







流和并发
CUDA流Streams
⭐️流:一系列将在GPU按顺序执行的操作。

🌟概念:CUDA流是一系列异步的CUDA操作,这些操作按照主机代码确定的顺序在设备上执行。流能封装这些操作,保持操作的顺序,允许操作在流中排队,并使它们在先前的所有操作之后执行,并且可以查询排队操作的状态。这些操作包括在主机与设备间进行数据传输,内核启动以及大多数由主机发起但由设备处理的其他命令。流中操作的执行相对于主机总是异步的。

stream操作
-
定义流:cudaStream_t s1;
-
创建流:cudaStreamCreate(&s1);
-
销毁流:cudaStreamDestory(s1);
CUDA流示例:
#include <cuda_runtime.h>
// 定义流
cudaStream_t s1;
int main() {
// 创建流
cudaError_t err = cudaStreamCreate(&s1);
if (err != cudaSuccess) {
// 处理错误
fprintf(stderr, "Failed to create stream (error code %s)!\n", cudaGetErrorString(err));
return -1;
}
// ... 在流上执行操作 ...
// 销毁流
err = cudaStreamDestroy(s1);
if (err != cudaSuccess) {
// 处理错误
fprintf(stderr, "Failed to destroy stream (error code %s)!\n", cudaGetErrorString(err));
return -1;
}
return 0;
}CUDA流的好处
🌟流:
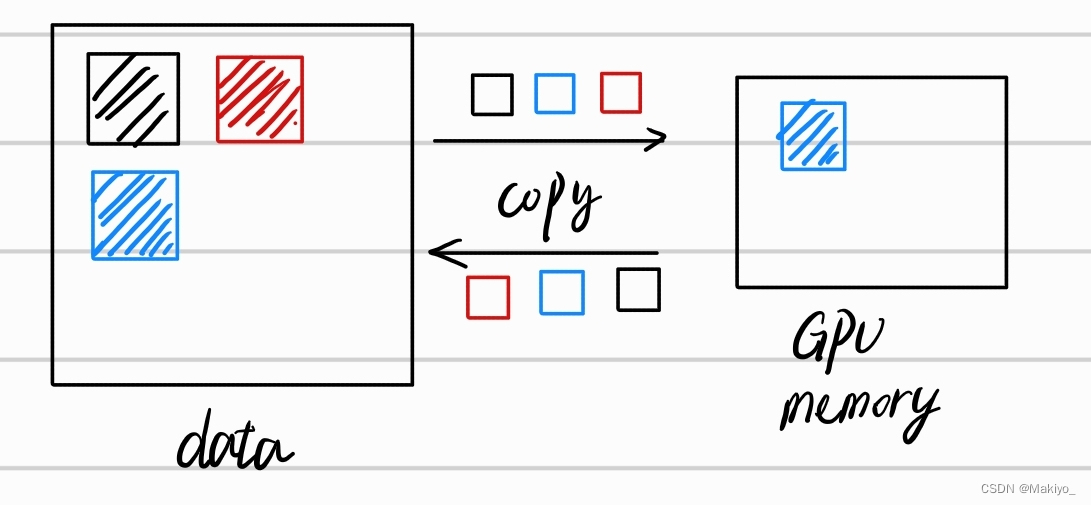
初始存在大量数据,假定为16G,gpu显存为2G,那么普通流的处理过程为:先将数据data分为8块,每块大小为2G,接着依次将数据块复制到Gpu Memory上进行处理,随后返回处理后的数据块,再将下一块传到GPU处理。
🌟CUDA流:
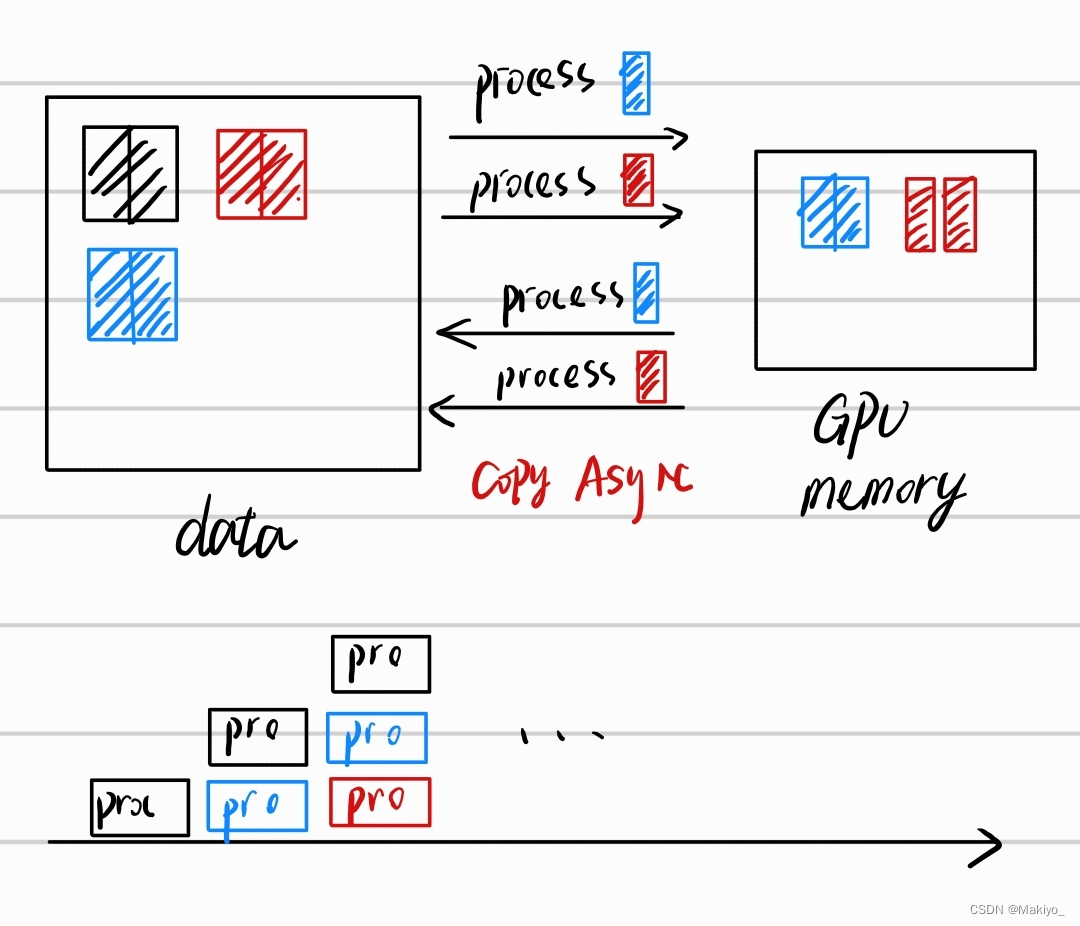
初始存在大量数据,假定为16G,gpu显存为2G,与流不同,CUDA流处理过程为:先将数据data分为16块,每块1G,接着可以将GPU Memory当作2个1G Memory,分别对不同数据块异步处理,过程类似流水线。
🖋CUDA流案例:
#include <cuda_runtime.h>
#include <stdio.h>
#define N 1000
#define CHUNK_SIZE 100 // 每个流处理的元素数量
__global__ void addKernel(int *c, const int *a, const int *b, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
c[i] = a[i] + b[i];
}
}
int main() {
// 主机内存分配
int h_a[N], h_b[N], h_c[N];
for (int i = 0; i < N; ++i) {
h_a[i] = i;
h_b[i] = i * 2;
}
// 设备内存分配
int *d_a, *d_b, *d_c;
cudaMalloc((void**)&d_a, N * sizeof(int));
cudaMalloc((void**)&d_b, N * sizeof(int));
