







 本文使用新的DNN模型研究从听觉神经到语音皮层的神经编码,将DNN模型计算和人类听觉神经响应相关联,增强AI模型可解释性。通过实验验证了DNN分层与上行听觉通路相关、能捕捉特定语言信息等,揭示了语音学习DNN和人类听觉通路的相似性。
本文使用新的DNN模型研究从听觉神经到语音皮层的神经编码,将DNN模型计算和人类听觉神经响应相关联,增强AI模型可解释性。通过实验验证了DNN分层与上行听觉通路相关、能捕捉特定语言信息等,揭示了语音学习DNN和人类听觉通路的相似性。
Dissecting neural computations in the human auditory pathway using deep neural networks for speech(使用语音深度神经网络剖析人类听觉通路中的神经计算)

专业术语
auditory pathway 听觉通路
deep neural network(DNN)深度学习网络
ascending auditory pathway 上行听觉通路
unsupervised learning 无监督学习
supervise learning 监督学习
self-supervise learning 自监督学习
auditory nerve (AN) 听觉神经
inferior colliculus(IC) 下丘
Heschl’s gyrus(HG)海什尔回
superior temporal gyrus(STG)上颞回
primary auditory cortex 初级听觉皮层
phonemic 音素的
syllabic 音节的
auditory periphery 听觉周围
ridge regression model 岭回归模型
acoustic-phonemic features 声学语音特征
spectrogram features 光谱特征
temporal integration 时间整合
automatic Speech Recognition(ASR)自主语音识别
概述
本文使用一种新的 DNN 模型研究从听觉神经到语音皮层的神经编码,DNN 的分层表示与整个上行听觉系统(ascending auditory)的神经活动相关。并且深层的 DNN 与皮层的高阶活动相关,DNN 的计算与语音中的音素和音节结构 align。总之,作者将 DNN 模型计算和人类听觉神经响应相关联,增强 AI 模型的可解释性。
相关介绍
主要相关知识
一些相关资料看完再看这篇文章会比较好:
关于 STG 在语音中的功能,大家可以参考这篇文章:Speech Computations of the Human Superior Temporal Gyrus、还有关于听觉通路的研究可以参考这一篇文章:Understanding rostral–caudal auditory cortex contributions to auditory perception、与本研究相关的几个区域的功能及研究可以参考这篇文章:The DIVA model: A neural theory of speech acquisition and production、有关听觉系统的详细解释,大家可以参考这篇文章:auditory system,也可以直接去 b 站搜上科大刘泉影的课程进行学习~
Q: 什么是
上行听觉通路(ascending auditory pathway)?
A: 简单概述:当人类听到一段语音时,信号并不会直接到达大脑皮层,在此之前,会先经过一个上行通路,这个通路如下图所示,从耳蜗产生的电信号开始,由螺旋神经节细胞(ganglion cells)通过听觉神经(auditory nerve (AN))传递到延髓(medulla)的ventral cochlear nucleus和dorsal cochlear nucleus,这两个神经元是同侧的(ipsilateral),再传递到superior olive。然后通过lateral lemnisus传递到中脑(midbrain)的下丘(inferior colliculus(IC))。最后到达丘脑(thalamus)的MGN(Medial Geniculate Nucleus),由MGN将信号传递到大脑的听觉皮层(auditory cortex)。本文中涉及的听觉皮层包括Heschl's gyrus(HG)和superior temporal gyrus(STG上颞回)。信号先到达 HG 再到达 STG,通常被认为是初级听觉皮层

