







图 解
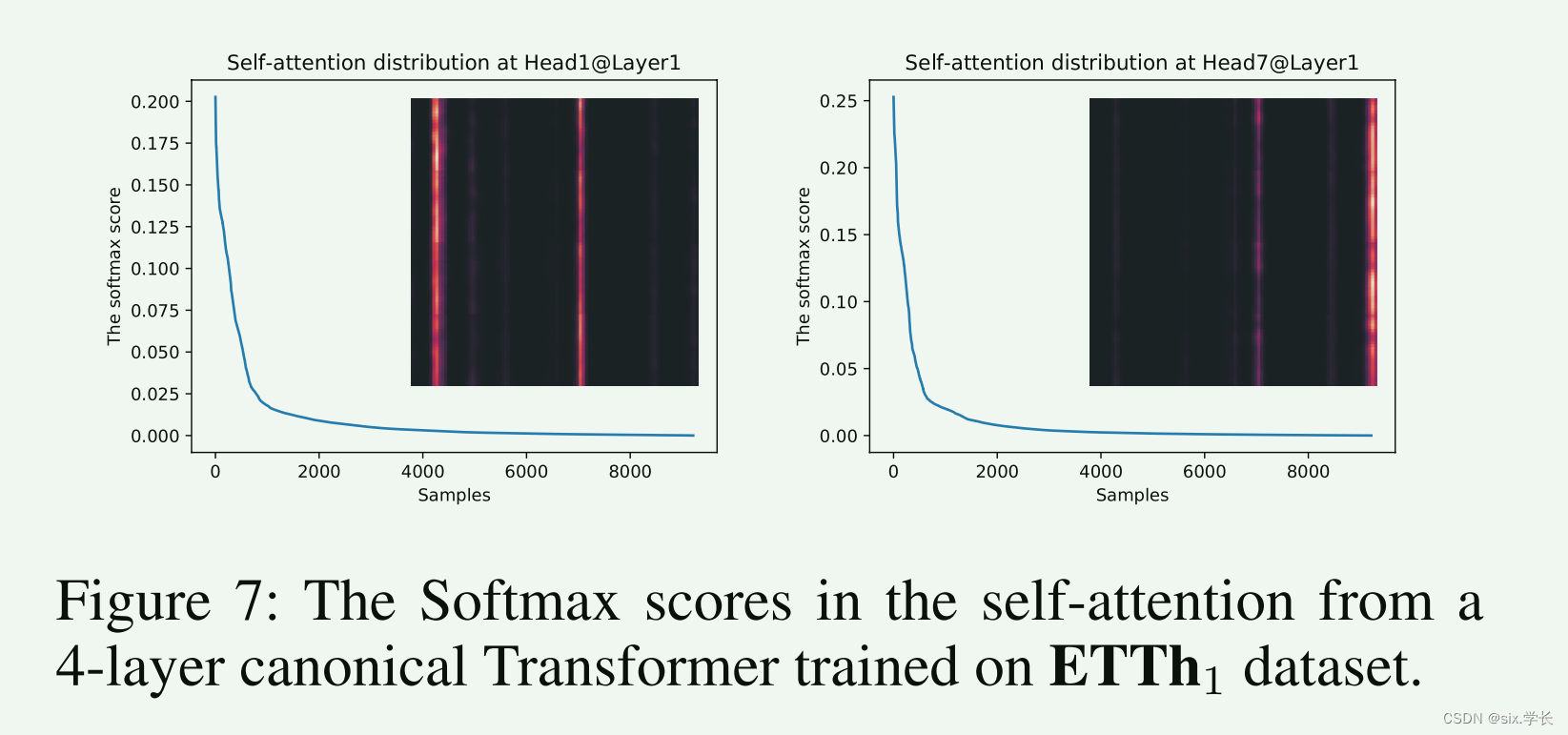
图 展示了在 ETTh1 数据集上训练的 4 层标准 Transformer 模型中的自注意力分布。具体来说,它显示了在第 1 层的第 1 头和第 7 头的自注意力分布及其 Softmax 得分。图中包含两部分内容:
- 左图:第 1 头自注意力分布
- 右图:第 7 头自注意力分布
关键观察点
-
长尾分布:
- 两个图的蓝色曲线都展示了注意力得分的分布,形成了长尾分布。少数的注意力得分较高,而大多数注意力得分较低。
- 这种分布表明,只有少数点积对在自注意力机制中起到了主要作用,而其他大多数点积对的贡献很小。
-
热力图:
- 每个图中的热力图显示了注意力得分的分布情况。红色表示高注意力得分,黑色表示低注意力得分。
- 热力图中的竖线表示在某些位置上有较高的注意力得分,这些位置是模型关注的关键部分。
详细分析
左图:第 1 头自注意力分布
- Softmax 得分曲线:纵轴表示 Softmax 得分,横轴表示样本数量。从曲线可以看出,大多数得分非常低,少数得分较高,形成长尾分布。
- 热力图:热力图中的红色竖线表示在这些位置上有较高的注意力得分。这些位置是模型在第 1 头中高度关注的。
右图:第 7 头自注意力分布
- Softmax 得分曲线:纵轴表示 Softmax 得分,横轴表示样本数量。从曲线可以看出,大多数得分非常低,少数得分较高,形成长尾分布。
- 热力图:热力图中的红色竖线表示在这些位置上有较高的注意力得分。这些位置是模型在第 7 头中高度关注的。
总结
-
长尾分布的意义:
- 长尾分布表明模型在处理数据时会集中注意力于少数关键部分,这些部分对模型的决策有重大影响。
- 大多数注意力得分较低的部分可以在计算时被忽略,从而提高模型的计算效率。
-
热力图的意义:
- 热力图显示了自注意力机制在不同位置上的关注度。红色竖线的出现位置是模型认为重要的时刻或特征。
- 通过分析这些高关注位置,可以理解模型在决策时关注的关键因素。
这张图帮助我们理解 Transformer 模型的自注意力机制如何在处理 ETTh1 数据集时分配注意力,从而提高模型的预测能力和效率。















 3374
3374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