cudaMalloc((void**)&d_c, N * sizeof(int));
// 创建CUDA流
const int numStreams = (N + CHUNK_SIZE - 1) / CHUNK_SIZE;
cudaStream_t streams[numStreams];
for (int i = 0; i < numStreams; ++i) {
cudaStreamCreate(&streams[i]);
}
for (int i = 0; i < N; i += CHUNK_SIZE) {
int chunkSize = (i + CHUNK_SIZE < N) ? CHUNK_SIZE : (N - i);
// 异步复制数据到设备
cudaMemcpyAsync(d_a + i, h_a + i, chunkSize * sizeof(int), cudaMemcpyHostToDevice, streams[i / CHUNK_SIZE]);
cudaMemcpyAsync(d_b + i, h_b + i, chunkSize * sizeof(int), cudaMemcpyHostToDevice, streams[i / CHUNK_SIZE]);
// 启动内核
int blockSize = 256;
int numBlocks = (chunkSize + blockSize - 1) / blockSize;
addKernel<<<numBlocks, blockSize, 0, streams[i / CHUNK_SIZE]>>>(d_c + i, d_a + i, d_b + i, chunkSize);
// 异步复制结果回主机
cudaMemcpyAsync(h_c + i, d_c + i, chunkSize * sizeof(int), cudaMemcpyDeviceToHost, streams[i / CHUNK_SIZE]);
}
// 同步所有流
for (int i = 0; i < numStreams; ++i) {
cudaStreamSynchronize(streams[i]);
}
// 显示前10个结果
for (int i = 0; i < 10; ++i) {
printf("h_a[%d] + h_b[%d] = h_c[%d] -> %d + %d = %d\n", i, i, i, h_a[i], h_b[i], h_c[i]);
}
// 验证结果
bool success = true;
for (int i = 0; i < N; ++i) {
if (h_c[i] != h_a[i] + h_b[i]) {
fprintf(stderr, "Verification failed at index %d!\n", i);
success = false;
break;
}
}
if (!success) {
printf("Test FAILED\n");
}
// 释放设备内存
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
// 销毁CUDA流
for (int i = 0; i < numStreams; ++i) {
cudaStreamDestroy(streams[i]);
}
return 0;
}🖋详解:初始定义三个数组,并初始化数组数据,接着为gpu定义三个数组,并分配相应内存,随后创建CUDA流数组,一共10个,对每个流异步copydata,并启动内核,最后异步复制结果到主机,最后同步所有流,完成数据处理。
多GPU编程
