







一.摘要
本文在进行语义分割任务时将空间金字塔池化(SPP)模块或encoder-decoder结构引入到深度神经网络中。以前的网络通过对输入的feature map使用多种尺度的卷积核或者池化操作以及多种感受野能够编码出多尺度的环境信息。而之后的一些工作中提出的网络通过逐渐恢复空间信息能够捕获更加精细的物体边界。在本文中,将以上两种优势(多尺度特征+恢复空间信息)进行结合。特别地,本文提出的deeplabv3+在deeplabv3的基础上加入了简单却有效的decoder模块去细化分割结果,特别是物体的边界。本文进一步探索了Xception模型并且将深度可分离卷积应用在空洞空间金字塔池化(ASPP)以及decoder模块中,从而构造出了更快和更强的encoder-decoder网络。
二.方法
这部分简单介绍空洞卷积以及深度可分离卷积。然后在探讨本文提出的附加在encoder模块之后的decoder模块之前先来回顾DeepLabv3,Deeplabv3用来当作本文提出模型的encoder模块。
2.1包含空洞卷积的encoder-decoder
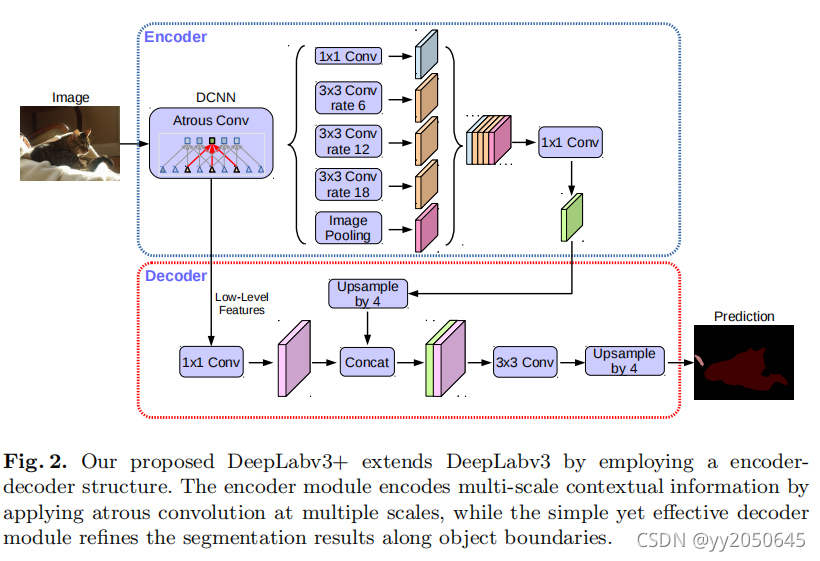
上图为本文提出的deeplabv3+整体模型结构,可以看出整体是基于encoder-decoder架构的,其中用到了空洞卷积和金字塔模块,下面具体介绍各个模块。
空洞卷积:
空洞卷积是一个能够有效控制深度神经网络输出的feature map的分辨率的工具以及能够调整卷积核的感受野从而捕获多尺度信息,空洞卷积是标准卷积的一个扩展。在一个二维卷积中,对于卷积输出的特征上的每个位置
以及对应的卷积核
,对于输入
,空洞卷积的计算如下所示:
上式中为空洞率,表示卷积核在卷积操作的输入
上的取样步长;
表示卷积核参数的位置,例如卷积核尺寸为3,则
;
表示卷积核尺寸(论文中公式上没有,在这里为了表示清晰加入)。更直观的空洞卷积如下图所示:
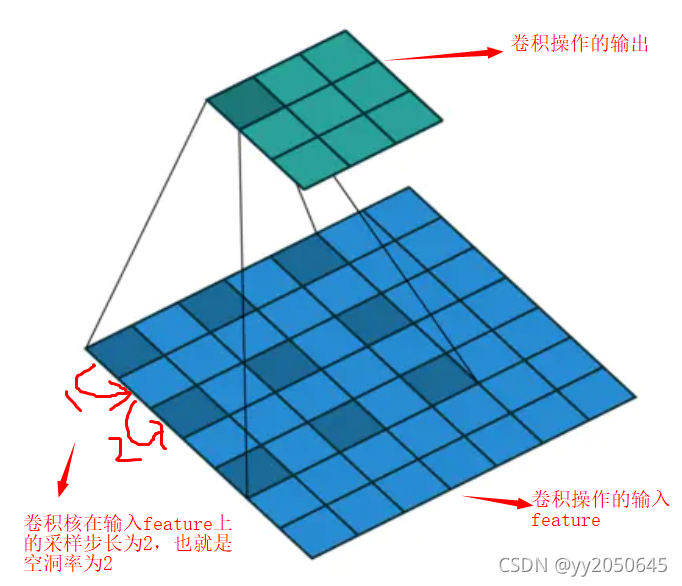
不难看出,标准卷积就是空洞率为1的空洞卷积。卷积核的感受野随着空洞率的改变随之也会发生改变。
深度可分离卷积:
深度可分离卷积将一个标准卷积拆分为深度卷积+1*1卷积,极大的减少了计算复杂度。特别地,深度卷积独立的为输入feature的每个channel做卷积操作,然后使用1*1的卷积对深度卷积的输出进行channel间进行融合操作,这样就替代了一个标准卷积操作,即融合了空间信息,也融合了不同通道间的信息。在之前的一些工作中,已经能够将空洞卷积融入到深度可分离卷积中,如下图所示:
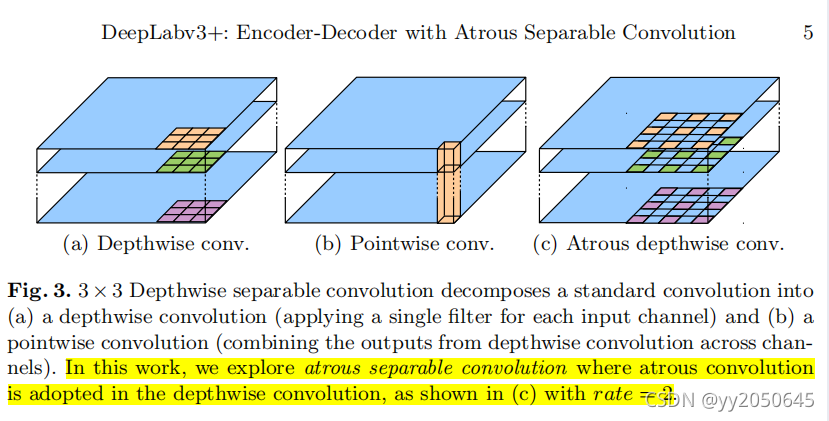
上图中(a)就是之前提到的深度卷积,单独的为每个channel进行卷积操作;(b)就是之前提到的1*1卷积用来融合channel间的信息。(a)和(b)就组成了深度可分离卷积。那如果将(a)中的标准卷积操作替换为空洞卷积,如图(c)所示就实现了带有空洞卷积的深度可分离卷积,本文称之为空洞可分离卷积(atrous seperable convolution)。本文应用空洞可分离卷积极大的减少所提出模型的计算复杂度与此同时维持了与原模型相似或者更好的模型效果。
DeepLabv3作为encoder:
Deeplabv3使用了空洞卷积去对深度神经网络输出的任意分辨率的feature进行特征提取。这里使用输出步长(output stride)表示模型输入图像和输出的feature map(在全局池化或全连接层之前)的空间分辨率的比值。对于分类任务,最终feature map的空间分辨率往往是模型输入图像的1/32,因此输出步长为32。对于语义分割任务来说,通过移除网络最后1到2个模块的步长以及相应地使用空洞卷积(例如对最后两个网络模块采用空洞率为2和4的空洞卷积从而实现输出步长为8)从而减小整个模型的输出步长从而达到输出步长为8或16,这样就能够提取到更稠密的特征。此外,deeplabv3增加了带有图像级别特征的空洞空间金字塔模块(ASPP),空间金字塔模块(ASPP)能够通过不同的空洞率获取多尺度卷积特征。本文使用原始deeplabv3的logits模块之前最后输出的feature map作为本文encoder-decoder中encoder部分的输出。需要注意的是,encoder输出的feature map包含256个通道以及丰富的语义信息。除此之外,根据计算能力可以采用空洞卷积在任意分辨率的输入上提取特征。
提出的decoder:
deeplabv3作为encoder输出的features通常输出步长为16,在之前的研究工作中,feature map通过双线性插值上采样16倍来将输出feature map恢复为模型输入尺寸,可以将其看作是一个简单的decoder模块。然而,这种简单的decoder模块可能并不能够很好的恢复物体分割细节。因此本文提出了一个简单但是有效的decoder模块,2.1中deeplabv3+整体结构图中所示,encoder输出的特征首先进行4倍的双线性插值上采样,然后和encoder中backbone中拥有相同尺寸的低级别(浅层)特征(例如Resnet-101的Conv2模块的输出)进行通道维度的拼接,在拼接之前首先对低级别特征进行1*1卷积,目的是为了减小低级别特征的通道数目,因为低级别特征通常含有大量的通道数目(例如256或512),这样底级别特征的重要性可能会超过encoder输出的富有语义信息的特征(在本文模型中只有256个通道)并且使得训练更加困难。在将encoder输出特征和低级别特征拼接之后,对拼接结果进行了几个3*3卷积操作去细化特征,并随后又接了一个4倍的双线性插值上采样。在之后的实验中证明了,当encoder的输出步长为16时可以达到速度和精度的最好的权衡。当encoder的输出步长为8时模型效果略有提升,但也相应增加了额外的计算复杂度代价。
2.2改进Aligned Xception
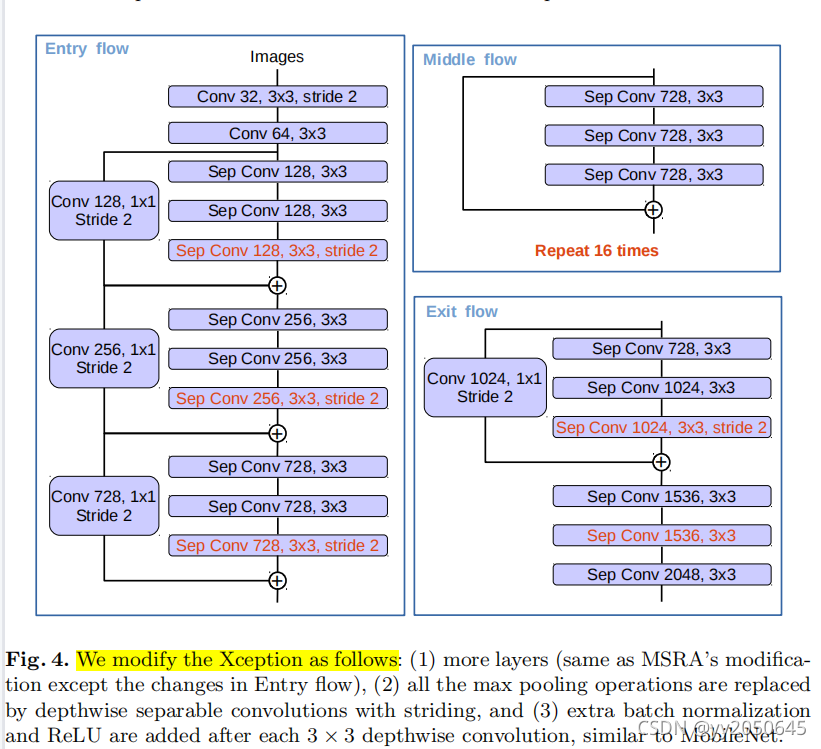
Xception模型在ImageNet上已经展示了不错的图像分类结果并有着较快的计算速度。最近,MSRA团队对Xception模型做了一些改动(称为Aligned Xception)以及进一步的推动了在目标检测任务上的表现。受这些发现的启发,本文沿着相同的方向去采用Xception模型来进行语义分割任务。特别地,我们在MSRA的修改上做了一些变动,分别为(1)更深的Xception,这个变动借鉴了以前的一些研究工作,但是不同的是,为了更快的计算以及高效的内存运用本文没有修改Xception的输入流网络结构(entry flow network structure);(2)最大池化操作通过使用带有一定步长的深度可分离卷积进行替代,也可以将深度可分离卷积替换为前文所说的空洞可分离卷积去在任意分辨率的输入上提取特征(或者另一种选择就是使用带有空洞率的最大池化操作替换原始的池化操作)。(3)在每一个3*3的深度卷积之后添加额外的batch normalization以及ReLU操作,这与MobileNet的设计类似。修改后的Xception整体结构如下图所示:
三.实验验证
