







MPI
MPI环境配置(WSL Ubuntu20.04)
-
下载源码并解压
wget http://www.mpich.org/static/downloads/3.4.2/mpich-3.4.2.tar.gz
tar -xvzf mpich-3.4.2.tar.gz-
创建安装文件夹
mkdir mpich-install-
配置并编译
cd mpich-3.4.2
./configure -prefix=$HOME/mpich-install --with-device=ch3 --disable-fortran
make -j8 && make install -j8-
配置环境变量
#返回首页
cd ../
#打开bashrc文件
vim .bashrc
#mpi config
#mpi config
export MPI_ROOT=$HOME/mpich-install
export PATH=$MPI_ROOT/bin:$PATH
export MANPATH=$MPI_ROOT/man:$MANPATH-
验证安装
mpicc --version-
测试案例
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
MPI_Init(NULL, NULL);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
printf("Hello world from processor %d of %d\n", world_rank, world_size);
MPI_Finalize();
return 0;
}-
编译运行
//编译程序
mpicc -o hello_mpi hello_mpi.c
//运行程序
mpirun -np 4 ./hello_mpiMPI简介
🌟概念:
-
MPI(Message Passing Interface)是一个消息传递接口标准
-
MPI提供一个可移植、高效、灵活的消息传递接口库
-
MPI以语言独立的形式存在,可运行在不同的操作系统和硬件平台上
-
MPI提供与C/C++和Fortran语言的保定
⭐️MPI版本:
-
MPICH:MPICH 是由美国阿贡国家实验室(Argonne National Laboratory)开发的一种高性能且可扩展的 MPI 实现。MPICH 被广泛用于研究和高性能计算环境,并且作为其他许多 MPI 实现的基础。
-
LAM/MPI (Local Area Multicomputer):LAM/MPI 是一种适用于局域网环境的 MPI 实现,最初由俄亥俄州立大学开发。虽然 LAM/MPI 在其活跃时期是一个流行的选择,但由于项目不再维护,许多用户已经转向其他更现代的 MPI 实现。
-
Open MPI:Open MPI 是一个开源的、高性能的 MPI 实现,由多家研究机构和企业合作开发。Open MPI 结合了许多前期 MPI 项目的最佳特性,并得到了广泛的社区支持。
🖊基本思想:MPI(Message Passing Interface)编程的基本思想是通过消息传递实现并行计算,其中“对等式”(peer-to-peer)是一个重要的概念。在对等式模型中,每个进程都是平等的,具有相同的能力和权限。这与主从模型不同,在主从模型中有一个主节点和多个从节点。

🌟详解:MPI通常采用对等设计,所有节点在理论上是平等的,可以互相通信。虽然没有固定的主从节点,但程序可以根据需要给予某个节点特殊角色,每个进程有唯一的标识符(rank),从0到N-1(N是总进程数),rank 0的进程常被用来执行初始化、结果收集等特殊任务。MPI通常遵循Single Program, Multiple Data (SPMD)模型,同一程序在所有节点上运行,但处理不同的数据集。MPI通信方式包括点对点或集体通信,点对点通信为任意两个进程之间可以直接交换数据,集体通信为涉及一组或所有进程的通信操作。
MPI命令
编译与执行命令
🌟mpicc:mpicc 是 MPI 编译器命令,用于编译 C 语言的 MPI 程序。它通常会调用底层的 C 编译器(如 gcc),并自动链接 MPI 库。
mpicc -o myapp myapp.c🖊详解:
mpicc: 调用 MPI 编译器。
-o myapp: 指定输出可执行文件名为 myapp。
myapp.c: 源文件名。
🌟mpiexec:mpiexec 是 MPI 执行命令,用于启动 MPI 程序。它允许用户指定要运行的进程数量以及在哪些机器上运行这些进程。
mpiexec -machinefile ./machinefile ./myapp🖊详解:
mpiexec: 调用 MPI 执行器。
-machinefile ./machinefile: 指定一个机器文件(machinefile),该文件列出了要运行 MPI 进程的机器列表。
./myapp: 要执行的 MPI 程序。
🔴机器文件(machinefile):机器文件是一个文本文件,列出所有要参与运行 MPI 程序的机器或节点。每行通常代表一个机器,可以包含机器名称或 IP 地址,并且可以指定每个机器上的进程数量。
//示例 machinefile:
node1 slots=4
node2 slots=4
node3 slots=4node1, node2, node3:参与计算的机器名或 IP 地址。
slots=4: 每个机器上可运行的进程数量。
⭐️PS:没有 machinefile 的情况默认本地执行,如果没有指定 machinefile 或者主机列表,mpiexec 默认在本地机器上启动所有的进程。也就是说,所有的进程会在同一台机器的不同核心上运
MPI子集
🌟概念:#include <mpi.h> MPI头函数,提供了MPI函数和数据类型定义