📔PS:硬件条件有限,试验无法进行,后续补充~
纹理内存与纹理操作
🌟概念:纹理内存(Texture Memory)是CUDA编程中的一种特殊内存,用于优化对图像和其他多维数据的访问。
💬特点:
-
只读访问:纹理内存是只读的,内核(kernel)只能从中读取数据,不能写入。
-
缓存:纹理内存有专门的缓存(texture cache),可以显著提高内存访问的效率,特别是在访问具有局部空间相关性的二维或三维数据时。
-
插值功能:纹理内存支持硬件插值,可以用于平滑图像缩放和旋转等操作。
🚀应用:
-
适合高访问率的数据:将那些会被频繁访问的数据放入纹理内存中,可以显著提高性能。
-
利用插值功能:在需要进行平滑缩放、旋转或其他图像变换时,充分利用纹理内存的硬件插值功能。
-
局部性访问:设计内核时,尽量使数据访问具有空间局部性,以充分利用纹理缓存。
-
显示能力:提供与GPU显示能力交互的方法,通过使用纹理和缓冲区,开发者可以将数据传递到GPU,并从GPU读取数据:纹理:用于存储图像数据,可以在着色器中进行采样和插值。帧缓冲区:用于存储渲染的结果,可以用于后处理效果。顶点缓冲区:用于存储顶点数据,如坐标、法线和颜色。
CUDA数组
🌟概念:CUDA数组(CUDA Array)存储类型为多维数组(1D、2D或3D),专为纹理内存和表面内存优化,主要用于图像处理和多维数据存储,支持多种格式(如浮点数、整型数等),并有专用的存储格式描述符(cudaChannelFormatDesc)。
纹理内存详细使用步骤
- 在CUDA中声明纹理内存
texture <type, dim, readmode> texture_reference;
• texture_reference: the handle to be used
• type: type of texel data returned from an access to
the texture: int, float, … .
• dim: 1 (default), 2, or 3
• readmode: controls conversion of texel returned by
an access
– cudaReadModeElementType (default) no conversion
– cudeReadModeNormalizedFloat
• if type is integer, value returned is mapped to [-1.0,1.0] for
signed, and [0.0, 1.0] for unsigned
• Example:
texture <float, 2, cudaReadModeElementType> mytex;
// 定义一个二维纹理引用
texture<float, cudaTextureType2D, cudaReadModeElementType> texRef;- 将纹理内存绑定到纹理引用:在主机代码中,需要创建和分配CUDA数组,并将其绑定到之前定义的纹理引用,CUDA数组用于存储需要在纹理内存中访问的数据。
cudaBindtexture (size *t offset,
& testure_reference , const void * devptr,
size_t size) ;
• Binds size bytes of the memory area pointed to by
devPtr to texture reference texture_reference.
• offset parameter is an optional byte offset.