本文想要解决的两个问题:
(1)无统一的计算模型,经典的神经编码模型能够解释语音知觉过程中的神经编码,但无法直接适应到统一的语音知觉的计算框架中。
(2)模型可解释性差,现代的深度神经网络(DNN)在自动语音识别方面接近人类水平的性能,但其端到端的“黑盒子”特性限制了对内部计算和表示的解释。
本文的发现
(1) 一个与 ascending auditory pathway中层次结构(hierarchy)相关的 DDN 模型
(2)没有明确语言知识的无监督学习(unsupervised learning) 中可以学习到与人类听觉通路相似的特征表示
(3)DNN 的深层与在非初级听觉皮层(nonprimary auditory cortex)的语音相应群体相关联,存在与关键语言相关的时间结构(phonemic and syllabic contexts)对齐的特定计算驱动
(4)DNN 可以揭示跨语言中的语言的特定属性(language-specific properties)
Q: 为什么作者强调了
有监督和无监督?
A: 因为语音是一个动态的序列,模型需要提取语音的动态表征,需要当前的输入以及依赖于前面的一段语音序列,如果训练需要大量的标签数据,但是无监督学习不需要。所以解释语音的神经编码模型更适合用无监督学习。
结果
overview
总目标是:理解在言语感知(language perception)过程中整个听觉系统中发生和出现的计算和表示。
下面介绍实验的数据,模型以及对比的基线模型。
模拟上行通路包括两部分:
(1)为了模拟早期通路,我们使用了听觉周围(auditory periphery)和中脑(midbrain) 的生物物理模型的模拟。在仿真中分别得到了50个独特的听神经元(AN)和100个独特的下丘脑神经元(IC)。
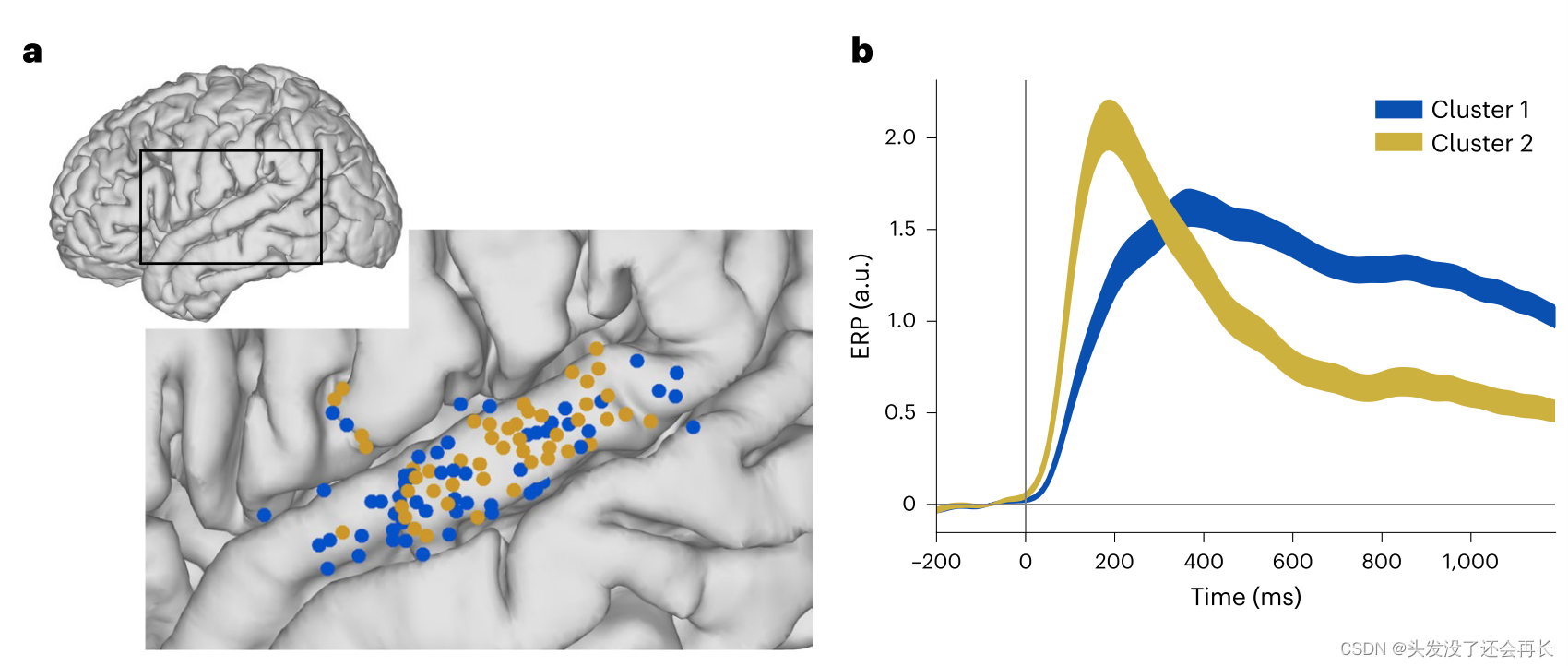
(2)对于通路的后一部分,我们使用了9名参与者的主要和非主要听觉皮层区域的颅内皮层记录(intracranial cortical recording)。电极的记录位置如下图所示:一共 553 个电极,在 HG 区域有 81 个,在 STG 区域有 472 个,在高γ波段(70-150 Hz)中的局部场电位的幅度被用作局部神经元活动的量度。

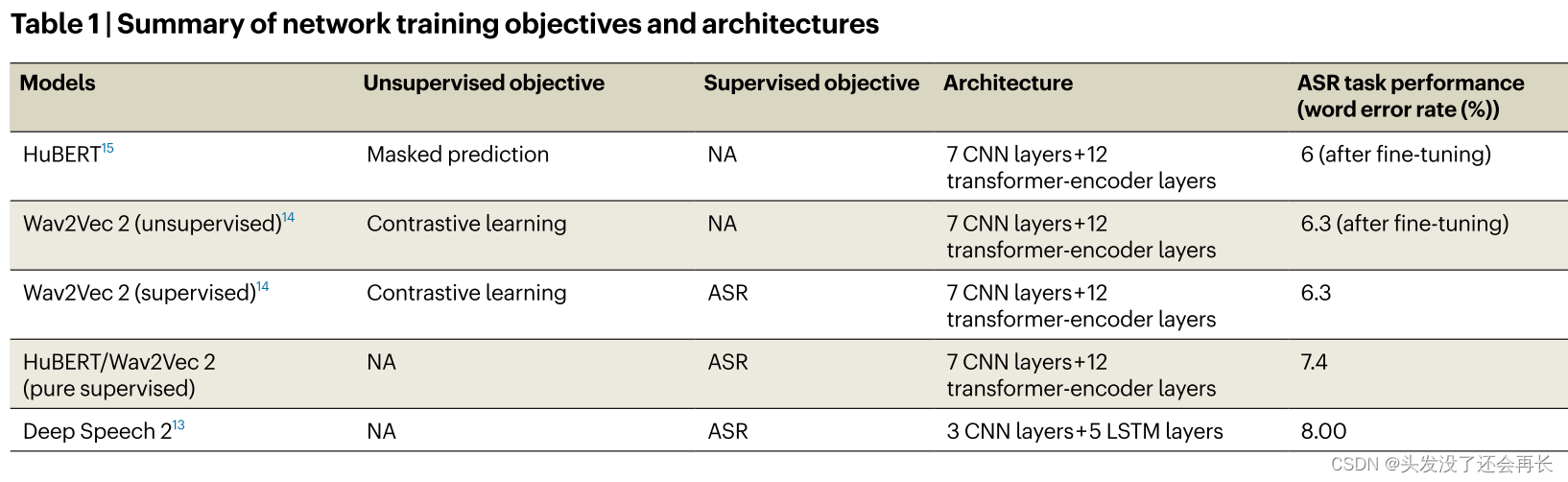
使用了五个 DNNs 用来提取语音表征:
(1)HuBERT 模型,一个基于 transformer 的自监督模型被训练用于预测语音的掩码部分(让 model 根据 mask 的前后部分信息进行预测学习)。
(2)Wav2Vec2 无监督模型,一个基于 transformer 的自监督模型,用于对语音进行对比学习。它的目标是区分语音中的特定片段与其他干扰项。
(3)Wav2Vec2 监督模型,基于 transformer 的监督模型,基于在 Wav2Vec 无监督的微调。
(4)HuBERT 监督模型,一个完全监督模型,只训练监督的 ASR,没有无监督的训练。
(5)Deep speech 2 模型,基于 LSTM 的监督 ASR 模型。
这些模型共享一个相似的层级架构:一个多层卷积特征编码器,用来提取时间上受约束的较低层级的声学特征(acoustic feature)表示,一个多层的序列解码器(有许多的 transformer-encoder 或者 LSTM 层)用来从 encoder 的输出中提取高层次的基于内容的音素(context-dependent phonetic)信息。
来自听觉通路和DNN的语音响应在时间上对齐(align) 以训练线性编码模型(linear encoding models)。DNN中的不同表示层用于预测听觉通路中的神经反应(图1)。
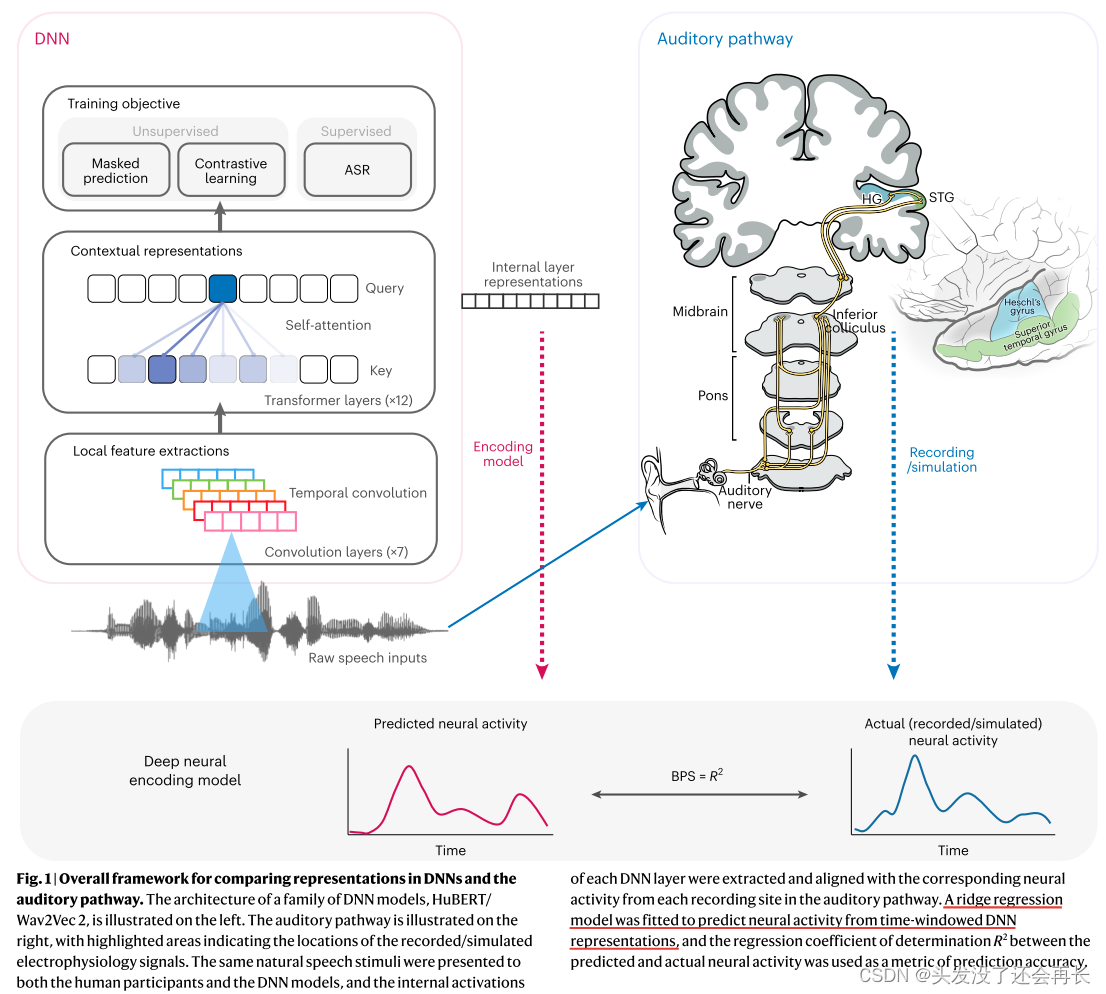
使用时间窗口的DNN表示作为输入特征,并将神经活动作为目标变量。通过拟合岭回归模型(ridge regression model),寻找最优的回归系数,使得预测的神经活动与实际神经活动之间的均方误差最小。使用了回归系数的确定系数
R
2
R^2
R2作为评估指标。确定系数
R
2
R^2
R2通过回归模型对神经活动的变异性进行解释的比例。它的取值范围从0到1,其中1表示完美的预测,0表示模型无法解释神经活动的变异性。