本文利用ImageNet-1k预训练的Resnet-101或上文中修改后的aligned Xception去使用空洞卷积提取稠密特征。
训练时采用了“poly”学习率策略以及初始学习率设置为0.007,图像尺寸为513*513。模型训练时端到端的。
3.1decoder设计选择
定义“DeepLabv3 feature map”作为Deeplabv3最后输出的feature map(例如,features包含ASPP特征以及图像级别的特征),[k*k,f]作为卷积操作,表示卷积核尺寸为k*k,共有f个卷积核(即卷积输出feature map的通道数为f)。
当采用输出步长为16时,基于Resnet-101的DeepLabv3在训练和测试中对logits均采用16倍的双线性插值。这种简单的双线性插值方式可以认为时一种简单的decoder设计,在PASCAL VOC2012验证集上得到了77.21%的精度,比不用这种简单的decoder方式(例如直接将groud truth降采样来保证和网络输出尺寸相同)提升了1.2个百分点。为了提升这种简单的baseline,本文剔提出的“Deeplabv3+”在encoder输出后添加了decoder模块,如前文中DeepLabv3+整体结构图中所示。在decoder模块中,本文想了3个不同的设计方式,(1)1*1卷积减少encoder的低级别特征通道数;(2)3*3卷积被运用去获取更加精准的分割结果;(3)什么encoder的低级别特征应当被应用。
为了验证decoder中的1*1卷积的效果,本文采用Resnet-101网络的Conv2特征作为低级别特征。采用1*1卷积对低级别特征减少通道数,减少为不同通道数目的模型效果如下表所示:

可以看到,当通道数目降低为32或48时模型效果较好,因此对低级别特征采用[1*1,48]的卷积操作来减少低级别特征通道数目。
之后设计了decoder的3*3卷积结构,不同的设计效果如下表所示:
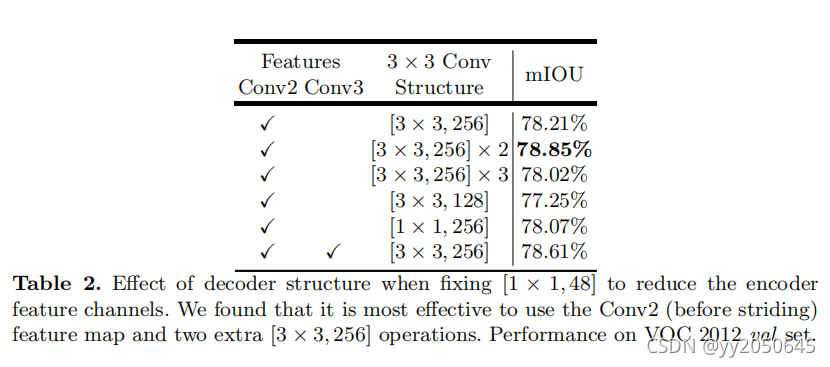
本文发现,在拼接Conv2特征和“Deeplabv3 feature map”后,采用2个3*3,卷积核个数为256的卷积操作效果要优于简单的使用1个或3个卷积操作。并发现,将卷积核数目从256变至128或卷积核从3*3变为1*1均会降低模型表现。随后还做测试了同时使用Conv2以及Conv3特征,但发现效果并不明显,因此最终采用了简单而有效的decoder:利用减少通道数的低级别特征(Conv2特征)和“Deeplabv3 feature map”进行拼接,然后进行2个[3*3,256]的卷积操作。
