







Fast k nearest neighbor search using GPU
论文链接
百度网盘:链接:百度网盘 请输入提取码 提取码:fbcl
问题引入
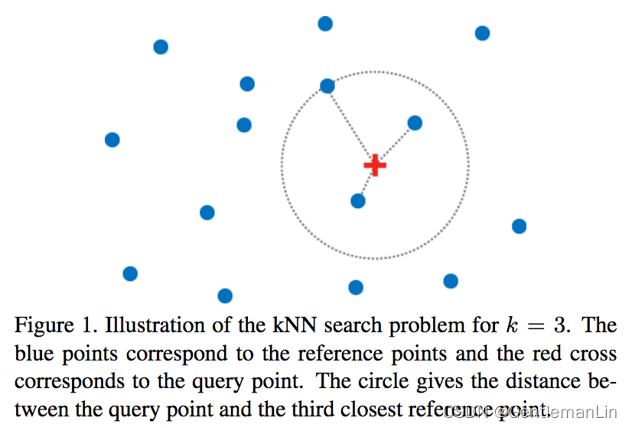
📝参考(reference)点集有M个点,查询(query)点集有N个点,空间维度(dim)为d维,那么计算查询点集与参考点集的距离时间复杂度为O(nmd)。同时,对于每一个query点计算出的M个距离需要进行排序,排序至少需要O(mlogm)的时间复杂度,全部query点集仅排序就需要O(mnlogm)的时间复杂度。因此,整个KNN问题的时间复杂度为O(mnd)+O(mnlogm).
显存加速
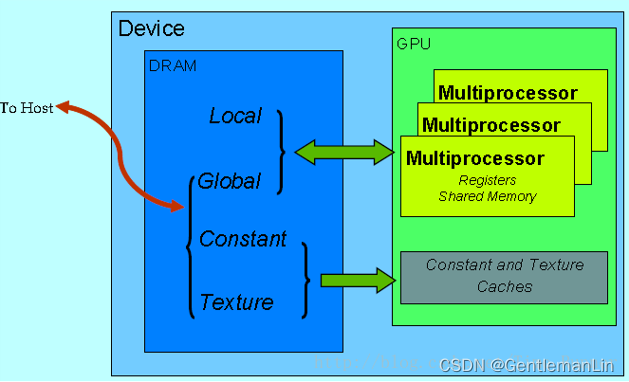
🌟GPU的全局显存(global memory)具有大带宽,但是对于非合并(non-coalesced)访问有巨大的性能损耗;而纹理显存(texture memory)对于非合并访问则损耗较小。因此,在Cuda实现中,可使用全局显存存储查询点集Q(合并访问),使用纹理显存存储参考点集R(非合并访问)。对于n个查询点,参考点集所有点到它的距离是彼此独立的,因此,可以由一个线程处理一个查询点的距离排序获得性能加速。
Code
/**
*
* 日期 03/07/2009
* ====
*
* 作者 Vincent Garcia
* ======= Eric Debreuve
* Michel Barlaud
*
* 描述 给定一个参考点集和一个查询点集,程序返回每个查询点到参考点集中最近的k个邻居的距离和索引。
* =========== 计算是使用NVIDIA CUDA API执行的。
*
* 论文 使用GPU进行快速k最近邻搜索
* ====
*
* BibTeX @INPROCEEDINGS{2008_garcia_cvgpu,
* ====== author = {V. Garcia and E. Debreuve and M. Barlaud},
* title = {Fast k nearest neighbor search using GPU},
* booktitle = {CVPR Workshop on Computer Vision on GPU},
* year = {2008},
* address = {Anchorage, Alaska, USA},
* month = {June}
* }
*
*/
// 如果代码用于Matlab,请将 MATLAB_CODE 设置为 1。否则,设置为 0。
#define MATLAB_CODE 0
// 头文件
#include <stdio.h>
#include <math.h>
#include <algorithm>
#include "cuda.h"
#if MATLAB_CODE == 1
#include "mex.h"
#else
#include <time.h>
#endif
// 程序使用的常量
#define MAX_PITCH_VALUE_IN_BYTES 262144
#define MAX_TEXTURE_WIDTH_IN_BYTES 65536
#define MAX_TEXTURE_HEIGHT_IN_BYTES 32768
#define MAX_PART_OF_FREE_MEMORY_USED 0.9
#define BLOCK_DIM 16
// 参考点的纹理(如果可能的话)
texture<float, 2, cudaReadModeElementType> texA;
//-----------------------------------------------------------------------------------------------//
// 核函数 //
//-----------------------------------------------------------------------------------------------//
/**
* 计算两个矩阵A(参考点)和B(查询点)之间的距离,分别包含wA和wB个点。
* 矩阵A是一个纹理。
*
* @param wA 矩阵A的宽度 = A中的点数
* @param B 指向矩阵B的指针
* @param wB 矩阵B的宽度 = B中的点数
* @param pB 矩阵B的步幅(以列数表示)
* @param dim 点的维度 = 矩阵A和B的高度
* @param AB 指向包含计算出的wA*wB距离的矩阵的指针
*/
__global__ void cuComputeDistanceTexture(int wA, float* B, int wB, int pB, int dim, float* AB) {
unsigned int xIndex = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int yIndex = blockIdx.y * blockDim.y + threadIdx.y;