Q: R 2 R^2 R2在这里的作用是什么?
A:在这里, R 2 R^2 R2表示的就是 DNN学习到的语音表示和实际的神经表示之间的相似性。这个 R 2 R^2 R2就可以用来评估模型预测的好坏。
有了 DNN 模型,当然也要有对比的基线模型,为了处理不同记录位置上的异质信噪比,研究人员正对每个记录位置训练了两个基准模型(baseline model),这些模型旨在对神经元的活动进行预测:
(1) 使用频谱图特征(spectrogram features)的线性时域感受野(TRF)模型。
(2) 使用声学-语音特征(acoustic-phonetic features)的线性TRF模型,包括频谱图(spectrogram)、语音包络(envelop)/时间标记(temporal landmark)、音高(pitch)和语音特征(phonetic features)。
Q: 什么是时间感受野(TRF)?
A:可以参考这篇文章:temporal receptive field。时间感受野其实也是一个模型,这个模型使用的是岭回归,训练得到一组最优权重,用来预测给定特征的神经活动。
为了确保在不同记录位置和区域之间进行公平比较,研究人员将使用不同特征集的神经编码模型的性能与第二个基准模型进行归一化。归一化后的预测
R
2
R^2
R2被称为脑预测分数(BPS),它是每个记录位置的预测准确性的主要指标。
这个 BPS 贯穿全文,所以一定要记住,就是归一化后的
R
2
R^2
R2。
DNN hierarchy correlates with the ascending auditory pathway(DNN 分层与上行听觉通路相关联)
首先,需要验证 DNNs 的层级结构是否与 ascending pathway 的层级结构相似。即,测试经过训练以学习语音表示的DNN是否收敛于AN-IC-HG-STG的相同标准听觉(串行前馈)层次。(阅读过程中也在思考,如果是我我会怎么设计实验?真的觉得这个文章的实验设计非常棒👍)
本小节从两个不同的角度比较了 DNN 层次结构和上行听觉通路:1)DNN中的层次结构是否反映了上行听觉通路中的类似层次结构?(2)DNN学习的特征表示是否比语言学衍生的声学语音特征集与神经编码(neural coding)更强相关?
关于第一个问题,解决的思路就是计算DNN 的各层与实际上行通路中的不同层级之间非别计算相关性。——so,作者就是对model所有的层,都计算了和四个 ascending auditory pathway 的AN、IC、HG、STG 这四个区域的 BPS。作者还考虑了在层级结构中的另一个问题,时间整合(temporal integration)窗口!因为听觉层次的特点是越来越长的时间整合窗口。那就要看实际的神经响应和模型预测的神经响应是不是有相似的时间窗口。(天呐 完全想不到这个思路)
首先,每个解刨区域和 DNN 各层的BPS具体的计算如下,对比overview提到的线性基线模型 2(acoustic–phonetic 的线性 TRF)。
我们考虑了一个代表性的最先进的自监督DNN,HuBERT模型,对于model 的每一层,计算每个解剖区域内所有记录部位的平均BPS(归一化预测R2),结果如下图 a 所示(横轴表示 model 的每一层,纵轴表示每一层的 BPS,从左到右分别为AN、IC、HG、STG 这四个区域的 BPS,洋红条表示CNN输出层;青色条表示Transformer层。红星星表示每个区域的最佳模型;黑点表示与最佳模型无统计学差异的其他模型),这个 BPS的计算:模型不同层(输入为 speech)得到预测的neural encoding 分别与这四个区域的实际neural encoding计算 BPS,BPS 越大,相关性越强。
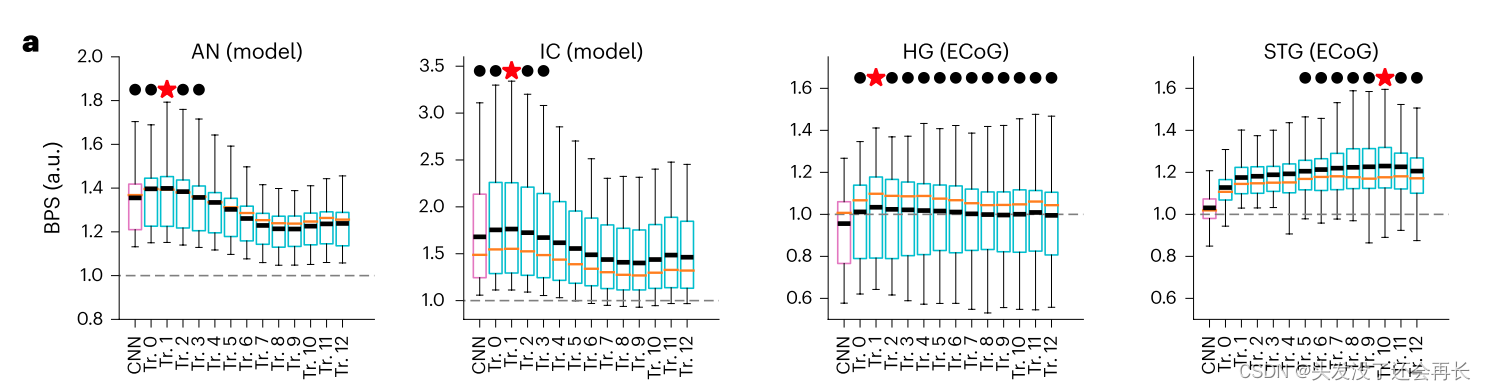
实验结果总结:
(1)DNN编码模型的性能在Transformer层1的AN中高出39.9%(mean BPS = 1.399, t(50) = 13.97, P = 2.5 × 10−44, two-sided)。
(2)在Transformer层1的IC中高76.3%(mean BPS = 1.763, t(100) = 13.75, P = 5 × 10−43, two-sided)。