🌟六个基本函数:
- MPI初始化:通过MPI_Init函数进入MPI环境并完成所有的初始化工作。
//初始化 MPI 环境。必须在调用任何其他 MPI 函数之前调用。
int MPI_Init(int *argc, char ***argv);
//argc: 指向命令行参数个数的指针。
//argv: 指向命令行参数数组的指针。
MPI_Init(&argc, &argv);-
MPI结束:通过MPI_Finalize函数从MPI环境中退出。
//终止 MPI 环境。所有 MPI 程序必须在结束时调用此函数。
int MPI_Finalize(void);
MPI_Finalize();-
获取指定通信域的进程数:调用MPI_Comm_size 函数获取指定通信域的进程个数,确定自身完成任务比例。
//获取指定通信器中的进程总数。
int MPI_Comm_size(MPI_Comm comm, int *size);
//comm: 通信器(通常为 MPI_COMM_WORLD)。
//size: 指向存储进程总数的变量的指针。
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);-
获取进程的编号:调用MPI_Comm_rank函数获得当前进程在指定通信域中的编号,将自身与其他程序区分。
//获取指定通信器中当前进程的排名(ID)。
int MPI_Comm_rank(MPI_Comm comm, int *rank);
//comm: 通信器(通常为 MPI_COMM_WORLD)。
//rank: 指向存储当前进程排名的变量的指针。
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);-
消息发送:MPI_Send函数用于发送一个消息到目标进程。
//向指定进程发送消息。
int MPI_Send(const void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm);
//buf: 指向要发送的数据的指针。