if (xIndex < wB && yIndex < wA) {
float ssd = 0;
for (int i = 0; i < dim; i++) {
float tmp = tex2D(texA, static_cast<float>(yIndex), static_cast<float>(i)) - B[i * pB + xIndex];
ssd += tmp * tmp;
}
AB[yIndex * pB + xIndex] = ssd;
}
}
/**
* 计算两个矩阵A(参考点)和B(查询点)之间的距离,分别包含wA和wB个点。
*
* @param A 指向矩阵A的指针
* @param wA 矩阵A的宽度 = A中的点数
* @param pA 矩阵A的步幅(以列数表示)
* @param B 指向矩阵B的指针
* @param wB 矩阵B的宽度 = B中的点数
* @param pB 矩阵B的步幅(以列数表示)
* @param dim 点的维度 = 矩阵A和B的高度
* @param AB 指向包含计算出的wA*wB距离的矩阵的指针
*/
__global__ void cuComputeDistanceGlobal(float* A, int wA, int pA, float* B, int wB, int pB, int dim, float* AB) {
// 声明共享内存数组As和Bs,用于存储A和B的子矩阵
__shared__ float shared_A[BLOCK_DIM][BLOCK_DIM];
__shared__ float shared_B[BLOCK_DIM][BLOCK_DIM];
// A的子矩阵(起点,步长,终点)和B的子矩阵(起点,步长)
__shared__ int begin_A;
__shared__ int begin_B;
__shared__ int step_A;
__shared__ int step_B;
__shared__ int end_A;
// 线程索引
int tx = threadIdx.x;
int ty = threadIdx.y;
// 其他变量
float tmp;
float ssd = 0;
// 循环参数
begin_A = BLOCK_DIM * blockIdx.y;
begin_B = BLOCK_DIM * blockIdx.x;
step_A = BLOCK_DIM * pA;
step_B = BLOCK_DIM * pB;
end_A = begin_A + (dim - 1) * pA;
// 条件
int cond0 = (begin_A + tx < wA); // 用于写入共享内存
int cond1 = (begin_B + tx < wB); // 用于写入共享内存、计算和写入输出矩阵
int cond2 = (begin_A + ty < wA); // 用于计算和写入输出矩阵
// 循环遍历A和B的所有子矩阵,计算块子矩阵
for (int a = begin_A, b = begin_B; a <= end_A; a += step_A, b += step_B) {
// 将矩阵从设备内存加载到共享内存;每个线程加载一个矩阵元素
if (a / pA + ty < dim) {
shared_A[ty][tx] = (cond0) ? A[a + pA * ty + tx] : 0;
shared_B[ty][tx] = (cond1) ? B[b + pB * ty + tx] : 0;
} else {
shared_A[ty][tx] = 0;
shared_B[ty][tx] = 0;
}
// 同步,以确保矩阵已加载
__syncthreads();
// 计算两个矩阵之间的差异;每个线程计算块子矩阵的一个元素
if (cond2 && cond1) {
for (int k = 0; k < BLOCK_DIM; ++k) {
tmp = shared_A[k][ty] - shared_B[k][tx];
ssd += tmp * tmp;
}
}
// 同步,确保前面的计算在下一次迭代中加载两个新的A和B子矩阵之前完成
__syncthreads();
}
// 将块子矩阵写入设备内存;每个线程写入一个元素
if (cond2 && cond1)
AB[(begin_A + ty) * pB + (begin_B + tx)] = ssd;
}
/**
* 在距离矩阵的每列中收集第k小的距离。
*
* @param dist 距离矩阵
* @param dist_pitch 距离矩阵的步幅(以列数表示)
* @param ind 索引矩阵
* @param ind_pitch 索引矩阵的步幅(以列数表示)
* @param width 距离矩阵和索引矩阵的宽度
* @param height 距离矩阵和索引矩阵的高度
* @param k 邻居数
*/
__global__ void cuInsertionSort(float* dist, int dist_pitch, int* ind, int ind_pitch, int width, int height, int k) {
// 变量