(3)在Transformer层1的HG中高3.4%(mean BPS = 1.033, t(53) = 1.20, P = 0.23, two-sided)。
(4)在Transformer层10的STG中高出23.0%(mean BPS = 1.230, t(144) = 16.1, P = 5 × 10−58)。
(5)CNN 层和 transformer1 中最好地预测了 AN 和 IC 的响应,并且CNN 前面几层对 AN 的预测 BPS 高于对 IC 的预测,后几层的 CNN相反,这刚好对应了 ascending pathway 从 AN 和 IC 层开始响应,并且 AN 先与 IC。
(6)而语音响应 STG 群体的活动最好由 DNN 模型后半部分预测,并且在第十个 Tr 层达到顶峰,这对应于 ascending pathway 最后到达 STG。
(7)HG 活动响应最好的预测也在 Tr 层。但是对于 HG 活动来说,在几个 transformer 之间没有太大差异。
总结上面的实验结果,可以看出,DNNs 的层级结构和 ascending pathway 的层级结构十分相似。
然后测试是否 DNNs 和听觉层次的越来越长的时间整合(temporal windows)窗口一致,使用前面提到的基线模型 1–光谱特征 TRF。
使用基线光谱模型,每一个区域的 TRFs 都显示了一个渐进时间整合的层次结构:AN和IC的时间响应大多在100 ms内是短暂的,而皮层的神经响应显示出长于100 ms的整合时间窗口。更具体地说,HG响应平均具有200 ms的一致时间整合窗口,并且一些STG电极显示出高达300 ms和更长的显著持续时间整合窗口。如下图 b 所示(每个区域的语音响应单元/电极中的平均TRF权重,浅色区域表示随机排列分布;黑点表示TRF权重显著高于机会水平的时间点)。

这种增加时间积分窗口的趋势也与估计的最佳编码窗口大小一致如下图b 所示,该最佳编码窗口大小在编码模型中产生最佳预测,从左到右分别对应与对 AN、IC、HG、STG 活动的最佳预测窗口。

从这个实验可以看出,DNNs 和听觉层次的越来越长的时间整合(temporal windows)窗口一致。
最后是关于最后一个问题的解决思路,要验证 DNNs 是否比基线模型的与神经编码(neural coding)更强相关,那就要看基线模型与 5 个 DNN 模型,哪一个做 ASR(Automatic Speech Recognition) 任务得到的正确率更高。(ASR 即将语音信号转换为文本)
使用 5 个 DNN 模型和两个基线模型做 ASR 任务,得到的实验结果如下表所示:
基于DNN的编码模型在AN中解释了29.3-40.0%的方差,在IC中解释了61.7-76.3%的方差,在HG中解释了-3.5%至11.4%的方差,在STG中解释了3.1-23.0%的方差,如下图 c 所示,从左到右分别对应与对 AN、IC、HG、STG 活动的 BPS。
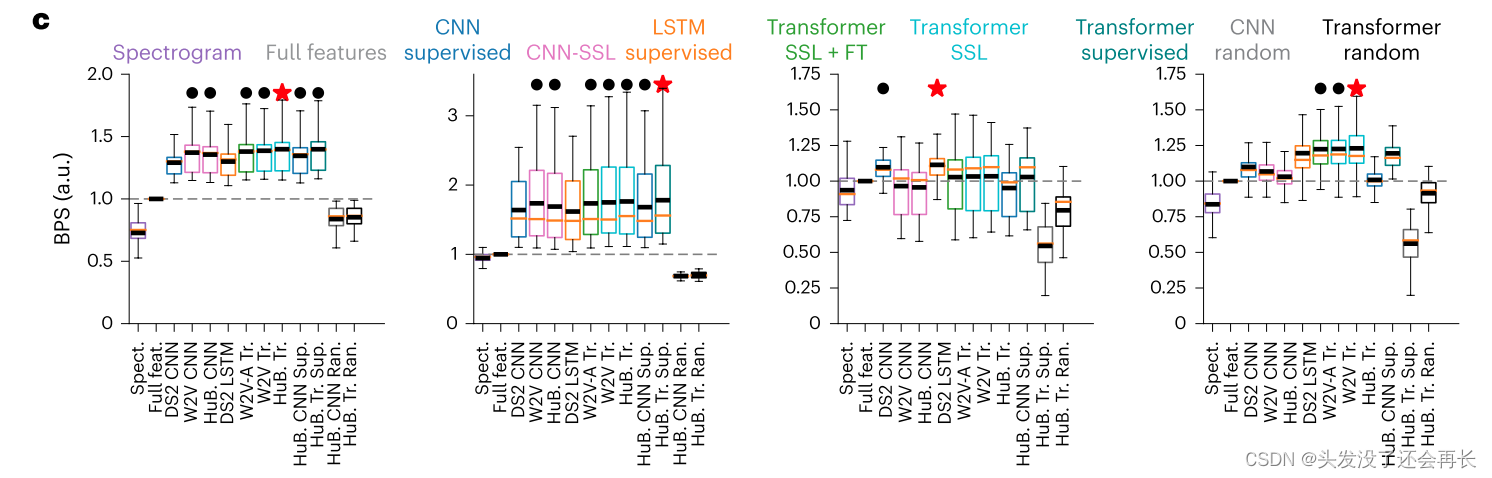
实验结果总结:
(1)所有的 DNN 模型的表现都优于基线线性模型。
(2)HuBERT 模型的transformer 层的表现在除了 HG 之外的所有区域中都表现出最高的平均性能。
(3)在所有模型中,AN 和 IC 和 HG 都主要由局部分辨 filter 表示(CNN),并且有一个固定的感受野,而STG在更深的 transformer 中可以得到最好的预测。
本小节的所有实验结果表明,被训练来学习语音表示的DNN中的从早到晚的层与上行听觉通路中的连续处理相关。
DNN layers correlate with distinct STG populations(DNN 层与不同 STG 群体相关)
关于 STG 对语音的神经表征研究已经证明,局部神经群体对特定的声学-语音特征有选择性的响应,比如有的神经群体对onset 有较高的神经响应,但还有一部分对phoneme有更高的响应。我们需要评估功能不同的语音响应群体是否对应于同一 DNN 模型中的不同层。
研究思路,对应 DNN 模型的不同层,计算和不同特征的 BPS,看是否存在一定相关性。那和什么特征计算呢?怎么得到不同的特征呢?——这里作者使用聚类得到了两个簇,这个两个簇在不同句子的基于 Hg 活动的 osnet 和 sustained 响应上有明显的不同。然后计算不同功能簇和 DNN 模型每一层的 BPSs(为什么选择研究这两个特征呢?)
