







1.Abstract
随着多媒体的发展,许多假新闻通过图像或者视频来吸引读者,所以视觉信息是新闻检测的重要内容,作者发现,在现实世界,假新闻在物理和语义层面与真实新闻有很大不同, 因此,作者提出了一种新颖的框架多域视觉神经网络(MVNN)来融合频域和像素域的视觉信息来检测假新闻。具体来说,作者设计了一个基于 CNN 的网络来自动捕获频域中假新闻图像的复杂模式; 并利用多分支 CNN-RNN 模型从像素域中的不同语义级别提取视觉特征。 利用注意力机制动态融合频域和像素域的特征表示。
2.Introduction
作者总结概述了前人的工作,发现大家很多注重于融合多模态,但是没有考虑如何充分利用图像信息建模。而且作者发现,假新闻在物理和语义层面与真实新闻差别很大,因此作者将图像的信息分为两个层面:
物理层面:在物理层面,假新闻图像可能质量较低,在频域中可以清楚地体现出来。

假新闻图像和真实新闻图像在物理层面的比较。 我们观察到假新闻图像(a)具有明显的块效应,而真实新闻图像(b)更清晰。 为了更好地比较,我们放大了两张图片的脸。
- 考虑到经常重新压缩和篡改的图像在频域中存在周期性,可以很容易地通过具有捕捉空间结构特征的能力的 CNN 来表征,我们设计了一个基于 CNN 的网络来自动捕捉频域中假新闻图像的特征
语义层面:在语义层面,假新闻图像在像素域(也称为空间域)中也表现出一些明显的特征。 假新闻发布者倾向于利用图像来吸引和误导读者进行快速传播; 因此,fakenews 图像通常显示视觉影响 和情感挑衅 。

在语义级别上比较假新闻图像和真实新闻图像。 我们可以发现,假新闻图像比真实新闻图像更具视觉冲击力和情感挑衅性,即使它们描述了相同类型的事件,例如火灾 (a)、地震 (b) 和道路坍塌 (c )。
- 我们构建了一个多分支 CNN-RNN 网络来提取不同语义级别的特征,以充分捕捉像素域中假新闻图像的特征。
并非所有特征都对假新闻检测任务做出同等贡献,这意味着在评估给定图像是假新闻图像还是真实新闻图像时,某些视觉特征比其他特征发挥更重要的作用。 因此,我们采用注意力机制 [23] 来动态融合来自不同领域的这些视觉特征。
作者提出了一种多域视觉神经网络 (MVNN) 框架,该框架可以通过结合频率域和像素域的信息来学习有效的视觉表示以进行假新闻检测。 所提出的模型由三个主要部分组成:频域子网络和像素域子网络,用于分别在物理和语义级别捕获假新闻图像的特征,以及动态融合这些特征的融合子网络。 综上所述,本文的贡献在于三个方面:
1)据我们所知,我们是第一个利用多域视觉信息进行假新闻检测的人,它在物理和语义层面捕捉假新闻图像的固有特征。
2)我们提出了一个新的框架MVNN,它利用端到端的神经网络来同时学习频率和像素域的表示并有效地融合它们。
3)我们对真实世界的数据集进行了广泛的实验,以验证所提出模型的有效性。 结果表明,我们的模型比现有方法要好得多,并且我们模型学习的视觉表示可以帮助大大提高多模态假新闻检测的性能。 此外,我们表明频域和像素域的信息在检测假新闻方面是互补的。
Related Work
该小结介绍了谣言检测的相关工作,但是作者发现,现有的跟踪侧重于如何融合不同模态的信息,而忽略了对视觉的有效建模。由于缺乏与任务相关的信息,他们采用的这些视觉特征过于笼统,无法反映假新闻图像的内在特征,从而降低了视觉内容在假新闻检测中的性能。所以作者提出了一种新颖的深度学习网络来模拟物理和语义级别的视觉内容,以完成假新闻检测的任务。
Problem Formulation
问题 1:给定一组新闻帖子 X = {x1, x2, . . . , xm},对应图像I = {i1, i2, . . . , im},标签Y = {y1, y2, . . . , ym},学习一个分类器f,它可以利用相应的图像来分类给定的帖子是假新闻(yt = 1)还是真实新闻(yt = 0),即yˆt = f(it)。
Methodology
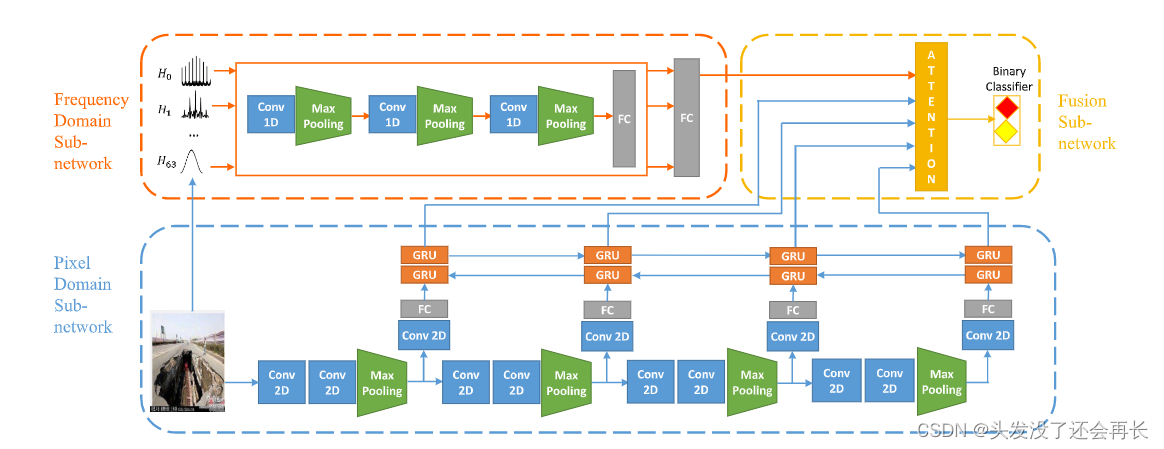
MVNN 包括三个主要部分:频域子网络、像素域子网络和融合子网络。 对于输入图像,我们将其输入频域和像素域子网络,分别获得物理和语义级别的特征。 融合子网络将这些学习到的特征作为输入,并学习该图像的最终视觉表示,以预测该图像是假新闻图像还是真实新闻图像。
-
Frequency Domain Sub-network
在输入图像上使用DCT将其从像素域转换为 频域。 考虑到篡改图像和重新压缩图像在频域中往往呈现周期性,具有捕捉空间结构特征的能力的 CNN 可以很容易地对其进行表征;所以作者设计一个基于 CNN 的网络来捕获频域中假新闻图像的特征。结构如下图所示:

