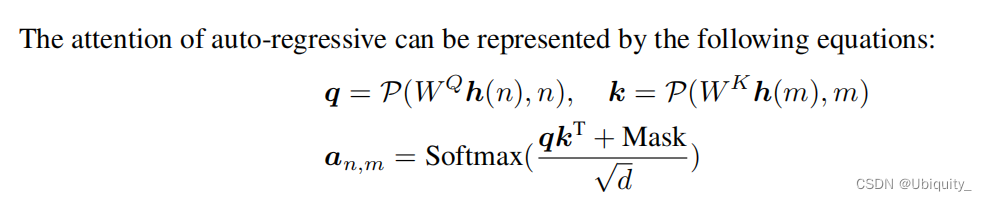
实验结果:
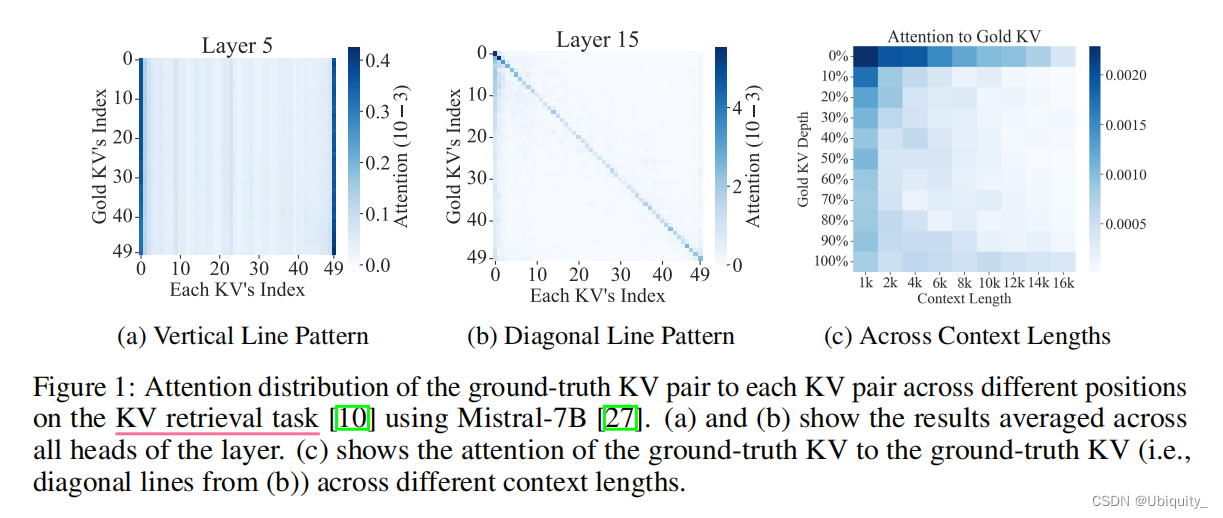
实验中的 KV 检索任务介绍:

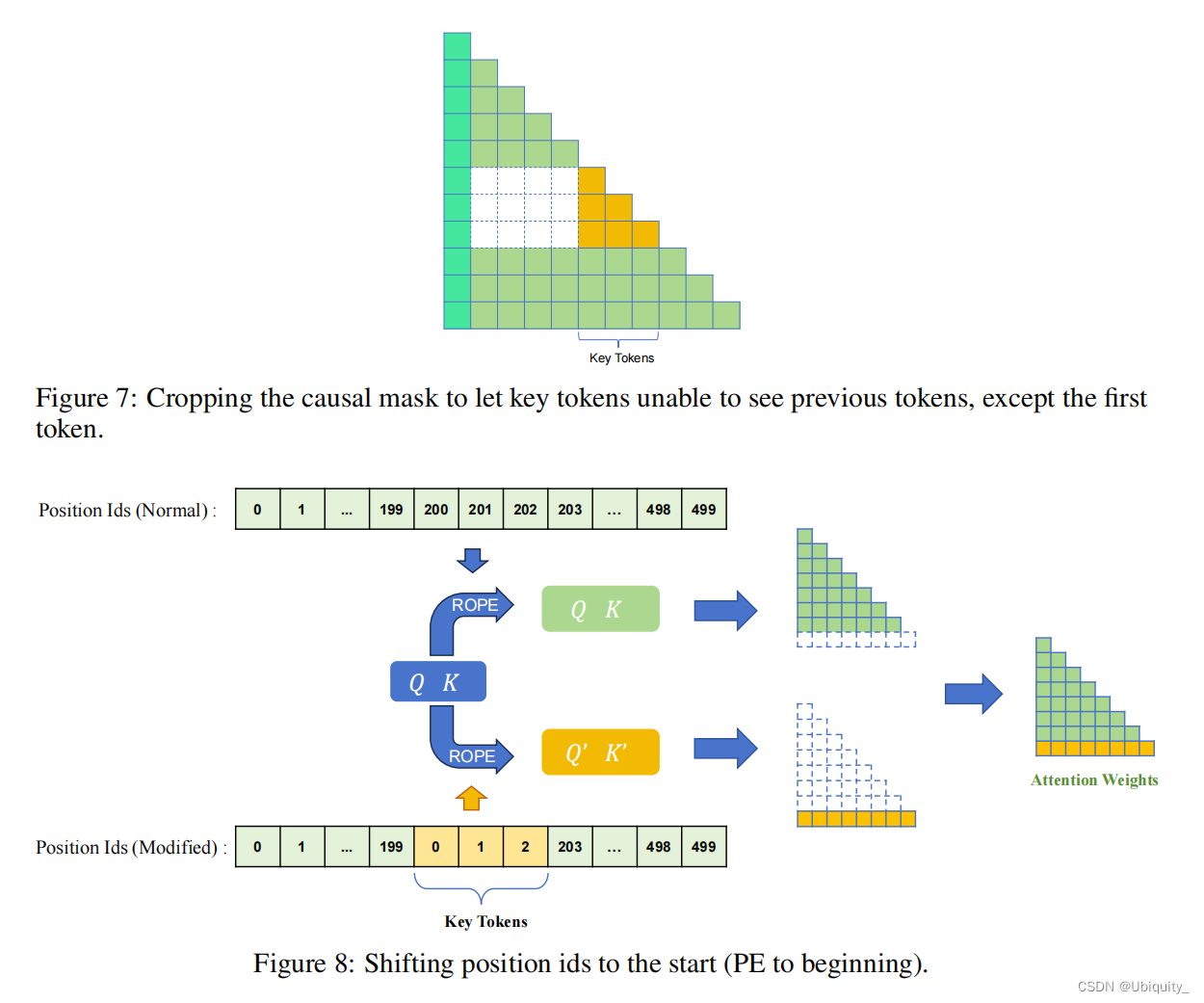
实验2:除位置嵌入(PE)外,因果掩码(Causal Mask)也会导致位置偏差。该实验对 PE 和 Mask 都做了处理前后对比。