使用非负矩阵分解对 STG 区域的 144 个响应电极进行聚类,发现了两个簇,这个两个簇在不同句子的基于 HG 活动的 osnet 和 sustained 响应上有明显的不同,如下图 3a,b所示。(这个聚类结果之后,如何得到图 b ?聚类之后,对于每个簇内的电极,将他们的 hg 活动求平均变得到了图 b ,图 b 可以看到osnet 和 sustained 响应上有明显的不同。)
然后计算不同功能簇和 DNN 模型每一层的 BPSs,看DNN 模型的不同层是否和两个 cluster 之间存在相关性。使用 HuBERT 模型,计算的结果如下图所示(红星星表示得分最高的层;黑点表示与最佳层无统计学差异的其他层,箱形图显示了电极间的第一和第三分位数(橙子线表示中位数;黑线表示平均值;须线表示第5和第95分位数)。水平灰线:表示全声学语音特征基线模型的表现。)。
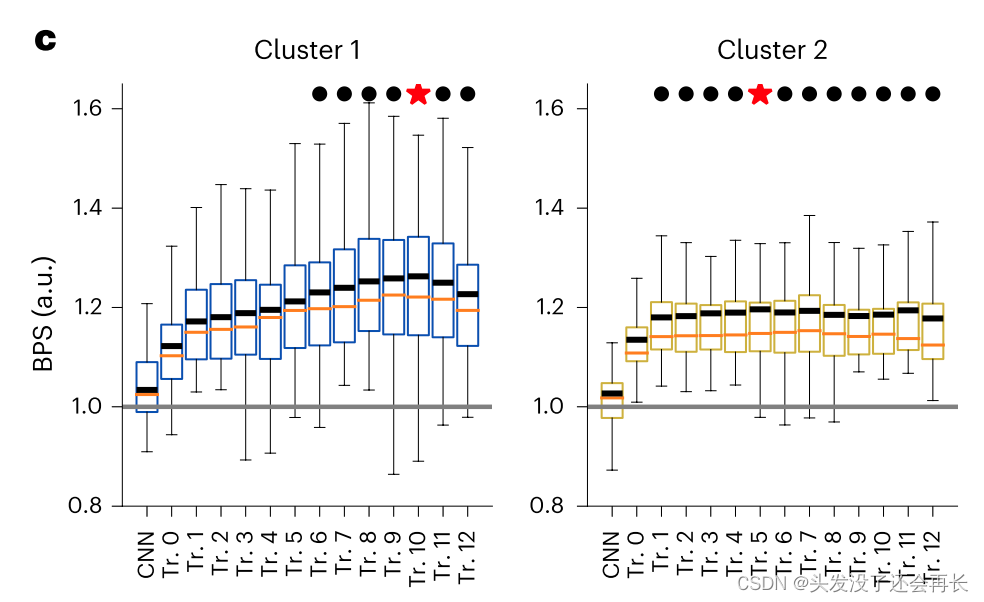
实验结果总结:
(1)簇 1(sustained)最好的预测在模型的 transformer10
(2)簇 2(transient) 最好的预测在layer5,但跟其他 layer 之间没有明显的差别。
说明,对于 sustained 的响应主要的在 DNNs 的更深层预测,而 transient 的响应在 DNNs 的早期和晚期都有预测。(这与其他研究是保持一致的)
同时,图 3d 这两个簇都显示出近似 200-250ms 的最佳延迟窗口,与 STG 活动最佳延迟窗口保持一致。
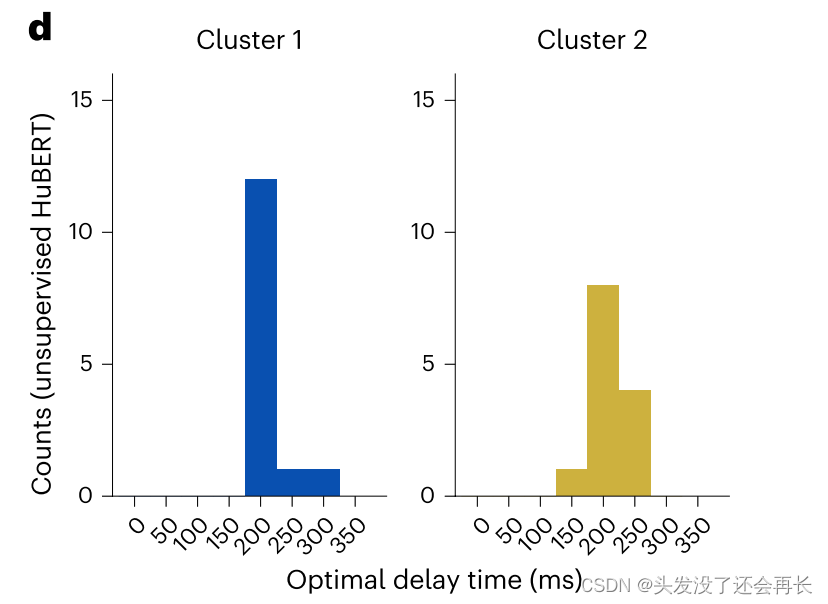
从上面的实验结果可以看出,DNNs 的不同层确实表征了不同的 STG 群体的活动,这也说明一些如句子和短语的 onset 特征可以在 DNNs 的多个层中表示。
DNN computations explain neural encoding predictions(DNN 中的计算解释了神经编码预测)
本小节想要研究的主要问题是,DNN中表示的计算机制,即DNN 中某些类型的注意力计算是否可以解释预测大脑反应的能力?本小节的重点在于语音背景(phonological context),其对应于目标语音声音的相邻音素(phonemes)和音节(syllabes)。
问题解决的思路是,先要确定 DNN 中某些类型的注意力是否存在,本文研究相对于音素和音节的注意力,(1)所以对于 DNN 的不同 transformer layer,作者首先计算和音素音节的相关性(本文中使用注意力分数(AS))。问题是:transformer layer 的注意力权重和谁计算相似性,哪里来的音素或者音节的注意力权重?——作者的解决办法是,自定义了与语音不同层次的上下文信息表示相对应的注意力矩阵模板。(2)在确定有一定相关性之后作者又测试这种趋势是否会预测 DNN 中不同层的大脑预测性能,关于这个问题,作者将不同DNN层中每个大脑区域的AS与BPS相关联。
Q:为什么使用
transformer 的注意力权重矩阵?