int l, i, j;
float* p_dist;
int* p_ind;
float curr_dist, max_dist;
int curr_row, max_row;
unsigned int xIndex = blockIdx.x * blockDim.x + threadIdx.x;
if (xIndex < width) {
// 指针偏移、初始化和最大值
p_dist = dist + xIndex;
p_ind = ind + xIndex;
max_dist = p_dist[0];
p_ind[0] = 1;
// 部分1:排序前k个元素
for (l = 1; l < k; l++) {
curr_row = l * dist_pitch;
curr_dist = p_dist[curr_row];
if (curr_dist < max_dist) {
i = l - 1;
for (j = 0; j < l - 1; j++) {
if (p_dist[j * dist_pitch] > curr_dist) {
i = j;
break;
}
}
for (j = l; j > i; j--) {
p_dist[j * dist_pitch] = p_dist[(j - 1) * dist_pitch];
p_ind[j * ind_pitch] = p_ind[(j - 1) * ind_pitch];
}
p_dist[i * dist_pitch] = curr_dist;
p_ind[i * ind_pitch] = l + 1;
} else {
p_ind[l * ind_pitch] = l + 1;
}
max_dist = p_dist[curr_row];
}
// 部分2:将元素插入前k行
max_row = (k - 1) * dist_pitch;
for (l = k; l < height; l++) {
curr_dist = p_dist[l * dist_pitch];
if (curr_dist < max_dist) {
i = k - 1;
for (int a = 0; a < k - 1; a++) {
if (p_dist[a * dist_pitch] > curr_dist) {
i = a;
break;
}
}
for (j = k - 1; j > i; j--) {
p_dist[j * dist_pitch] = p_dist[(j - 1) * dist_pitch];
p_ind[j * ind_pitch] = p_ind[(j - 1) * ind_pitch];
}
p_dist[i * dist_pitch] = curr_dist;
p_ind[i * ind_pitch] = l + 1;
max_dist = p_dist[max_row];
}
}
}
}
/**
* 计算距离矩阵前k行的平方根。
*
* @param dist 距离矩阵
* @param width 距离矩阵的宽度
* @param pitch 距离矩阵的步幅(以列数表示)
* @param k 邻居数
*/
__global__ void cuParallelSqrt(float* dist, int width, int pitch, int k) {
unsigned int xIndex = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int yIndex = blockIdx.y * blockDim.y + threadIdx.y;
if (xIndex < width && yIndex < k) {
dist[yIndex * pitch + xIndex] = sqrt(dist[yIndex * pitch + xIndex]);
}
}
//-----------------------------------------------------------------------------------------------//
// k最近邻居算法 //
//-----------------------------------------------------------------------------------------------//
/**
* 打印内存分配过程中返回的错误信息。
*
* @param error 内存分配函数返回的错误值
* @param memorySize 无法分配的内存大小
* @return 如果发生错误,返回1
*/
int returnError(cudaError error, const char* memorySize) {
if (error) {
printf("内存不足: %s\n", memorySize);
return 1;
}
return 0;
}
/**
* 计算每个分配内存的大小。
*
* @param pitch 距离矩阵的步幅
* @param width 距离矩阵的宽度
* @param height 距离矩阵的高度
* @param dim 点的维度