• devPtr: Memory area on device
• size: Size of the memory area pointed to by devPtr
// 创建CUDA数组描述符
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>();
// 分配CUDA数组
cudaArray* cuArray;
cudaMallocArray(&cuArray, &channelDesc, width, height);
// 初始化主机上的数据
float* hostData = new float[width * height];
for (int i = 0; i < width * height; ++i) {
hostData[i] = static_cast<float>(i) / (width * height);
}
// 将数据从主机内存拷贝到CUDA数组
cudaMemcpyToArray(cuArray, 0, 0, hostData, width * height * sizeof(float), cudaMemcpyHostToDevice);
// 绑定CUDA数组到纹理引用
cudaBindTextureToArray(texRef, cuArray, channelDesc);- 在CUDA内核中从纹理引用读取纹理内存:在CUDA内核中,可以通过纹理提取函数从纹理引用读取数据。
• The easiest is: tex1Dfetch()
Example:
texture <int,1,cudaReadModeElementType> texref;
__global__
void textureTest(int *out){
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float x;
int i;
for(i=0; i<30; i++)
x = tex1Dfetch(texref, i);
}
// 内核函数
__global__ void kernel() {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < width && y < height) {
float u = x / (float)width;
float v = y / (float)height;
float value = tex2D(texRef, u, v); // 从纹理内存中提取数据
// 使用提取的数据进行操作
}
}-
从纹理引用中解除纹理内存绑定:在完成对纹理内存的操作后,需要从纹理引用中解除绑定,以释放资源。
cudaUnbindTexture(texture_reference);
// 启动内核
dim3 blockSize(16, 16);
dim3 gridSize((width + blockSize.x - 1) / blockSize.x, (height + blockSize.y - 1) / blockSize.y);
kernel<<<gridSize, blockSize>>>();
// 清理
cudaUnbindTexture(texRef);
cudaFreeArray(cuArray);
delete[] hostData;
return 0;
}🖊完整示例:
#include <cuda_runtime.h>
#include <iostream>
const int width = 1024;
const int height = 1024;
// 步骤1:定义一个二维纹理引用
texture<float, cudaTextureType2D, cudaReadModeElementType> texRef;
// 内核函数
__global__ void kernel() {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < width && y < height) {
float u = x / (float)width;
float v = y / (float)height;
float value = tex2D(texRef, u, v); // 从纹理内存中提取数据
// 使用提取的数据进行操作
}
}
int main() {
// 步骤2:创建CUDA数组描述符
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>();
// 分配CUDA数组
cudaArray* cuArray;
cudaMallocArray(&cuArray, &channelDesc, width, height);
// 初始化主机上的数据
float* hostData = new float[width * height];
for (int i = 0; i < width * height; ++i) {
hostData[i] = static_cast<float>(i) / (width * height);
}
// 将数据从主机内存拷贝到CUDA数组
cudaMemcpyToArray(cuArray, 0, 0, hostData, width * height * sizeof(float), cudaMemcpyHostToDevice);
// 绑定CUDA数组到纹理引用
cudaBindTextureToArray(texRef, cuArray, channelDesc);
// 步骤3:启动内核
dim3 blockSize(16, 16);
dim3 gridSize((width + blockSize.x - 1) / blockSize.x, (height + blockSize.y - 1) / blockSize.y);
kernel<<<gridSize, blockSize>>>();
// 步骤4:清理
cudaUnbindTexture(texRef);
cudaFreeArray(cuArray);
delete[] hostData;
return 0;
}CPU/GPU协同
🌟概念:在CUDA编程中,CPU和GPU协同工作时,使用cudaHostAlloc函数(有时也称为cudaMallocHost)分配“页锁定”内存或“pinned”内存。这种类型的内存分配允许更高效的主机和设备之间的数据传输。