A:注意力权重矩阵表示了不同上下文部分对每个时间点的特征表示的贡献,这些权重会根据具体的语音序列动态变化,反映了每个语音序列中基于刺激的动态上下文信息提取。这样的动态上下文信息提取有助于提取声学信号中的有意义的顺序特征表示。
第一步,确定是否存在一定相关性
首先,对于语料库中的每一个句子,定义了与语音不同层次的上下文信息表示相对应的注意力矩阵模板(为了后面与实际 DNN 中每一个层的注意力矩阵计算相似性)——同一个音素内的上下文信息(contextual information within the same phoneme)、来自前一个音素的上下文信息(contextual information from the previous phoneme(s))、同一个音节内的上下文信息、来自前一个音节的上下文学习。(这个矩阵模板是怎么计算的?根据每个句子的频谱吗?)如下图a,b 所示,对于一个句子定义的6个注意力矩阵。
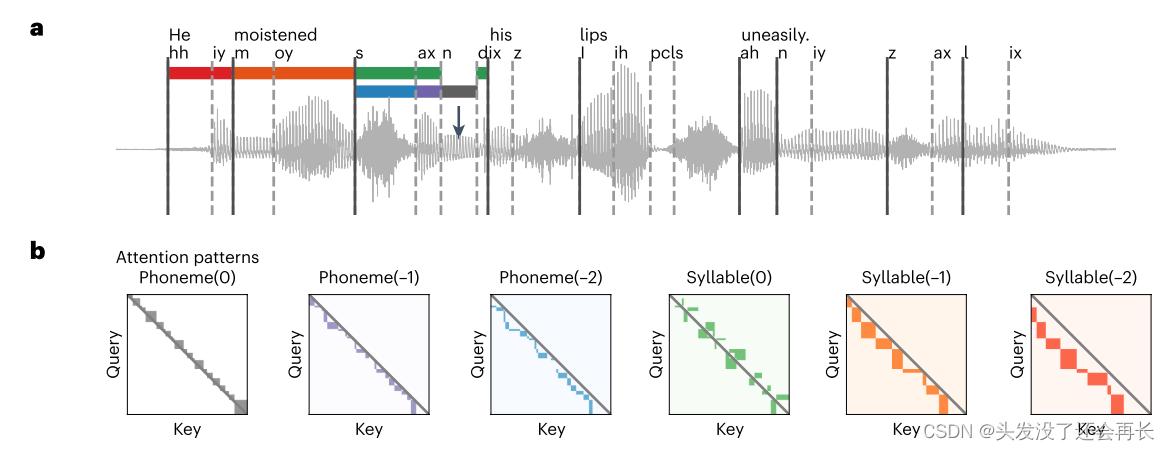
然后,计算DNN 每一层的实际注意权重矩阵与所有句子中的模板之间的平均相关系数,在本文中称为 attention score(AS)。结果如下图 c 所示(6 个矩阵表示的模板顺序如上图 b 一致,每个图左上角的r值表示AS和层指数之间的相关性(n = 12个不同层,排列检验)。黑线指示来自具有随机化权重的相同DNN架构的平均AS(mean ± s.e.m.,n = 499个独立句子))。

实验结果总结:
(1)在图 4c 中可以发现 更深的层次对语言结构(前面的音素和音节)的上下文注意力增加。
(2)具有相同架构但没有对语音数据进行预训练的随机DNN模型没有显示出这种沿层次结构的渐进式上下文注意力。(图中黑色的线)
说明,注意力与上下文结构的一致性不仅是深度神经网络模型的层次结构的直接结果,而且也反映了通过对自然语音的训练来提取语音特定的、语言相关的表示的计算。
第二步,测试了上下文计算中的这种趋势是否会预测DNN中不同层的大脑预测性能。
具体来说,我们将不同DNN层中每个大脑区域的AS与BPS相关联。计算结果如下图 d-g 所示(每个点表示一个Transformer层,每个面板对应一种类型的注意力模式。即每一行代表一个脑区域,列表示的注意力模式与上图 b 保持一致。r和P值对应于各层之间的AS-BPS相关性(Pearson相关性,排列检验,单侧。红色字体表示显著的正相关性))。(如何理解这里的相关性:在前面,已经计算出了大脑每个区域和模型各层输出之间的 BPS,也已经计算出了模型各层注意力和所有句子模板的 AS, BPS 表示的是大脑预测分数,那 BPS 和 AS 的相关性表示的就是各层的不同的注意力模式是否与大脑预测分数存在相关性,如果相关,那说明,DNN 层的上下文计算的趋势会预测 DNN 中不同层的大脑预测性能)
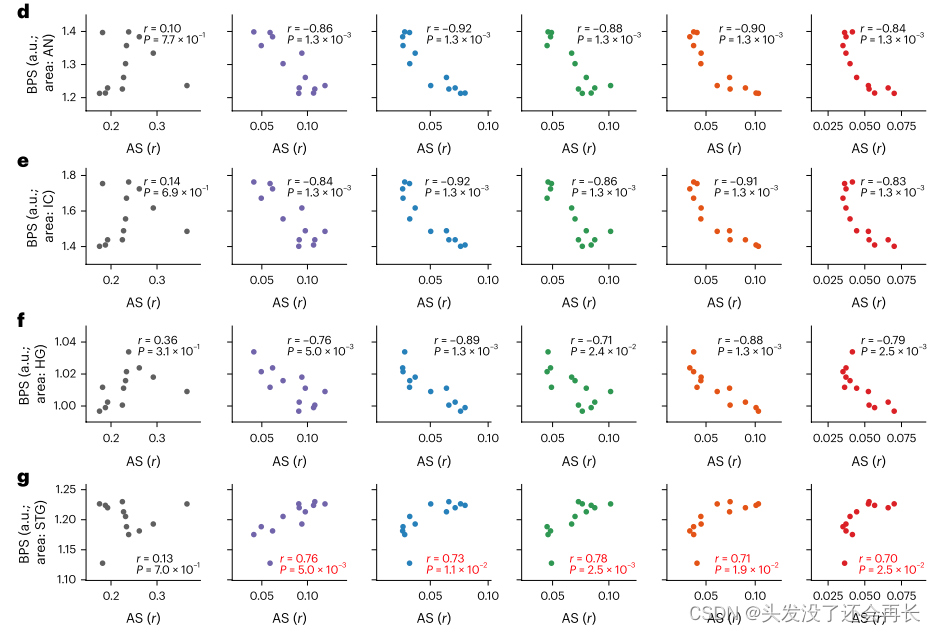
实验结果总结:
(1)结果(图 4g)显示,对语音的音素和音节水平的注意力(AS)与预测大脑活动的能力(BPS)仅在非初级听觉皮层(STG)呈正相关。
(2)而在听觉外围或初级听觉皮层(图4d ~ f)则不相关。
该实验的结果可以看出,这种上下文信息和 DNN 中不同层的大脑响应预测是相关的,对于模型中的给定Transformer层,注意力权重与语言上下文结构对齐得越好,该层的学习表示就越能够预测STG中的语音响应(正相关)。相反,参与的上下文信息越多,学习的表征与AN-IC-HG响应的相关性就越小。
DNN encoding models capture language-specific information(DNN 编码模型捕捉到了特定语言的信息)
本小节的主要目标是验证,DNN 模型是否在不同语言中存在差异,即 DNN 模型是否学习到了针对特定语言(language-specific)的信息。