//count: 发送的数据个数。
//datatype: 数据类型(如 MPI_INT)。
//dest: 目标进程的排名(ID)。
//tag: 消息标签。
//comm: 通信器(通常为 MPI_COMM_WORLD)。
int message = 123;
MPI_Send(&message, 1, MPI_INT, dest_rank, 0, MPI_COMM_WORLD);-
消息接受:MPI_Recv函数用于从指定进程接收一个消息
//从指定进程接收消息。
int MPI_Recv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status);
//buf: 指向存储接收数据的缓冲区的指针。
//count: 接收的数据个数,以datatype为单位,必须连续。
//datatype: 数据类型(如 MPI_INT)。
//source: 源进程的排名(ID)。
//tag: 消息标签。
//comm: 通信器(通常为 MPI_COMM_WORLD)。
//status: 指向存储接收状态信息的变量的指针。
int received_message;
MPI_Recv(&received_message, 1, MPI_INT, source_rank, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
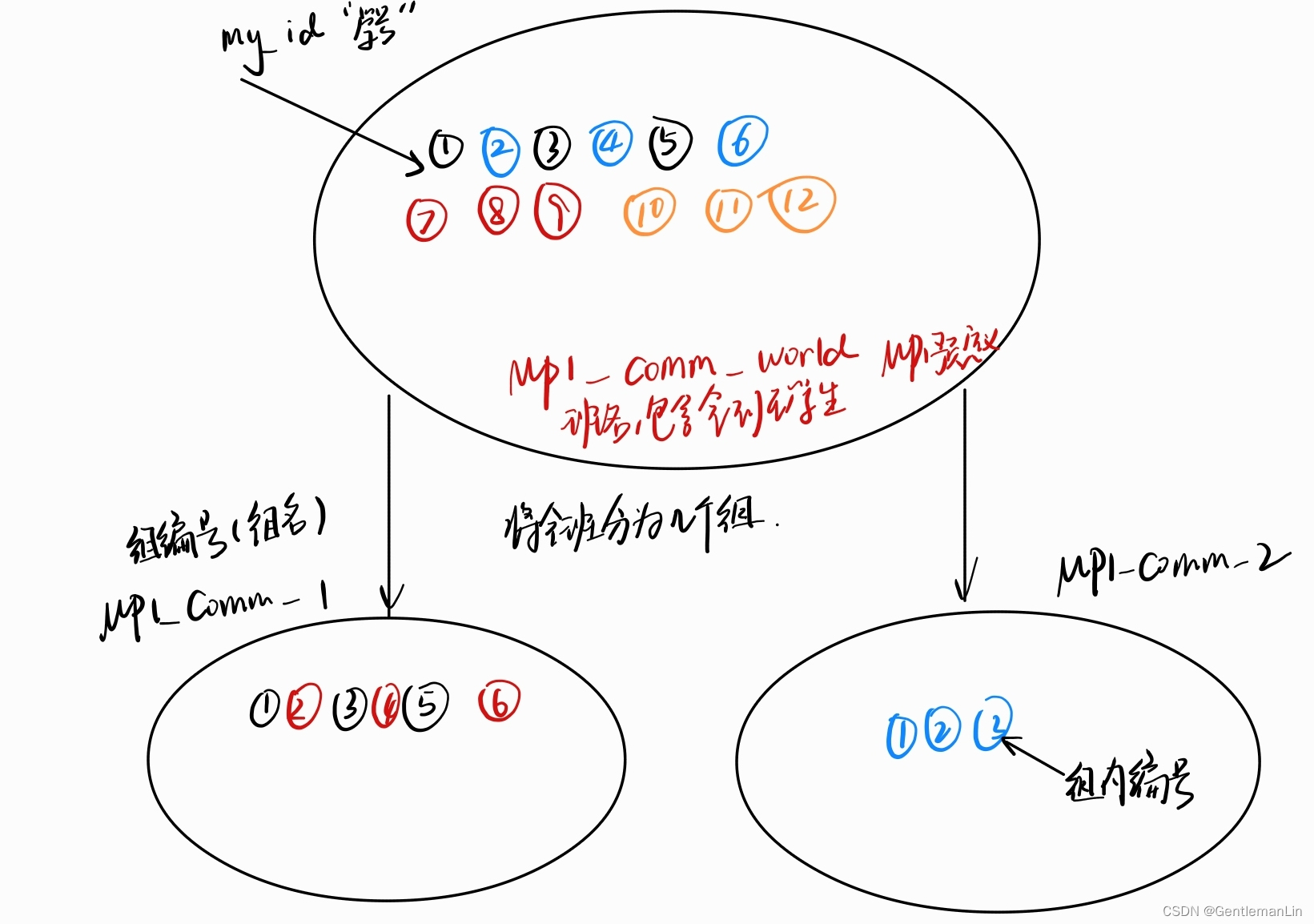
🔴通信域(通信子):在 MPI(Message Passing Interface)编程中,通信域(communicator)是一个关键的概念。通信域定义了一组可以相互通信的进程,并且每个通信域都有一个唯一的标识符和进程的本地编号系统。MPI_COMM_WORLD:默认的通信域,包含所有的 MPI 进程。
🔴MPI消息发送机制--两步进行
-
MPI_Send( A, … ) 发送
-
MPI_Recv( B, … ) 接收
发/收 两步机制:避免直接读写对方内存,保证安全性。