3.2Resnet-101作为backbone网络
当使用Resnet-101作为DeepLabv3+的backbone时,为了比较精度和速度的变化,观察了mIOU以及Multiply-Adds。得益于空洞卷积,模型在训练时能够在不同分辨率下获取特征以及在模型验证时使用单一模型。
Baseline:
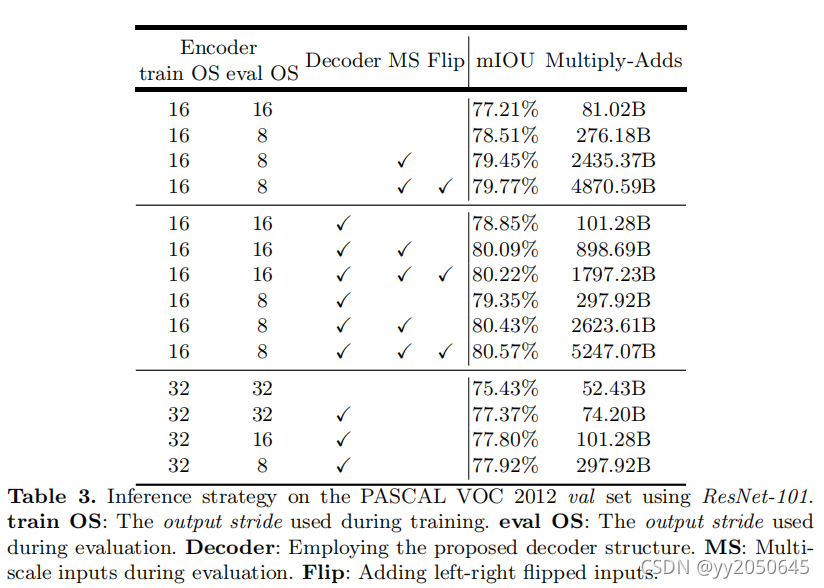
上表中train OS表示训练时的输出步长,eval OS表示验证时的输出步长。Decoder表示是否使用本文提出的decoder模块,MS表示验证时模型使用多尺度输入,Flip表示模型输入时添加左右反转输入。
上表中第一大行(前4小行)展示了采用更小的输出步长(输出步长为8时)获取更稠密特征或者采用多尺度输入以及采用decoder模块、输入图像反转等操作时的模型效果。其中采用图像反转输入模型将模型计算复杂度变为原来的两倍,但是效果提升很小。
添加decoder:
上表中第二大行采用了本文提出的decoder结构,呈现了验证时不同的输出步长(8或16)或采用多尺度输入或图像反转时模型效果。
粗粒度feature maps:
进行了实验模型训练时采用输出步长为32(例如在训练时没有采用空洞卷积)来达到更快的计算速度。在上表中第三大行展示了在训练时采用输出步长为32以及在验证时采用输出步长为8~32,以采用decoder和不采用decoder时的模型效果。
3.3Xception作为backbone网络
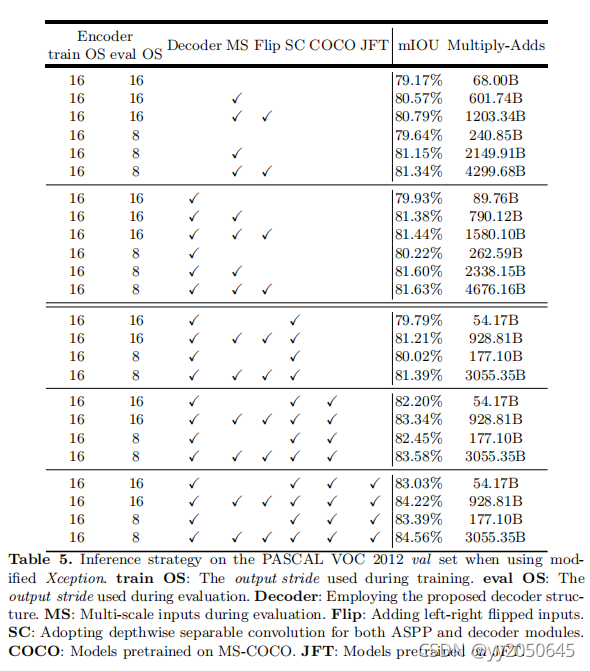
如上表所示为Xception作为backbone时的一些实验效果,与Resnet-101的类似,这里就不细讲了,需要说明的是,可以发现表中多了一些操作,其中SC表示是否采用深度可分离卷积在ASPP以及decoder模块中;COCO表示模型是否在MS-COCO上预训练;JFT表示模型是否在JFT上预训练。
四.实验效果


















 6335
6335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









