







这节课讲DeepLabv3+模型,及前身DeepLabv3模型,两篇论文来自Google的同一个团队。
参考资料
DeepLabv3+,被引1000+
DeepLabv3,被引1000+
Pytorch DeepLabv3+实现,Star 1.5k
我们讲1.模型原理2.代码实现
from PIL import Image
from IPython import display
import torch.nn as nn
import torch
第一部分,模型原理
背景知识
整体架构
背景知识
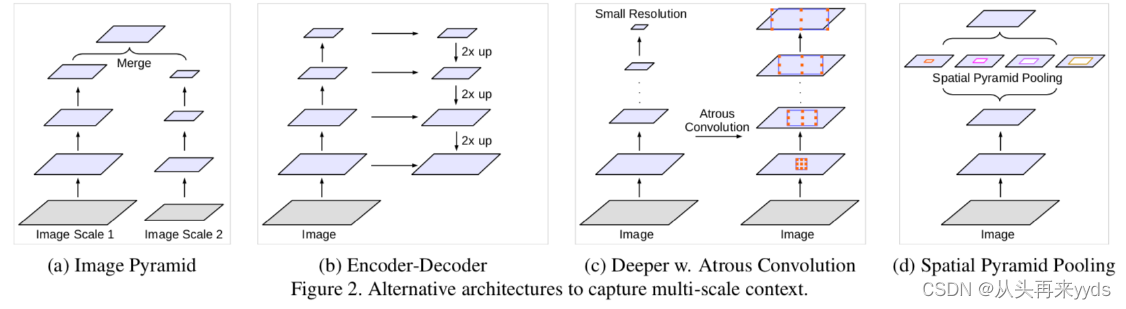
图像任务中 捕捉多尺度的图像信息很重要。通常有以下几种网络结构:
图a,一个相同的网络,共享权重,应用到不同尺度的图片上提取特征。对于尺寸小的图片输入,提取全局图像信息;对于尺寸大的图片输入,提取局部图像信息。最后将多尺度的图像信息融合。
图b,包含两个部分,下采样部分中图片尺寸逐层降低,浅层提取局部图像信息,深层提取全局图像信息;上采样中多尺度的图片特征合并,逐层还原图片尺寸。
图c,
图d,SPP层采用多个不同比率(rate)的Atrous convolution,并行作用在特征图上,比率(rate)较大的卷积提取相对全局信息,较小的卷积提取相对局部的信息,最后将多个特征图进行合并。下面介绍"Atrous convolution"。
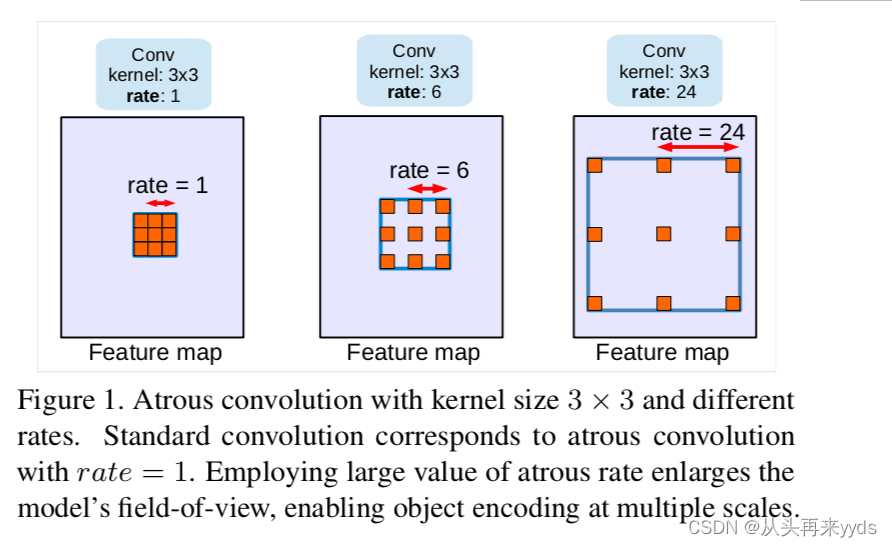
什么是"Atrous convolution"?(又叫"dilated convolution",回忆我们在pytorch的conv2d中的参数dilation=1)
一个卷积核中,相邻两个元素之间存在间隔,间隙中存在几个空白的元素,权重为0,不对图像做卷积
假如一个 3×3 的卷积,dilation rate分别为1、6、24,这三个卷积核内同样包含9个元素,对图像做9个像素点的计算
不额外增加计算量
dilation rate越大,扩大了卷积核的视野范围
dilation rate=1时就是我们常用的标准卷积核
多种dilation rate的卷积核能够捕捉多种尺度下的物体特征
dilation rate为1代表两个红色像素之间距离为1个像素点
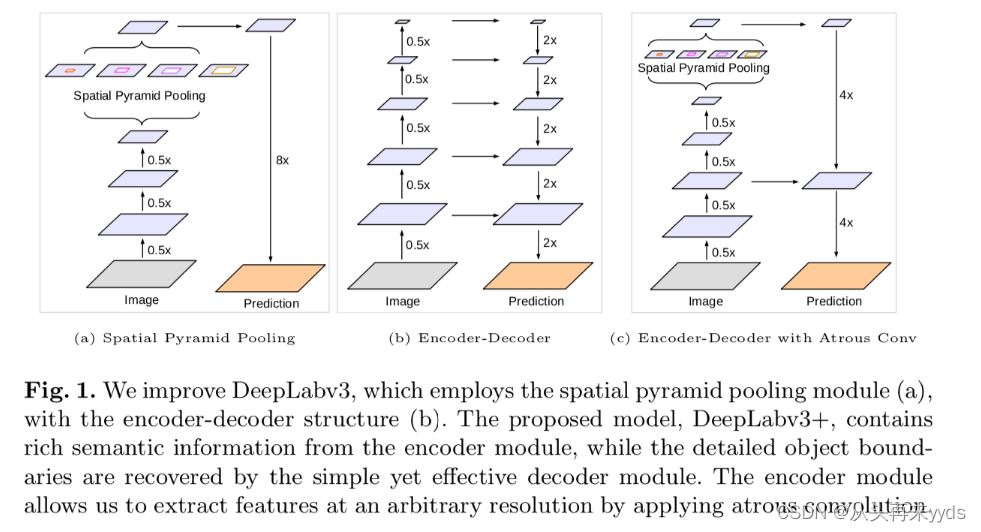
什么叫"ASPP"模块?
多个不同比率(rate)的Atrous convolution作用在特征图上,提取多尺度下图像特征,进行合并的结构叫做"ASPP"模块。例如下图中(a)(c)中,全称"Spatial Pyramid Pooling"。