解决思路是,针对不同的语言进行实验,训练两个基不同语言的DNN模型,然后去验证 DNN 模型是否学到了针对特定语言的信息。一个很直观的思想就是:让基于英语的训练 model 理解普通话语音,同时让英语为母语的人听一段中文记录大脑活动,两者计算 BPS,在同样用英语做实验,计算 BPS,两组进行对比,看是否人在理解语言上存在的差异也在 DNN上存在;同样,对于基于普通话训练的模型做同样的实验。此外,作者还评估了 DNN 层中音素和音节上下文信息的计算与STG中普通话语音的相应脑预测性能之间的关系。
作者使用了一个跨语言的方法,让两组受试者(母语为普通话和母语为英文),听英语和普通话研究。然后作者在自然普通话上预训练了一个HuBERT 模型。然后,我们比较了两种HuBERT模型在两组人听不同语言时的表现,实验设计如下图所示。
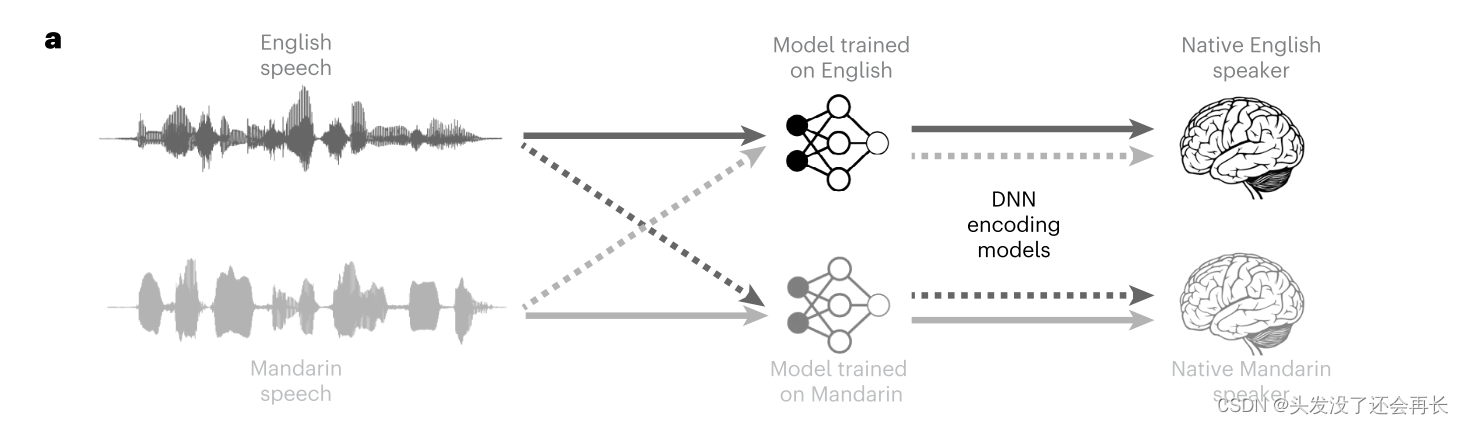
首先,测试基于英语进行预训练的模型
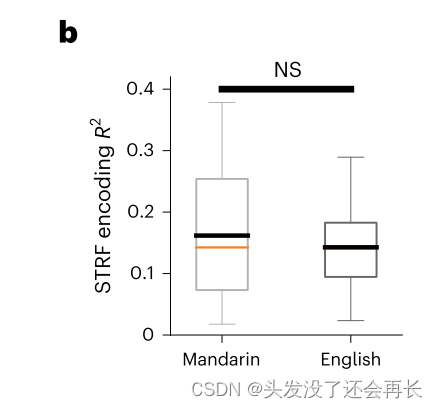
在 acoustic 层面,线性 TRF(基于频谱特征的)显示,当参与者听不同的语言语音时,model 显示了相似的预测响应。说明低层次的声学特征在不同语音之间的计算是共享的。图 5b((mean R2 = 0.162 and 0.143 for Mandarin and English speech, respectively; paired t(57) = 1.65, P = 0.104, two-sided;)
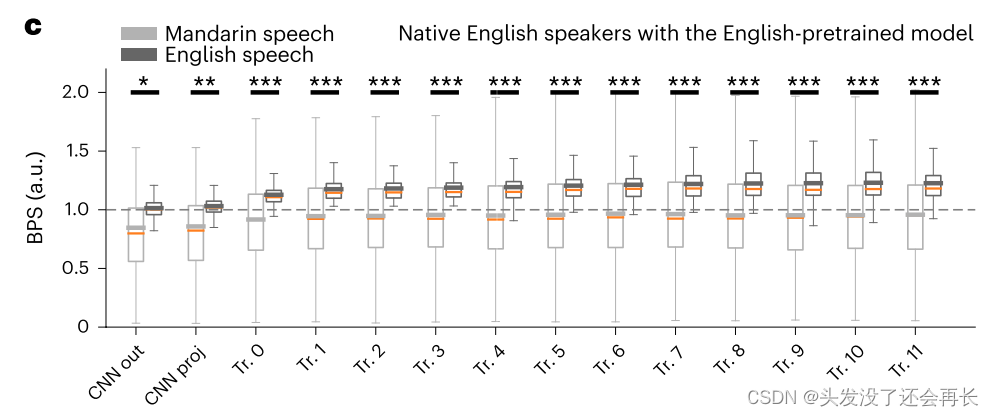
但是不同语言之间的的 DNN 编码模型中发现了性能差异,英语语音 BPS 显著高于普通话 BPS,且这种差异随着网络层数递增,表明,网络中表现出越来越多语言特点信息。图 5c(paired t(57) = 4.56, two-sided P = 3 × 10−5 )
作者还评估了DNN层中音素和音节上下文信息的计算与STG中汉语语音的相应脑预测性能(BPS)之间的关系。如下图所示(在基于英语的预训练 HuBERT 模型中跨层的 AS-BPS 相关性与母语为英语的说话者的 STG 区域之间的相关性),当英语母语者听普通话讲话时,DNN层中的注意模式与BPS之间的音素或音节水平没有发现显著相关性。

然后,测试基于普通话进行预训练的模型
在 acoustic 层面,与上面的实验结果相同,如下图所示,在声学层面不同语音之间的计算是共享。
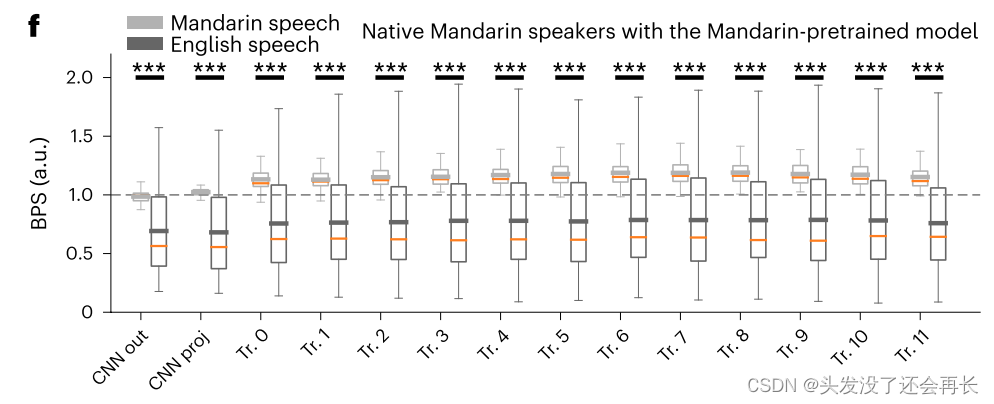
遇上一个模型的实验基本相同,DNN编码模型对普通话语音的神经反应表现出比英语语音更高的性能,在更深的层中,差距也增大。,表明,网络中表现出越来越多语言特点信息。图 5f(all 14 of 14 comparisons had P < 0.01, paired t test, two-sided; Fig. 5f)
我们发现在这些母语为汉语的人中,当听汉语讲话时,音素或音节水平的AS和BPS之间始终存在显著相关性(P < 0.05),而当听英语讲话时,没有显著相关性。如下图所示(此图和图 d 相同,但是使用的是基于普通话的预训练HuBERT模型和来自母语为汉语的n = 61个STG电极的记录)。

总结上面的实验,研究结果证明了预训练模型和母语之间的双重分离模式,这表明DNN计算和表示在STG中捕获了更高级别的语言特定语言信息,这些信息是根据语言经验学习的。
DNN acoustic–phonetic hierarchy explains brain prediction(DNN 声学-语音层次解释大脑预测)
本小节解决最后一个问题:DNN层的大脑预测性能是否可以通过声学到语音处理层次来考虑。
解决这个问题的思路便是对于 DNN 的不同层,考虑每一种特征在该层所能解释的方差比例。如何计算不同层的输出对每一种特征所能解释的方差比例?作者使用了一个线性编码模型去预测 CNN 层的隐藏单元的激活,并计算每组特征解释的唯一方差。