- Crop Mask:裁剪掩码,修改因果掩码,使关键KV对只看到自身而不看到之前的tokens。
- PE to Beginning:将基础KV对的位置ID减少到与第一个KV对相同。
- PE to End:将基础KV对的位置ID增加到与最后一个KV对相同。
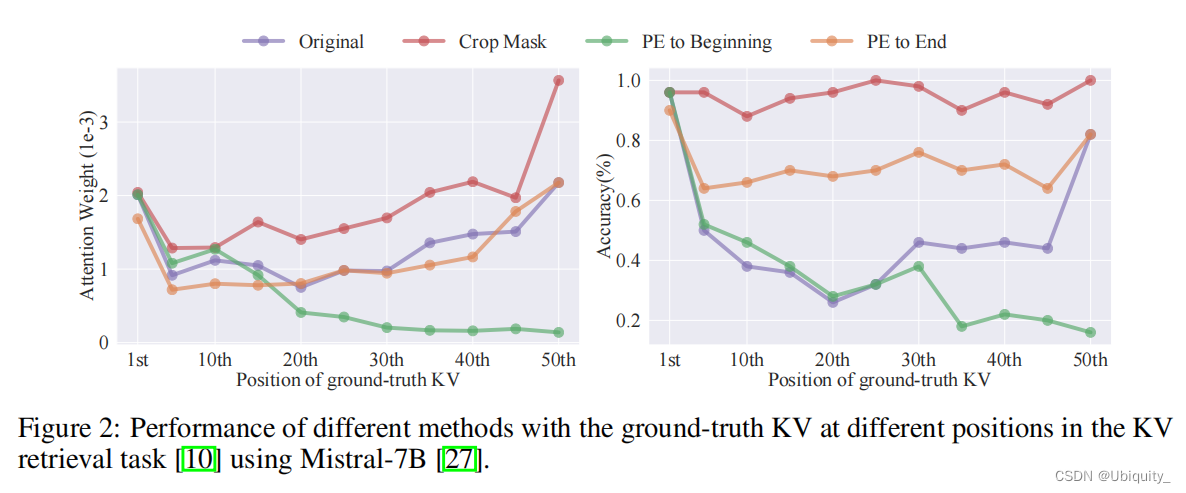
实验结果:
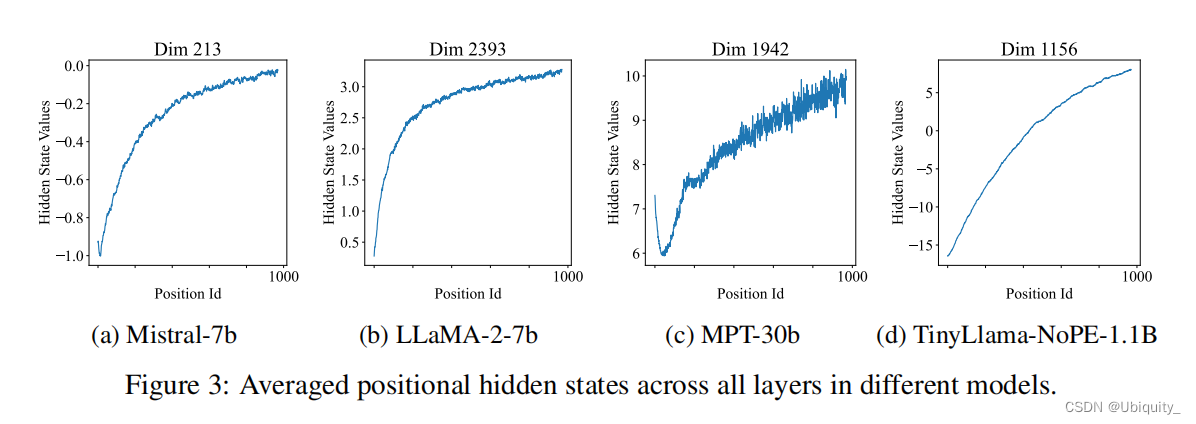