测试样例
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
// 初始化 MPI 环境
MPI_Init(&argc, &argv);
// 获取进程总数
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// 获取当前进程的排名
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
// 进程 0 向所有其他进程发送消息
if (world_rank == 0) {
int message = 123;
for (int i = 1; i < world_size; i++) {
MPI_Send(&message, 1, MPI_INT, i, 0, MPI_COMM_WORLD);
}
} else {
int received_message;
MPI_Recv(&received_message, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("Process %d received message %d from process 0\n", world_rank, received_message);
}
// 终止 MPI 环境
MPI_Finalize();
return 0;
}
//测试指令
mpicc -o mpi_example mpi_example.c
mpirun -np 4 ./mpi_example🌟任务案例:
计算矩阵乘积:计算矩阵 A*B=C ,A,B,C:NxN矩阵,采用P个进程计算 (N能被P整除);
存储方式:分布存储, A, C 按行分割, B 按列分割。

#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
void print_matrix(float* matrix, int rows, int cols, int rank) {
printf("Process %d:\n", rank);
for (int i = 0; i < rows; ++i) {
for (int j = 0; j < cols; ++j) {
printf("%f ", matrix[i * cols + j]);
}
printf("\n");
}
printf("\n");
}
int main(int argc, char** argv) {
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
int N = 4; // 矩阵的维度 (假设 N 可以被 size 整除)
int local_N = N / size;
float* A = (float*) malloc(local_N * N * sizeof(float));
float* B = (float*) malloc(local_N * N * sizeof(float));
float* C = (float*) calloc(local_N * N, sizeof(float));
float* B_tmp = (float*) malloc(local_N * N * sizeof(float));
// 初始化矩阵 A 和 B
for (int i = 0; i < local_N; ++i) {
for (int j = 0; j < N; ++j) {
A[i * N + j] = rank * local_N + i + 1;
B[i * N + j] = (rank * local_N + i + 1) * 0.1;
}
}
print_matrix(A, local_N, N, rank);
print_matrix(B, local_N, N, rank);
// 循环通信
for (int step = 0; step < size; ++step) {
int id_send = (rank + step) % size;
int id_recv = (rank - step + size) % size;
// 使用 MPI_Sendrecv 进行同步发送和接收
MPI_Sendrecv(B, local_N * N, MPI_FLOAT, id_send, 0,
B_tmp, local_N * N, MPI_FLOAT, id_recv, 0,
MPI_COMM_WORLD, MPI_STATUS_IGNORE);
// 计算部分结果并累加到 C
for (int i = 0; i < local_N; ++i) {
for (int j = 0; j < N; ++j) {
for (int k = 0; k < local_N; ++k) {
C[i * N + j] += A[i * N + k] * B_tmp[k * N + j];
}
}
}
}
print_matrix(C, local_N, N, rank);
free(A);
free(B);
free(C);
free(B_tmp);
MPI_Finalize();
return 0;
}🌎PS:MPI_Sendrecv是MPI库中用于并行计算的函数,它允许进程在一次调用中同时发送和接收消息。这种方法相比于单独的发送(MPI_Send)和接收(MPI_Recv)可以避免死锁,简化代码,提高性能。
MPI + CUDA
🌟概念:不同机器间数据传输过程:
-
初始化和分配内存:在主机和设备上分配内存。
-
数据传输:在主机和设备之间传输数据。
-
计算:在GPU上执行计算。
-
数据传输回主机:将结果从设备传输回主机。
-
释放内存:释放主机和设备上的内存。


UVA统一虚拟寻址
🔺概念:统一虚拟寻址(Unified Virtual Addressing, UVA)是NVIDIA CUDA的一项功能,它简化了CPU和GPU之间的内存管理和数据传输。在UVA环境下,主机(CPU)和设备(GPU)共享同一个统一的虚拟地址空间,使得编程更加方便和高效。
✏️特点:
-
简化内存管理:CPU和GPU共享统一的虚拟地址空间,无需显式管理主机和设备之间的数据传输。
-
简化编程模型:可以直接使用指针访问数据,无需区分主机指针和设备指针。
-
提高数据传输效率:利用统一地址空间可以优化数据传输,减少显式内存拷贝的需求。

#UVA使用案例
#include <mpi.h>
#include <cuda_runtime.h>
#include <stdio.h>
// CUDA核函数,执行简单的向量加法
__global__ void vectorAdd(float* A, float* B, float* C, int N) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) {
C[i] = A[i] + B[i];
}
}
int main(int argc, char** argv) {
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
int N = 1024; // 向量的大小
int local_N = N / size;
float *h_A, *h_B, *h_C;
float *d_A, *d_B, *d_C;
// 在统一虚拟地址空间中分配主机和设备内存
cudaMallocManaged(&h_A, N * sizeof(float));
cudaMallocManaged(&h_B, N * sizeof(float));
cudaMallocManaged(&h_C, N * sizeof(float));
// 初始化向量 A 和 B
for (int i = 0; i < local_N; ++i) {
h_A[rank * local_N + i] = rank * local_N + i;
h_B[rank * local_N + i] = (rank * local_N + i) * 0.1f;
}
// 同步进程,以确保所有进程完成初始化
MPI_Barrier(MPI_COMM_WORLD);
// 定义 CUDA 核函数的执行配置
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
// 调用 CUDA 核函数
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(h_A, h_B, h_C, N);
cudaDeviceSynchronize();
// 打印计算结果
if (rank == 0) {
for (int i = 0; i < N; ++i) {
printf("C[%d] = %f\n", i, h_C[i]);
}
}
// 释放内存
cudaFree(h_A);
cudaFree(h_B);
cudaFree(h_C);
MPI_Finalize();
return 0;
}▶️PS:使用cudaMallocManaged在统一虚拟地址空间中分配内存,这些内存可以被CPU和GPU共享。
















 1305
1305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











