







1.过拟合问题
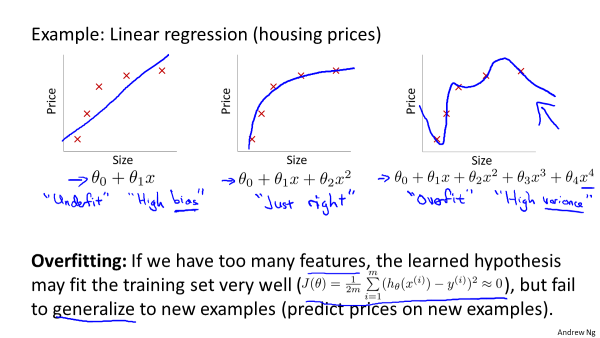
如图所示:第一个模型是线性的,属于欠拟合,不能很好的适应数据集,而第3个则是一个高次方的模型,过于拟合原始数据,从而不能很好的预测数据,属于欠拟合。也不难看出,当x的次数越高,训练出来的模型就会对数据集拟合的越好,但是其预测效果就会变差。
解决方案:
①减少特征的数量,丢弃掉一些非必要的特征。
②正则化。保留所有特征,减小模型参数。
2.代价函数
在上面图中第三个模型为:
h
θ
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
2
+
θ
3
x
3
3
+
θ
4
x
4
4
h_{\theta(x)}=\theta_{0}+\theta_{1}x_{1}+\theta_{2}x_{2}^{2}+\theta_{3}x_{3}^{3}+\theta_{4}x_{4}^{4}
hθ(x)=θ0+θ1x1+θ2x22+θ3x33+θ4x44.由于高次方项,是我们的模型产生了过拟合,所以如果让这些高次方项的系数接近与0的话,就能很好的拟合数据了。所以我们要修改代价函数,修改后的代价函数为:
J
(
θ
)
=
1
2
m
[
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
θ
3
2
+
λ
θ
4
2
]
J(\theta)=\frac{1}{2m}[\sum_{i=1}^{m}{(h_{\theta}(x^{(i)})-y^{(i)})^{2}}+\lambda\theta_{3}^{2}+\lambda\theta_{4}^{2}]
J(θ)=2m1[∑i=1m(hθ(x(i))−y(i))2+λθ32+λθ42]
如果
λ
=
1000
\lambda=1000
λ=1000,则要想使代价函数最小,
θ
3
,
θ
4
\theta_{3},\theta_{4}
θ3,θ4就约等于0。从而使高次方项的影响减少。
J
(
θ
)
=
1
2
m
[
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
∑
j
=
1
n
θ
j
2
]
J(\theta)=\frac{1}{2m}[\sum_{i=1}^{m}{(h_{\theta}(x^{(i)})-y^{(i)})^{2}}+\lambda\sum_{j=1}^{n}\theta_{j}^{2}]
J(θ)=2m1[∑i=1m(hθ(x(i))−y(i))2+λ∑j=1nθj2]
其中
λ
\lambda
λ称为正则化参数,如果选择的正则化参数过大,就会把所有的参数都最小化了,导致
h
θ
(
x
)
=
θ
0
h_{\theta}(x)=\theta_{0}
hθ(x)=θ0.还有
θ
0
不
参
与
正
则
化
\theta_{0}不参与正则化
θ0不参与正则化

3.正则化线性回归
1.梯度下降法
正则化线性回归的代价函数为:
J
(
θ
)
=
1
2
m
[
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
∑
j
=
1
n
θ
j
2
]
J(\theta)=\frac{1}{2m}[\sum_{i=1}^{m}{(h_{\theta}(x^{(i)})-y^{(i)})^{2}}+\lambda\sum_{j=1}^{n}\theta_{j}^{2}]
J(θ)=2m1[∑i=1m(hθ(x(i))−y(i))2+λ∑j=1nθj2]
,运用梯度下降法法最小化得:
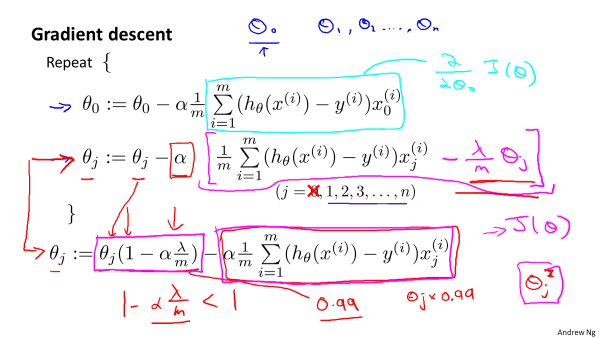
2.正规方程
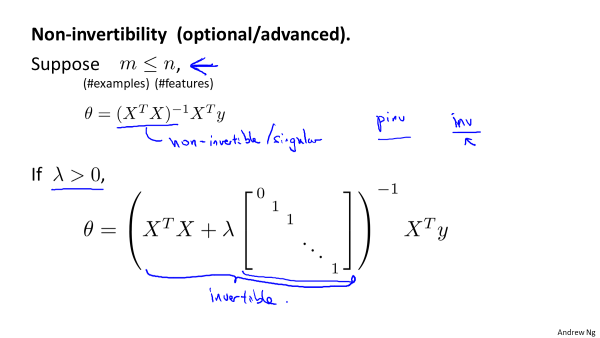
其中矩阵的尺寸为(n+1)*(n+1).
4.正则化逻辑回归
其正则化后的代价函数为:
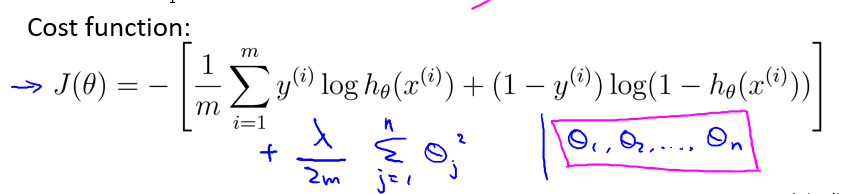
进行梯度下降法:















 3553
3553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