作者测试了DNN层中声学(acoustic),音素(phonetic)和韵律(prosodic)信息的特征表示。因为分析这些特征需要静态的而非上文提到的上下文信息,所以作者使用了一个相似的线性编码模型去预测不同 DNN 层的隐藏单元的激活,并且计算每一个特征所解释的唯一方差。
这里提到的计算唯一方差的步骤是这样的:(2)首先,我们需要一个线性编码模型,该模型的输入是我们要研究的不同的特征(spectrogram、phonetic、envelop、pitch),这些特征都可以从speech 中获得,该模型的输出是预测的DNN 层的隐藏单元的激活。(2)对于每个隐藏单元,获取其在DNN上的真实激活值(将 speech 输入 DNN 得到的每一层的激活值)和线性模型预测的激活值。(3)计算每个隐藏单元的独立方差。可以使用以下公式来计算独立方差:独立方差 = 1 - (方差(真实激活值 - 预测激活值) / 方差(真实激活值))(其中,方差表示方差的计算,真实激活值是隐藏单元在训练集上的真实激活值,预测激活值是线性模型预测的激活值。)
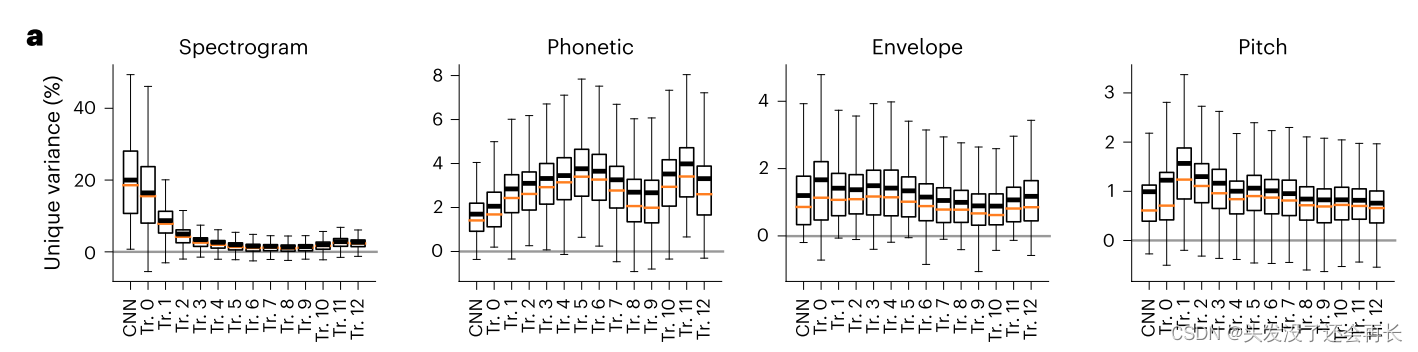
下图 a计算了不同层的 spectrogram、phonetic、envelop、pitch 的唯一方差。唯一方差表示该层的激活所能解释的对应特征的能力,方差越大,说明该层的激活包含的相对的特征的信息越多。
实验结果总结:
(1)可以看到,在 CNN 输出层,声学(spectrogram)特征唯一地占总方差的20.0%,而语音(phonetic)特征仅占1.70%。
(2)在第三层 transformer 之后,语音(phonetic)特征解释了更多的方差,时间标志(包络envelop)特征(如语音包络和起始点)和韵律音高特征(绝对音高和相对音高pitch)沿网络的层次分布更加均匀。
此外,当与各个层的BPS相关时,谱图(spectrogram)特征编码仅在外周区域显示出显著的正相关性;语音(phonetic)特征编码与STG中的BPS相关,但在其他区域中不相关。 如下图b 所示(第一行为spectrogram 和大脑各个区域的相关性,第二行为 phonetic 和大脑各个区域的相关性,唯一方差是上一步计算得到的,将唯一方差与不同脑区 BPS 相关联,可以看出对应脑区是否与该种特征相关联)

总之,将这些放在一起,发现了类似的声学到语音层次结构,并且与自我监督DNN模型和上行AN-IC-STG通路都相关。
discussion
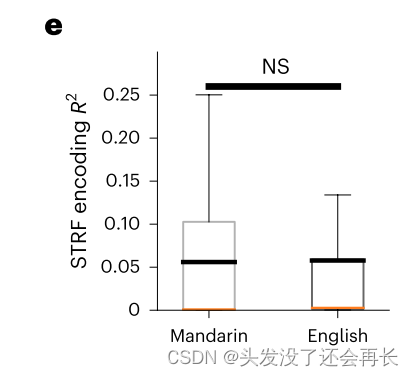
上面的各种实验研究已经证明,在最先进的DNN中学习的语音表示类似于人类听觉系统中信息处理的重要方面。DNN特征表示在预测整个听觉通路对自然语音的神经反应方面显着优于理论驱动的声学语音特征集。DNN层层级与AN-midbrain-STG上行听觉通路相关。更深的DNN层与非初级听觉皮层中功能不同的语音调谐群体相关。 基于DNN的神经编码模型可以在跨语言(language-specific)感知过程中揭示STG中的语言特定编码 ,而线性STRF模型则不能。
(更多的讨论我没有再细读,后面读了再更新,欢迎大家交流讨论)
Conclusion
使用比较的方法,我们展示了语音学习DNN和人类听觉通路之间重要的代表性和计算相似性。从神经科学的角度来看,数据驱动的计算模型擅长从统计结构中提取中间语音特征,超越了传统的基于特征的编码模型。从人工智能的角度来看,我们通过将它们与神经反应和选择性进行比较,揭示了一种理解DNN中“黑匣子”表示的途径。我们表明,现代DNN可能已经收敛于人类听觉系统中近似处理的表示。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