实验3:”位置隐藏状态“(Positional Hidden States)中包含着与绝对位置相关的信息,猜想是由因果掩码引起的
“位置隐藏状态”定义:

实验结果:
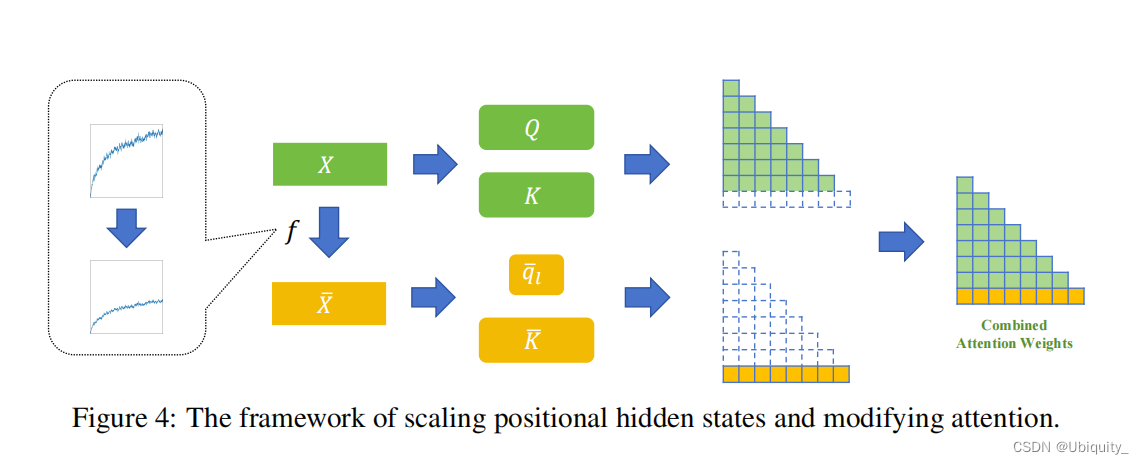
方法
虽然因果掩码对位置偏差有着深刻的影响,但提前及时知道有效信息的位置是不可行的,这使得修改因果掩码的方法难以设计。因此,本文提出了一种通过缩放位置隐藏状态来减轻位置偏差的方法
- 基于先验的位置隐藏搜索算法