* @return 如果发生错误,返回1
*/
int computeAllocationSize(size_t pitch, int width, int height, int dim) {
size_t freeMem, totalMem;
cudaMemGetInfo(&freeMem, &totalMem);
size_t allocSize = pitch * height + pitch * width + dim * height * sizeof(float) * 2;
if (allocSize > freeMem * MAX_PART_OF_FREE_MEMORY_USED) {
printf("内存不足: 需要 %ld 字节,但仅有 %ld 字节可用。\n", allocSize, freeMem);
return 1;
}
return 0;
}
/**
* 执行k最近邻居计算。
*
* @param ref_host 参考点(维度为 点数 * 点的维度)
* @param ref_width 参考点矩阵的宽度
* @param query_host 查询点(维度为 点数 * 点的维度)
* @param query_width 查询点矩阵的宽度
* @param height 点矩阵的高度
* @param k 邻居数
* @param dist_host 返回的距离矩阵(维度为 查询点数 * k)
* @param dist_pitch 距离矩阵的步幅
* @param ind_host 返回的索引矩阵(维度为 查询点数 * k)
* @param ind_pitch 索引矩阵的步幅
*/
extern "C" void knn(float* ref_host, int ref_width, float* query_host, int query_width, int height, int k,
float* dist_host, int dist_pitch, int* ind_host, int ind_pitch) {
// 变量
float* ref_dev;
float* query_dev;
float* dist_dev;
int* ind_dev;
size_t ref_pitch, query_pitch, dist_pitch_dev;
cudaError error;
// 为参考点分配内存
error = cudaMallocPitch((void**)&ref_dev, &ref_pitch, ref_width * sizeof(float), height);
if (returnError(error, "参考点")) return;
// 为查询点分配内存
error = cudaMallocPitch((void**)&query_dev, &query_pitch, query_width * sizeof(float), height);
if (returnError(error, "查询点")) return;
// 为距离矩阵分配内存
error = cudaMallocPitch((void**)&dist_dev, &dist_pitch_dev, query_width * sizeof(float), ref_width);
if (returnError(error, "距离矩阵")) return;
// 为索引矩阵分配内存
error = cudaMallocPitch((void**)&ind_dev, &ind_pitch, query_width * sizeof(int), k);
if (returnError(error, "索引矩阵")) return;
// 从主机内存复制到设备内存
cudaMemcpy2D(ref_dev, ref_pitch, ref_host, ref_width * sizeof(float), ref_width * sizeof(float), height, cudaMemcpyHostToDevice);
cudaMemcpy2D(query_dev, query_pitch, query_host, query_width * sizeof(float), query_width * sizeof(float), height, cudaMemcpyHostToDevice);
// 核函数的参数
dim3 block(BLOCK_DIM, BLOCK_DIM, 1);
dim3 grid((query_width + block.x - 1) / block.x, (ref_width + block.y - 1) / block.y);
// 计算距离
cuComputeDistanceGlobal<<<grid, block>>>(ref_dev, ref_width, ref_pitch / sizeof(float), query_dev, query_width, query_pitch / sizeof(float), height, dist_dev);
// 同步
cudaThreadSynchronize();
// 核函数的参数