DeepLabv3网络结构是什么?下图(a)
输入图片先进入Encoder层提取特征
对特征图进行Atrous convolution操作,提取多尺度特征图后合并(ASPP模块)
模型学习到的图像分割其实是在降低8倍分辨率图片上进行的
还原图像尺寸输出Mask(比率8倍,例如 64×8=512 )
DeepLabv3改进点:
借鉴UNet等Encoder-Decoder结构中Skip Connection思想,将更多底层特征图融入到Decoder中
DeepLabv3+网络结构是什么?下图(c)
整体结构与DeepLabv3雷同,设计新的Decoder结构
Decoder中先将ASPP模块特征图还原4倍
将Ecoder中底层特征图与Decoder中特征图合并
将合并后特征图还原4倍,输出Mask
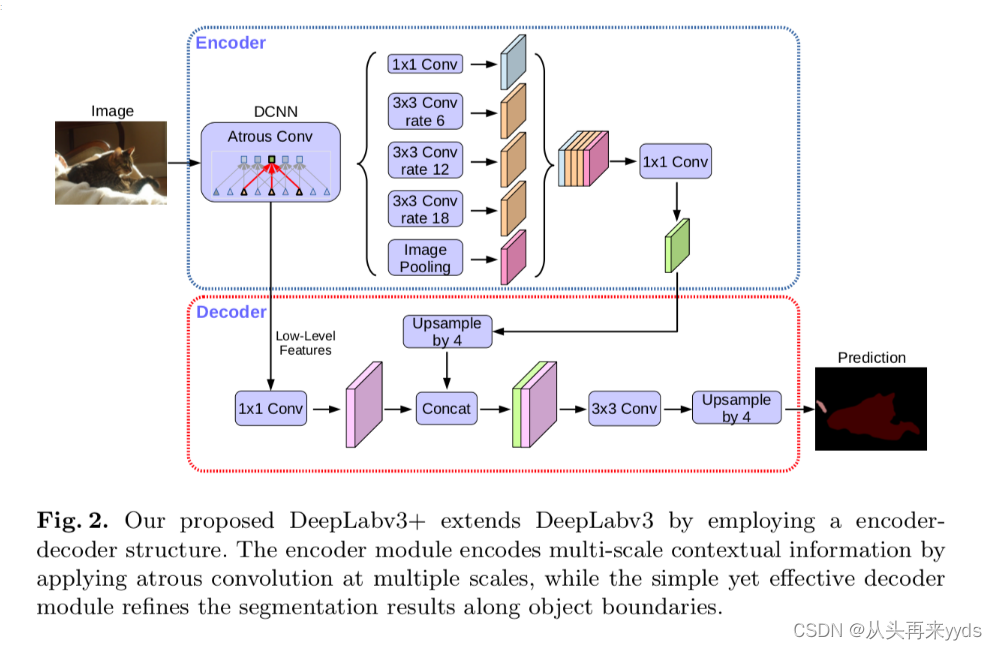
整体架构
输入图片,进入Ecoder层提取特征图,作者使用Resnet101、Modified Aligned Xception
进入ASPP模块,作者使用1个 1×1 卷积、3个 3×3 的Atrous convolution分别比率为6、12、18,以及一个图像全局的Pooling操作(为了克服当比率较大时Atrous convolution效果不好)
合并Ecoder特征图,使用一个 1×1 的卷积
上采样4倍
对底层特征图加一个 1×1 的卷积降低channel数,与Encoder特征图合并,进入 3×3 卷积层矫正分割效果(底层特征图通常256、512层,与Encoder特征图合并中层数占比过高,减损了Encoder特征图丰富的信息)
将分割上采样4倍还原图像尺寸
当rate特别大时,举一个极端的例子,当大到卷积核尺寸与特征图一样大时,3x3卷积的9个顶点在图像上,而计算的只是特征图的中间的像素点做了计算,即使卷积核在图像范围内,有效的卷积操作数越来越少,所以当rate越来越大时,卷积不太好,所以加了一个image pooling提取整张图片的特征图。
还有一个细节需要注意。
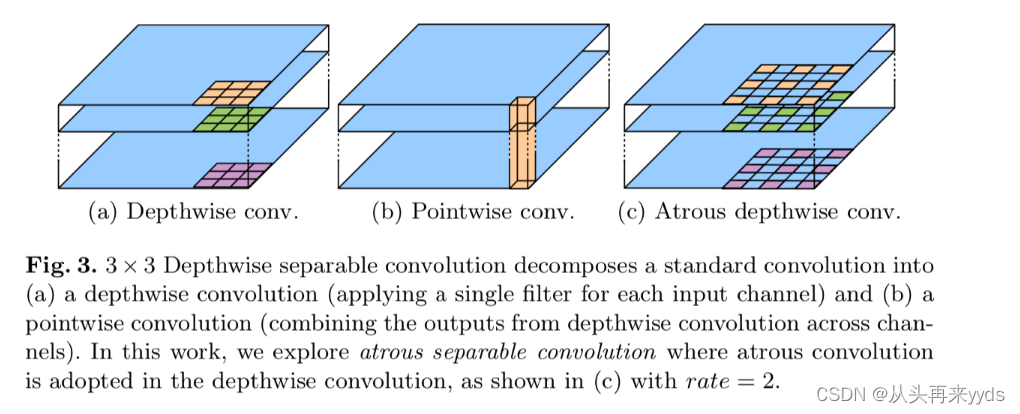
"Depthwise separable convolution"是什么?
图(a)一个 3×3 的卷积作用在每一个channel上,计算后每一个channel在每一个像素点位置上得到一个数值。几何平面内的操作。
图(b)将所有channel的每一个对应像素点位置的数值合并,得到一个数值,作为这个像素位置上的卷积结果。几何第三维度上的操作。
图(c)作者提出使用Atrous卷积核进行以上两步Depthwise separable convolution操作,称为"atrous separable convolution"
%%writefile resnet.py
import math
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, dilation=1, downsample=None, BatchNorm=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = BatchNorm(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
dilation=dilation, padding=dilation, bias=False)
self.bn2 = BatchNorm(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = BatchNorm(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
self.dilation = dilation
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, output_stride, BatchNorm, pretrained=True):
self.inplanes = 64
super(ResNet, self).__init__()
blocks = [1, 2, 4]
if output_stride == 16:
strides = [1, 2, 2, 1]
dilations = [1, 1, 1, 2]
elif output_stride == 8:
strides = [1, 2, 1, 1]
dilations = [1, 1, 2, 4]
else:
raise NotImplementedError
# Modules
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = BatchNorm(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 782
782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