目标:首先识别在多层中单调且平滑的隐藏状态维度,接着在验证集上评估这些维度的缩放影响,最终选择出能够最小化损失的缩放因子,从而优化长上下文语言模型处理长文本时的位置偏差问题。

算法伪代码:

- 对所搜索的位置隐藏状态进行缩放,从而减轻模型的位置偏差

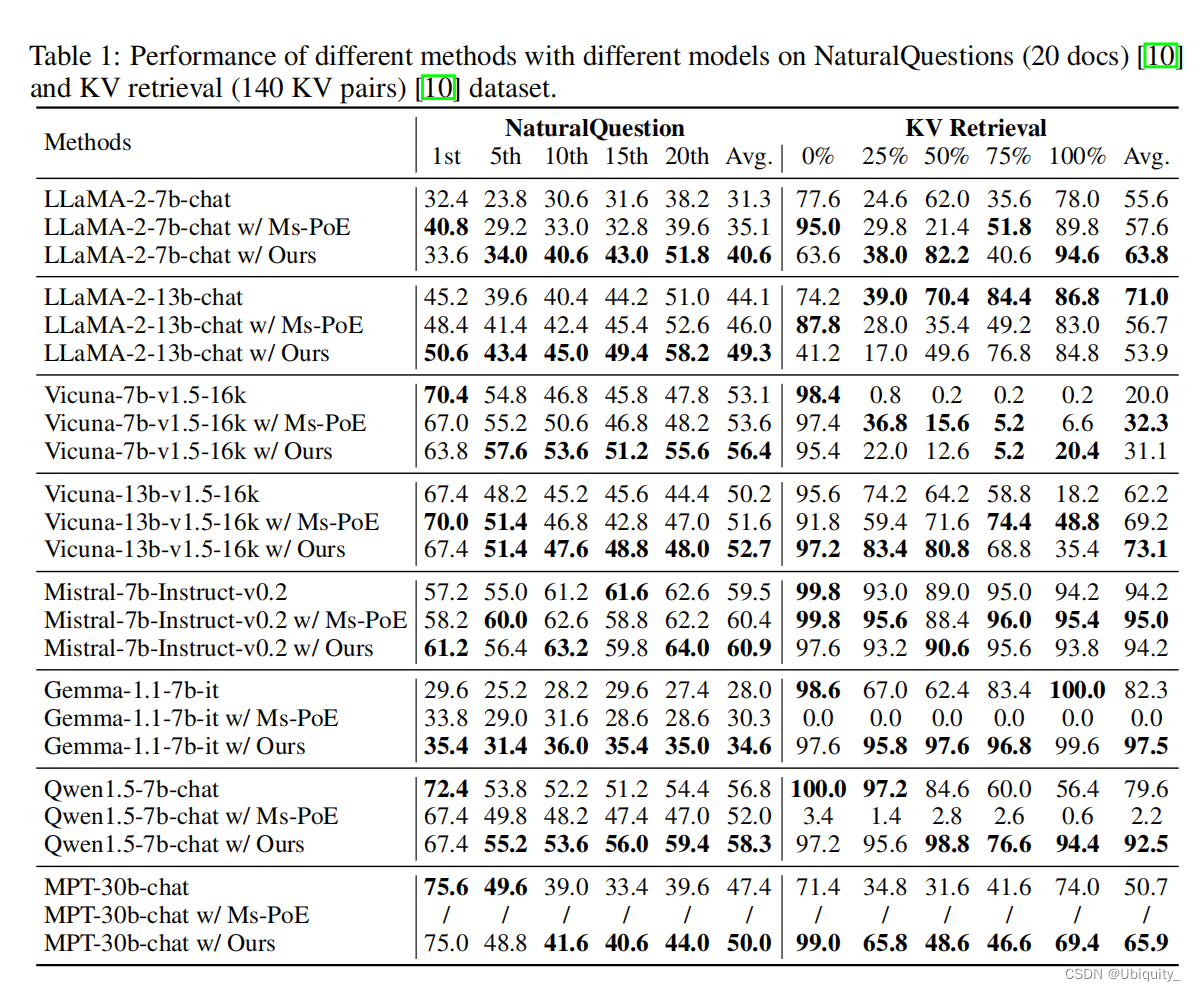
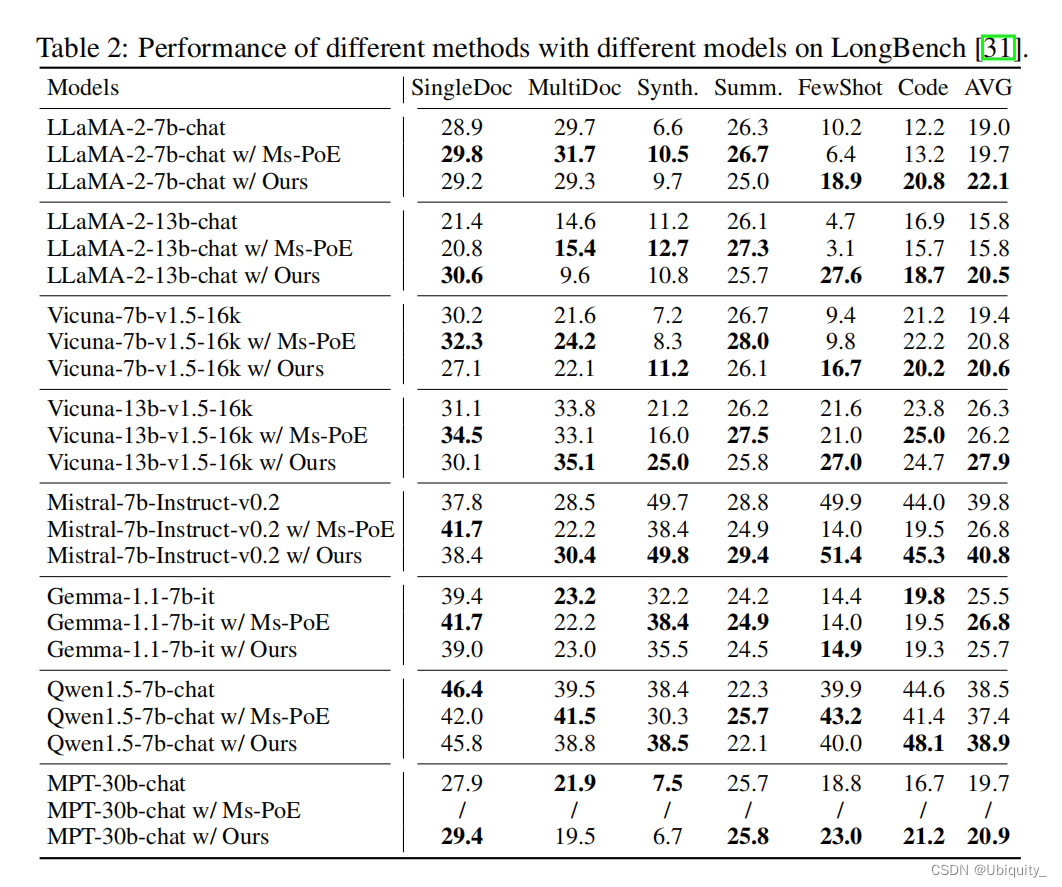
实验
效果不错,除了LLaMA-2-13b表现不太好,其它模型适配性都不错,有的任务可以提15个点。
5. 优点与潜力
提出的方法显著提高了LLMs在处理长文本时的性能,特别是在上下文中后部信息的理解上表现出色。未来,该方法有潜力进一步优化LLMs在更复杂的长上下文任务中的表现,并能适应不同类型的位置信息嵌入模型。















 234
234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