grid = dim3((query_width + block.x - 1) / block.x, 1, 1);
// 排序距离
cuInsertionSort<<<grid, block>>>(dist_dev, dist_pitch_dev / sizeof(float), ind_dev, ind_pitch / sizeof(int), query_width, ref_width, k);
// 同步
cudaThreadSynchronize();
// 计算最小k个距离的平方根
grid = dim3((query_width + block.x - 1) / block.x, (k + block.y - 1) / block.y);
cuParallelSqrt<<<grid, block>>>(dist_dev, query_width, dist_pitch_dev / sizeof(float), k);
// 同步
cudaThreadSynchronize();
// 从设备内存复制到主机内存
cudaMemcpy2D(dist_host, dist_pitch, dist_dev, dist_pitch_dev, query_width * sizeof(float), k, cudaMemcpyDeviceToHost);
cudaMemcpy2D(ind_host, ind_pitch, ind_dev, ind_pitch, query_width * sizeof(int), k, cudaMemcpyDeviceToHost);
// 释放内存
cudaFree(ref_dev);
cudaFree(query_dev);
cudaFree(dist_dev);
cudaFree(ind_dev);
}
#if MATLAB_CODE == 1
// MATLAB入口点
void mexFunction(int nlhs, mxArray* plhs[], int nrhs, const mxArray* prhs[]) {
// 变量声明和输入检查
// 调用knn函数
// 返回结果
}
#endif核心部分理解
🌟布鲁特力方法(Brute-Force, BF)用于最近邻搜索的两个关键步骤:计算距离和排序的并行化。
-
计算距离的并行化:距离计算的目标是计算查询点集中的每个点与参考点集中每个点之间的距离。这个步骤可以通过CUDA的线程并行化来加速。
例如16x16的块大小意味着每个CUDA块(block)包含16 x 16 = 256个线程,这些线程协同工作来处理数据。
线程分布:
每个CUDA块有256个线程,分布在一个16 x 16的网格中。
threadIdx.x代表线程在块内的列索引,范围是0到15。threadIdx.y代表线程在块内的行索引,范围是0到15。数据处理:
每个线程负责处理矩阵中的一个元素。在本例中,每个线程处理查询集合和参考集合中子矩阵的一对元素,并计算它们之间的距离。
16 x 16的块大小意味着每个块同时处理16个查询点和16个参考点之间的距离计算。
共享内存:
每个块有两个共享内存数组
shared_A和shared_B,每个大小为16 x 16,用于存储当前处理的子矩阵数据。这样可以有效利用共享内存的高访问速度,减少对全局内存的访问,提高计算效率。
🖊计算示例
假设我们有两个矩阵A(查询集合)和B(参考集合),如下所示:
-
矩阵A:大小为
wA x dim,表示wA个查询点,每个点有dim个特征。 -
矩阵B:大小为
wB x dim,表示wB个参考点,每个点有dim个特征。
我们希望计算查询点和参考点之间的距离,并存储在矩阵AB中,大小为
wA x wB。步骤:
-
线程索引计算:
tx = threadIdx.x:当前线程在块内的列索引。ty = threadIdx.y:当前线程在块内的行索引。 -
子矩阵加载:
每个块负责加载并处理16 x 16的子矩阵。
例如,第一个块加载矩阵A和B的前16行和前16列。
子矩阵数据从全局内存加载到共享内存。
-
距离计算:
每个线程计算其对应位置的距离。
例如,线程
(tx, ty)计算子矩阵A中第ty行第tx列的元素与子矩阵B中相同位置的元素之间的距离。 -
结果存储:
每个线程计算的结果存储在全局内存中的结果矩阵AB中对应的位置。
Code:
__global__ void cuComputeDistanceGlobal(float* A, int wA, int pA, float* B, int wB, int pB, int dim, float* AB) { __shared__ float shared_A[BLOCK_DIM][BLOCK_DIM]; __shared__ float shared_B[BLOCK_DIM][BLOCK_DIM]; int tx = threadIdx.x; int ty = threadIdx.y; float tmp; float ssd = 0; int begin_A = BLOCK_DIM * blockIdx.y; int begin_B = BLOCK_DIM * blockIdx.x; int step_A = BLOCK_DIM * pA; int