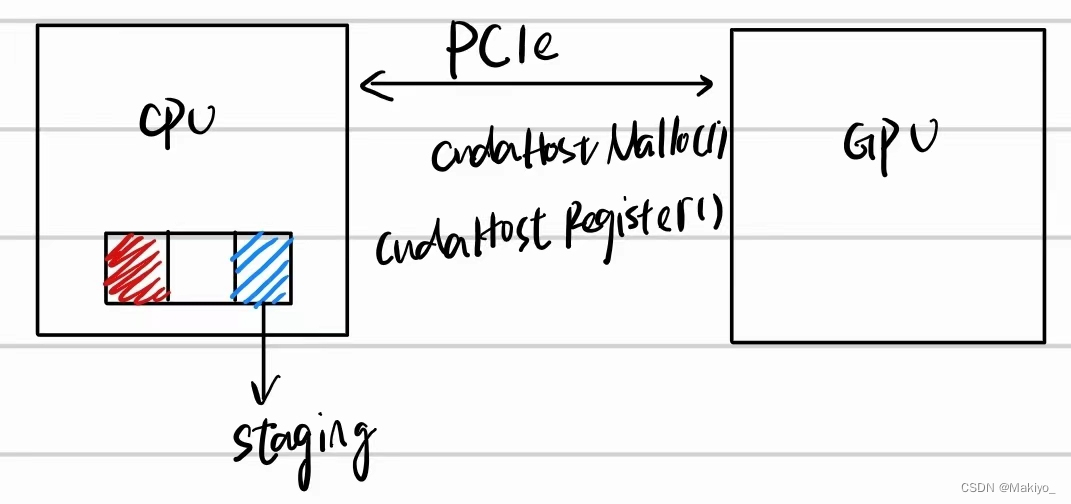
🖊详解:在普通内存中定义的数据会在🔴区域,当cpu需要将数据copy到gpu时,需要先将数据复制到🔵staging区域,再由staging区域传到gpu,数据传输效率较低,因为会涉及额外的内存拷贝操作。而使用cudahostmalloc()或者cudaHostRegister()函数可以直接将数据定义到staging中,省去了额外拷贝操作,减少了主机到设备(或设备到主机)数据传输的开销,提高了带宽利用率。
🔑使用cudaHostAlloc的好处:
-
更快的数据传输:
-
页锁定内存不会被操作系统交换到磁盘,因此GPU可以直接访问这些内存地址。
-
这种直接访问减少了主机到设备(或设备到主机)数据传输的开销,提高了带宽利用率。
-
-
异步数据传输:
-
使用页锁定内存可以实现异步数据传输。异步传输允许CPU和GPU同时进行计算和数据传输,从而提高了整体应用的并行性和性能。
-
使用普通的内存(非页锁定内存)时,数据传输是同步的,CPU必须等待数据传输完成才能继续执行其他任务。
-
-
与流(Streams)结合:
-
页锁定内存可以与CUDA流结合使用,进一步优化数据传输和内核执行的并行性。
-
例如,使用
cudaMemcpyAsync进行异步传输时,必须使用页锁定内存。
-
//示例代码
#include <cuda_runtime.h>
#include <iostream>
const int size = 1024;
__global__ void kernel(float* d_data) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < size) {
d_data[idx] = d_data[idx] * 2.0f; // 简单的计算示例
}
}
int main() {
// 分配页锁定内存
float* h_data;
cudaHostAlloc(&h_data, size * sizeof(float), cudaHostAllocDefault);
// 初始化主机数据
for (int i = 0; i < size; ++i) {
h_data[i] = static_cast<float>(i);
}
// 分配设备内存
float* d_data;
cudaMalloc(&d_data, size * sizeof(float));
// 异步拷贝数据从主机到设备
cudaMemcpyAsync(d_data, h_data, size * sizeof(float), cudaMemcpyHostToDevice);
// 启动内核
dim3 blockSize(256);
dim3 gridSize((size + blockSize.x - 1) / blockSize.x);
kernel<<<gridSize, blockSize>>>(d_data);
// 异步拷贝结果从设备到主机
cudaMemcpyAsync(h_data, d_data, size * sizeof(float), cudaMemcpyDeviceToHost);
// 同步设备
cudaDeviceSynchronize();
// 输出部分结果
for (int i = 0; i < 10; ++i) {
std::cout << h_data[i] << " ";
}
std::cout << std::endl;
// 释放内存
cudaFree(d_data);
cudaFreeHost(h_data);
return 0;
}CPU普通内存和数据传输流程
-
分配普通的主机内存:使用标准的C++内存分配函数(例如
malloc或new)分配普通的主机内存。 -
数据拷贝到staging buffer:在将数据传输到GPU之前,CUDA运行时会将数据从普通的主机内存复制到一个临时的页锁定内存区域。
-
数据传输到GPU:数据从临时的页锁定内存区域复制到GPU内存中。
//示例代码
#include <cuda_runtime.h>
#include <iostream>
const int size = 1024;
__global__ void kernel(float* d_data) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < size) {
d_data[idx] = d_data[idx] * 2.0f; // 简单的计算示例
}
}
int main() {
// 分配普通的主机内存
float* h_data = new float[size];
// 初始化主机数据
for (int i = 0; i < size; ++i) {
h_data[i] = static_cast<float>(i);
}
// 分配设备内存
float* d_data;
cudaMalloc(&d_data, size * sizeof(float));
// 同步拷贝数据从主机到设备
cudaMemcpy(d_data, h_data, size * sizeof(float), cudaMemcpyHostToDevice);
// 启动内核
dim3 blockSize(256);
dim3 gridSize((size + blockSize.x - 1) / blockSize.x);
kernel<<<gridSize, blockSize>>>(d_data);
// 同步拷贝结果从设备到主机
cudaMemcpy(h_data, d_data, size * sizeof(float), cudaMemcpyDeviceToHost);
// 同步设备
cudaDeviceSynchronize();
// 输出部分结果
for (int i = 0; i < 10; ++i) {
std::cout << h_data[i] << " ";
}
std::cout << std::endl;
// 释放内存
cudaFree(d_data);
delete[] h_data;
return 0;
}















 8465
8465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