具体网络架构的细节:
(1)对于输入图像,首先对其使用block DCT,以得到64 个频率对应的DCT系数的64个直方图。
(2)然后在这些DCT系数直方图上进行1D Fourier transform,以增强CNN的影响。考虑到CNN需要固定大小的输入,因此对这些直方图进行采样并得到64个250维的向量,表示成{Ho , H1,…H63}
(3)预处理之后,每个输入向量被输入到共享的CNN网络,以得到相应的特征表示{ w 0 , w 1 , . . . , w 63 } -
Pixel Domain Sub-network
像素域子网络,用于在语义级别提取输入图像的视觉特征,其详细架构如下图所示:
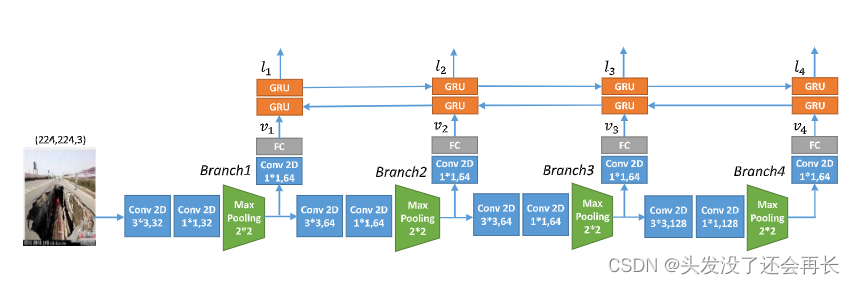
CNN 通过从局部到全局视图的逐层抽象来学习高级语义表示,其中较早的层更喜欢颜色、线条和形状等低级特征,而后面的层则倾向于关注对象。
假新闻图像通常表现出一些视觉冲击和情感挑衅,这已被证明与从低级到高级的许多视觉因素有关[22],因此,要充分捕捉假新闻的语义特征 图像,作者构建了一个多分支 CNN 网络来提取多层次的特征,并利用双向 GRU (Bi-GRU) 网络。
将这些来自不同级别的特征建模为序列 V = {vt}, t ∈ [1, 4], 其中 vt 表示从图 6 中描述的 CNN 网络中的第 t 个分支提取的视觉特征。然后整个管道 在 GRU 中,时间步 t 可以表示为

其中 r t , z t , h t ~, h t 分别是重置门、更新门、隐藏候选和隐藏状态。 W 是权重矩阵,b 是偏置项。 此外,a 代表 sigmoid 函数,⊙代表元素乘法。
考虑到不同层次特征之间的依赖关系可以从局部到全局视图和全局到局部视图进行估计;利用双向 GRU 从两个不同的角度对关系进行建模

-
Fusion Sub-network
并非所有特征对假新闻检查任务的贡献都相同,这意味着一些视觉特征发挥更大的作用,可以通过注意力机制突出这些有价值的特征,以及增强的图像表示的计算公式如下:
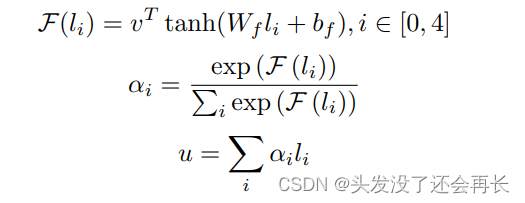
其中 Wf 表示权重矩阵,bf 是偏置项,v T 表示转置的权重向量,F是衡量每个特征向量显着性的得分函数。
到目前为止,已经获得了输入图像的高级表示u,然后使用带有softmax激活的全连接层将该向量投影到两个类别的目标空间中:假新闻图像和真实新闻图像,并获得概率分布:
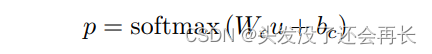
损失函数:预测概率分布和基本事实之间的交叉熵:
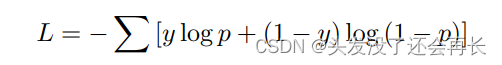
Experiments
Dataset:
在本文中,仅在微博数据集上进行实验,以评估所提出模型的有效性。
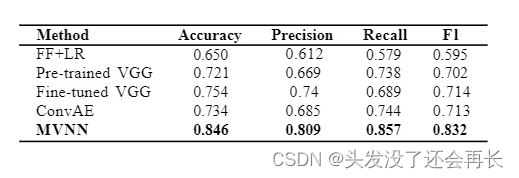
results:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