step_B = BLOCK_DIM * pB; int end_A = begin_A + (dim - 1) * pA; int cond0 = (begin_A + tx < wA); int cond1 = (begin_B + tx < wB); int cond2 = (begin_A + ty < wA); for (int a = begin_A, b = begin_B; a <= end_A; a += step_A, b += step_B) { if (a / pA + ty < dim) { shared_A[ty][tx] = (cond0) ? A[a + pA * ty + tx] : 0; shared_B[ty][tx] = (cond1) ? B[b + pB * ty + tx] : 0; } else { shared_A[ty][tx] = 0; shared_B[ty][tx] = 0; } __syncthreads(); if (cond2 && cond1) { for (int k = 0; k < BLOCK_DIM; ++k) { tmp = shared_A[k][ty] - shared_B[k][tx]; ssd += tmp * tmp; } } __syncthreads(); } if (cond2 && cond1) AB[(begin_A + ty) * pB + (begin_B + tx)] = ssd; } -
-
排序的并行化:排序是为了找到查询点集中的每个点到参考点集中距离最小的k个点。这一步我们可以通过并行插入排序来实现。
线程分配:每个线程处理查询点集的一列(即一个查询点到所有参考点的距离)。
并行排序:每个线程独立地对其负责的一列进行插入排序。
Code:
__global__ void cuInsertionSort(float* dist, int dist_pitch, int* ind, int ind_pitch, int width, int height, int k) { // 变量 int l, i, j; float* p_dist; int* p_ind; float curr_dist, max_dist; int curr_row, max_row; unsigned int xIndex = blockIdx.x * blockDim.x + threadIdx.x; if (xIndex < width) { // 指针偏移、初始化和最大值 p_dist = dist + xIndex; p_ind = ind + xIndex; max_dist = p_dist[0]; p_ind[0] = 1; // 部分1:排序前k个元素 for (l = 1; l < k; l++) { curr_row = l * dist_pitch; curr_dist = p_dist[curr_row]; if (curr_dist < max_dist) { i = l - 1; for (j = 0; j < l - 1; j++) { if (p_dist[j * dist_pitch] > curr_dist) { i = j; break; } } for (j = l; j > i; j--) { p_dist[j * dist_pitch] = p_dist[(j - 1) * dist_pitch]; p_ind[j * ind_pitch] = p_ind[(j - 1) * ind_pitch]; } p_dist[i * dist_pitch] = curr_dist; p_ind[i * ind_pitch] = l + 1; } else { p_ind[l * ind_pitch] = l + 1; } max_dist = p_dist[curr_row]; } // 部分2:将元素插入前k行 max_row = (k - 1) * dist_pitch; for (l = k; l < height; l++) { curr_dist = p_dist[l * dist_pitch]; if (curr_dist < max_dist) { i = k - 1; for (int a = 0; a < k - 1; a++) { if (p_dist[a * dist_pitch] > curr_dist) { i = a; break; } } for (j = k - 1; j > i; j--) { p_dist[j * dist_pitch] = p_dist[(j - 1) * dist_pitch]; p_ind[j * ind_pitch] = p_ind[(j - 1) * ind_pitch]; } p_dist[i * dist_pitch] = curr_dist; p_ind[i * ind_pitch] = l + 1; max_dist = p_dist[max_row]; } } } }
















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











